【R】 小技メモ
lapplyでリストの名前属性も使いたい時
hoge <- vector("list", length=3)
names(hoge) <- c("a","b","c")
seq(list)でリスト番号ベクトル取り出し、lapplyに使用する。
seq()関数にリストを入れるとリストの長さ分の連番が作られる。
seq(hoge)
[1] 1 2 3
この連番ベクトルを使ってlapply()。xにはリストの要素番号が渡される。function内でリストのx番目のdataやリストの名前属性のx番目を取り出せば良い。
hoge <- lapply(seq(hoge), function(x){
name <- names(hoge)[x]
data <- hoge[[x]]
})
名前属性のベクトル
hoge <- lapply(names(hoge), function(name){
data <- hoge[[name]]
})
空のオブジェクト作成
空のベクトル
hoge <- NULL
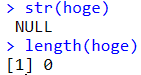
特定の型を指定した空ベクトル
foo <- as.numeric()
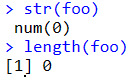
長さを指定して空ベクトル作成
bar <- character(length = 10)
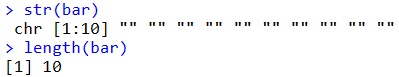
空のmatrix, data.frame
matrix(nrow = 5,ncol = 10)

matrix(data = "", nrow = 5,ncol = 10)
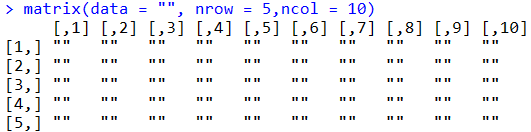
data.frame(matrix(data = "", nrow = 5,ncol = 10))
空のリスト
hoge <- list()
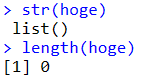
長さを指定して空のリスト作成
foo <- vector(mode = "list", length = 10)

長さを指定した作った空のリストではリストの要素に名前を付けることができる。
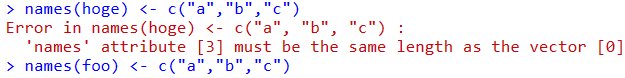
1行で名前付きベクトル作成
data.frameから1列だけ抜き出したベクトルにはdata.frameの行名が残らない。
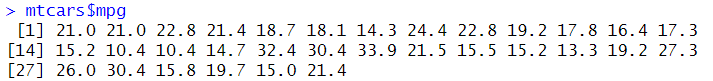
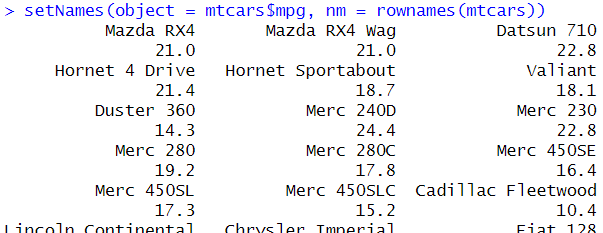
setNames()機能を使えば1行で名前付きベクトルが作れる。
setNames(object = mtcars$mpg, nm = rownames(mtcars))
pattern matchの時の正規表現例
デモ用ベクトル
a <- "MUT: A159P; AMP. BBB_C/D\\-E"
特定の記号をXXXに変換する例を考える。
コロンや半角スペース、アンダーバーなどなどの記号をパターンマッチさせる際は特に何も意識しなくてよい。
gsub(pattern = ":", replacement = "XXX", x = a)
gsub(pattern = ";", replacement = "XXX", x = a)
gsub(pattern = " ", replacement = "XXX", x = a)
gsub(pattern = "_", replacement = "XXX", x = a)
gsub(pattern = "/", replacement = "XXX", x = a)
gsub(pattern = "-", replacement = "XXX", x = a)

ピリオドは任意の1文字を意味する。ベクトルの1文字ずつがXXXに変換される。
gsub(pattern = ".", replacement = "XXX", x = a)
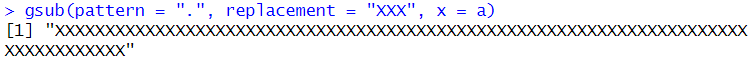
ちなみにピリオドを2つにすると、2文字ずつがXXXに変換される。3つにすると3文字ずつXXXに変換される。.{回数}のようにしてもよい。
gsub(pattern = "..", replacement = "XXX", a)
gsub(pattern = "...", replacement = "XXX", a)

ピリオドは1つだけで使用すると、全文字がヒットしてしまうが、他の文字と組み合わせると任意の文字数を変換できる。
# コロンと次の1文字
gsub(pattern = ":.", replacement = "XXX", a)
# BBBとその後ろ3文字
gsub(pattern = ";...", replacement = "XXX", a)
# 先頭から2文字
gsub(pattern = "^..", replacement = "XXX", a)
# 後ろから4文字
gsub(pattern = "....$", replacement = "XXX", a)

先頭を示す^と末尾を示す$を単独で使うと、文字が置換されずに挿入される。
gsub(pattern = "^", replacement = "XXX", a)
gsub(pattern = "$", replacement = "XXX", a)

ピリオドを沢山打てば長い文字をヒットさせられるが、ある個所以前/以後をヒットさせるにはピリオドとアスタリスクを組み合わせるとよい。
# :の前は何文字でもヒットする。
gsub(pattern = ".*:", replacement = "XXX", a)
# BBBの後ろは何文字でもヒットする。
gsub(pattern = "BBB.*", replacement = "XXX", a)
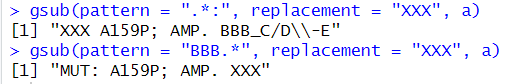
正規表現をエスケープ
ピリオドを正規表現として使わずにピリオドを変換したい場合はバックスラッシュを2つつける。\\.
gsub(pattern = "\\.", replacement = "XXX", x = a)
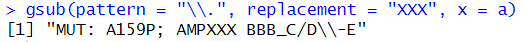
バックスラッシュを文字として扱いたいときも、バックスラッシュをつけるのだが、挙動がわかりにくいので、あまり使わないようにする方が無難

