はじめに
こんにちは、令和トラベルでバックエンドエンジニアをしている飯沼です。
MySQLでは、UUID (v4)などのランダム性の高いIDをプライマリキーに設定すると、パフォーマンスが低下すると言われています。私自身もこの問題については認識しておりアンチパターンとして避けて来ましたが、イマイチ理由を理解できず何度も調べていたので自分の理解を整理しました。
※ この記事は令和トラベルのTech LT会で共有した内容を記事にしたものです。社外の方にもご参加いただけるTech LT会は connpass にて告知しています。
UUIDをプライマリキーにするユースケース
そもそもUUIDをプライマリキーにするユースケースはどのようなものがあるのでしょうか?
いくつかの観点から考えてみます。
パフォーマンス観点
大量の同時書き込みが発生するような状況でauto incrementを利用してIDを発番すると、発番のための同期処理がボトルネックになることがあります。書き込み先を複数サーバに分散出来たとしても、どこか一箇所で1, 2, 3... と順序を保ったIDの発番が必要になり、そこがボトルネックになるということです。
衝突を気にしなくて良いUUID (v4)をIDに利用することで、こういった発番処理を排除したい、というのが理由です。
※ UUIDを使う以外にも対処方法はあって、例えばOracle Databaseでは一定の範囲のIDをまとめて発番する仕組みがあります。20件ずつ発番して、1-20は1台目のサーバ、21-40は2台目のサーバに割り当てる、という使い方です。
セキュリティ観点
例えば、連番のIDを利用して、それがURLなどにも表出するようなシステムの場合、以下のような問題が考えられます。
- 非公開のリソースのURLを推測される : https://example.com/resource/1000 というURLがあったら、1001, 1002, ... もあるのでは?と推測される。万が一アクセス制御に不備があった場合、推測されたリソースにアクセスされてしまう。
- カスタマー数、商品数、予約数などの重要指標が推測される : 最近追加された商品のURLが https://example.com/item/1000 なら、1,000件くらいの商品があるのでは?と推測される。
ランダム性の高いIDを利用することで、こういった推測を回避したい、というのが理由です。
前提1:MySQL (InnoDB) はクラスタインデックスを利用
なぜUUID (v4)をプライマリキーにするとパフォーマンスが低下するのか?その理由を理解するために、まずはMySQLのインデックスについて理解する必要があります。
MySQL (InnoDB) ではクラスタインデックスと呼ばれる構造を利用しており、プライマリキーと同じ順序でデータが格納されます。
Oracle Databaseのドキュメントが分かりやすかったので図を引用させて頂きます。
※ 「索引構成表」というのが「クラスタインデックス」のことです。
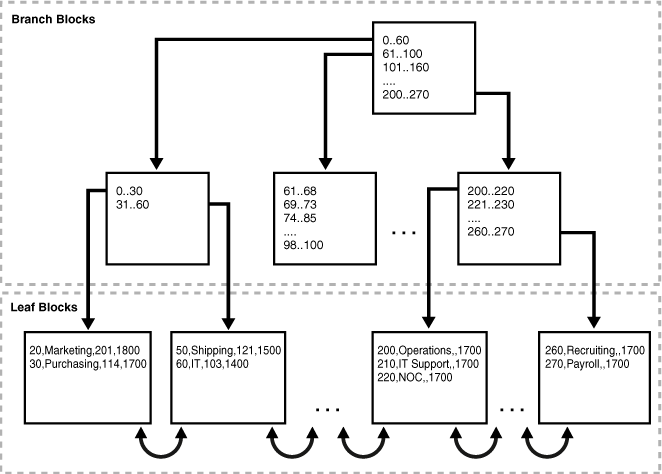
- インデックスにはBツリー(バランス・ツリー)が利用されています。
- クラスタインデックスは、末端のLeaf Blockにプライマリキーの順序でデータが格納されます。
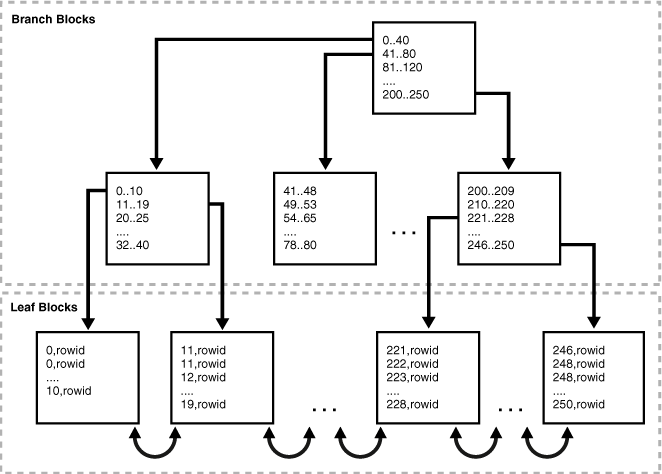
比べると分かりやすいので、クラスタインデックスじゃない構造のインデックスも紹介します。こちらもOracle Databaseのインデックスの内部構造ですが、Leaf Blockにはデータの代わりにROWIDというデータへのリファレンスが格納されます。
前提2:バッファプールの存在
MySQL (InnoDB) では、ディスクから読み込んだデータをメモリ上にキャッシュする仕組みがあります。これがバッファプールと呼ばれるもので、バッファプールを通してデータの読み書きをすることで処理速度を向上させています。
ここでポイントになるのがキャッシュの単位です。バッファプールにはページという16KBの単位でデータが格納され、1つのページには複数の行が格納できます。そして、クラスタインデックスの性質を踏まえると、ページ内はプライマリキーの順序でデータが格納されることになります。
