prisma + PostgreSQL + pgvectorで顔の類似検索をしてみる
初めに
PostgreSQL の拡張モジュールである pgvector を使用すると、PostgreSQL 上でベクトル管理・検索が行えます。
今回は pgvector を用いて似ている顔を検索するプログラムを作成します。
typesprict で作成した web アプリケーションに組み込むことを前提としているので prisma を用います。
ではやっていきましょう。
データベースの作成 → prisma client の作成
PostgreSQL と pgvector の用意
pgvector の拡張モジュールをインストールするのが面倒でしたので、
DockerHub で探すと ankane/pgvector:v0.4.4 という image があったのでこれを使用しました。
prsima で migrate
まずは prisma で init し、schema を書いていきます。
書き方は以下を参考にしました。
generator client {
provider = "prisma-client-js"
previewFeatures = ["postgresqlExtensions"]
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
extensions = [pgvector(map: "vector", schema: "public")]
}
model FaceEmbedding {
id Int @id @default(autoincrement())
personId Int
embedding Unsupported("vector")
}
マイグレーションとクライアントの作成を行います。
npx prisma migrate dev
prisma generate
画像から顔の特徴量を取り出し、DB へ保存する
画像の用意
水瀬いのり、佐倉綾音、大西沙織の画像を 5 枚づつ用意しました。
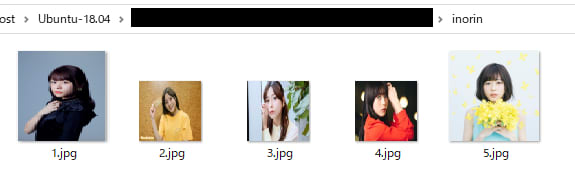
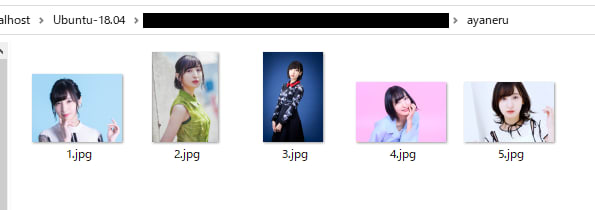
各画像から顔の特徴量の抽出
今回は顔の特徴量の作成に facenet-pytorch のライブラリを使用しました。
これを用いると顔から 512 次元のベクトルで特徴量を抽出してくれます。
各画像に対して特徴量の抽出を行います。
img = Image.open(os.path.join(img_dir, filename))
face = mtcnn(img)
emb = resnet(face.unsqueeze(0)).detach().numpy()
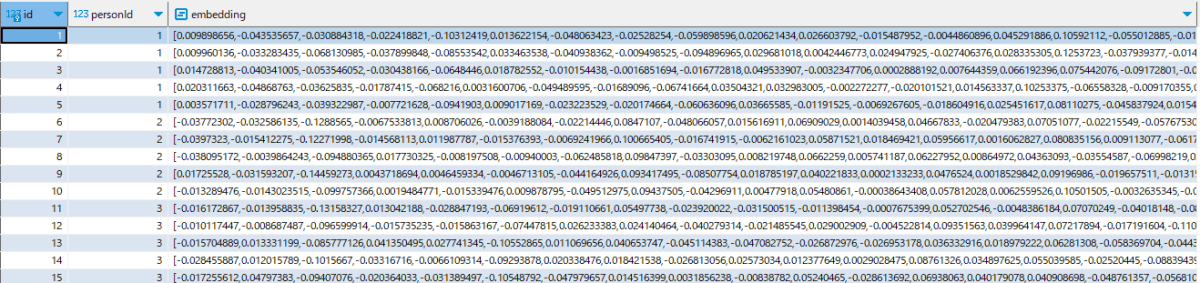
db にベクトルを insert する
python で pgvector を扱うライブラリがありました。
これを使用して、作成したベクトルを DB に保存します。
水瀬いのり、佐倉綾音、大西沙織の順に、personId は 1,2,3 と設定しました。
以下は psycopg2 を使用した場合の例です。
import psycopg2
from pgvector.psycopg2 import register_vector
conn = psycopg2.connect(host=host, dbname=dbname, user=user, password=password)
register_vector(conn)
cur = conn.cursor()
cur.execute('INSERT INTO "FaceEmbedding" ("personId", embedding) VALUES (1, %s)', (emb,))
conn.commit()
挿入できました。
顔類似検索を行う
prisma でクエリをたたく雛形を作成
import { PrismaClient } from "@prisma/client"
const prisma = new PrismaClient()
async function main() {
const list = await prisma.$queryRaw`
SELECT
id, "personId"
FROM
"FaceEmbedding"
`
console.log(list)
}
main()
[
{ id: 1, personId: 1 },
{ id: 2, personId: 1 },
{ id: 3, personId: 1 },
{ id: 4, personId: 1 },
{ id: 5, personId: 1 },
{ id: 6, personId: 2 },
{ id: 7, personId: 2 },
{ id: 8, personId: 2 },
{ id: 9, personId: 2 },
{ id: 10, personId: 2 },
{ id: 11, personId: 3 },
{ id: 12, personId: 3 },
{ id: 13, personId: 3 },
{ id: 14, personId: 3 },
{ id: 15, personId: 3 }
]
実際に類似検索を行う
では、実際にベクトルを使ってクエリをたたきます。
id:1 の水瀬いのりの顔の特徴量を用いて、cos 距離を使用して距離が近い順に上から 5 個取得します。
