Remix + Cloudflare Workers + D1 + KV + Queue + R2 + DOで簡単なアプリを作る
Remix + Cloudflare Pages/WorkersをベースにD1とKVと組み合わせた構成で作るアプリの解説は巷に結構あるが、それらに加えてQueueやR2なども合わせた参照実装みたいなものが見当たらなかったので作った。
このアプリの機能は下記。
- Googleアカウントを用いたOAuthログイン
- セッション管理にKV,ユーザー管理にD1を使う
- はてブのようなブックマーク機能(基本的なCRUD)
- URLとコメントを入力してD1へデータ登録できる
- URLの先のページからOGPを取得して登録
- QueueのProducerとConsumerを使って非同期にタイトルと画像を取得
- 取得した画像はR2にアップロードする
- URLごとにブックマーク数を管理する
- Durable Object(DO)を使う。
- Cron Trigger
- ついでに追加。アプリ的には不要だがせっかくなので設定だけしておく。
- 記事のdescriptionを翻訳して表示
- AI Gatewayを使いたいがために追加。特に意味の無い機能...。
QueueとR2の利用にはPaid Planの登録が必要なので本番環境にて試したい場合は事前に$5を払う必要がある。
以下、このアプリを作る過程を最初から解説していく。分からないところが出てきたり詰まったりしたら完成済みのリポジトリの方を確認してほしい。
準備
Cloudflareのアカウントがない人はまずはここから登録しておく。
プロジェクト生成を行う。色々と聞かれるのでプロジェクト名(自分はremix-workers-bookmarkとした)を入力し、Basicを選び、Cloudflare Workersを選択し、npm installまでやっておく。
npx create-remix@latest
npm run devでローカル実行を確認する。http://localhost:8787にアクセスし無事に動けばOK。
cd remix-workers-bookmark
npm run dev
このあと必要になるライブラリを入れる。
npm install -D drizzle-orm remix-auth remix-auth-google remix-validated-form zod @remix-validated-form/with-zod prettier drizzle-kit better-sqlite3 tailwindcss
.gitignoreを追加する。ローカル実行時に生成される.wranglerとWorkers用の.envみたいなやつの.dev.varsは入れ忘れがちなので注意(というかcreate-remixをしたときに自動でこの辺は生成しておいてくれ...)
.DS_Store
node_modules
/.cache
.dev.vars
/public/build
/build
.vscode
.wrangler
認証機能の作成
以下ではGoogleログインを追加していく。
基本的にはmizchi/remix-d1-bulletsの実装を踏襲することで手抜きをしてる。
Google側での設定
概要 | Authentication | Google for Developers
下記にアクセスし適当なプロジェクトを作成。
https://console.cloud.google.com/
APIとサービス > OAuth同意画面、へ進む。[外部]を選択し、必要情報を埋めていく。
スコープはuserinfo.emailとuserinfo.profileとopenidを選択。
テストユーザーはテストログインしたいアカウントのアドレスを登録する。
認証情報へ行きクライアントIDの発行をする。
承認済みのJavascript生成元にはhttp://localhost:8787とhttps://<your-workers-name>.workers.devを設定し、承認済みのリダイレクトURIにはhttp://localhost:8787/auth/google/callbackとhttps://<your-workers-name>.workers.dev/auth/google/callbackを設定する。
ちなみに登録フローは【Rails7】Googleログインを公式ドキュメントに沿って実装するがスクショ付きなのでわかりやすかった。
KV
KVの作成。本番用とPreview用を作る。
npx wrangler kv:namespace create session_kv
npx wrangler kv:namespace create session_kv --preview
wrangler.tomlに下記を追加する(preview_idがないとnpm run devするときに怒られるので忘れない)。
[kv_namespaces]
binding = "SESSION_KV"
id = "..."
preview_id = "..."
