🖥️
計算効率上限界のバッチサイズを推定する方法[An Empirical Model of Large-Batch Training]
本記事では以下の論文を解説する。
An Empirical Model of Large-Batch Training
これは、2018年にOpenAIから出た論文である。
Scaling Laws for Neural Language Modelsでも言及されている。
なにこれ?
- 複数GPUで分散的に学習するとき有効に計算資源を活用するためにバッチサイズを上げることがある
- そこでバッチサイズを増やして学習率を上げてを繰り返してもいいが、あるラインを超えると計算効率が著しく低下する
- その限界となるバッチサイズはミニバッチ内の勾配分散と、全体の勾配から事前に推定可能
- 以下の式で限界のバッチサイズを大まかに推定できる
\mathcal{B}_\text{simple} = \frac{\text{tr}(Σ)}{|G|^2}
具体的に
-
学習時間(そのロスを達成するのに必要なoptimization steps)と計算資源(バッチサイズ)の図(Gradient accumulation=1)

-
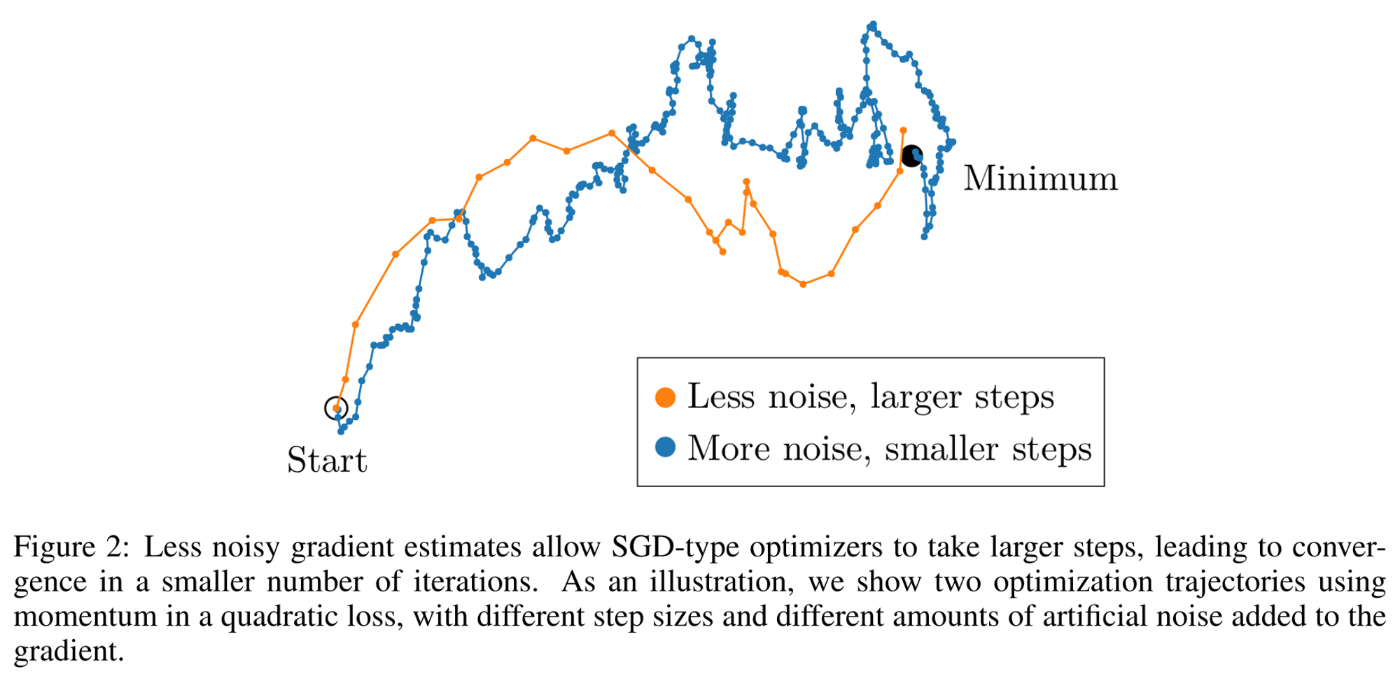
