
はじめに
こんにちは、ソフトウェアエンジニアのshmokmtです。
私が所属しているチームはシステム&データ基盤[1]と呼ばれ、クラウドインフラの運用や改善を中心とする業務が主になっています。
今回はチームを代表し、2023年に取り組んだことに関して
一部抜粋しつつ、振り返ってみようと思います。
取り組んだこと
コスト最適化
今までのコスト周りの運用はマネージャーが定期的をモニタリングしつつ、気になる箇所があればミーティングの議題としてあげるような緩い方針での運用で特に大きな問題はなく運用できていました。
しかし、2023年の前半にコストを全体的に見直しをする機会があり、それを機にある程度ガッとコスト最適化を実施しました。
具体的には以下のような取り組みを実施しました。
-
切れていたSavings Plansやリザーブドインスタンス(RI)の見直し
READYFORは主にAuroraとECS/Fargateに料金がかかっている状態であるため、これらに割引を適用しました。 -
ECRのプライベートリポジトリのイメージをNAT Gateway経由ではなく、PrivateLink経由でプルする
NATゲートウェイの通信料が高いため、できるだけ回避できるようにPrivateLinks経由で取得するようにしました。 -
ECR PublicやDockerHubからイメージをプルしていた箇所にECR プルスルーキャッシュを適用する
Dockerイメージを事前にビルドしていないサイドカー(Datadog Agentなど)はそのままインターネットからイメージを取ってきている状態であったため、プルスルーキャッシュを利用し、NATゲートウェイの通信料を削減できるようにしました。 -
利用頻度の低い開発環境の削除
AWS上の開発環境を複数用意していますが、利用頻度が月に数回程度の開発環境があり、そのためだけに
ECSやALB、OpenSearchの料金がかかってしまっていました。 -
Circle CIとGitHub Actionの併用をやめて、GitHub Actionsに統一
-
オートスケールの条件のチューニング
ターゲット追跡ポリシーとステップスケーリングポリシーを併用することで急にアクセスが増えた場合でも今まで以上にオートスケールしやすくなりました。
とくにREADYFORのECSのタスク定義では、複数のサイドカーを定義しているため、上記の施策の中でもプルスルーキャッシュの効果は大きい方でした。
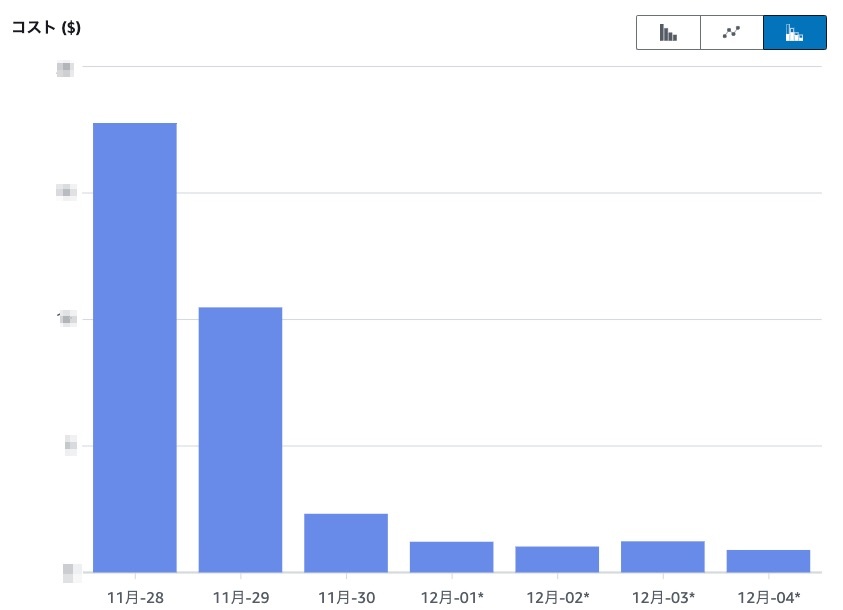
図1. プルスルーキャッシュ適用前後のNATゲートウェイのデータ処理料金の推移
また、来年の2024年2月1日より、すべてのパブリックIPv4アドレスに対して新しい料金体系が適用されます。まだ対応できていませんが、AWSの開発アカウント内に存在するALBを始めとするリソースでまとめることができるものはまとめてしまおうかなと考えています。
負荷耐性の向上
2023年はREADYFORで公開されているプロジェクトで注目を浴びるものが多く、サービスに大量のリクエストが来る年となりました。これを機会に多くの方に利用していただけたものの、ECSやAurora MySQLが過負荷状態になったり、メール配信処理が遅延しやすい状態になったりしており、利用者の方々にご迷惑をおかけしておりました。
この反省として、バックエンドエンジニアの基盤チームと連携しつつ、インフラおよびアプリケーション側で以下の修正を入れました。
- Aurora MySQLのリードレプリカの活用[2]
- データを取得するコストが比較的大きい、かつ頻繁に実行されるクエリの結果をRails側で短時間キャッシュする
- 支援者数が多いプロジェクトに関するメール配信でもジョブキューが詰まらず、即時配信できるように処理の全体的な見直しおよび、メール配信サービスの移行
Aurora MySQLに関しては、リードレプリカをオートスケールさせる、Amazon Aurora Auto Scalingというサービスもありますが、そちらはまだ必要性が高いとは考えておらず、導入に至っていません[3]。
また、アプリケーションのミドルウェア部分に関しては、READYFORで稼働しているメインのRuby on Railsのアプリケーションがunicornを使っているため、pumaに乗り換えを検討したいなと考えています[4]。
クラウドセキュリティの強化
READYFORではGitHub ActionsからAWSにアプリケーションをデプロイすることが多いですが、それらのほとんどが未だにIAMロールではなく、IAMユーザーの永続化するクレデンシャルを使ってしまっている状態でした。今年は時間をかけて少しずつIAMユーザーからIAMロールに移行する活動を実施してきました。まだデプロイ用のIAMユーザーを完全になくすことはできていませんが、来年もコツコツ進めていきたいです。
データ基盤周りの整備
現在進行中の取り組みではありますが、READYFORでは利用しているさまざまなSaaSのログ等の基盤をBigQuery上に構築しようとしています。インフラ周りのログとしてはDatadogのアーカイブログ[5]やCloudFrontのアクセスログがBigQueryに格納される仕組みが既にできており、以前のアクセスログでも今までよりもスムーズにアクセスすることができるようになりました。次はAurora MySQLのデータをBigQueryに連携できるように動いているところです。
その他
そのほかにも以下のような多くの細かな改善がありました。