ちなみにこのbindingで設定した値(ここではSESSION_KV)にアプリからアクセスすることでCloudflare上のKVに操作を行うことになる。
D1
DBを作成する。DB名は好きなもので良い。
npx wrangler d1 create SAMPLE_DB
wrangler.tomlに下記を追加する。
[d1_databases]
binding = "DB"
database_name = "SAMPLE_DB"
database_id = "..."
migrations_dir = "db/migrate"
migrations_dirはD1用のマイグレーションファイルの置き場の指定。デフォルトだとプロジェクトルートにmigrations/というディレクトリができるはず。自分の場合はschema.tsもまとめて管理したかったのでdb/migrateを指定した(Railsと同じ)。
package.jsonのscriptsに下記を追加する。
"migrations:gen": "drizzle-kit generate:sqlite",
"local:migrations:apply": "wrangler d1 migrations apply SAMPLE_DB --local",
"migrations:apply": "NO_D1_WARNING=true wrangler d1 migrations apply SAMPLE_DB"
migrations:genではdrizzle-kit(次で解説する)でmigrationファイルを生成する。
migrations:applyとlocal:migrations:applyでは生成したmigrationファイルを元にD1へSQLクエリを実行する。
Envの設定
types/env.d.tsにD1やKVへアクセス際のBindingの型の設定をしておく。どうせ後で使うのでQueueとかR2用の設定も一緒にしちゃう。
declare interface Env {
SESSION_SECRET: string;
GOOGLE_AUTH_CALLBACK_URL: string;
GOOGLE_AUTH_CLIENT_ID: string;
GOOGLE_AUTH_CLIENT_SECRET: string;
SESSION_KV: KVNamespace;
DB: D1Database;
QUEUE: Queue<any>;
ASSETS: Fetcher;
BUCKET: R2Bucket;
COUNTER: DurableObjectNamespace;
}
アプリ側の設定
Google側での設定で取得したクライアントIDなどを環境変数として設定する。.dev.varsに追加した環境変数はnpm run devでローカルサーバを実行したときに自動で読み込んでくれる。
$ touch .dev.vars
GOOGLE_AUTH_CALLBACK_URL=http://localhost:8787/auth/google/callback
GOOGLE_AUTH_CLIENT_ID=xxxxxx
GOOGLE_AUTH_CLIENT_SECRET=xxxxxx
SESSION_SECRET=xxxxxx
ユーザー保持用のテーブルを作成する。以降ではD1とのやり取りにDrizzle ORMとDrizzle Kitを使う。Drizzle ORMはその名の通りORMで、Drizzle Kitはマイグレーション管理などを行うCLIツール。
まずはDrizzle ORM用の設定をしていく。drizzle.config.tsを作成する。
import type { Config } from "drizzle-kit";
export default {
schema: "./db/schema.ts",
out: "./db/migrate",
} satisfies Config;
mkdir -p db/migrate
touch db/schema.ts
schema.tsをdb/に作成する。
import { sqliteTable, text, integer } from "drizzle-orm/sqlite-core";
export const users = sqliteTable("users", {
id: integer("id").primaryKey().notNull(),
profileId: text("profileId").notNull(),
iconUrl: text("iconUrl"),
displayName: text("displayName").notNull(),
createdAt: integer("createdAt", { mode: "timestamp" }).notNull(),
});
migrationファイルを生成する。
npm run migrations:gen
ちなみにdb/migrateに生成されたsqlファイルはいじらないこと。
最後にローカルのD1へmigrationを適用する。
npm run local:migrations:apply
なおローカルのD1は.wrangler/配下にあり、のぞいてみるとSQLiteが配置されていることがわかる。
また、マイグレーションはDBへの適用前(applyコマンド実行前)ならdrizzle-kit drop(drizzle-kit drop – DrizzleORM)で破棄することができる。が、DBに適用済みの場合はd1_migrationsテーブルのレコード削除とdrop table <your-table-name>を手動で実行しないといけない。例えば以下のような感じ。
NO_D1_WARNING=true npx wrangler d1 execute SAMPLE_DB --local --command='select * from d1_migrations'
NO_D1_WARNING=true npx wrangler d1 execute SAMPLE_DB --local --command='delete from d1_migrations where id = 4' <- 取得したd1_migrationsテーブルのレコードのid
NO_D1_WARNING=true npx wrangler d1 execute SAMPLE_DB --local --command='drop table users'
tableの処理まで管理してくれるrollbackコマンドはないので注意。
実装
アプリケーションコードの作成に移るが、Remixの基本的な使い方についてはDocsを読んでほしい。
認証の具体的な実装はサンプルリポジトリのapp/routes/auth.*とapp/features/common/services/auth.server.tsを参照。
大体のロジックはmizchi/remix-d1-bulletsとほぼ同じなので特に工夫した点とかはない。
ただそれだけだと味気ないので以下ではディレクトリ構成について解説しておく。
アプリケーションコードの構造
このツイートをみて知ったが、Route File Naming (v2) | Remixで解説されているFolders for Organizationという構造でアプリの機能を作ることができる。
Folders for Organization(これが正式名称でいいのかは謎)はapp/routes配下にapp/routes/hoge.bar.tsxとおいて/hoge/barというURLへマッピングするデフォルトの構成をapp/hoge.bar/route.tsxというディレクトリとファイルで表現する方法。app/hoge.bar/のroutes.tsx以外のファイルは特に他に影響しないのでapp/hoge.bar/card.tsxとかapp/hoge.bar/list.tsxみたいなhoge.barだけに関連するコンポーネントをまとめて管理できるのが利点。
Our general recommendation for scale is to make every route a folder and put the modules used exclusively by that route in the folder, then put the shared modules outside of routes folder elsewhere.
