高速な形状ベーステンプレートマッチング


高速な形状ベーステンプレートマッチング
昨今はDeepLearningや大規模言語モデルによる画像認識や物体認識の進歩が凄まじいですが、本記事では古典的の画像処理による高速な形状ベースのテンプレートマッチングについて解説してきます。アルゴリズムは以下の論文をベースに独自改良を行っており、実装したアプリケーションをgithubに公開しています。
論文:
Github:

背景とアルゴリズムの概要
画像からオブジェクトを検出するときには、テンプレートマッチングや統計的手法、DeepLearning等の手法が用いられます。従来のテンプレートマッチング手法は学習が不要で高速ですが、照明変動や背景の影響を受けやすく、アルゴリズムによってはリアルタイム性が低い場合があります。一方、統計的手法やDeepLearningではロバストな検出が可能ですが、大量のトレーニングデータと計算リソースが必要です。論文ではこれらの課題を克服し、効率的かつロバストな方法でテクスチャレスのオブジェクトを検出する手法が提案されています。
論文のアプローチでは、画像からオブジェクトの勾配方向のみを特徴量としてテンプレートデータを作成し、テスト画像からテンプレートデータと類似するオブジェクトを探索します。勾配のノルム(大きさ)を考慮せず、勾配方向みを扱うことでコントラストの変化に対してロバスト性を向上させています。類似度の計算には特徴点の勾配方向のコサインを計算することでテンプレートデータとの一致度合いを求めます。
ただし、コサインは計算コストが大きいため、勾配方向を量子化して方向毎の評価値を求めるルックアップテーブルを用いることで計算コストを効率化し、SSE命令により高速化を実施します。
画像処理のアプローチ
