Open3
動画生成に使えそうなデータセット一覧
| データセット | 公開年 | 規模・内容 | キャプション / プロンプト | 代表的な解像度 | ライセンス・入手方法 | 特徴・補足 |
|---|---|---|---|---|---|---|
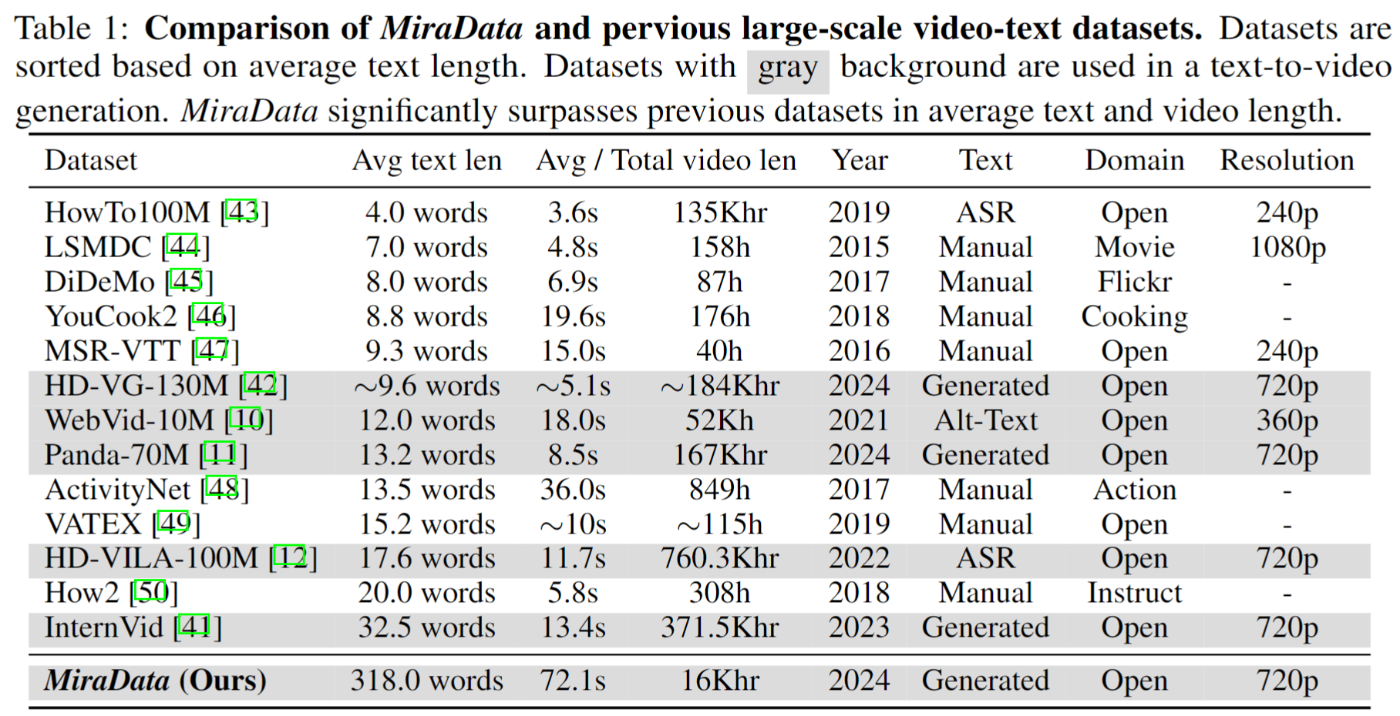
| Panda-70M | 2024 | 7 千万クリップ/高解像度 | 複数教師モデルで抽出した高品質キャプション | 720–1080 p | GitHub+URL (research-only) ([arXiv][1]) | HD-VILA から抽出 → 自動選別で“きれいな”字幕付き。汎用 T2V の新定番候補 |
| MiraData | 2024 | 345 Kロング動画(平均30 s) | GPT-4V による階層キャプション+4視点属性 | 720–1080 p | HuggingFace(研究目的) ([arXiv][2]) | ロングモーション&強い動き。MiraBench 評価セット同梱 |
| VidGen-1M | 2024 | 100 万クリップ | Coarse-to-Fine で整形した詳細キャプション | 720 p+ | GitHub / HF (research-only) ([arXiv][3]) | 時間的整合性の高さを売りにした軽量セット |
| HOIGen-1M | 2025 | 104 万 HOI 動画 | Mixture-of-MM Experts 生成キャプション | 512–720 p | 申請制(学術) ([arXiv][4]) | “人物×物体” 相互作用を網羅。T2V の動作精度ベンチに最適 |
| CFC-VIDS-1M | 2025 | 100 万クリップ | VLM で精緻化したキャプション | 720 p | 近日公開予定 (Raccoon 論文) ([arXiv][5]) | 品質重視の 4-段階キュレーション。Raccoon モデルと併用 |
| HD-VG-130M | 2023 | 1.3 億クリップ | 自動抽出キャプション | 1080 p(ワイド) | GoogleDrive+ライセンス同意 (academic-only) ([GitHub][6]) | VideoFactory 論文が提唱。高解像度&ワイド比率・WM なし |
| HowTo100M | 2019 | 1.36 億クリップ/約15 年 | 自動字幕 (ASR) | 480–720 p | Web スクレイプ (YT) ([Papers with Code][7]) | “実演系”が中心。音声付きマルチモーダル前訓練の古典 |
| WebVid-10M | 2021 | 1,000 万クリップ | 自然文キャプション | 720 p まで | URL リスト (stock site) | 既存表で紹介済み — デファクト標準 |
| HD-VILA-100M | 2022 | 330 万長尺動画 → 37 万時間 | ASR 字幕 & メタ | 720 p+ | URL (YouTube) | 高解像度&多ジャンル |
| VideoCC (6.3 M / 12 M) | 2022 | 630〜1,200 万 | CC-BY キャプション | 480–1080 p | CC-BY-4.0 | 法的に扱いやすい |
| OpenVid-1M / HD-0.4M | 2024 | 100 万 / 43 万(HD) | LLM リライト高品質 | 1080 p | HF (research-only) | 軽量かつ高精度 |
| LVD-2M | 2024 | 200 万 (≥10 s) | 時間密キャプション | 720–1080 p | 申請制 | ロングホライズン学習 |