とあるようにスケールする作り方としてはこの構成が推奨されていた。
Folders for Organizationと先のツイートを考慮した結果、個人的には下記のようなルールでの運用が良さそうという結論になった。
-
app/routes- URLに紐づくRouteを配置する。
-
Folders for Organizationのパターンに従ってRouting Pathをディレクトリにして
route.tsxファイルを配置する。 - ディレクトリの中にはそのページでのみ使うコンポーネントなどを配置する。
-
app/features- Route横断で使うコンポーネントや関数などを配置する。
-
app/features/feature-nameのようにディレクトリを作成し、その中にcomponentsやservicesなどのように階層を設けてファイルを配置する。
-
app/db- データベースのスキーマファイルとマイグレーションファイルを配置する。
今回の規模のアプリではやり過ぎだけど参照実装なのでこういう作りにしている。
ブックマーク機能の実装
URLをブックマークして一覧出来たり編集したり削除できたりするようなCRUD機能を作っていく。
TailwindCSSの設定
今回はTailwind CSS | Remixを使うので設定をしておく。
まずremix.config.jsにtailwind: trueを追加して下記をインストール。
npm install -D tailwindcss
npx tailwindcss init --ts
tailwind.config.tsにcontent: "./app/**/*.{js,jsx,ts,tsx}",を追加。
app/tailwind.cssを作成し@tailwind base; @tailwind components; @tailwind utilities;を追加。
app/root.tsxのLinkタグの指定を下記のように書き換える。
import styles from "./tailwind.css";
export const links: LinksFunction = () => [{ rel: "stylesheet", href: styles }];
CSSに関してはTailwindに限らずさまざまな手法が取れるので詳しくは下記を見てほしい。
テーブル作成
下記のようなbookmarksテーブルのスキーマを作る。
export const bookmarks = sqliteTable(
"bookmarks",
{
id: integer("id").primaryKey().notNull(),
slug: text("slug").notNull(),
userId: integer("userId").notNull(),
url: text("url").notNull(),
title: text("title"),
comment: text("comment"),
imageKey: text("imageKey"),
isProcessed: integer("isProcessed", { mode: "boolean" })
.notNull()
.default(false),
createdAt: integer("createdAt", { mode: "timestamp" }).notNull(),
},
(table) => ({
userIdAndUrl: unique().on(table.userId, table.url),
})
);
npm run migrations:genでマイグレーションファイルを生成。npm run local:migrations:applyでD1へ反映する。
実装
作成するURLは下記。
-
/users/:userId- ブックマークの一覧。はてブのユーザーページみたいな感じ。
- 実装
-
/bookmarks/:bookmarkId
基本的なCRUD機能がほぼここの実装に詰まってる。一つずつ解説するのは大変なので具体的なコードはリポジトリの方を見てほしい。やってることはapp/features/service/bookmark.tsにCRUDの操作を記述して、routeファイルからのloaderとactionでそれぞれ呼び出してるだけ。
なおこの辺のアプリの実装を進めていくときに何度も行ったり来たりするであろうドキュメントを記載しておく。この辺見ておけば大体なんか動くものは作れると思う。
-
Route File Naming (v2) | Remix
- Remixのルーティングの規則についての確認でよく使う。
-
Querying with SQL-like syntax CRUD – DrizzleORM
- Drizzle ORMでどうやってDBとやりとりするのかを学ぶのによく使う。
-
Remix Validated Form
- Form作成の参考に使う
ブックマーク先の情報の取得機能の作成
ブックマークしたURLのタイトルやOGPなどを取得する機能を作る。このアプリではURLとコメントだけまずデータベースに登録しQueueにその情報をsendしている。
sendされた情報を検知したQueueのconsumerが動き、そのURL先ページを取得。タイトルやOGP画像のURLを取得し、D1を更新する。その際OGP画像は別途ダウンロードしてR2へ保存するようにしている。
Queues
Queueの作成。
npx wrangler queues create bookmark-queue
wrangler.tomlへ下記を追記。
[queues.producers]
binding = "QUEUE"
queue = "bookmark-queue"
[queues.consumers]