ついでに cos 類似度も表示します。
水瀬いのりの画像は 5 枚登録しているので、 LIMIT 5 で usetId が全部 1 ならちゃんと似ている顔を検索できていると言えそうです。
クエリはこうです。
SELECT
id, "personId", 1 - (embedding <=> (SELECT embedding FROM "FaceEmbedding" WHERE id = 1)) AS cosine_similarity
FROM
"FaceEmbedding"
ORDER BY
embedding <=> (SELECT embedding FROM "FaceEmbedding" WHERE id = 1)
LIMIT 5
結果はこうです。
[
{ id: 1, personId: 1, cosine_similarity: 1 },
{ id: 5, personId: 1, cosine_similarity: 0.9087675117139582 },
{ id: 4, personId: 1, cosine_similarity: 0.8679171024203919 },
{ id: 2, personId: 1, cosine_similarity: 0.8474558816347088 },
{ id: 3, personId: 1, cosine_similarity: 0.7921975676309791 }
]
ちゃんと取得できていそうです。
id:11 の特徴量を使用した場合のクエリを実行します。
personId は 3 なので大西沙織ですね
SELECT
id, "personId", 1 - (embedding <=> (SELECT embedding FROM "FaceEmbedding" WHERE id = 12)) AS cosine_similarity
FROM
"FaceEmbedding"
ORDER BY
embedding <=> (SELECT embedding FROM "FaceEmbedding" WHERE id = 12)
LIMIT 5
[
{ id: 12, personId: 3, cosine_similarity: 1 },
{ id: 14, personId: 3, cosine_similarity: 0.8723990442868933 },
{ id: 11, personId: 3, cosine_similarity: 0.8329527631679011 },
{ id: 13, personId: 3, cosine_similarity: 0.7559596640701564 },
{ id: 15, personId: 3, cosine_similarity: 0.7152676916689075 }
]
ちゃんと似た顔を抽出できていそうです。
ちなみに LIMIT を外してすべてスコアを出してみます。
[
{ id: 1, personId: 1, cosine_similarity: 1 },
{ id: 5, personId: 1, cosine_similarity: 0.9087675117139582 },
{ id: 4, personId: 1, cosine_similarity: 0.8679171024203919 },
{ id: 2, personId: 1, cosine_similarity: 0.8474558816347088 },
{ id: 3, personId: 1, cosine_similarity: 0.7921975676309791 },
{ id: 12, personId: 3, cosine_similarity: 0.4142360076233724 },
{ id: 15, personId: 3, cosine_similarity: 0.41278395343945573 },
{ id: 11, personId: 3, cosine_similarity: 0.35532161824856123 },
{ id: 14, personId: 3, cosine_similarity: 0.30938845868067055 },
{ id: 13, personId: 3, cosine_similarity: 0.23102589274443774 },
{ id: 9, personId: 2, cosine_similarity: 0.22384490461591244 },
{ id: 10, personId: 2, cosine_similarity: 0.1999829384866848 },
{ id: 7, personId: 2, cosine_similarity: 0.1632603921874849 },
{ id: 6, personId: 2, cosine_similarity: 0.12457679634476515 },
{ id: 8, personId: 2, cosine_similarity: 0.10706567962724378 }
]
水瀬いのりは、佐倉綾音と大西沙織ならどちらかというと、大西沙織に似ているようです。
まとめ
普通に使えそうでとてもよかったです。
PostgreSQL でベクトル検索ができるのは大変ありがたいです。
RDS とかでも使えるみたいですしね。
ベクトルデータベースの Pinecone とか結構値段するので個人開発にはきついですからね、、、
Discussion