
Hello! My name is Rodrigo Ramirez. I’m a Senior Engineer at ReiwaTravel.
I had the privilege of deciding the Tech Stack for NEWT's Backend and Front End, and I introduced GraphQL for communication between our clients and our backend systems.
In this blog, I will share the core principles and best practices we learned while designing our GraphQL schema for our web and mobile apps.
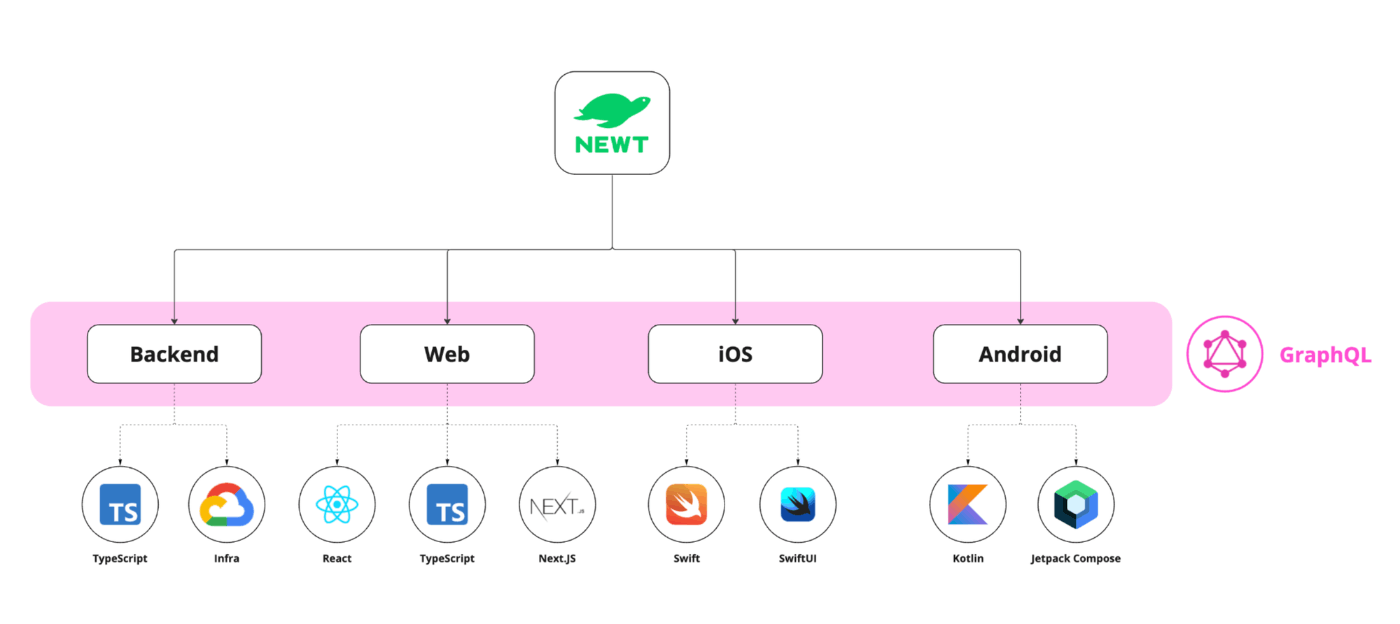
🧩 NEWT Stack
Here is a quick summary of the NEWT stack for each platform:
- Backend + Web: TypeScript
- Web: React + Next.JS
- iOS: Swift
- Android: Kotlin
- API Layer: GraphQL
🤔 Why GraphQL?
