私たちREADYFORの社内には、dbtとBigQueryにより整備されたデータ基盤があり、日々多くの情報が蓄積されています。
しかし、社内の誰もが自分の手で「今知りたいこと」をデータから引き出すのは、いまだに簡単ではありません。
この課題を解決するために、READYFORでは社内データ基盤とLLMを組み合わせた“社内データ分析エージェント”の開発に取り組んでいます。
前回の記事では、エージェントの概要・アーキテクチャに加えて、実装の工夫・ハマりどころ・得られた知見を紹介しました。
今回の記事は、前回書ききれなかった知見を最後まで紹介する続編です。
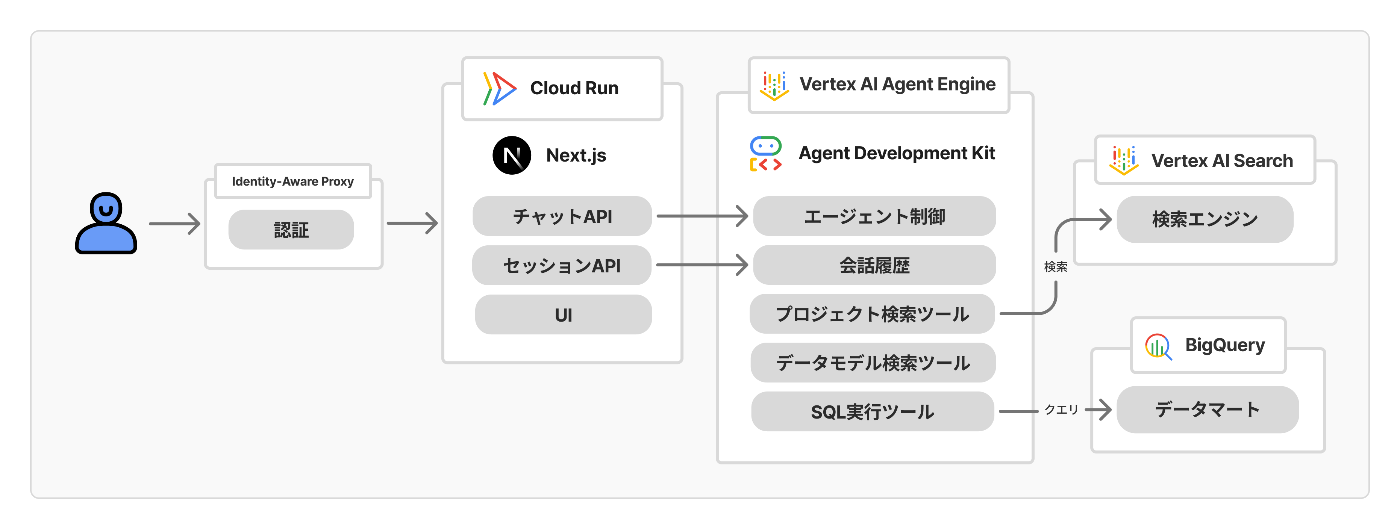
どんなエージェントか?(再掲)
端的に言えば、「人間の代わりにSQLを書いて実行したり全文検索ツールを駆使したりしてデータを集めて結果を教えてくれるエージェント」です。

