
はじめに
はじめまして!Rehab for Japanでデータアナリストをしている松村です。
近年、データドリブンな意思決定の重要性が増す中で、企業や組織においてデータの有効活用が求められていますが、私たちのチームにおいても、オープンデータを活用することで、業務の改善や新たなビジネスチャンスの発見につなげたいという意識が高まっています。
そこで、今回は試験的に政府の統計データを使用し、データの可視化に挑戦してみることにしました。
ターゲット
データ分析やオープンデータの活用に興味がある方に読んで頂けたら幸いです。
要約
この記事では、政府統計の総合窓口であるe-StatからAPIを通じて国民健康・栄養調査データを取得し、高齢者のBMIの推移を可視化するプロセスと、得られた結果からどのようなインサイトが得られるのかについて考察します。
政府統計データ
今回使用する統計データはe-Statから取得します。e-Statは、日本の統計が閲覧できる政府統計ポータルサイトです。
政府統計の総合窓口(e-Stat)は、各府省情報化統括責任者(CIO)連絡会議で決定された「統計調査等業務の業務・システム最適化計画」に基づき、日本の政府統計関係情報のワンストップサービスを実現するため2008年から本運用を開始した政府統計のポータルサイトです。各府省等が実施している統計調査の各種情報をこのサイトからワンストップで提供することを目指し、各府省等が公表する統計データ、公表予定、新着情報、調査票項目情報などの各種統計情報をインターネットを通して利用いただくことができます。
e-Statでは開発者向けにAPI機能も提供されています。APIを利用するために、e-Statのユーザ登録を行いアプリケーションIDを取得している必要があります。開発ガイドやAPIの使い方などが公開されているので、参考にしてみてください。
可視化するデータの選定
e-Statでは、例えば人口統計、経済指標などに関する豊富なデータセットを提供しています。
今回は国民健康・栄養調査からBMIの状況 - 年齢階級,肥満度(BMI)別,人数,割合 - 総数・男性・女性,15歳以上〔妊婦除外〕のデータを取得して可視化してみたいと思います。
国民健康・栄養調査は、健康増進法に基づき、国民の身体の状況、栄養素等摂取量及び生活習慣の状況を明らかにし、国民の健康増進の総合的な推進を図るための基礎資料を得ることを目的として、毎年実施しています。
APIを通じたデータ取得
まず、API経由でデータを取得します。
パラメータにはアプリケーションIDと、取得したいデータの統計表表示IDを指定します。
import requests
import pandas as pd
# e-Stat APIのエンドポイント
api_endpoint = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# アプリケーションID
app_id = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# APIリクエストのパラメータ
params = {
"appId": app_id,
"lang": "J",
# 統計表表示 ID
"statsDataId": "0003224180",
}
# APIリクエストの実行
response = requests.get(api_endpoint, params=params)
# JSON形式でデータを取得
data = response.json()
取得データの確認
次に、取得したデータのメタ情報をから、どのようなデータが格納されているのか確認します。
data["GET_STATS_DATA"]["STATISTICAL_DATA"]["CLASS_INF"]["CLASS_OBJ"]
出力結果
[{'@id': 'tab',
'@name': '表章項目',
'CLASS': [{'@code': '100', '@name': '人数', '@level': '', '@unit': '人'},
{'@code': '140', '@name': '割合', '@level': '', '@unit': '%'}]},
{'@id': 'cat01',
'@name': '肥満度(BMI)',
'CLASS': [{'@code': '100', '@name': '総数', '@level': '1'},
{'@code': '110', '@name': 'やせ_18.5未満', '@level': '2', '@parentCode': '100'},
{'@code': '120',
'@name': '普通_18.5以上25未満',
'@level': '2',
'@parentCode': '100'},
{'@code': '130', '@name': '肥満_25以上', '@level': '2', '@parentCode': '100'},
{'@code': '140', '@name': '(再掲)20以下', '@level': '1'},
{'@code': '150', '@name': '(再掲)25以上30未満', '@level': '1'},
{'@code': '160', '@name': '(再掲)30以上', '@level': '1'}]},
{'@id': 'cat02',
'@name': '年齢階級',
'CLASS': [{'@code': '100', '@name': '総数', '@level': '1'},
{'@code': '140', '@name': '15歳-19歳', '@level': '2', '@parentCode': '100'},
{'@code': '160', '@name': '20歳-29歳', '@level': '2', '@parentCode': '100'},
{'@code': '170', '@name': '30歳-39歳', '@level': '2', '@parentCode': '100'},
{'@code': '180', '@name': '40歳-49歳', '@level': '2', '@parentCode': '100'},
{'@code': '190', '@name': '50歳-59歳', '@level': '2', '@parentCode': '100'},