queue = "bookmark-queue"
max_batch_size = 10
max_batch_timeout = 30
なおRemixではCloudflare Workersにデフォルトで対応していてそのアダプタが@remix-run/cloudflareというライブラリなのだが、ここで@cloudflare/workers-typesのremix-cloudflare/package.jsonで指定されているWorkers用のインターフェースがqueueやCron Trigger用のscheduledに対応していないv3系のバージョンになっている。これはつまりこのままだとqueueやscheduledを使おうとすると型エラーが出る。
あまり行儀は良くないが仕方ないので最新の@cloudflare/workers-typesで生成された型情報を全部記載したファイルをtypes/配下に置いて対応した。
QueueのConsumerの実装
QueueのConsumerの実装を追加する。QueueのConsumerをWorkersに生やすにはserver.tsにqueue()をexportすれば良い。
実装としてはserver.tsとapp/queue/consumer.tsあたり。
こんな感じでqueueにsendされた情報がメッセージとして渡ってくるので受け取ってOGPを取得しR2に画像をアップロードしてレコードを更新するイメージ。
export async function queue(batch: MessageBatch, env: Env): Promise<void> {
console.log("queue", JSON.stringify(batch.messages));
for (const message of batch.messages) {
const { url, slug } = message.body as QueueBody;
const { title, image } = await fetchOGP(url);
const uploadedImage = await uploadImage(env, image);
await updateBookmark(env, slug, title, uploadedImage);
}
}
なおブックマークした先のHTMLからタイトルやOGPを取得する部分に関して。巷のhtml parserはnode依存のものが多くWorkersのランタイムで使える良さそうなものがパッと探して見つからなかったので正規表現で適当にやってる。手抜き。
R2
Bucketを作成する。
npx wrangler r2 bucket create bookmark-bucket
npx wrangler r2 bucket create bookmark-bucket-preview
wrangler.tomlに下記を追記。
[r2_buckets]
binding = "BUCKET"
bucket_name = "bookmark-bucket"
preview_bucket_name = "bookmark-bucket-preview"
今回のアプリでは例えば取得したサイトのOGP画像のURLがhttps://example.com/a/b/c.jpgだとしたら、その画像をダウンロードしR2のBucketのa/b/c.jpgに保存する。
そしてその画像へのアクセスはWorkers(https://<your-app-name>.workers.dev)に対してhttps://<your-app-name>.workers.dev/images/a/b/c.jpgというような感じで受けて画像を返すようにする。
R2ではデフォルトで全てのBucketは非公開であり、Publicアクセスを受けるにはカスタムドメインを設定するかr2.devドメインを有効にする必要がある。カスタムドメインを設定するのはチュートリアルとしてはやや面倒だし、r2.devに関してはアクセス自体にrate-limitedがあったりそもそも本番利用であまり薦められてないのであまり有効にして公開したくない。ということで今回に関しては少し例外的だが全てのアクセスをWorkersに集めて対応することにした。
この辺りのBucketの公開に関する話はこのドキュメントに書いてあるので興味がある人は読んでほしい。
それではR2の画像へのアクセスをWorkersで捌く設定をする。Workersへのリクエストに関する素の設定を行うにはserver.tsのfetch()を弄る。
https://*.workers.dev/images/a/b/c/hoge.jpgみたいなパスへのアクセスはa/b/c/hoge.jpgをkeyとしてR2にアップロードされてる画像を取得して返すようにしてる。
...
try {
const url = new URL(request.url);
if (url.pathname.startsWith("/images/")) {
const object = await env.BUCKET.get(
url.pathname.replace("/images", "").slice(1)
);
if (object === null) {
return new Response("Object Not Found", { status: 404 });
}
const headers = new Headers();
object.writeHttpMetadata(headers);
headers.set("etag", object.httpEtag);
return new Response(object.body, {
headers,
});
}
} catch (error) {}
...