探索対象のテンプレート画像からエッジ(勾配)の勾配角度を算出し、勾配角度を特徴量のテンプレートデータを作成する。テンプレートデータをテスト画像に対して走査して類似度を求める。
テンプレート画像をO、テスト画像をLとした時に、類似度は以下の計算式で求める。
ori は勾配角度を示し、R(c+r) は入力画像の位置 c+r を中心としたサイズTの近傍勾配を示す。コサインは勾配角度の一致度合いを評価する。つまり、テンプレートの特徴点が、R(c+r)の近傍領域に対して最大の一致度(コサイン)を求め、全ての特徴点に対して求めたコサインを加算した値を類似度とする。
勾配方向の計算
画像からソーベルフィルタで輝度勾配を計算し、勾配の方向を求める。RGBカラー画像の場合は、各色チャンネルの勾配を別々に計算し、最大のチャンネルの勾配方向を以下の計算式で求める。
勾配方向は、後の工程でレスポンスマップを算出するために8方向に量子化する。ノイズに強くするために、閾値以上の勾配ノルムに対して、3x3の近傍領域で最も頻繁に出現する勾配方向を各位置に配置していく。量子化した勾配方向マップをLとする。
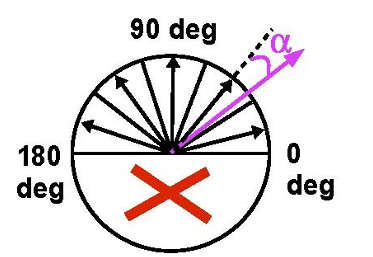
勾配方向の拡散
テンプレートをテスト画像位置に対して評価する度に(1)のコサインとmax演算子の評価を避けるために、各画像位置周辺の勾配の新しいバイナリ表現(J)を導入する。このバイナリ表現とルックアップテーブルテーブルを使用して、max演算の最大値を効率的に事前計算する。
まず、勾配方向を拡散したバイナリ表現(J)のイメージを以下に示す。
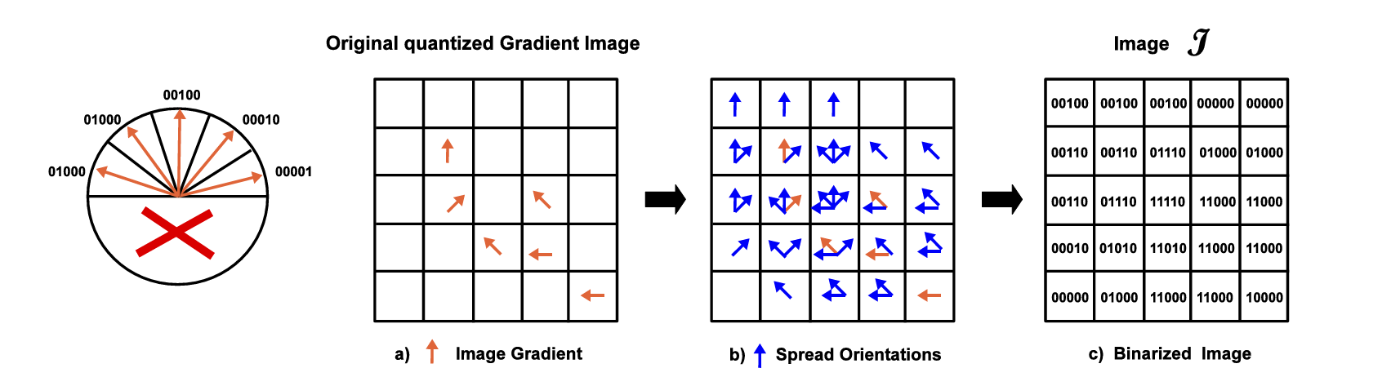
量子化した勾配方向を2進数表現で符号化し、各ビットに勾配方向を対応させる。この勾配方向を近傍に拡散させて、バイナリ表現(J)を作成する。