{'@code': '210', '@name': '60歳-69歳', '@level': '2', '@parentCode': '100'},
{'@code': '220', '@name': '70歳以上', '@level': '2', '@parentCode': '100'},
{'@code': '270', '@name': '(再掲)20歳以上', '@level': '1'},
{'@code': '330', '@name': '(再掲)20歳-69歳', '@level': '1'},
{'@code': '370', '@name': '(再掲)40歳-69歳', '@level': '1'},
{'@code': '460', '@name': '(再掲)65歳以上', '@level': '1'},
{'@code': '470', '@name': '(再掲)65歳-69歳', '@level': '1'},
{'@code': '490', '@name': '(再掲)70歳-74歳', '@level': '1'},
{'@code': '510', '@name': '(再掲)75歳-79歳', '@level': '1'},
{'@code': '520', '@name': '(再掲)80歳-84歳', '@level': '1'},
{'@code': '540', '@name': '(再掲)80歳以上', '@level': '1'},
{'@code': '550', '@name': '(再掲)85歳以上', '@level': '1'}]},
{'@id': 'cat03',
'@name': '性別',
'CLASS': [{'@code': '100', '@name': '総数', '@level': '1'},
{'@code': '110', '@name': '男性', '@level': '2', '@parentCode': '100'},
{'@code': '120', '@name': '女性', '@level': '2', '@parentCode': '100'}]},
{'@id': 'time',
'@name': '時間軸(年次)',
'CLASS': [{'@code': '2019000000', '@name': '2019年', '@level': '1'},
{'@code': '2018000000', '@name': '2018年', '@level': '1'},
{'@code': '2017000000', '@name': '2017年', '@level': '1'},
{'@code': '2016000000', '@name': '2016年', '@level': '1'},
{'@code': '2015000000', '@name': '2015年', '@level': '1'},
{'@code': '2014000000', '@name': '2014年', '@level': '1'},
{'@code': '2013000000', '@name': '2013年', '@level': '1'},
{'@code': '2012000000', '@name': '2012年', '@level': '1'},
{'@code': '2011000000', '@name': '2011年', '@level': '1'},
{'@code': '2010000000', '@name': '2010年', '@level': '1'}]}]
メタ情報を確認すると、各項目が表しているものは以下のようになっているようです。
tab: 表章項目
cat01: 肥満度(BMI)
cat02: 年齢階級
cat03:性別
統計数値(セル)の情報を確認して、実際の数値データを見てみます。
df = pd.DataFrame(data["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"])
df.head()
@unitに単位が入っていて、$に実際の数値が入っています。

データの前処理
年次ごとのBMIの状況推移グラフに描画するために、データを加工します。
df = df[df["$"]!="-"].copy()
df['$'] = df['$'].astype(float)
df['$'] = df['$'].astype(int)
df.loc[df["@tab"]=="100", "表彰項目"] = "人数"
df.loc[df["@tab"]=="140", "表彰項目"] = "割合"
df.loc[df["@cat01"]=="100", "BMI"] = "総数"
df.loc[df["@cat01"]=="110", "BMI"] = "under 18.5"
df.loc[df["@cat01"]=="120", "BMI"] = "18.5 - 25"
df.loc[df["@cat01"]=="130", "BMI"] = "over 25"
df.loc[df["@cat02"]=="100", "年齢階級"] = "総数"
df.loc[df["@cat02"]=="160", "年齢階級"] = "20歳-29歳"
df.loc[df["@cat02"]=="140", "年齢階級"] = "15歳-19歳"
df.loc[df["@cat02"]=="160", "年齢階級"] = "20歳-29歳"
df.loc[df["@cat02"]=="170", "年齢階級"] = "30歳-39歳"
df.loc[df["@cat02"]=="180", "年齢階級"] = "40歳-49歳"
df.loc[df["@cat02"]=="190", "年齢階級"] = "50歳-59歳"
df.loc[df["@cat02"]=="210", "年齢階級"] = "60歳-69歳"
df.loc[df["@cat02"]=="220", "年齢階級"] = "70歳以上"
df.loc[df["@cat03"]=="100", "性別"] = "総数"
df.loc[df["@cat03"]=="110", "性別"] = "男性"