- BigQueryを中心にGoogle CloudのTerraformによる管理の開始
READYFORのシステムのほとんどはAWSで構成されているため、Google CloudのTerraform管理は優先度が低く、コンソール管理になってしまっていました。 - Terraformのバージョンアップを効率的にできるように、Renovateを導入
昨年まではまだ手作業で必要に応じて気づいた人がアップデートするという運用スタイルでしたが、同僚のKazuyaMiyagiさんの提案/実装により劇的に改善されました。今は全tfstateに対して自動的にPRで作成がされるため、即日でバージョンアップが可能になっています[6]。

図2. 実際に作成されたTerraformのバージョンを更新するPR
- tflint、trivyの運用をちゃんとするようになる
最初はtrivyではなく、tfsecを使っていましたが、trivyが推奨されていること[7]と
reviewdog/action-trivyがリリースされたことを機にtrivyに移行しました。 - ECSサービスの負荷が偏らないようにALBの負荷分散アルゴリズムを変更する
READYFORでの多くのECSサービスでは、負荷試験等に基づきデフォルトのRound RobinよりもLeast Outstanding Requestsの方が適切であると判断し、アルゴリズムを変更しました。
まとめ
2023年にインフラ周りで取り組んだことの一部をざっくり紹介しました。
まだまだ多くの課題は抱えているものの、
2019年以前はまだIaCが導入されておらず、WebアプリケーションはEC2 Classic上で稼働していたことを考えると、安全にインフラ構成を変更したり、アプリケーションをデプロイできる状態が整ってきたように思います。
引用: 1行のコードから社会課題の解決へ、思いを馳せる。READYFORのエンジニアリングの軌跡と展望|Ryohei Kumagai, https://note.com/9ma3r/n/nfeebefe15807
来年も引き続き、良いサービスを提供できるよう努めていきたいと考えています。
明日はAdvent Calendar最終日で@yono_memoさんからの記事になります。お楽しみに。
-
専任のデータエンジニアがいないため、私たちのチームがデータパイプラインの整備なども担当しています。実際に手を動かすエンジニアは私とKazuyaMiyagiさんで構成される比較的小規模なチームです。 ↩︎
-
READYFORでは数年前からAurora MySQLを運用してきましたが、実はリードレプリカはライターインスタンスに障害が発生したときにすぐにフェイルオーバーできるようなアクティブスタンバイとしての役割しか持っておらず、リードレプリカに実際にクエリを投げて負荷分散することができていませんでした。今までもシステムの負荷が上がることはありましたが、それはECS/FargateのCPUに限った話であり、AuroraのCPUが大きく上がることはほとんどなかったということもあり、施策の優先度としてはかなり低くなっていました。 ↩︎
-
リードレプリカのオートスケーリングはActiveRecordのコネクションプールと相性が良くないため、Amazon RDS Proxyあたりでこのあたりがうまく解決できるのかなと想像しますが、あまり詳しくないです。 ↩︎
-
過去にも話題に出ることはありましたが、アプリケーションコードの特定の一部分がスレッドセーフではなかったり、負荷試験する環境が整備されていなかったため動くにくい状態でした。現在はこれらのブロッカーが解消されたため、取り組みやすい状態になってきました。pumaとunicornのそれぞれでベンチマークを取り、移行するメリットがどのぐらいあるかどうか確かめてみたいなと思っています。 ↩︎
-
弊社のDatadog Logsでは2週間以上経過したログはS3に格納される設定になっています。S3に格納されたログをDatadogで再び見るためにはLog Rehydrationという機能を使う必要があるのですが、状況によってはこの実行に数時間単位で時間がかかることがありました。また、BigQuery上に格納することで他のデータセットとJOINしたいという需要もありました。 ↩︎
-
RenovateのregexManagersやmatchManagersを活用することで、.terarform-versionやGitHub Actionsのワークフローなども含めて同一のPRで更新することができています。 https://docs.renovatebot.com/presets-regexManagers/ ↩︎
-
↩︎Going forward we want to encourage the tfsec community to transition over to Trivy. Moving to Trivy gives you the same excellent Terraform scanning engine, with some extra benefits:
https://github.com/aquasecurity/tfsec

「みんなの想いを集め、社会を良くするお金の流れをつくる」READYFORのエンジニアブログです。技術情報を中心に様々なテーマで発信していきます。 ( Zenn: zenn.dev/p/readyfor_blog / Hatena: tech.readyfor.jp/ )
Discussion