2進数表現にすることで、指定範囲でシフトさせてOR演算することで拡散の計算でJを求めることが出来る。シフトさせる範囲は(2)で示したサイズTの近傍とする。
レスポンスマップの計算
次に、バイナリ表現(J)をルックアップテーブルを使用して、各方位に対する類似度を事前計算する。事前計算した結果をレスポンスマップと定義する。レスポンスマップの作成イメージを以下に示す。
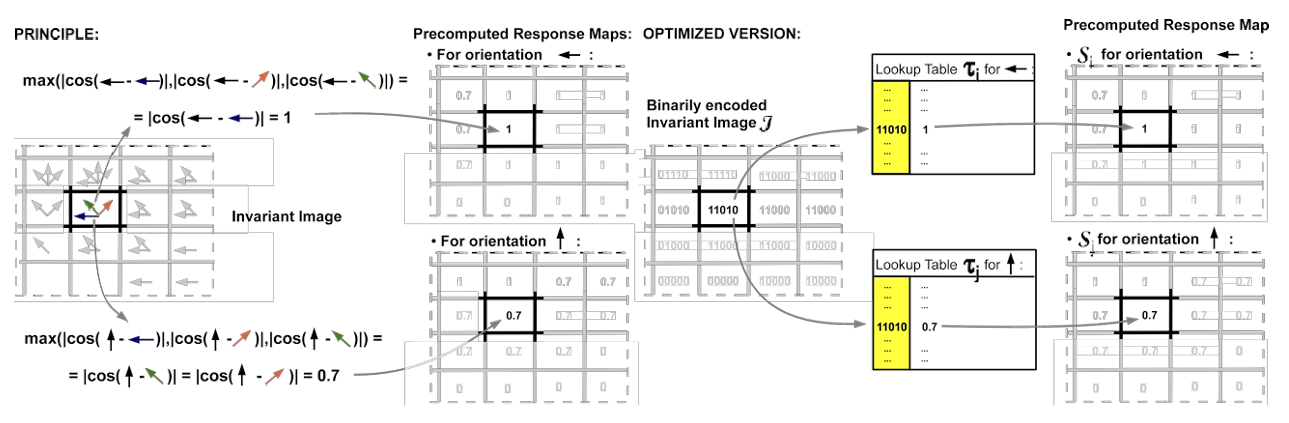
各量子化方位に対して1つのレスポンスマップを作成する。原理としては、特定の方位に対する最大類似度を計算して保存する(右のイメージ)。この計算を各方位に関する類似度が格納されたルックアップテーブルを用意しておくことで、方位をインデックスに類似度を求める(左のイメージ)。このレスポンスマップを元に、量子化8方位のレスポンスマップが作成される。
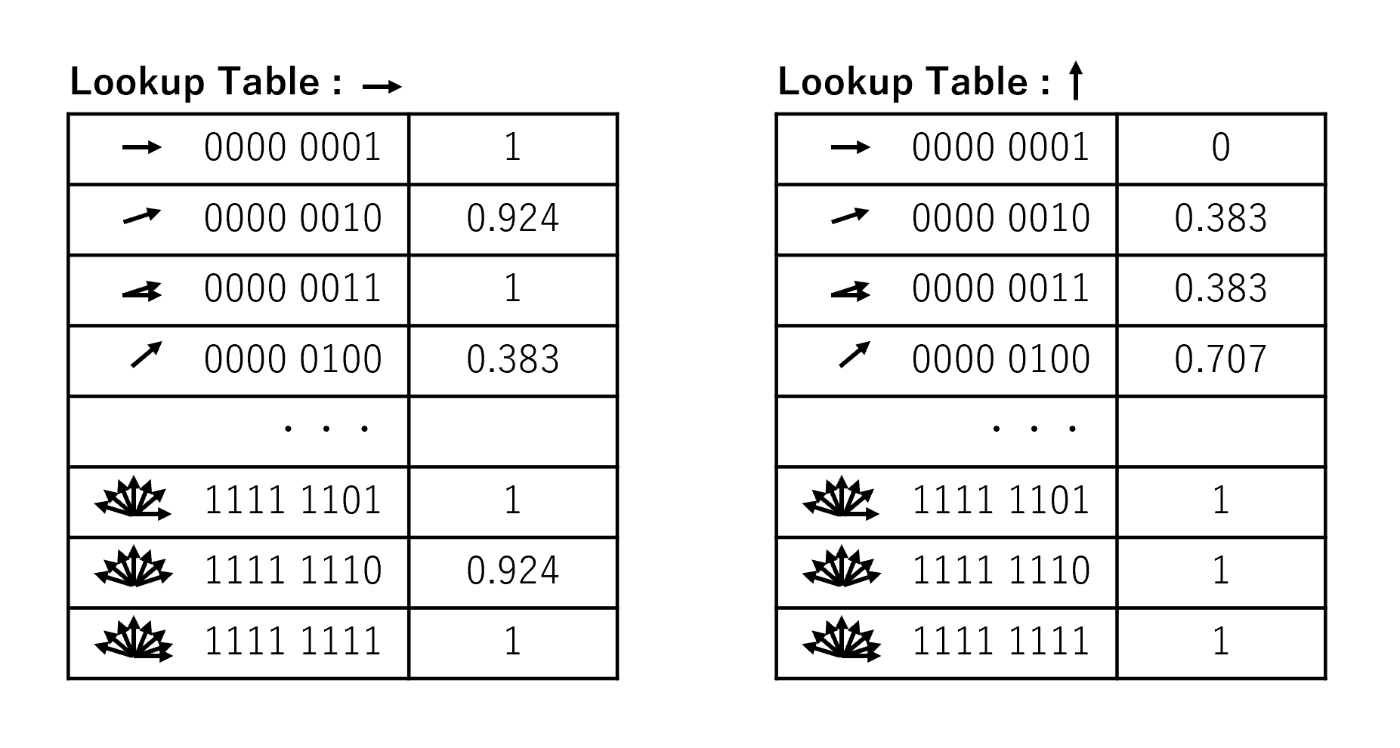
参考として、方位が0度(→)と90度(↑)ルックアップテーブルの例を以下に示す。方位が一致している場合はcos(0)で「1」となり、方位がズレる毎に類似度が低下していることが分かると思う。
各方位iについて、レスポンスマップSiの各位置cにおける値は以下の計算式となる。Tはルックアップテーブルを示す。
最終的な類似度の計算は以下となる。
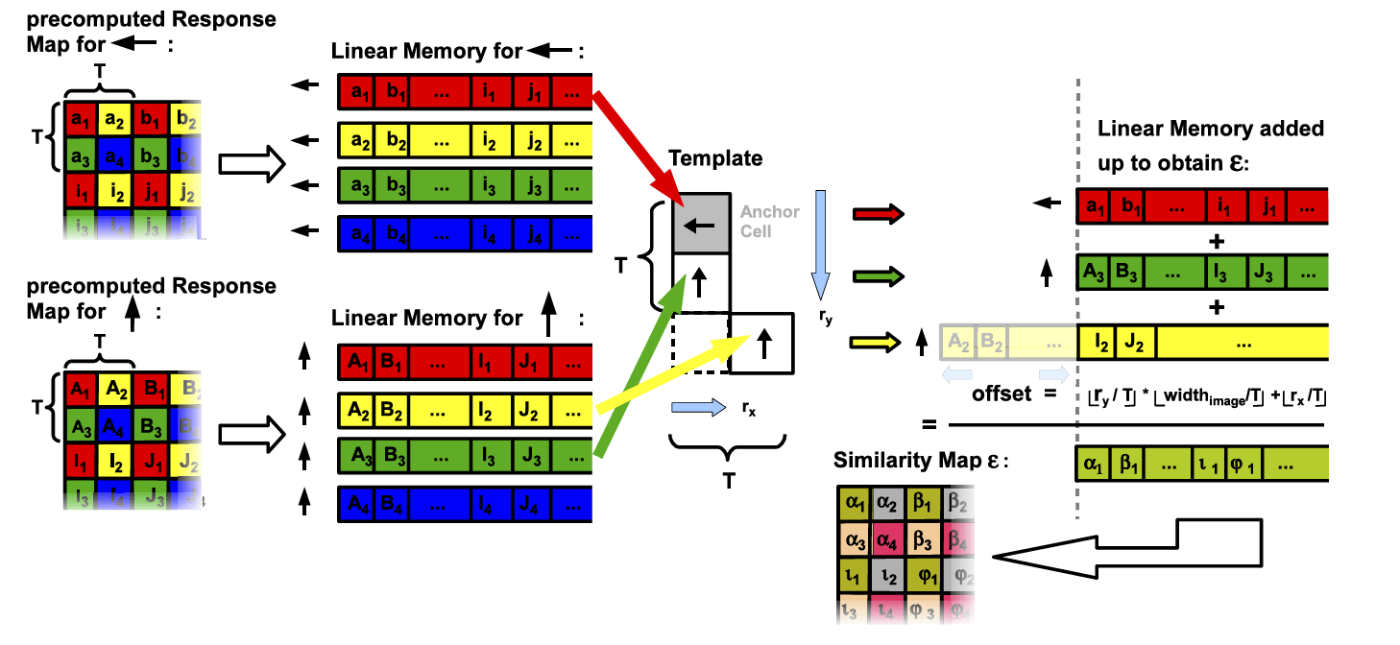
並列化のためメモリ線形化
最近のプロセッサでは、メインメモリから一度にいつのデータを読み出すだけでなく、キャッシュラインと呼ばれる複数のデータを同時に読み出している。ランダムな場所からメモリにアクセスすると、キャッシュが失われて計算速度が低下する。