参考:
結論:なぜUUID (v4)をプライマリキーにするとパフォーマンスが低下するのか?
ここまでで説明した性質をまとめると
- 行データはプライマリキーの順序で配置される
- 連続した行データを含むページ単位でメモリ上にキャッシュされる
つまり、連続性のあるIDを使うと直前に書き込んだページに再度書き込む確率が高くなり、キャッシュの恩恵を受けやすいということがわかります。
一方、ランダムなUUID (v4)をプライマリキーにすると、書き込み先がランダムなページになり、バッファプールのキャッシュがヒットせずディスクI/Oが増える、ということでした。
UUID (v4)の代替案
これを解決するために、UUID (v7)やULIDが提案されています。
UUID (v7)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | unix_ts_ms | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | unix_ts_ms | ver | rand_a | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |var| rand_b | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | rand_b | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 先頭48bitがタイムスタンプになっており、時系列順に生成することが出来ます。
- 残りの部分はUUID versionと疑似乱数のセクションで、ランダム性により衝突を回避できます。
ULID
01AN4Z07BY 79KA1307SR9X4MV3 |----------| |----------------| Timestamp Randomness 48bits 80bits
- UUID v7と同様に、タイムスタンプと疑似乱数を組み合わせてIDを生成します。
- 人間にとっての視認性が考慮されており、誤認しやすい
I,L,O,Uを除いたCrockford’s base32で表現され、UUIDよりも短い26桁になります。※ UUIDは32桁
まとめ
- クラスタインデックスを使うMySQL (InnoDB) でランダム性の高いIDをプライマリキーにすると、書き込み先のページがランダムになり、バッファプールのキャッシュがヒット率が低下し、性能劣化に繋がる。
- まずは、本当にランダム性の高いIDが必要かどうか良く考えましょう。複数サーバに分散して書き込むほどの規模でないならauto incrementで良いかもしれません。URLを推測できないものにしたければ、プライマリキーとは別カラムにランダムなIDを設定すれば良いかもしれません。
- もし本当に必要であれば、UUID (v7)やULIDを利用しましょう。
参考資料
- SQLパフォーマンス詳解
- MySQLでプライマリキーをUUIDにする前に知っておいて欲しいこと:UUID(v1)でも順序を担保した保存方法を紹介されています。
- MySQLとPostgreSQLと主キー:UUIDをchar(32), binary(16)で保存したケースをベンチマークで比較されています。
- MySQLでもULIDを発行した〜い!ので検証してみた:MySQLのFunctionでULIDを発行する方法を紹介されています。
最後にちょっとだけ宣伝させてください 🙏
令和トラベルでは定期的にTech LT会などの勉強会やイベントを開催していく予定です。2/20(火)は 19:30〜 タイミーさん、VoicyさんとBackendに関する合同イベントを開催しますので、ぜひご参加ください。

令和トラベルのTech Blogです。 「あたらしい旅行を、デザインする。」をミッションに、旅行におけるあたらしい体験や、あたらしい社会価値の提供を目指すデジタルトラベルエージェンシーです。旅行アプリ「NEWT(ニュート)」を提供しています。(NEWT:newt.net/)
Discussion