We compared some common options before selecting GraphQL. Here’s a summary of the criteria we considered:
Candidates
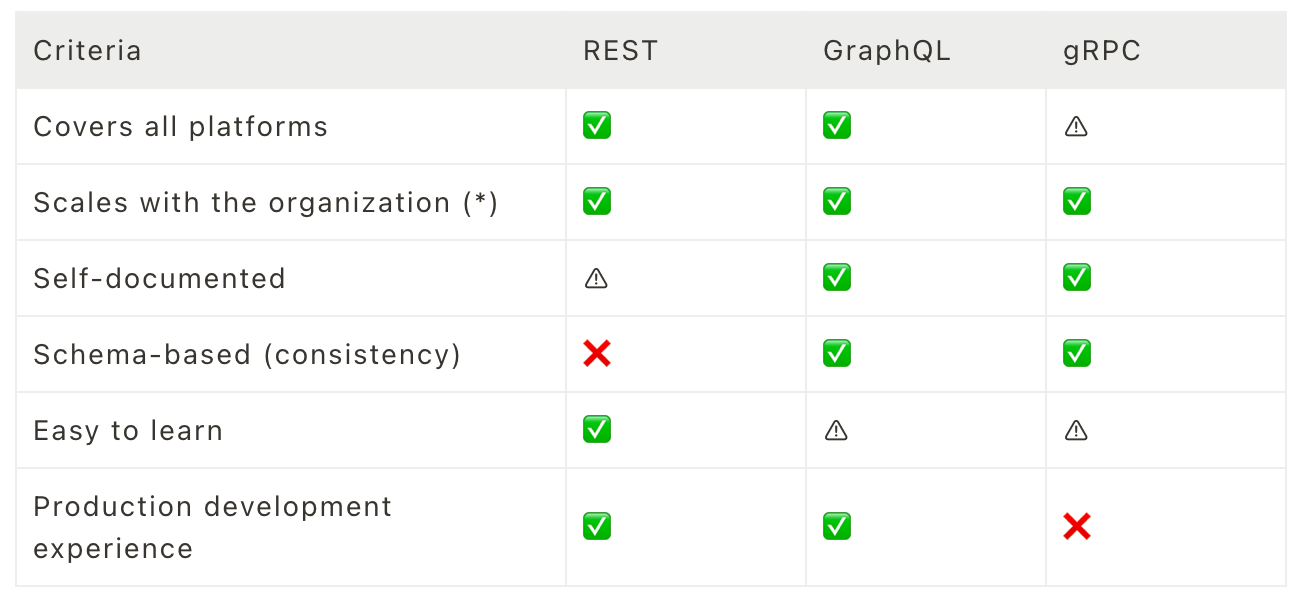
REST:
Simple to start but concerns over long-term endpoint maintainability.
GraphQL:
Met all our criteria. It has a slight learning curve, but maintaining a central schema benefits future scaling.
gRPC:
Requires a proxy for web compatibility.
🔥 GraphQL Schema Design Principles
The GraphQL principles we adopted at NEWT are:
- One Graph
- Demand-oriented schema design
🚪 1) One Graph
By having one graph, you maximize the value of GraphQL. The benefits include:
- Single Endpoint: Access more data and services from a single query.
- Central Data Catalog: A central catalog of all available data.
- Portability Across Teams: Code, queries, skills, and experience are portable across teams.
- Unified Access Control: Centralized graph management allows for unified access control policies.
