はじめに
こんにちは
株式会社Rehab for JAPAN開発2部データプラットフォームチームの
データエンジニア のすです。
記事を書くにあたっての背景
私は、普段業務で弊社のデータ基盤である「CDP(Care Data Platform:以降CDPとする)」の設計、開発、運用、保守、構築、可視化などをしています。
データ基盤の改善を目的に、新技術「dbt」を導入し、その過程と効果を紹介。導入の背景にはデータサイエンスチームからの要望があり、メンテナンス性や運用性の向上を図る。試験的に「dbt-core」を使用し、実行例やテスト結果を詳述。これにより、他のエンジニアにもdbtの利便性を伝えるために記事を書きました。
ターゲット
以下の項目に当てはまるデータエンジニアやその関係者様
-
データ分析基盤の構築やパイプラインの見直したい
-
メタデータの管理方法を楽にしたい
-
データ基盤のメンテナンス性、保守性などを見直したい
-
dbtの導入したい
要約
dbt(data build tool)はデータ基盤のETLにおけるTransform部分を担うツールで、データエンジニアにとってメンテナンス性や運用性、保守性、テストのしやすさを向上させるため試験的に利用を開始しました。自社のデータ基盤「CDP」の改善を目指し、初めてのdbt導入を試み、無料の「dbt-core」を利用しました。介護事業向けプロダクトのデータ基盤を支えるために、BigQueryやCloud Buildなどの周辺技術も活用しています。本記事では、dbtを使った具体的な実行例やメタデータ管理、テストの手順を詳しく紹介しています。この記事を通じて、初心者向けにdbtの利便性と効果的な活用方法が伝わればと思います。
データエンジニア界隈で何かと話題になる「dbt」
正式名称は「data build tool」と言われているらしい。
データ基盤でよく出てくるETLにおけるTの部分を担う。
ETLについてそれぞれの概要は以下となるExtract(抽出)Transform(変換)Load(読み込み)なんかのアプリケーションで入力されたデータを収集し一つのデータベースに集める。その後分析したい形に変換を行い読み込みを行うなどといった形だ。
さてなぜそんなに話題になっているのだろうか?
私も自社内で初めてdbtを導入をした。
というのも自社のデータ基盤はまだできて1年半が経過したくらいで、データエンジニアも私が社内で1人目の社員となります。そのため新たな技術が導入しやすい環境です。
dbtを採用したきっかけ
1人目のデータエンジニアとして一番大事なデータ基盤のこれからを考えこれまでのデータ基盤の構築や開発の経験から「メンテナンス性や運用性・保守性・テストのしやすさ」の部分を意識して構築と開発に重点を置くことにし採用しました。
データ基盤を日々いじる中でデータサイエンスの方々と関わる機会もかなり多い。スタートアップならではなのがすぐ隣に分析チームがいること。そのおかげですぐにデータ基盤の要件や設計に反映することができます。
そんないつも飛び交う意見の中で「dbtってどうなんだろう?使いやすいのか?」というデータサイエンスチームの方からの声がありました.
また、私が入社する2年前にSlack内で弊社のCEO大久保も「dbtってめちゃめちゃうちのデータ基盤作る上で大事なんじゃないか?」みたいなスレッドが一瞬だがありました。
当時の記事、、2022年1月末なのでおよそ2年前、、

さすがCEO感度と先見性がすごい(笑)
そんな話が上がっていたため「これはもう試しに導入してみてダメならやめよう!!」というある種の挑戦でdbtを導入してみました。
私自身もdbtを触るのは初めてでした、色々触っているうちにかなり便利そうということがわかってきました。
dbtには2種類ある?
ところでdbtには2種類ある。有料で使う「dbt cloud」と無料で使う「cliベースのdbt-core」だ。
有料の方は一人当たりおよそ50$/月という金額だ。結構高い。。
まずはお試しということも兼ねてるから「dbt-core」で使うことにしました。
CDPとは?