| VidProM | 2024 | 167 万プロンプト+生成動画 | 生成側 プロンプト | 256–1024 p | HF (CC-BY-NC 4.0) | プロンプト工学研究向け |
| Ego4D / Ego4D-HCap | 2021–23 | 3,670 時間 | 階層キャプション | 960 p | Consortium 承認 | 主観視点 |
| Kinetics-700 | 2020 | 65 万 (10 s) | 行動ラベル | 320 p | URL (YouTube) | 動作多様性 |
| UCF-101 | 2012 | 1.3 万 | 行動ラベル | 320 p | 直DL | 小規模・実験用 |
最新セット活用のポイント
-
Panda-70M × WebVid の 2 段プリトレ
- まず WebVid で粗学習 → Panda で高品質ファインチューンが流行。
-
ロング動画強化は MiraData or LVD-2M
- 10 s 上限の既存コーパスではカメラワークが貧弱になりがち。
-
人と物の相互作用を重視するアプリ
- HOIGen-1M を追加すると “手元+道具” の生成精度が向上。
-
研究コストを抑えたい個人 / スモール GPU
- VidGen-1M や OpenVid-1M は 4×A100 程度でも回し切れるサイズ。
-
高解像・ワイド比率モデルを目指す場合
- HD-VG-130M(HD-VG-40M subset)で事前学習、SDXL VAE 併用が有効。
主な動画生成データセット──ダウンロード方法早見表
| データセット | 取得できるもの | 公式取得手段 / スクリプト | 追加ツール・前提 | 備考 |
|---|---|---|---|---|
| OpenVid-1M / OpenVidHD-0.4M |
.tar 分割ファイル(HuggingFace 直置き) |
git lfs install && git clone … もしくは huggingface-cli download/datasets.load_dataset("OpenVid-1M")
|
Git LFS, 200 GB 以上空き | 完全ミラーなので YouTube など外部 DL 不要 ([Hugging Face][1]) |
| Panda-70M | URL & メタ CSV + DL スクリプト | python tools/download.py --config full.yaml |
yt-dlp, FFmpeg, 約 36 TB |
10 M/2 M の軽量サブセット YAML も同梱 ([snap-research.github.io][2]) |
| MiraData |
.parquet 連番(HuggingFace) |
datasets.load_dataset("TencentARC/MiraData") で自動ストリーミング |
Git LFS, 約 15 TB | ロング動画向け。分割取得可 ([Hugging Face][3]) |
| VidGen-1M | HF ストレージ(zip 50 GB ×20) | huggingface-cli download Fudan-FUXI/VIDGEN-1M |
Git LFS | 軽量なのでローカル GPU 学習向き ([Hugging Face][4]) |
| HOIGen-1M | HF 分割 tar(約 200 GB) | datasets.load_dataset("HOIGen/HOIGen-1M") |
Git LFS | 研究オンリーライセンス ([Hugging Face][5]) |
| CFC-VIDS-1M | URL リスト+β版 DL スクリプト | 論文付属 video2dataset 設定ファイルを実行 |
video2dataset, yt-dlp
|
2025-Q3 公開予定(現時点は論文のみ) ([GitHub][6]) |