一方、同じキャッシュラインから複数の値にアクセスすることは非常に効率が良い。そのため、アクセスする順序にデータを保存すると計算を高速化することが可能となる。
また、前述したサイズT近傍への方位の拡散により、T番目の画素毎に評価を行うのが効率が良いため、下記の図に示すように、レスポンスマップをキャッシュフレンドリーな順番になるようにメモリに格納する。
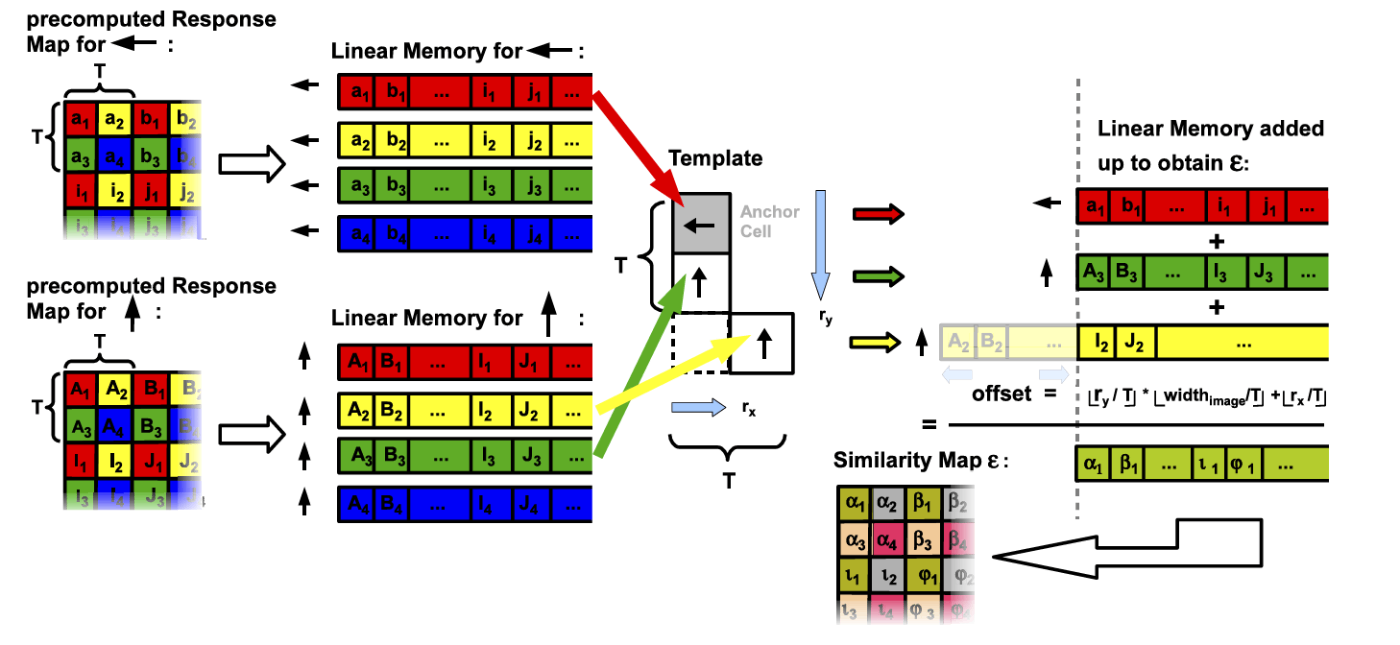
各レスポンスマップをX軸上でTピクセル離れた値がメモリ上で隣り合って配置されるように再構築する。現在の行が終わったら、Y軸にTピクセル離れた行に進む。
テンプレートの異なる方向(下記図の黒矢印)に対する線形メモリを、アンカー座標(探索基準座標)に対するテンプレートの相対位置 (Rx,Ry)^T に応じたオフセットだけシフト加算することで、テンプレートに対する入力画像上の類似度を計算することができる。また、これらの加算を並列SSE命令で実行することで、計算がされに高速化される。
以上までが論文に記載されている内容となります。以降は、実装した際の検証となります。
T近傍の拡散
前述したとおり、このアルゴリズムは特徴量をT近傍に拡散させて、T番目の画素毎に評価を行うことで計算の効率化を行っており、論文ではTのサイズは「8」と記載されている。
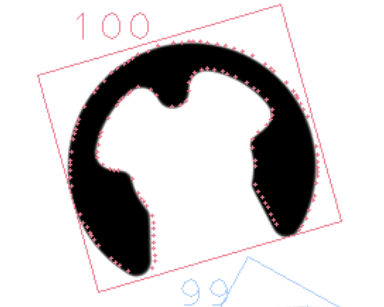
Tのサイズに関して、T=8、T=4、T=1で検出した結果を以下に示す。
| T=8 | T=4 | T=1 |
|---|---|---|
 |
 |
 |
T=8だと対象物に対してズレが大きく、Tのサイズを小さくするにつれてフィットしていきますね。これは、Tサイズで拡散するとT近傍で評価値が全て同じ結果となり、一番フィットする位置を絞りこむことができないため、Tが大きくなるとその分ズレが大きくなります。