弊社のデータ基盤について紹介をしておきます。弊社は介護事業所向けにプロダクトを開発しているスタートアップの企業です。メインのプロダクト開発に加えてデータ基盤も持ち合わせています。それがCDPです。
弊社の構想として科学的介護をし利用者様・事業所の皆様がより楽にリハビリや業務にあたれるようにデータ基盤を活用しプロダクトの改善をします。
また弊社の匿名加工基盤では弊社のプロダクトから得たデータを第三者へ提供できるように個人情報が再識別できないように匿名加工したデータの基盤の開発もしています。
以下が匿名加工基盤のプレスリリース記事となります。
今回その匿名加工基盤の開発で利用し始めた「dbt」についてご紹介します。
会社紹介資料でも以下画像を確認できます。
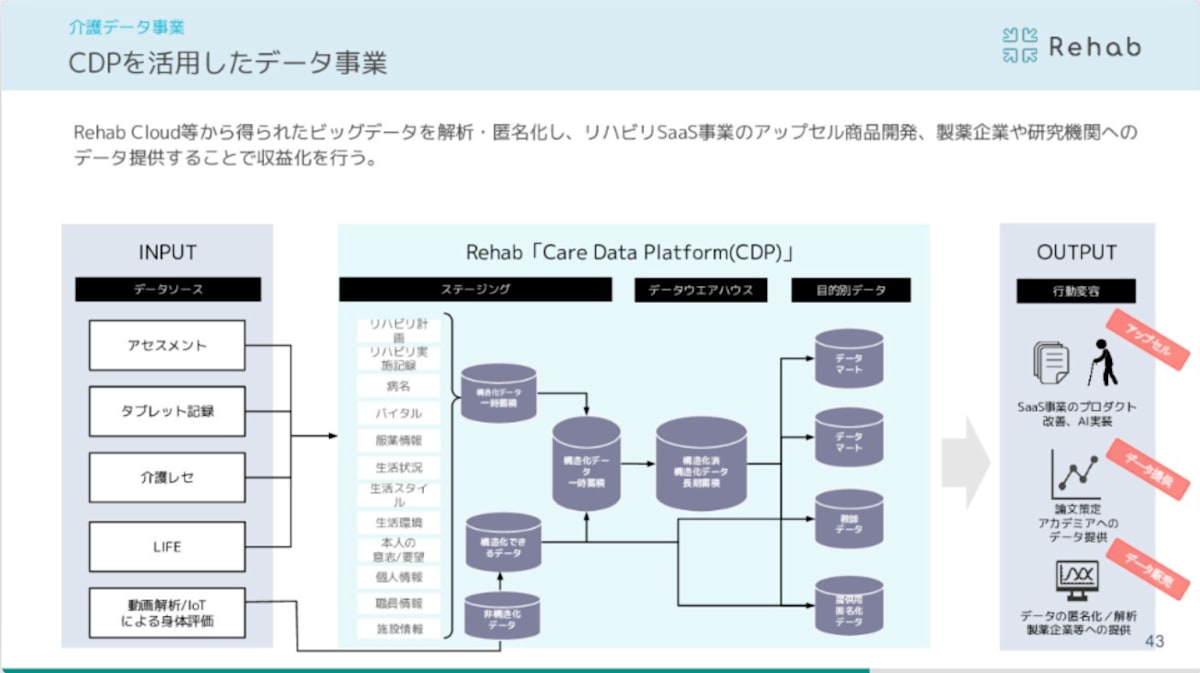
周辺技術について
さて、弊社のdbtの実行環境やそれに関する周辺技術をまずは知ってもらいたいです。(一部抜粋)
| 技術名 |
|---|
| BigQuery |
| Cloud Build |
| CloudComposer(AirFlow) |
| Looker Studio |
| Vertex AI |
dbtで使用しているライブラリ
| ライブラリ名 | 用途など |
|---|---|
| dbt-core | dbtの根幹の処理 |
| dbt-osmosis | BigQueryのデータセット名、単体テスト、カラムのディスクリプション |
これが今現在弊社で採用しているライブラリです。
dbtの効果的な使い方および利用方法について解説します。初心者でも一から触れるような記事にしております。
今回記事用に「test」というモデルを作成
# ディレクトリ構造
プロジェクト名
〜
省略
〜
├──
├── macros
models
├── [モデル名1]
│ ├── テーブル名.sql
├── [モデル名2]
├── [モデル名3]
└── test → 今回記事用で作成したモデル名
│ └── test.sql → 今回記事用で作成したSQL
〜
省略
〜
├── target
├── dbt_project.yml
├── profiles.yml
実行用のSQLとして「test.sql」を作成
//test.sql
{{ config(schema=generate_schema_name("test")) }} //→ どこのデータセットに作るか(マクロになります。)
SELECT * FROM `プロジェクト名.test.test_table`
test_tableを作成
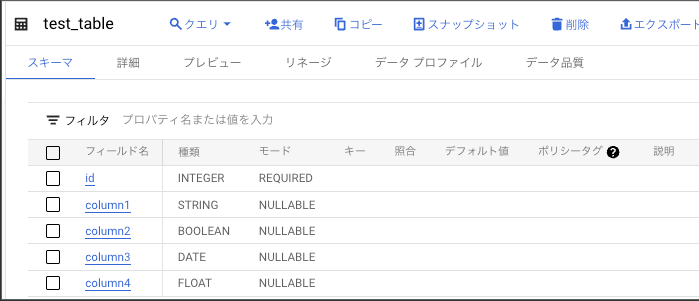
実際にこのテーブルに対してdbt runを実行する。
$ dbt run --models "test"
14:00:09 Running with dbt=1.6.0
14:00:10 Registered adapter: BigQuery=1.6.0
14:00:10 Found 62 models, 357 tests, 33 sources, 0 exposures, 0 metrics, 616 macros, 0 groups, 0 semantic models
14:00:10
14:00:13 Concurrency: 4 threads (target='profiles.ymlに記載のターゲット')
14:00:13
14:00:13 1 of 1 START sql table model test.test ......................................... [RUN]
14:00:16 1 of 1 OK created sql table model test.test .................................... [CREATE TABLE (0.0 rows, 0 processed) in 3.17s]
14:00:16
14:00:16 Finished running 1 table model in 0 hours 0 minutes and 5.40 seconds (5.40s).