マスコットキャラクターもいます。めぐりちゃんと言います
UIは至ってシンプル。チャットの入力欄からエージェントに対して指示や依頼を送信できます。

ユーザーの求めに応じてツールを呼び出し、必要な情報を集めた上で回答を生成してくれます。
READYFORはクラウドファンディングと寄付のプラットフォームを運営しているので、
- 「こういう条件に当てはまるプロジェクトの事例を探して」
- 「これまでで最も支援金額の多かったリターン上位10件は?」
といった問いに対して、社内データをもとに回答を得られます。
実装の工夫・ハマりどころ・得られた知見
ここからは、実装しながら工夫した点・ハマった点、開発を通して得られた知見を一気に紹介します。
No.1 〜 5までは前回の記事をご覧ください。
6. AI SDK Coreは使わずAI SDK UIだけ使った
フロントエンドにPythonではなくTypeScriptを採用する利点のひとつとして、AI SDK by Vercelを使えることがありました。
複雑になりがちなチャットの状態管理をライブラリに預けられることは、本丸でのエージェントの開発に専念する上で大きな恩恵でした。
また、AI ElementsのおかげでAIアプリケーションでよく使われるUIコンポーネント(チャットバブル、メッセージのインプット、ツール呼び出しのトグル、etc)を簡単に取り入れることができます。
最初は Next.js App Router Quickstart を読みながら、AI SDK CoreのstreamTextを使ってチャット用のAPIを実装していました。
// Next.js App Router Quickstartより
import { streamText, UIMessage, convertToModelMessages } from 'ai';
import { yourProvider } from "your-custom-provider";
export async function POST(req: Request) {
const { messages }: { messages: UIMessage[] } = await req.json();
const result = streamText({
model: yourProvider("your-model-id"),
messages: convertToModelMessages(messages),
});
return result.toUIMessageStreamResponse();
}
今回の構成では、GeminiやClaudeなどのAPIをそのまま呼ぶのではなく、Agent Engineにデプロイした独自のエージェントを通じてテキスト生成させるので、そういうカスタムプロバイダーを作成すればよいのかと考えていました。
しかし、公式ドキュメントを読みながらカスタムプロバイダーを作ろうとしても、どうにもインターフェイスがしっくり来ません。
interface ProviderV2 {
languageModel(modelId: string): LanguageModelV2;
textEmbeddingModel(modelId: string): EmbeddingModelV2<string>;
imageModel(modelId: string): ImageModelV2;
}
結論として、「プロバイダー」という概念は「モデルを抽象化したものであって、エージェントを抽象化したものではない」ということがわかりました。
AI SDK Coreの持つ役割は、
- LLMのAPIを呼び出すAIサービスのバックエンドを作ること(エージェントを作ることも含む)
- データをAI SDK UI(フロントエンド)に橋渡しすること
の2つで、今回の構成では上記の1とADK(Agent Development Kit)が持つ役割が衝突します。
なので、AI SDK Coreを使うことはせず、Next.jsのサーバーサイドでは「Agent Engine + ADKから得られるデータをAI SDK UIが求める形式に変換してストリーミングする」という役割に専念することのしました。
AI SDK UIが求める具体的なデータ形式は、以下のプロトコルとして整理されています。
上記のプロトコルを満たすチャットAPIを用意すれば、AI SDK Coreを使わなくてもAI SDK UIの useChat() から接続することができます。
(さらに詳しいADK × Next.jsの苦労や工夫については、個人的にADK Advent Calendar 2025の9日目に寄稿する予定です)
7. 大事なユースケースを選んで探索ステップを減らす
社内データの分析エージェントを作る上では、「さまざまな業務知識の中から何を厳選してLLMの限りあるコンテキストウィンドウに渡すか」が重要です。
前回の記事で「データ基盤の品質も一緒に良くしていく」という話を書きましたが、メタデータをいくら拡充しても、それをうまくエージェントが探し当てられなくてはいけません。
ツールを使って欲しいデータがどこにあるか探すことになりますが、ステップが長くなりがちです。
READYFORでは、以下が集計条件として使われることが多い傾向が見られました。
- プロジェクトのカテゴリ
- プロジェクトのステータス(下書き、審査中、募集中など)
- 利用プラン(ベーシックプラン/サポートプラン/コンサルティングプラン)
少しずつ社内でユーザーを広げながら、実際の会話履歴を蓄積して、その分析の中で見えてきた重要なユースケースについては、事前知識をシステムプロンプトに落とし込みます。
それによって着実に分析結果が出てくるまでの速さや安定性が上がっていきます。
(ただし、何でもかんでも入れるとコンテキストが伸びるので取捨選択は必要です)
以下がシステムプロンプトの一部抜粋です。
root_agent = Agent(
name="root_agent",
model="gemini-2.5-flash",
instruction="""
あなたはデータ分析専門のAIアシスタントで、あなたの名称はmeguri (めぐり)です。READYFOR株式会社の内部データにアクセスすることが許可されています。
あなたが会話する相手はREADYFOR株式会社の社員です。
この会話は {session_start_date} に始まりました。
あなたの現在だと認識している日付は古い可能性があります。上記の日付を優先してください。
...(中略)
用語:
- 実行者: プロジェクトを立ち上げる個人または団体。projects.user_id にIDが保存されている。プロジェクト実行者としての名義は xxxxx.xxxxx に保存されている
- キュレーター: READYFORのスタッフで、プロジェクトのサポートを担当する。projects.xxxxx に名前が保存されている
- プラン: プロジェクトが利用しているサービスプラン。projects.xxxxxx に保存されている
- 現行プラン: "コンサルティングプラン", "サポートプラン", "ベーシックプラン", "継続寄付"
- 旧プラン名(データに残っている可能性あり): ...
利用可能なデータモデル (分析タスクに関連しそうなデータモデルがあれば get_data_model_tool で詳細を取得すること):
{data_mart_models}
""",
before_agent_callback=before_agent_callback,
)
8. モデル検索の選択肢を最初から与える
前述のシステムプロンプト例にも含まれていますが、「利用可能なデータモデル」の選択肢をあらかじめ与えています。
例:
利用可能なデータモデル (分析タスクに関連しそうなデータモデルがあれば get_data_model_tool で詳細を取得すること):
marts.projects: クラウドファンディングや寄付募集のプロジェクト情報。
marts.users:ユーザー情報。支援者、実行者の両方を含む
...
これはデータマートの規模が大きくなってくると使えなくなってくる手段ですが、モデルを検索する前からLLMがアタリをつけられるようになるのでステップ数の削減には効果があります。
ADKでは、before_agent_callback を使ってエージェント実行前に State にデータをセットすることができるので、これを利用してモデル名の一覧を動的にセットしています。
def before_agent_callback(callback_context: CallbackContext) -> None:
state = callback_context.state
if "data_mart_models" not in state:
data_models = list_data_marts_models()
summary_lines = [f"{model.name}: {model.description}" for model in data_models]
state["data_mart_models"] = "\n".join(summary_lines)
if "session_start_date" not in state:
start_dt = datetime.now(_JST)
state["session_start_date"] = start_dt.date().isoformat()
return None
LLMに現在の日付を認識させるために、日付データも before_agent_callback を利用して渡しています。
おわりに
アドカレ11日目に公開する予定のPoC編では、PoCのプロジェクトとしてどのように立ち上げ・社内展開・評価と改善を進めてきたかを紹介します。気になる方はフォローなどお願いします!
明日は READYFOR Advent Calendar 2025 8日目、KazuyaMiyagiさんによる記事が公開される予定です。
お楽しみに!

「みんなの想いを集め、社会を良くするお金の流れをつくる」READYFORのエンジニアブログです。技術情報を中心に様々なテーマで発信していきます。 ( Zenn: zenn.dev/p/readyfor_blog / Hatena: tech.readyfor.jp/ )
Discussion