URLごとにブックマーク数を管理する
Durable Object(DO)
雑に説明するとDurable Objectは状態を持ったクラスをCloudflareネットワークのグローバルなメモリに一意になるように展開してKey-Valueストア風なアクセスができるようにした強整合性を持つストレージ機能。Ethereumでコードを書いたことがある人はスマートコントラクトのコードをイメージするとわかりやすいかもしれない。
今回はURLごとのブックマーク数を記録するためにDurable Objectを使う。
wrangler.tomlに下記を追加。
[[durable_objects.bindings]]
name = "COUNTER"
class_name = "BookmarkCounter"
[[migrations]]
tag = "v1"
new_classes = ["BookmarkCounter"]
app/do/bookmark-counter.tsとしてカウンター用のクラスを作成する。
export class BookmarkCounter {
state: DurableObjectState;
constructor(state: DurableObjectState, _: Env) {
this.state = state;
}
async fetch(request: Request) {
let url = new URL(request.url);
let value: number = (await this.state.storage.get("value")) || 0;
switch (url.pathname) {
case "/increment":
++value;
break;
case "/decrement":
--value;
break;
case "/":
break;
default:
return new Response("Not found", { status: 404 });
}
await this.state.storage?.put("value", value);
return new Response(value.toString());
}
}
これでenv.COUNTER.fetch('http://../increment')とかenv.COUNTER.fetch('http://../decrement')みたいな感じでstateの値を増減できる。オブジェクトはページのURLのslugごとに作成されるので、例えばユーザーAとユーザーBがhttps://example.com/をブックマークしたらそのURLのDOには2が保存される。実装としてはこんな感じでブックマークの追加/削除/取得時に実行する感じ。