14:00:16
14:00:16 Completed successfully
14:00:16
14:00:16 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
実行結果として、、
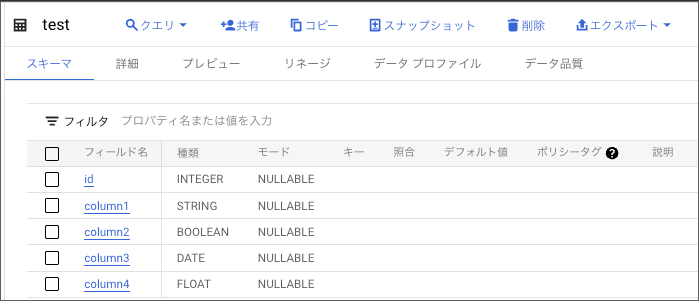
さらに、、メタデータ管理に便利な「dbt-osmosis」を使ってみます。
#dbt_project.yml
models:
dbtプロジェクト名:
test:
+materialized: table
+dbt-osmosis: 'test_metadata/{model}.yml'
schema: test
models配下に「test_metadataディレクトリ」を作成し以下のように書いておきます。
# test.yml
version: 2
models:
- name: test
現在のtestのディレクトリ構造
〜
省略
〜
models/test
├── test.sql
└── test_metadata → メタデータ管理ディレクトリ
└── test.yml
〜
省略
〜
この状態でコマンドを実行すると、、、
$ dbt-osmosis yaml refactor models/test
INFO 🌊 Executing dbt-osmosis main.py:170
INFO 📈 Searching project stucture for required updates and building action plan osmosis.py:567
INFO ...building project structure mapping in memory osmosis.py:455
INFO 🥇 Project structure approved osmosis.py:601
INFO ...building project structure mapping in memory osmosis.py:455
INFO 👉 Processing model: model.dbtプロジェクト名.test osmosis.py:814
INFO 🔍 Resolving columns in database osmosis.py:825
INFO 🔬 Looking for actions for model.dbtプロジェクト名.test osmosis.py:1051
INFO 💉 Injecting column column3 into dbt schema for model model.dbtプロジェクト名.test osmosis.py:1037
INFO 💉 Injecting column id into dbt schema for model model.dbtプロジェクト名.test osmosis.py:1037
INFO 💉 Injecting column column2 into dbt schema for model model.dbtプロジェクト名.test osmosis.py:1037
INFO 💉 Injecting column column1 into dbt schema for model model.dbtプロジェクト名.test osmosis.py:1037
INFO 💉 Injecting column column4 into dbt schema for model model.dbtプロジェクト名.test osmosis.py:1037
INFO 🔧 Reordering columns in schema file for model model.dbtプロジェクト名.test osmosis.py:890
INFO ✨ Schema file /自身のパス/dbtプロジェクト名/models/test/test_metadata/test.yml updated osmosis.py:910
(dbt-test)
実行結果は、以下のようになります!!自動でカラムがymlに反映されました。
# test.yml
version: 2
models:
- name: test
columns:
- name: id
description: ''
- name: column1
description: ''
- name: column2
description: ''
- name: column3
description: ''
- name: column4
description: ''
そしてカラムにプラスしてディスクリプションもついています。ちょっと使ってみましょう。
「column1」のディスクリプションを「テスト作成用」としてみます。
反映させる時は再度「dbt run」によりテーブルを作り直す必要があります。
そうするとあら不思議BigQueryのテーブルにも反映されました。
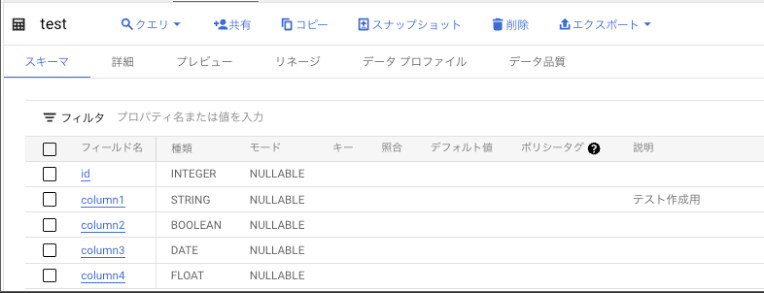
そして
「このymlファイルまだ何かに使えないか?」 とふと思い公式ドキュメントをみるとこのymlにテストも書くことができるらしい。かなり便利!!と言うことでやってみます。
試しにデータを10レコード用意します。
以下のように「cloumn1」にだけテストを施してみます。今回はcolumn1のデータに対して「データ1とデータ2以外はデータとしては認められない」と言うテストをしてみます。
# test.yml
version: 2
models:
- name: test
