【Yozora Diff:決算版】#3 新旧の決算短信の文を対応付けて差分を捉えよう!
はじめに
こんにちは!Rayです。普段は自然言語処理(NLP)の研究をしています。
僕たちは、Yozora Financeという学生コミュニティで、誰もが自分だけの投資エージェントを開発できる世界を目指して活動しています。
その中の基盤モジュール群のひとつとして、開示文書の差分に特化したシリーズを開発しており、それが Yozora Diff です。完成後は誰でも使えるようオープンソースで公開予定です!
前回は決算短信をXBRL/PDFから扱いやすいJSONにパースしました。
今回はそこから一歩進んで、「新旧どの文が対応関係にあるのか?」を文単位でアライメント(対応付け)していきます。
「意味のある差分」を取るためには、まず“どの文とどの文を比較すべきか”を正しく決める必要があるので非常に重要です。
文のアライメントとは?
文の対応付けとは、「旧版のどの文と新版のどの文を比較すべきか」を決める工程です。
このステップを正しく行っておかないと、後段の“差分”そのものが誤った箇所から抽出されてしまいます。
- 誤:似た場所でない文が比較される → 間違った差分
- 正:同じ文脈の文同士を比較する → 意味のある差分が取れる
決算短信はテンプレート的な文が多く、表現がほぼ同じ箇所も複数あります。
そのため「まず比較相手を正しく決めること」が差分抽出の成否を左右します。
方針
決算短信はフォーマットがかなり固定されているため、バージョンが変わっても全体構造は大きく変わりません。この特徴を活かし、まず章単位で対応付けを行い、その後に各章内の文同士を対応付けるという二段階アライメントを行います。
①章単位アライメント
無関係の文章同士を対応させないために範囲を絞り込みます。「1.当中間決算に関する定性的情報」と「1.当四半期決算に関する定性的情報」といった大枠を対応付けます。
「1.当中間決算に関する定性的情報」のさらにその中に含まれる「(1)経営成績に関する説明」のような最小単位の章まで対応付けることで、範囲を大幅に絞り込むことが可能です。
②文単位アライメント
対応付けた章の中で、文を対応付けます。added/deleted/matchedの3種類のラベルを付与することで、意味的な差分を可視化できます。
決算短信ではテンプレート文章の再利用が多く、文ごとの揺れも少ないです。
そのため、アライメントは高コストな埋め込みやモデル推論などを使わずにPython標準ライブラリのSequenceMatcherだけで十分上手く行きました。
SequenceMatcher
SequenceMatcherはdifflibに含まれる2つの文字列の“共通部分”を探すアルゴリズムです。
簡単に動作を説明すると、2つの文字列からLCS(最長共通部分列)を見つけ、それを除いた部分からLCSを見つけというのを繰り返し共通部分を見つけます。
今回は2つの文章の平均長に対する同じ文字列の割合であるSequenceMatcher().ratio()を使用しました。
章単位アライメント
章の並び順は基本的に変わらないので、先頭の章から順番に、新旧の章同士の類似度を計算し、閾値を超えた時点でマッチングさせています。
サブセクションが存在する場合は、同じ基準で最小単位の章(例: 1.→(1)→①のような構造)までマッチングを行います。
類似度の評価は次の順で行い、閾値を超えた瞬間マッチングさせます
| 比較対象 | 処理 | 閾値 |
|---|---|---|