Objectのメモリサイズを調べる
object.size(obj)
format(object.size(obj), units = "Mb")
repのtimes引数、each引数を使って全組み合わせ作成
繰り返しを行うrep()関数のtimes=引数では、ベクトルを指定数繰り返す。
rep(LETTERS[1:5], times = 3)
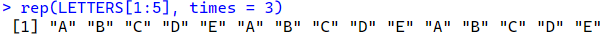
一方、each=引数では、1要素を指定数繰り返して、2要素目の繰り返しを行う。
rep(LETTERS[1:5], each = 3)
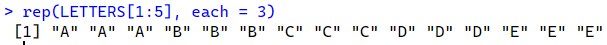
これをcbind()で列方向に繋げれば、全組み合わせを作ることができる。
cbind(rep(LETTERS[1:5], times = 3),rep(LETTERS[1:5], each = 3))

さらに1列目と2列目の要素が同じものを除くと1つ vs その他全ての組み合わせを作成できる。
hoge <- cbind(rep(LETTERS[1:5], times = 3),rep(LETTERS[1:5], each = 3))
hoge[hoge[,1] != hoge[,2], ]

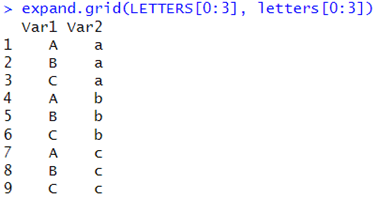
expand.grid()関数でもよい。
expand.grid(LETTERS[0:3], letters[0:3])
dputを使えば、Rコードで使える出力の形で返してくれる。
ベクトルの出力を別の関数にコピペして使いたい時に便利

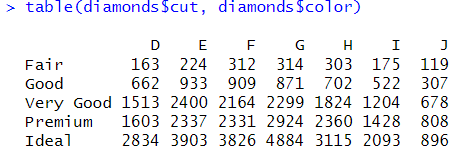
table()の結果をdata.frameにするとき
table(diamonds$cut, diamonds$color)
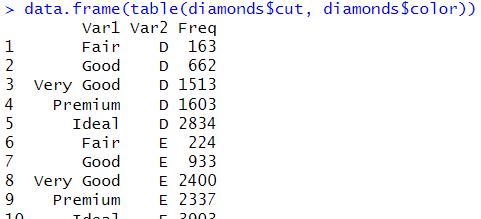
data.frameに渡すだけで頻度の列が作れる
data.frame(table(diamonds$cut, diamonds$color))
table()の出力形状を維持したければ、as.data.frame.matrixに渡す
as.data.frame.matrix(table(diamonds$cut, diamonds$color))

重複があるものには1つ目から連番をつける。
make.names()だと重複した要素の登場2回目に.1が付いてしまうので、重複要素の1つ目から連番をつけるように自作。
gene <- unique(gene_symbol)
for(i in gene){
n <- sum(gene_symbol %in% i)
if(n > 1){
count <- seq(n)
gene_symbol[gene_symbol %in% i] <- paste(i, count, sep = "_")
}
}
RでPython interpreterモードを使う
https://stackoverflow.com/questions/50145643/unable-to-change-python-path-in-reticulate
library(reticulate)
repl_python()

!を付けたシェルコマンドもいける。
終了するときはexitと打つ
エラーメッセージが日本語だと、エラーの検索がヒットしにくいので英語でエラーメッセージを表示させたい。
Sys.setenv("LANG" = "en")
日本語に戻す
Sys.setenv("LANG" = "ja")
処理待ち中にConsoleを使えるようにする
重たい処理を待っている間が勿体ないので、バックグラウンドで実行させる。
エラーメッセージなどが途中で出ないので、単純な処理だけにしておいた方が無難かも。
でもRStudioではダメっぽい。
library(future)
plan(multisession)
fut <- future({
saveRDS(atlas, "Object.rds")
})
Objectが巨大だと次エラーが出た。
This exceeds the maximum allowed size of 500.00 MiB
options(future.globals.maxSize = 110 * 1024^10)で適当に大きい値を入れたら行けた。
処理が終わったのかどうかはコマンド打ってみないわからない。
# 処理の状態を確認
resolved(fut)
エラーメッセージ等もコマンドで取り出す
# 結果を取得(エラーがあれば、ここで表示されます)
value(fut)
Rでsedコマンドみたいなパターンキャプター
sub()関数でできる。pattern=引数でキャプターしたい箇所を丸括弧で囲む。replacement=引数で"\\1"のように呼び出せる。
x <- "aaa123__/bbb"
# _より前をキャプチャー
sub(pattern = "^(.*)_.*",replacement = "\\1", x)
# _より前とbbbの箇所をキャプチャー。キャプチャー箇所を入れ替えて返す
sub(pattern = "^(.*)_.*(bbb)",replacement = "\\2\\1", x)

1つのキャプターに複数候補を入れる。
y <- c("Group_A 1", "Group_A 2", "Group_A 3",
"Group_B 1", "Group_B 2", "Group_B 2",
"Group_B_2 1", "Group_B_2 2", "Group_B_2 3")
sub(pattern = "^(Group_A|Group_B).*",replacement = "\\1", y)

【 saveRDS/readRDSは辞めてqsパッケージのqsave/qreadを使おう 】