columns:
- name: id
description: ''
- name: column1
tests:
- accepted_values:
values: ["テスト1","テスト2"]
description: 'テスト作成用'
- name: column2
description: ''
- name: column3
description: ''
- name: column4
description: ''
テストの結果「FAIL 6」と出ました。いい感じです。
$ dbt test --models "test"
15:08:13 Running with dbt=1.6.0
15:08:13 Registered adapter: BigQuery=1.6.0
15:08:14 Found 62 models, 358 tests, 34 sources, 0 exposures, 0 metrics, 616 macros, 0 groups, 0 semantic models
15:08:14
15:08:15 Concurrency: 4 threads (target='anonymised')
15:08:15
15:08:15 1 of 1 START test accepted_values_test_column1___1___2 ......................... [RUN]
15:08:17 1 of 1 FAIL 6 accepted_values_test_column1___1___2 ............................. [FAIL 6 in 1.69s]
15:08:17
15:08:17 Finished running 1 test in 0 hours 0 minutes and 3.07 seconds (3.07s).
15:08:17
15:08:17 Completed with 1 error and 0 warnings:
15:08:17
15:08:17 Failure in test accepted_values_test_column1___1___2 (models/test/test_metadata/test.yml)
15:08:17 Got 6 results, configured to fail if != 0
15:08:17
15:08:17 compiled Code at target/compiled/dbtプロジェクト名/models/test/test_metadata/test.yml/accepted_values_test_column1___1___2.sql
15:08:17
15:08:17 Done. PASS=0 WARN=0 ERROR=1 SKIP=0 TOTAL=1
(dbt-test)
テストデータを入れ替えてみましょう。今度は対象のデータのみです。
今回は想定通りテストが成功しました。
$ dbt test --models "test"
15:13:32 Running with dbt=1.6.0
15:13:33 Registered adapter: BigQuery=1.6.0
15:13:33 Found 62 models, 358 tests, 34 sources, 0 exposures, 0 metrics, 616 macros, 0 groups, 0 semantic models
15:13:33
15:13:36 Concurrency: 4 threads (target='anonymised')
15:13:36
15:13:36 1 of 1 START test accepted_values_test_column1___1___2 ......................... [RUN]
15:13:37 1 of 1 PASS accepted_values_test_column1___1___2 ............................... [PASS in 1.80s]
15:13:37
15:13:37 Finished running 1 test in 0 hours 0 minutes and 4.60 seconds (4.60s).
15:13:38
15:13:38 Completed successfully
15:13:38
15:13:38 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
(dbt-test)
まとめ
一通りdbtの使い方、メタデータ管理の仕方、テストの仕方を記事にさせていただきました。
メタデータ管理からのテストもできてしまうとはかなり楽だと思いませんか??
今回は一つのテーブルでしたが、これがいくつもあり、モデルの数も多いとなるとこのテストはかなり便利だと感じます。
ほんの一部のみをご紹介させていただきました。dbtにはまだまだ素晴らしい部分がたくさんあります。
ぜひ皆さんも一度試していただくとその凄さがわかるかと思います。
Rehabではエンジニアの採用募集してます!
CDPのデータ基盤はできて間もないため、新しい技術やあなたの意見が取り入れやすい環境です。単なるデータ基盤ではなく、利用者様や介護領域への業界を変革する一つのリソースとなりうる基盤なため業界の変化を楽しみながら基盤構築に携わることが可能です。データ基盤の開発を通して社会課題に向き合いたい方歓迎です!

Discussion