バッチサイズを大きくすればノイズは小さくなり大きなSGDのステップを取れ、より少ないイテレーションで収束可
-
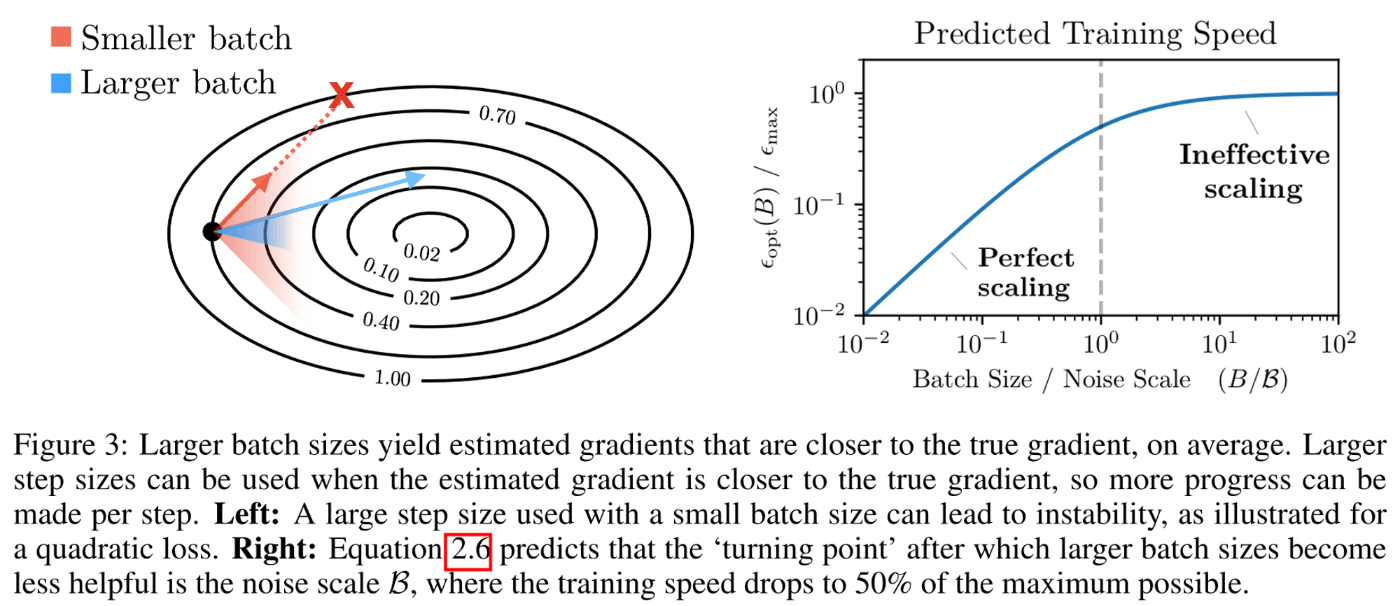
ただし、ある程度バッチサイズを大きくし勾配を正確に推測可能になると、それ以上バッチサイズを増やしても改善されない限界が現れる
- これは上のグラフでも表れていて、青い領域の上側となるようなラインはバッチサイズを増やしてもあまり学習時間に改善が見られない
- とあるラインを超えるてバッチサイズを増やしても学習率を増やせない事を表したグラフが下の右
- バッチサイズ
B B<\mathcal{B} \epsilon_\text{opt} -
B>\mathcal{B} \epsilon_\text{opt} -
\mathcal{B}
- バッチサイズ
以下の様に変数を定義する
-
H -
G -
G_\text{est} B
モデルパラメータ
これを最小化する学習率
なお、
ここで、
しかし、
よってこれを計算することで、ざっくりとバッチサイズの限界を推定することができる
PS: あくまで1学部生が調べたものであるので間違えたところがある可能性が有るのでその場合は是非教えてください。
Discussion