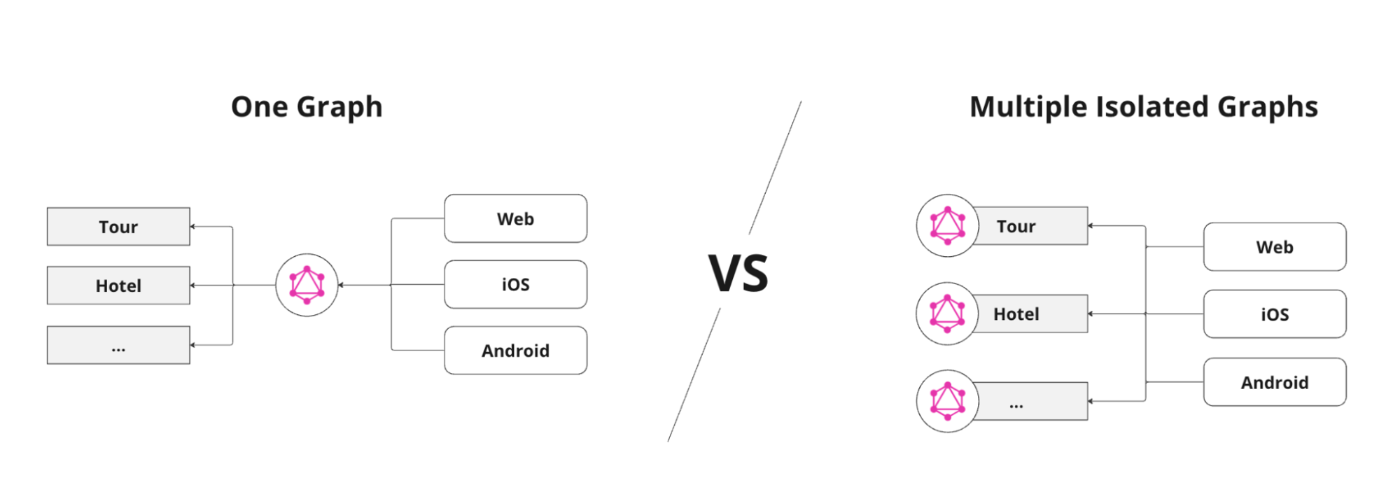
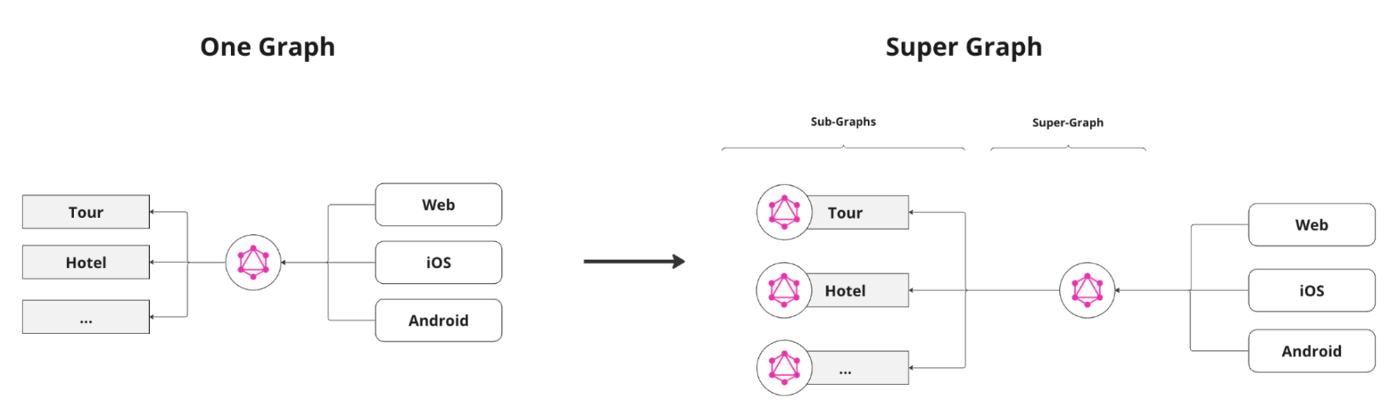
How to scale One Graph?
Different ways to scale GraphQL include:
Scaling GraphQL is primarily a backend implementation detail and does not affect clients since they continue to use a single entry point.
Ref:
🎯 2) Demand-oriented schema design
Demand-oriented design means designing your schema around client-side use cases. The benefits include:
Benefits:
- Simplified Schema
- Reduce Over-fetching
- Improved Developer Experience
- Easier to Understand and Maintain
- Reduce QA Costs
Key Points:
We apply three key points in this approach:
- ① Design schema around client-specific use cases
- ② Move the business logic to the backend
- ③ Close collaboration with client-side engineers
① Design Schema around client-specific use cases
Do not reflect your database in your schema; use a client-first approach. This means having more specific, finer-grained mutations and queries.
