JupyterNotebookでMarkdownの記事を書く(2) - mkdocs拡張
前回に続いて、Notebookで記事を書こうをやっていきます。
Zennに限らなかった
前回はZennで記事を書くと書いていたのですが、Zennに限らず
別途自分用ノートとして書いている
mkdocs+GithubPagesで構築しているこちらのページにも
共通していることなので、Zenn改め「NotebookでMarkdownの記事を書く」と変更することにしました。
今回やること
で。
今回はJupyterで書いた記事をMarkdownに変換する部分を改良していきます。
改良するのに、一緒にMkdocs側のNotebook追加処理が一部手動だったのを直すついでに
Mkdocs側でまずはテストします。(基本的にやることは同じ)
やることは、
- ipynbをPushしたらGithubActionsで変換するようにする
- nbconvertのテンプレート改良
- 記事への埋め込み
この3つになるので、順番にやっていきます。
GithubActionsの変更
まず、GithubActionsで実行するための環境をDockerで用意します。 環境はこちら。
今までは pipenv を利用していたのを、そのまま移動した形になります。
RUN apt-get install -y curl
RUN apt-get update && apt-get install -y git
RUN apt-get install -y vim less
RUN pip install --upgrade pip
ADD requirements.txt /work_dir/
WORKDIR /work_dir
RUN pip install -r requirements.txt
pipインストールは、コンテナに requirements.txt を追加して
これを利用してセットアップします。
mkdocs ==1.1.2
mkdocs-awesome-pages-plugin==2.2.1
mkdocs-git-revision-date-localized-plugin==0.4.8
mkdocs-macros-plugin==0.4.9
mkdocs-markdownextradata-plugin==0.1.3
mkdocs-material==5.3.0
mkdocs-minify-plugin==0.2.1
markdown-blockdiag==0.7.0
fontawesome-markdown==0.2.6
mkdocs-material-extensions
hbfm
nbconvert
必要なモジュールはこんなかんじになります。
今回の注意点は、GithubActionsを実行するときにSlackに開始と終了通知をしているのですが
これを実行するためには curl が必要なので、Dockfileに
RUN apt-get install -y curl
を追加しています。
ただ、 -y のオプションを入れないと Yes/No を聞かれてエラーになってしまうので
-y は必ず入れましょう(ハマった)
変換nbConvert
次に変換用のPythonを修正します。
これはほぼ前回と同じなのでコードのみ。
nbconvert を subprocessで実行し、mkdocs の指定のフォルダ以下に出力するようにします。
そして、元になったipynbへのリンクを、出力したmarkdownに追記します。
Zennの場合は、変換したmarkdownをPushしなければいけませんでしたが
Mkdocsの場合、ビルドするときにmarkdownがあれば良いので、Pushはしません。
root = f"{os.getcwd()}/notebooks"
md_root = f"{os.getcwd()}/docs/60_JupyterNotebook"
出力先は、相対パスだと色々問題なので os.getcwd() で
今のPythonのWorkDir指定になるようにしました。
これで、 notebooks 以下にある ipynb を、notebooks 以下のサブフォルダを維持して
Markdownフォルダに出力できるようになりました。
name: Python application
on:
push:
branches: [master]
jobs:
build:
runs-on: ubuntu-latest
container: docker://fereria/mkdocs:latest
steps:
- name: Send Slack Start
env:
HOOK_URL: ${{ secrets.SlackURL }}
run: |
curl -X POST --data-urlencode "payload={\"channel\": \"#github_actions\", \"username\": \"github_aciton_bot\", \"text\": \"GithubPagesのビルドを開始しました...\"}" ${HOOK_URL}
- name: Git config
run: |
git config --global core.symlinks true
git config --global user.name "Megumi Ando"
git config --global user.email "hoge@hoge"
- name: Checkout
uses: actions/checkout@v2
with:
fetch-depth: 0
- name: NbConvert
run: python create_jupyter_markdown.py
- name: Mkdocs
env:
TZ: Asia/Tokyo
run: |
python create_mkdocs_pages.py
mkdocs gh-deploy
- name: Send Slack Finish
env:
HOOK_URL: ${{ secrets.SlackURL }}
run: |
curl -X POST --data-urlencode "payload={\"channel\": \"#github_actions\", \"username\": \"github_aciton_bot\", \"text\": \"GithubPagesの更新が完了しました!!\"}" ${HOOK_URL}