| 見出し | 章番号を除去、短文正規化 *1 | 0.5 |
| サブ見出し(存在すれば) | 〃 | 0.5 |
| 本文 | 数字を<NUM>に置換 *2+\sを除去 |
0.3 *3 |
*1 SequenceMatcher().ratio()は2つの文章の平均長を分母に取るため、片方が短文だと過小評価されます。そのため見出しの計算では短い方の長さに対する割合を計算しています。
*2 業績説明のように文の構造は同じ/数値だけ毎期変わるケースが多いため、数字をマスクしないと類似度が過剰に低くなります。ちなみに、この処理は1回目で紹介した研究でも行われていました。(鈴木ら, 2023)
*3 閾値0.3は検証データから決めた値ですが、実際にはほとんどの章で0.5以上となります。
文単位アライメント
このままアライメントしてもそこそこうまく行くのですが、章が長い場合は誤対応が増えるのでもう一工夫必要です。
そこで、章の中に登場する(キャッシュ・フローの状況)のような小見出し(ミニセクション)を“アンカー”として使い、マッチング範囲をさらに絞り込みます。
※サブセクション=目次に載る見出し
※小見出し(ミニセクション)=本文中にのみ現れる最小単位の見出し
小見出しの判定は以下の2条件で行います。
- 改行記号で分割後の長さが40文字以下
- I, ( , [ や 1 などから始まる
こうして 章 → 小見出し単位まで対応範囲を絞り込んだ上で、対応する範囲の文同士について数字の<NUM>マスク+空白除去を行い、類似度を計算して最終的な文対応を決定します。
この時も、章単位の時と同様に先頭の文から順番に、新旧の文同士の類似度を計算し、閾値を超えた時点でマッチングさせています。
結果
それぞれアライメントした結果がこんな感じです。
文アライメントはまだ少し微妙な部分があります。SequenceMatcherは字面しか捉えないので仕方ないですね。とはいえ、下の画像のように上手く行く部分もあるので、全然使えそうです。
まあ今回は投資的な意味の近さでなく、一般的な意味の近さでマッチングさせているので、普通の埋め込みモデルで改善できそうです。
章アライメント結果

文アライメント結果①

文アライメント結果②
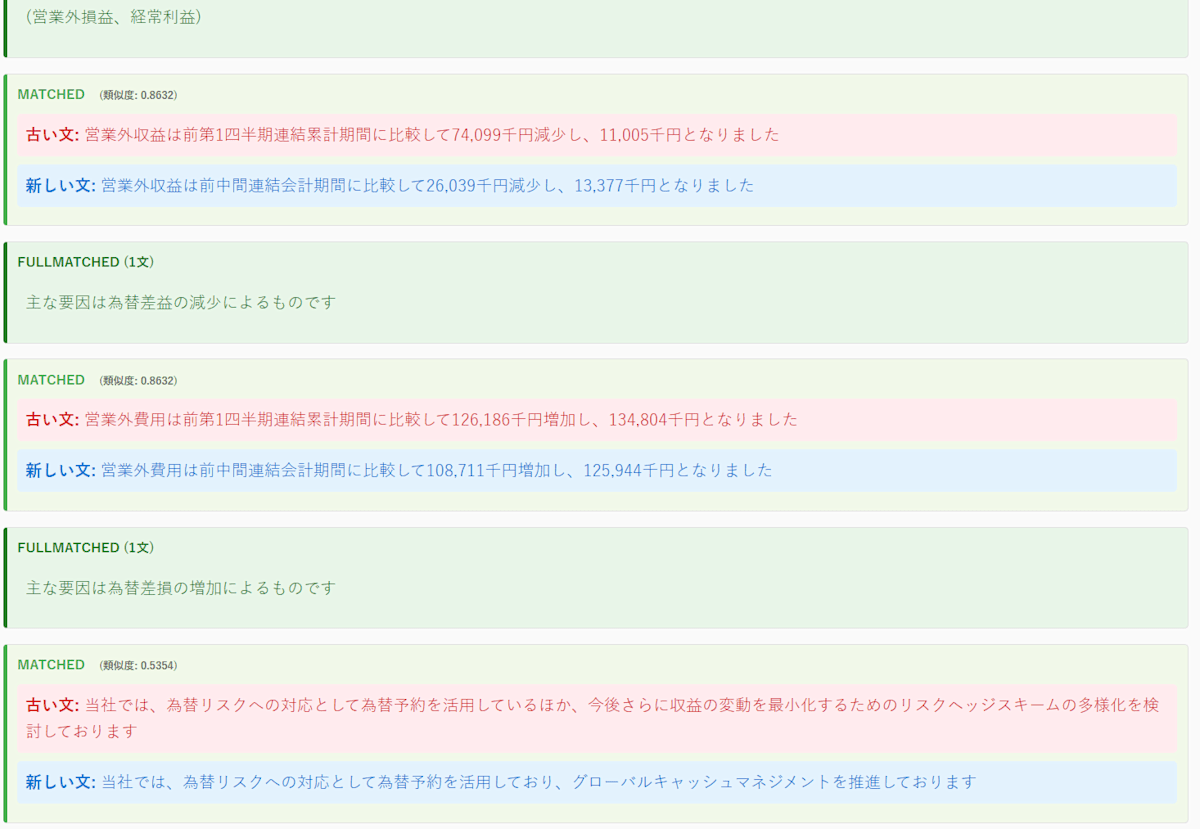
*この部分では(営業外損益、経常利益)が小見出しになっています。
まとめ
文アライメント結果②のように、財政説明部分のようなテンプレート構造の強い箇所は上手くいきました。一方で、字面は違うが意味的には同じ文章までマッチできないケースもあり、ここはSequenceMatcherアプローチ上しょうがないです。全体的には上手くいってそうなので将来的に改善します。
とはいえ、ここまで文レベルで対応付けができたからこそ、次の段階で「どんな変化があったか」をLLMに正確に要約させることが可能になります。
つまり「土台となる正しいマッチング」ができたことで、いよいよ“意味の変化そのもの”に踏み込めるようになりました。
次回は、このアライメント結果を入力として、LLMに差分を要約させていきます。
全文を読まずとも“どこがどう変わったか”を一目で正確に把握できるようになります。
今回も最後までお付き合いいただきありがとうございました。次回もぜひお楽しみに!
参考文献
- 鈴木雅弘, 坂地泰紀, 和泉潔. 2023. 時系列に並んだ金融文書からの差分抽出タスクの提案. 2023年度人工知能学会全国大会(第37回).
Discussion