あとはserver.tsでexportする設定を追加するだけ。
...
import { BookmarkCounter } from "~/do/bookmark-counter";
export { BookmarkCounter };
...
Cron Triggerを追加する
今回のアプリには実用的な意味で使う場所がないけどCron Triggerも試しておきたいので適当なものを追加する。構造としてはQueueと同じ。ハンドラをapp/に作ってserver.tsに追加するだけ。cronの実行パターンはwrangler.tomlに追加すればOK。
import { scheduled } from "~/cron/scheduled";
...
queue,
scheduled, <- 追加
}
scheduledの中身はapp/cron/scheduled.ts。
実行パターンをwrangler.tomlに追記。サポートされてる記法はここを参照。
[triggers]
crons = "0 0 1 1 *"
[env.dev.triggers]
crons = "0 * * * *"
以下でCron Triggerをテスト実行できる。
npm run dev
curl "http://localhost:8787/__scheduled?cron=0+*+*+*+*"
記事のdescriptionを翻訳して表示
先日発表されたAI Gatewayを使いたいがためにブックマークされた記事のmeta descriptionを翻訳して表示する機能を追加する。特に意味の機能。
機能の実装はこのコミットを見てもらうとして、
AI Gatewayの設定について書く。と言っても特に難しいことはない。
dashboardにログインしてここにアクセス。
Create Gatewayというボタンから、エンドポイント名を作成する。今回はremix-workers-bookmarkにした。アプリ名と一緒。アプリごとにいくつもエンドポイントを作成できるので適当にUniqueな名前でOK。
そうしたらhttps://gateway.ai.cloudflare.com/v1/xxxxxxxxxx/適当なエンドポイント名/openaiみたいなURLが発行される。これを既存のOpenAI APIを叩いていた実装部分のBASE URLと差し替えるだけ。
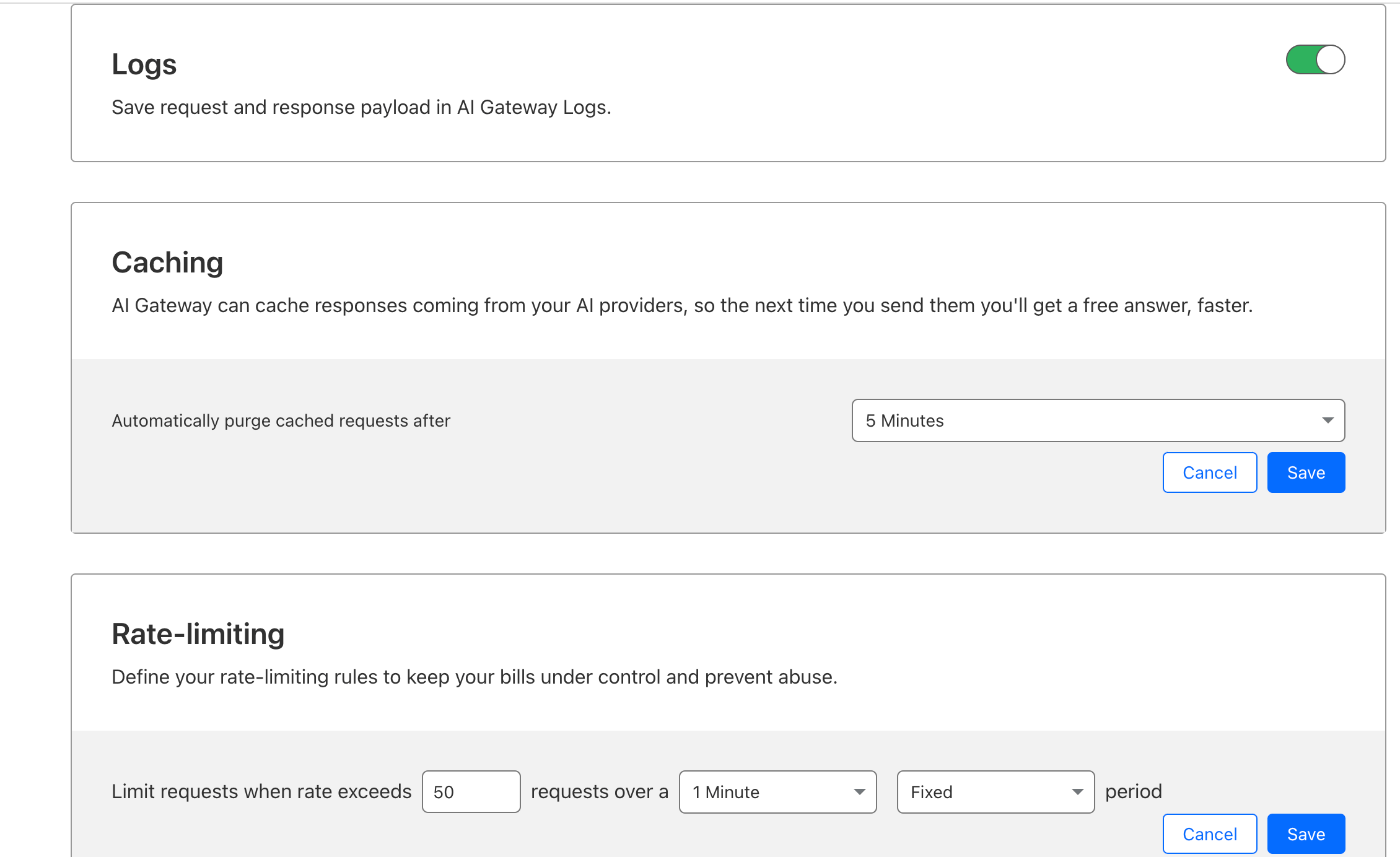
これだけでAI GatewayがOpenAI APIなどのバックエンドのAIサービスへのリクエストをプロキシしてくれる。
Analyticsやロギングはもちろん、リクエストのキャッシュやRate Limitingなんかもできるようになる。便利!!!