コンテナの準備ができたら、 Actionsの yml を更新します。
変更点は、今までPythonのインストールをActionsで作成+そのキャッシュを作るとしていた場所を全部消して
build.container に、Docker.ioにPushしておいたイメージを指定します。
NbConvert で、リポジトリ直下にある ipynb 変換用スクリプトを実行し、
そのあとに mkdocs のTabや階層構造を自動生成
最後に、 mkdocs gh-deply でビルド結果をデプロイします。
今回の変更の結果、手元で変更したmarkdownをPushする必要がなくなったので
リポジトリにPushしてあった変換済markdownはまとめて削除しました。
だいぶすっきり。
ipynb to markdown
ここまで準備ができたら、次はipynbの変換です。
Markdownのみならば今まででも良かったのですが、Pythonに変換後テストを実行したりしたい場合
どのようにテンプレートを編集していいのかわかりません。
なので、テンプレートの書き方を確認する意味で
create_jupyter_markdown.py のようにコマンドラインで実行するのではなく
Pythonのスクリプトで変換しつつ、いい感じに加工して
markdownへの埋め込みまでできるようにしてみます。
まず、テンプレートの構造について。
nbconvertで変換をする場合は、Jinja2を使用して変換されています。
ベースとなるテンプレートファイルが存在していて
このテンプレートで、cellの数だけforで繰り返して、markdownにコンバートするための雛形が作られます。
その雛形をベースに、markdown向けのテンプレートを定義します。
これはデフォルトで用意されているものを流用しています。
カスタマイズは、Template Structure のBlockごと(codecell body header など)単位で
関数をオーバーライドするように、Blockをオーバーライドします。
たとえば、mkdocs用のテンプレートの場合、
{% extends 'markdown.tpl'%}
これで、ベースとなるテンプレートをロードします。
このままなら、markdown.tpl と同じ見た目になります。
{% block markdowncell%}
{{cell.source}}
{% endblock markdowncell%}
Notebook のうち、 markdowncell の場合なら、cellの値をそのまま展開します。
{% block ~~ %} {% block ~~ %}が、いわゆる関数の定義のようなもので
ここで挟まれた内容で、 ベースになるテンプレートを上書きします。
{{ }} で二重になっている部分は、テンプレートに渡されるPythonの変数を展開する記述になります。
cell.source であれば、各cellのソースコードを展開する...という意味です。
{% block stream %}
!!! success
```
{{ super()}}
```
{% endblock stream %}
ベースになるテンプレートの内容を展開しつつ、前後になにか足したければ、
{{ super() }} で、ベーステンプレートの内容を展開できます。
そんなかんじで、書き換えたい block を↑のように上書きしていい感じになるように調整します。
変換する
テンプレートができたら、このテンプレートを利用して変換をします。
nbconvertモジュールでは、ipynbをロードして文字列に展開してくれるExporterが用意されていて
Html Markdown PDF など、よく使うものに関してはではデフォルトでクラスが用意されています。
今回のように、指定したテンプレートでコンバートしたければ、 その名の通り TempalteExporter というクラスがあるので
これを利用してスクリプトを書きます。
from nbconvert import TemplateExporter
import nbformat
with open("D:/work/dockerTest/hello_world.ipynb", 'r') as f:
lines = f.readlines()
# ipynbをロードする
f = nbformat.reads("".join(lines), as_version=4)
# Cellの0番を取得
buff = []
for i in f.cells:
if i['execution_count']:
buff.append(i)
f.cells = buff
exporter = TemplateExporter(template_file=r"C:\reincarnation_tech\template\embed_markdown.tpl")
(body, resources) = exporter.from_notebook_node(f)
buff = [" " + x for x in body.split("\n") if x != ""]
print(buff)
変換したいipynbをまずOpenして、その文字列を nbformat.reads で読み込みます。 Fileから読むのではなく、urlopen を利用してURLからロードすることもできます。
nbformat.readsで読み込むと、ipynb情報のディクショナリを取得できます。
この cells が、
{% block markdowncell%}
{{cell.source}}
{% endblock markdowncell%}
テンプレートでの cell として展開されているもと情報です。
(テンプレートは cells の数分だけこのBlockを展開します)
buff = []
for i in f.cells:
if i['execution_count']:
buff.append(i)
print(i['source'])
なので、ipynbからPythonのスクリプト部分だけ抜き出したければ
こうすればコードだけを取り出すことができます。