❌ Database → Schema
✅ Client Use Cases → Schema

An explanation about Client Use cases schema:
Type User
- Include only necessary fields used by clients.
-
created_a,updated_at,andcountry_idhave been removed, since clients do not need them.
-
- Use predictable values like
Enumtypes.- Gender is not a string anymore; we use the Enum type.
- Country returns a
Countrytype.
- Adapt fields around client use cases.
- If the client side always needs to display the full name of customers, a combined
fullNamefield is better than separatefirstNameandlastNamefields.
- If the client side always needs to display the full name of customers, a combined
Queries
- Focus on specific use cases rather than generic queries.
Mutations
- Tailored for each specific use case, like
signUpinstead ofcreateUser
② Move business logic to the Backend
Centralization of Business Logic
Implement essential logic on the server side, such as price calculations and language translations.
Reduced Client-Side Complexity
Client applications focus on presenting data rather than processing it.
Enhanced Security and Consistency
Centralizing business logic on the server reduces security risks and data handling inconsistencies.
Reduce QA cost
Specific test cases can be written on the backend, reducing QA costs for client implementations.
Examples:
Case #1: Hotel Card / Spoken Languages
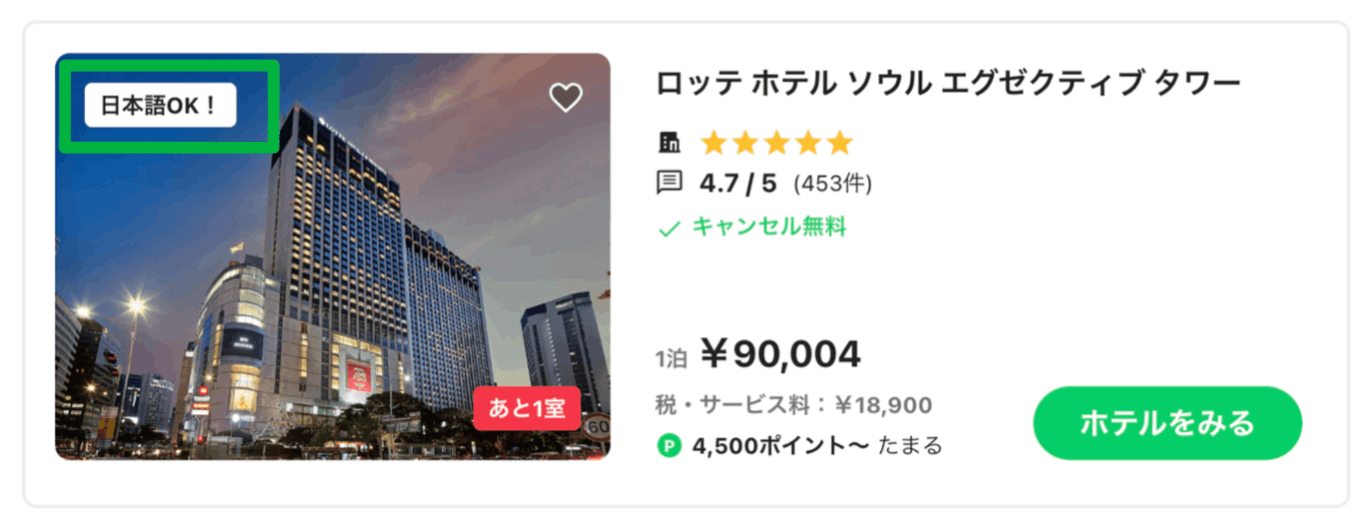

Before:
- Logic needs to be handled on each client (Web, iOS, Android)
- More data than needed is requested from the API
- QA cost increase to confirm implementation on each client
After:
- Logic is hidden on the backend
- Client implementation is simplified
- API tests can be written to confirm use cases
- QA cost decrease
Case #2: Hotel Card / Price
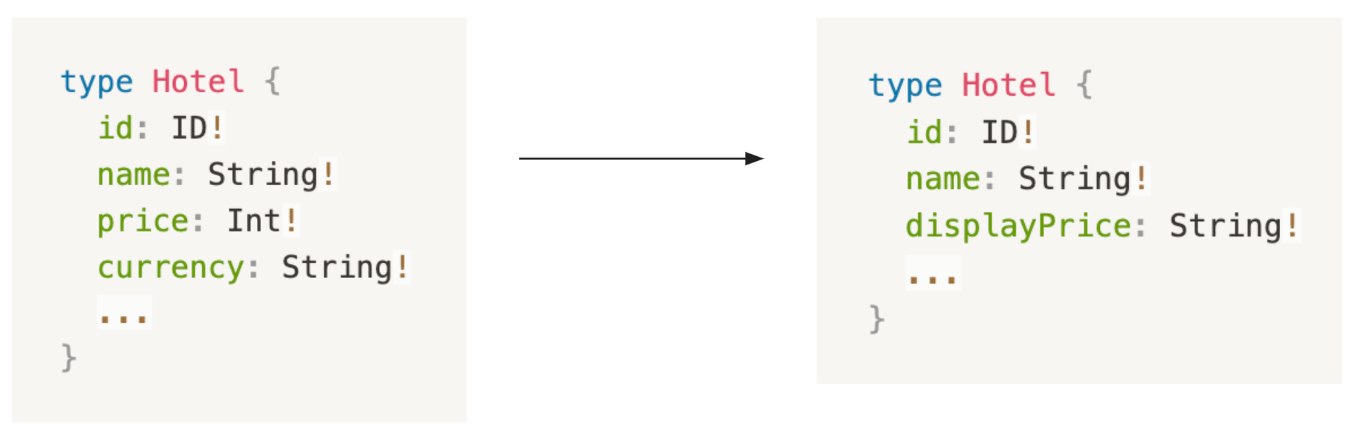
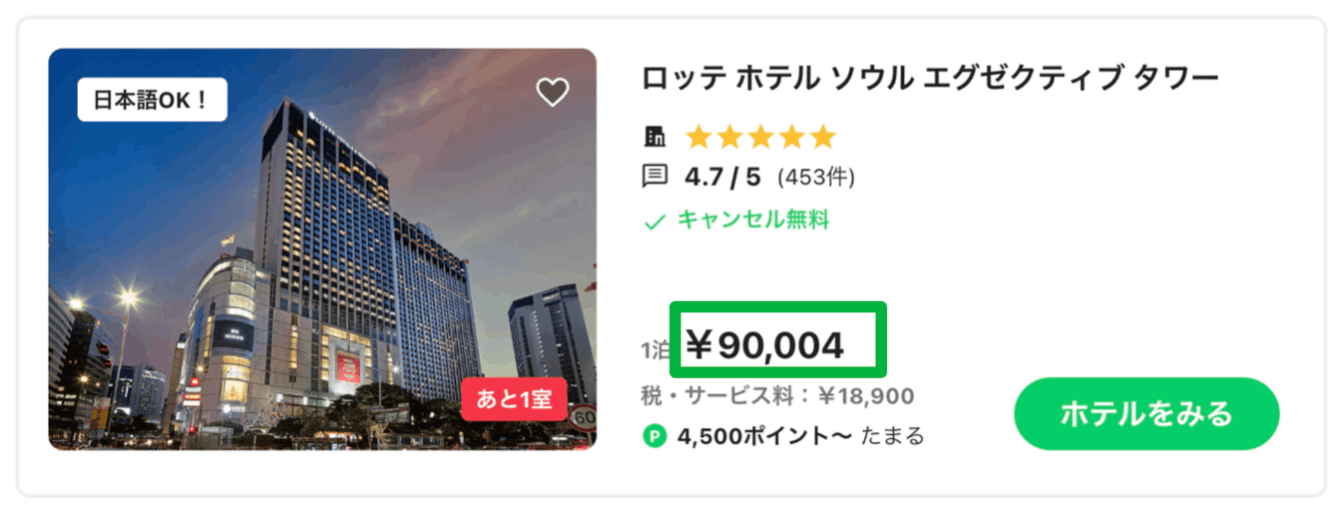