df.loc[df["@cat03"]=="120", "性別"] = "女性"
df["年"] = df["@time"].str[:4]
df['年'] = pd.to_datetime(df['年'])
今回は70歳以上の高齢者の各BMIのカテゴリに属する男女別人数データを取得して、可視化します。
# 人数データのみを取得
plot_df = df[df["表彰項目"]=="人数"].copy()
# 総数は使わないので除外
plot_df = plot_df[plot_df["BMI"]!="総数"]
plot_df = plot_df[plot_df["性別"]!="総数"]
plot_df = plot_df[plot_df["BMI"].notna()]
plot_df = plot_df[plot_df["年齢階級"]=="70歳以上"]
# 年次と性別毎にBMIの階級の割合を計算
plot_df['total'] = plot_df.groupby(["年", "性別"])['$'].transform('sum')
plot_df['rate'] = plot_df['$'] / plot_df['total']
plot_df.head()
データを加工した結果

データの可視化
BMIの状況推移をグラフに描画します。
fig = make_subplots(specs=[[{"secondary_y": True}]])
# 男女別にデータを取得
plot_male = plot_df[plot_df["性別"]=="男性"]
plot_female = plot_df[plot_df["性別"]=="女性"]
# BMI状況別にデータを取得
plot_1 = plot_df[plot_df["BMI"]=="under 18.5"]
plot_2 = plot_df[plot_df["BMI"]=="18.5 - 25"]
plot_3 = plot_df[plot_df["BMI"]=="over 25"]
# BMI状況のバーチャートを作成
bar_trace_1 = go.Bar(x=plot_1["年"], y=plot_1["$"], name='under 18.5', opacity=0.8)
bar_trace_2 = go.Bar(x=plot_2["年"], y=plot_2["$"], name='18.5 -25', opacity=0.8)
bar_trace_3 = go.Bar(x=plot_3["年"], y=plot_3["$"], name='over 25', opacity=0.8)
# BMIが18.5未満のパーセンテージを示すラインチャートを作成
plot_4 = plot_male[plot_male["BMI"]=="under 18.5"]
plot_5 = plot_female[plot_female["BMI"]=="under 18.5"]
# BMIが18.5未満の
line_trace1 = go.Scatter(x=plot_4["年"],
y=plot_4["rate"]*100,
name='male under 18.5 rate',
mode='lines+markers')
line_trace2 = go.Scatter(x=plot_5["年"],
y=plot_5["rate"]*100,
name='female under 18.5 rate',
mode='lines+markers')
# 左軸としてバーチャートを追加
fig.add_trace(bar_trace_1)
fig.add_trace(bar_trace_2)
fig.add_trace(bar_trace_3)
# 右軸としてラインチャートを追加
fig.add_trace(line_trace1, secondary_y=True)
fig.add_trace(line_trace2, secondary_y=True)
# レイアウトの設定
fig.update_layout(
title=dict(text=f'Transition of Male BMI',
font=dict(size=18,color='grey'),
),
width=800,
height=500,
xaxis = dict(
title="year",
dtick = "M12"
),
yaxis = dict(
title="number of people",
),
yaxis2=dict(
title='percentage',
overlaying='y',
side='right',
range=[0, 14.0]
)
)
- 可視化したグラフ
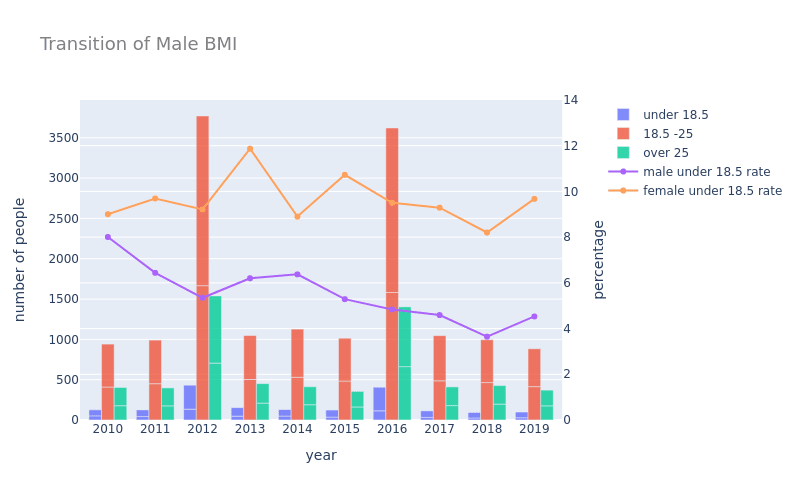
考察
グラフは2010年から2019年までのBMI(体格指数)の変遷を示し、異なるBMIカテゴリー(「18.5未満」「18.5-25」「25以上」)に属する人々の数と、男性および女性の「18.5未満」の割合を表示しています。
男性のBMI18.5未満の割合(紫のラインチャート)
男性のBMI18.5未満の割合の推移を見てみると、低BMIの割合2010年から2019年にかけて一貫して減少しています。
女性のBMI18.5未満の割合(オレンジのラインチャート)
女性のBMI18.5未満の割合は男性と比較して高い傾向にあります。
2010時点での低BMIの割合は男女で同程度ですが、2019年時点では女性の低BMIの割合と男性の低BMIの割合では4%程度の差が開き、女性の方が高い割合になっています。
BMIは栄養状態をみる上でも重要な指標であり、BMIの値が18.5以下で低体重となります。高齢者にとって低BMIは健康リスクに繋がります。高齢者の低栄養は社会問題の一つですが、上記の結果から、男性と女性で異なる栄養対策が必要であると言えるかもしれません。
まとめ
今回は政府統計のオープンデータを利用して可視化を行い、その結果から考察までしてみませした。詳細な分析を行うためにはミクロなデータを使う必要がありますが、統計データを用いたマクロレベルでの考察を行うことも大切です。オープンな統計データの活用することで、より広い視野からのトレンド分析や、特定の現象に対する一般的な理解を深めることができるかもしれません。

Discussion