おおよその位置を検出したい場合は問題ありませんが、詳細な位置合わせを行いたい場合は、Tを小さくする必要があります。ただし、Tのサイズを小さくすると検出速度が遅くなるため、速度と精度のトレードオフの関係となっている。
githubで公開しているアプリケーションでは、T近傍の拡散とピラミッド処理に粗探索をした後にT=1で詳細探索を行うことで、高速かつ高精度の両立を図っている。
様々な画像で評価
様々な画像で評価してみた結果をいかにします。また、評価には中京大学の橋本研究室が公開しているデータセットを使用させていただきました。
将棋の駒
テンプレート画像サイズ:149x131
テスト画像サイズ:600x400
検出時間:56[ms]

パズルピース
- テンプレート画像サイズ:153x115
- テスト画像サイズ:600x400
- 検出時間:27[ms]

T字プレート
テンプレート画像サイズ:107x121
テスト画像サイズ:600x400
検出時間:380[ms]

評価結果の考察
将棋の駒とパズルピースについては比較的高速かつ高い類似度でマッチングができていますが、T字プレートは比べてマッチングに時間がかかる結果となりました。
これは、似たような特徴量の物体が大量にあり、初回の粗探索で候補物体が多く見つかり、詳細探索で時間がかかっていると思われる。また、探索対象と他の物体の色合いが似ているため、輪郭が上手く検出できていない可能性もある。輪郭の検出感度を調整すれば検出類似度は高くなるかもしれないが、ノイズに弱くなる。
ソースコード
githubに公開しているアプリケーションのプロジェクト一式は以下のサイトで販売しております。紹介したアルゴリズムのソースコードを実際に確認・実行してみたい方はご購入ください。
Discussion