Before:
- The client depends on 2 fields to display the price
- The format needed to be coordinated between clients and places
- QA cost increase
After:
- Only one field is needed to display the price
- The Backend controls the format, and consistency between apps is simple
- QA cost decrease
Case #3: Hotel Card / Wishlist
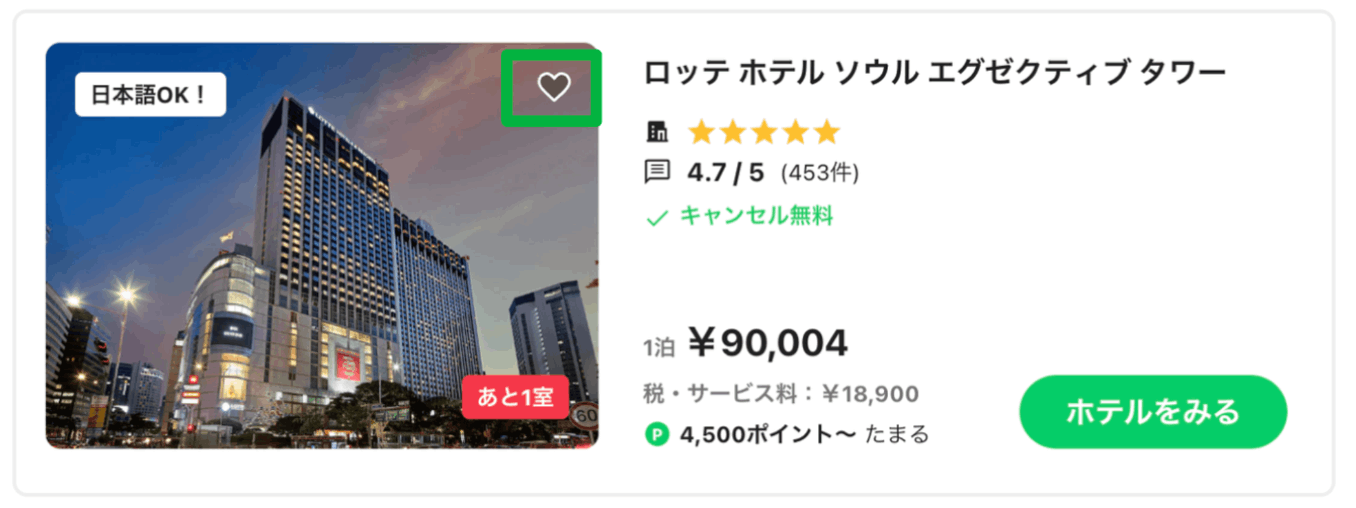
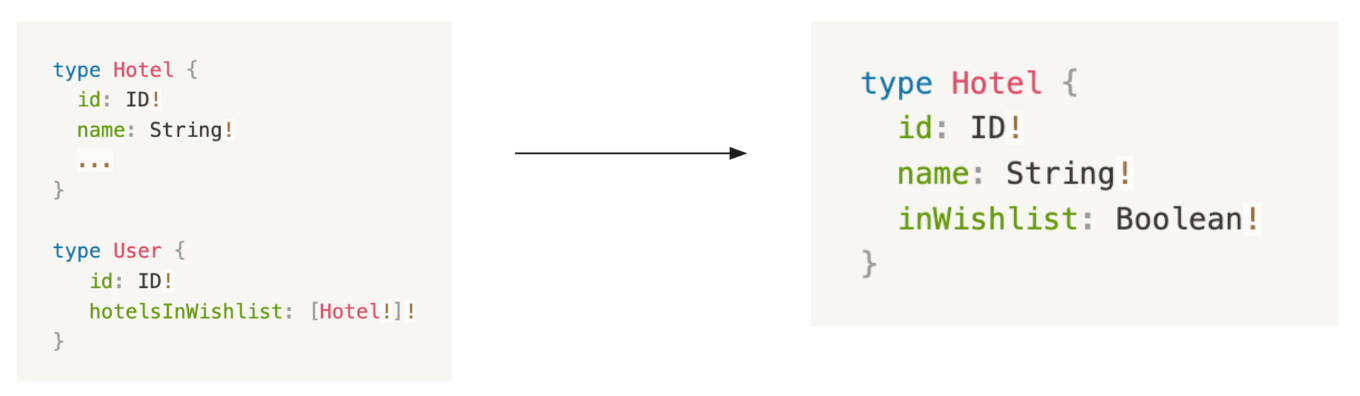
Before:
- To know if a Hotel is included inside the authenticated user Wishlist, a different query is needed
- The client needs to control the logic
- QA cost increase
After:
- Things that always need to be displayed together are together
- Client logic is simplified, and business logic is hidden on the backend
- QA cost decreases
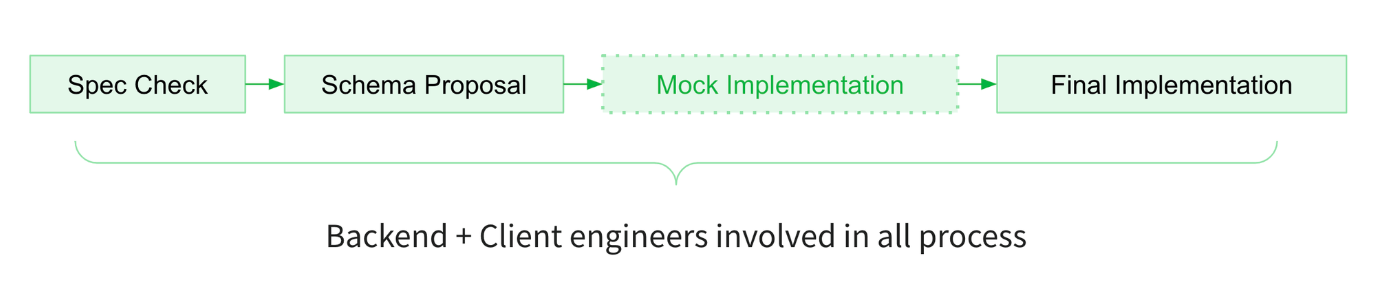
③ Close collaboration with Client-side engineers
- Prioritize client needs across all clients.
- Consult client teams early in the API design process.
- Client teams should approve the schema before implementation.
We discuss schema changes directly on a PR, which provides:
- Discussion history
- Recorded approval
- Improved schema comments based on discussions
Ref:
🧑🎓 Summary
One Graph:
- 1 schema, 1 endpoint.
Demand-Oriented Schema Design:
- Design based on client use cases.
- Reduce client-side complexity by moving business logic to the backend.
- Close collaboration with client-side engineers.
This blog summarizes the LT we did for NEWT Tech Talk vol.6, a monthly event held by ReiwaTravel; feel free to join online or offline!
令和トラベルでは、全ポジション、全力で仲間探しをしていますので、少しでもご興味ある方はぜひ採用ページからご連絡ください。まずは、気軽にお話を聞いていただけるミートアップも開催しています。メンバー全員で温かくお迎えいたしますので、ぜひご検討ください!
私たちが運営する海外旅行予約サービス、NEWTはこちらから。

令和トラベルのTech Blogです。 「あたらしい旅行を、デザインする。」をミッションに、旅行におけるあたらしい体験や、あたらしい社会価値の提供を目指すデジタルトラベルエージェンシーです。旅行アプリ「NEWT(ニュート)」を提供しています。(NEWT:newt.net/)
Discussion