その他
Sentryの設定
Workers用のSentryのクライアントライブラリとしてtoucan.jsがある。
実装例は下記にある。
このアプリでは上記の例のfetch()に定義されているものをserver.tsに追加すると設定できるはず。
本番環境で動かす
ここまでで一旦ローカル環境では一通り動くものができたはず。次はこれを本番環境で動かす。最初に書いたがQueueやR2はPaid Planじゃないと本番では使えないので$5/month(720円くらい)の課金が必要。
Bindingsの設定
D1,KV,R2,Queue全てにおいてBindings(Workerから他のリソースへのアクセスを可能にするための設定)が必要。Cloudflare Workersではwrangler.tomlにちゃんと記載されていればデプロイすると勝手にやってくれるので特に問題なし。一方Cloudflare Pagesでは手動でやらないといけないので面倒。
環境変数の設定
Pages&Workers > Settings > Environment variablesで.dev.varsで定義してた変数を本番用のものに変更して手動設定する。秘匿情報はSecret Valueとして設定した方が良い。
D1へmigrationの適用
やるだけ。
npx migrations:apply
デプロイ
やるだけ。
npm run deploy
デバッグ
下記のコマンドでWorkersへのリクエストのログが見られる。
npx wrangler tail <your workers name>
検証
あとは生成されたURL(https://hoge.bar.workers.dev/loginみたいなやつ)にアクセスして確認するだけ。問題があれば先のデバッグコマンドでログを見て確認する。アプリ内でconsole.logするとログが出力されるのであとはよしなにやる。
CI/CD
GitHub ActionsにPushするとActionsタブにデプロイ可能なボタンが表示されるようにする。
.github/workflows/release.ymlにこんな感じの設定を書いた。
name: Release
on:
workflow_dispatch:
inputs:
environment:
description: "Include the migrations:apply command in the postCommands step? (yes/no)"
required: true
default: "no"
jobs:
release:
runs-on: ubuntu-latest
name: Release
steps:
- uses: actions/checkout@v3
- name: Use Node.js 18
uses: actions/setup-node@v3
with:
node-version: 18
- run: npm install
- name: Deploy
uses: cloudflare/wrangler-action@v3
with:
apiToken: ${{ secrets.CF_API_TOKEN }}
accountId: ${{ secrets.CF_ACCOUNT_ID }}
preCommands: npm run prod:build
postCommands: |
if [ "${{ github.event.inputs.name }}" = "yes" ]; then npm run migrations:apply; else echo "Skipping migrations:apply"; fi
Cloudflare APIの生成に関してはこのドキュメントを参照。
Workersのデプロイに関しては公式のデプロイActionを使った。
また、workflow_dispatchを使い、migrationを適用するか否かを手動で入力してボタンクリックでデプロイできるようにしてる。
あとテストとかlintとかは適宜好きなものを各ステップに足してほしい。
まとめ
RemixにCloudflare Workersの色々(D1/KV/Queue/R2/DO/Cron Trigger)を組み合わせてアプリを作る流れについて書いた。
Next.jsについてはよく使っていたので大体の所作は分かっていたがRemixについては初めてだったので思うように実装できないところもあり苦戦した。ただこの辺は慣れかもしれない。
巷でNext.jsにServer Componentが導入されて本格的にフルスタックアプリケーション開発だみたいな話が賑わいをみせていたけど、正直Railsに慣れてる身からすると非同期実行処理とか定期バッチ実行とかマイグレーションの管理とか必須に思える機能の整備が微妙なのでフルスタックというにはまだイマイチだよなーと不満があった。今回はCloudflare製品を出来るだけ使っていかに自分好みのフルスタックに近づけられるかというのが一つの目的だったのでやりたいことはそれなりにできそうに思えたのは収穫。無料枠も豊富だから$5/monthからの課金だけでそれなりに使えそうなのも個人開発とかには良いかも。
一方でD1はOpen AlphaだしQueueはOpen Betaなのでまだまだ業務で本番導入するには心許ないしDrizzleはマイグレーション管理周りで不十分なので微妙な点は色々ある(まぁSQL周りに関してはPrismaなりsqlcなり好きなものを使えば良い)。しかしWorkers含めCloudflare製品自体はパワフルで将来的に期待できる技術が多そうなので何ができるか含め今のうちにキャッチアップしておけたのはよかった。
引き続きWorkersにアップデートや新機能追加があればこのアプリに対してキメラ的に統合して試していく予定。
Discussion