exporter = TemplateExporter(template_file=r"C:\reincarnation_tech\template\embed_markdown.tpl")
(body, resources) = exporter.from_notebook_node(f)
最後に、 TempalteExporterで変換します。
この結果、 body に変換後のmarkdownの文字列が代入されます。
今回は markdown としていますが、TemplateExporterの場合は
tplファイルの構造通りに変換してくれるので
Pythonのテストコードを出力するTplとかを作れば、
TemplateExporterを使用することでかんたんに変換することができます。
マクロを作る
あとはテンプレートを書けばどうにでもなりそうなので、実験を兼ねてmkdocsのマクロを書いて
既存のmarkdownのページにNotebookの内容を展開できるようにします。
全コードはこちら。
@env.macro
def embedIpynb(ipynbPath, cells=None):
# 引数のipynbをmarkdownに変換して返す
path = os.getcwd() + "/" + ipynbPath # root以下からのPathで指定
if os.path.exists(path):
try:
with open(path, 'r') as f:
lines = f.readlines()
f = nbformat.reads("".join(lines), as_version=4)
if cells:
# 表示したいCellが指定されてる場合
showCells = cells
else:
# 指定がなければ全部表示
showCells = [int(x['execution_count']) for x in f.cells]
buff = []
for i in f.cells:
if i['execution_count']:
if int(i['execution_count']) in showCells:
buff.append(i)
f.cells = buff
exporter = TemplateExporter(template_file="template/embed_markdown.tpl")
(body, reources) = exporter.from_notebook_node(f)
buff = [" " + x for x in body.split("\n") if x != ""]
text = [f"!!! example \"{os.path.basename(ipynbPath)}\"",
*buff,
f" :fa-bookmark: [{os.path.basename(ipynbPath)}](https://github.com/fereria/reincarnation_tech/tree/master/{ipynbPath})"]
return "\n".join(text)
except:
return f"ConvertEerror!! ->{ipynbPath}"
else:
return f"Not Found -> {ipynbPath}"
埋め込み部分はこちら。

使うときは embedIpynb(ipyhnbPath,[1])

実行結果。
埋め込み用のテンプレートで指定のipynbを変換し、
いい感じの見た目になるように加工しています。
見た目をどうしようか迷ったのですが、
Detailを利用すると、Admonition をネストできるようになるので
これを利用していい感じに調整しました。
一部Cellのみ展開
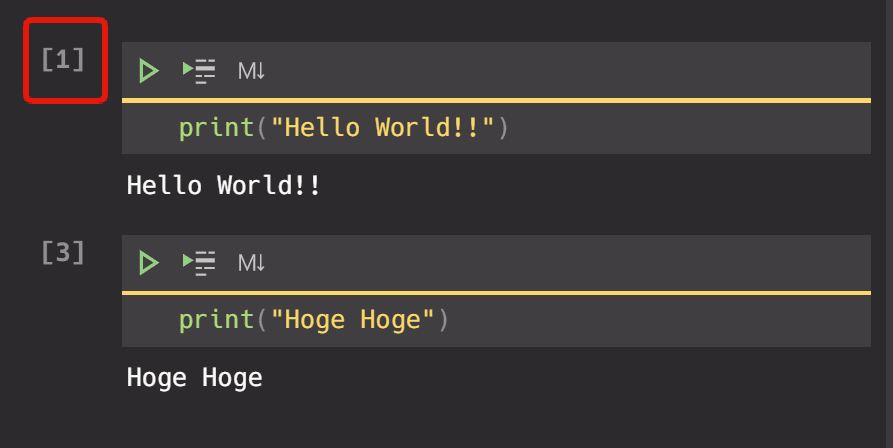
あとは、記事をMarkdownに埋め込みたいときは
コードはNotebookで書いて、記事は Markdownで書く...ということがやりたかったので
execution_count を指定することで、Notebookの一部のCellのみを展開できるようにしました。
エラーコードはコメントアウト
普通にMarkdownに展開するだけならこれでも良いですが
このNotebookのスクリプトがちゃんと動くかどうかテストしたい場合
あえてエラーをNotebookに残してる場合などはテストが都合が悪い気がする...
ということで、条件分岐をいれた版も用意します。
{% block input %}
{% if cell.outputs[0].output_type == 'error' %}
{{cell.source|comment_lines}}
{% else %}
{{cell.source}}
{% endif %}
Cellのステータスによって処理を変えたい場合は、テンプレートにif文を追加します。
ステータスは cell.outputs[0].output_type で取得できるので
その時は、変換時にコメントアウトを入れます。
フィルターとは、Jinjaの機能の1つで、 {{A|filter}} このように すると
Aの結果に対して、 filter の処理をしてくれるようになります。
これを利用して、comment_lines で、 cell.source をコメントアウトしておきます。
こうすると、Error担っている部分のコードは実行されません。
ただ、書いたあとに気がついたけど、テストなら output_typeに応じて
cell.sourceを実行して、ErrorかSuccessか取るようにすればよいかなと思います。
まとめ
今回の変更の結果、mkdocsのリポジトリにipynbをPushすれば
自動で変換されて
このページ以下に公開されるようになりました。
また、nbconvertを利用することでmkdocsのマクロでipynbをCell単位で埋め込みできるようになったので
かなりコードの記事をかくのが楽になりました。
TemplateExporter を使えば、Zenn用のテンプレートの構築も今回の記事の手順でなんとかなりそうです。
ので、今回の変更をふまえて次回はZenn+ipynbの記事更新と
Push時のPythonテスト、GithubAction周りに手を入れてみようとおもいます。
Discussion