| HD-VG-130M | URL CSV(1.8 GB)+サンプル CLI | python tools/download_hdvg.py --list hdvg.csv |
yt-dlp, Ray, LanceDB |
ワイド比率。解像度ごとにフォルダ分割 ([GitHub][7]) |
| HD-VILA-100M | URL list(jsonl)+ Ray DL スクリプト | python download_hd_vila.py --input meta.jsonl |
yt-dlp, ray[default]
|
Microsoft XPretrain リポに詳細 ([GitHub][8], [Gist][9]) |
| WebVid-10M | Shutterstock/Pond5 URL CSV | video2dataset --url_list webvid_10m.csv … |
video2dataset, 商用サイト APIキー不要 |
失効 URL 自動スキップ機能あり ([GitHub][10], [GitHub][11]) |
| VideoCC (6.3 M/12 M) | CC-BY URL TSV | video2dataset --url_list videocc.tsv |
video2dataset |
法的に扱いやすく再配布可 ([GitHub][12]) |
| HowTo100M | URL & 字幕 CSV | ①フォーム申請→アノテーション取得 ②公式 download_youtube.sh
|
yt-dlp, 12 TB+ |
音声付き。失効率高め ([GitHub][13]) |
| LVD-2M | URL CSV+公式 download_videos_release.py
|
python download_videos_release.py --out_dir videos |
yt-dlp, FFmpeg |
≥10 s の長尺のみを自動抽出 ([GitHub][14]) |
| VidProM | HF 直置き(生成動画+prompt) | datasets.load_dataset("WenhaoWang/VidProM") |
Git LFS, 5 TB | 合成動画なので著作権クリーン ([Hugging Face][15]) |
| Ego4D / Ego4D-HCap | 専用 Downloader CLI |
pip install ego4d → ego4d-download --token YOUR_KEY
|
承認キー, ~14 TB | CLI でサブセット指定可 ([docs.ego-exo4d-data.org][16]) |
| Kinetics-700 | DeepMind URL CSV+k700_downloader.sh
|
bash k700_2020_downloader.sh |
yt-dlp, FFmpeg, 650 GB |
Academic Torrents ミラーも有 ([GitHub][17]) |
| UCF-101 | 直接 ZIP(6.5 GB) |
wget https://www.crcv.ucf.edu/data/UCF101/UCF101.rar → 解凍 |
rar/zip ツール | 超小規模・検証用 ([TensorFlow][18]) |
使い分け早見
- 外部サイトに依存せず一撃 DL したい → OpenVid, VidGen, HOIGen, VidProM, MiraData
- URL から自前クロール派 → Panda-70M, WebVid, HD-VILA, VideoCC, HD-VG, LVD
- コンソーシアム or 申請が必要 → Ego4D, LVD-2M (research-only), 一部 HOIGen
- ストレージが限られている → VidGen-1M(50 GB), UCF-101(6 GB)でプロトタイピング