これで合格!Associate Data Practitioner 試験攻略法【2025 年 9 月版】
0. はじめに
みなさん、こんにちは!ラリオスです。
ビジネスでデータ活用が当たり前になった今、「何から学べばいいんだろう?」と悩んでいる方も多いのではないでしょうか。そんなデータ活用の「はじめの一歩」として、今回ご紹介したいのが Google Cloud の 「Associate Data Practitioner」 認定資格です。
この資格は、データ アナリストやマーケター、そしてこれからデータの世界に飛び込みたいと考えているすべての方を対象に、データがビジネスの価値に変わるまでの流れと、そのために必要な Google Cloud のツール知識を問うものです。
この記事では、Associate Data Practitioner の合格に必要な知識を、データ パイプラインの基本から、分析の心臓部である BigQuery の使い方、さらには機械学習の初歩まで、体系的に、そして分かりやすく解説します。単なる用語の暗記ではなく、「なぜこのツールを使うのか」「どんな場面で役立つのか」 が腑に落ちるように、実践的なポイントをしっかり押さえていきます。
この記事を読み終える頃には、試験合格への道筋がはっきりと見えているはずです。それでは、さっそく見ていきましょう。
1. Associate Data Practitioner 認定資格とは?
まずは、この資格がどのようなものか、全体像をしっかりつかむところから始めましょう。
1.1. どんな人におすすめの資格?
Google Cloud の公式サイトでは、この資格は「Google Cloud を使用してデータの収集、変換、可視化を行う担当者」向けとされています。
具体的には、以下のような方々におすすめです。
- データ アナリスト、ビジネス アナリスト
- BI(ビジネス インテリジェンス)担当者
- マーケティング担当者
- これからデータ関連のキャリアを歩みたい学生や IT 初心者
- Google Cloud のデータ技術の基礎を体系的に学びたいエンジニア
この資格の大きな特徴は、必ずしもプログラミングやインフラの深い知識がなくても挑戦できる点です。重要なのは、「ビジネス上の課題を、Google Cloud のどのデータサービスを使って解決できるか」を理解していることです。
1.2. なぜ今、この資格が注目されるのか
現代のビジネスにおいて、データは「21 世紀の石油」とも呼ばれるほど重要な経営資源です。しかし、ただデータを集めるだけでは意味がありません。そのデータを整理し(前処理)、分析し(加工)、誰もが理解できる形で見えるようにして(可視化)、初めてビジネス上の意思決定に活かすことができます。
Associate Data Practitioner 資格は、まさにこの一連のプロセスを Google Cloud 上で実践するための知識を証明するものです。この資格を取得することは、単にツールの使い方を知っているだけでなく、データを価値に変えるための基本的な考え方とスキルをもっていることの証となります。
1.3. 試験の概要
試験に挑戦する前に、基本的な情報を確認しておきましょう。
- 試験時間|2 時間
- 問題数|50 〜 60 問
- 形式|多肢選択式(単一または複数選択)
- 受験方法|テストセンターでの受験、またはオンラインでの遠隔監視付き受験
- 料金|$125(税別)
- 言語丨英語、日本語
(2025 年 9 月 30 日現在)日本語化が待ち遠しいですね! - 前提条件|とくになし
- 推奨される経験|Google Cloud でのデータ処理の経験が 6 か月以上
- 有効期間|3 年間
「経験 6 か月」と聞くと少し身構えてしまうかもしれませんが、心配は不要です。この記事と、Google Cloud が提供する無料の学習コンテンツなどを活用すれば、未経験からでも十分に合格を狙えます。
1.4. Google Skills を活用しよう!
Google Skills(旧 Cloud Skills Boost) は Google Cloud 公式のオンライントレーニングサイトです。オンデマンドのコースや実際に Google Cloud の環境を操作するハンズオンラボを通して、実践的なスキルを学ぶことができます。私の記事とあわせて、ぜひ活用してみてくださいね。
-
Google Skills にアクセスして、右上の 「参加」ボタンから個人の Google アカウントで登録(メールでの認証を求められます)

-
登録が完了したら、画面左の 「サブスクリプション」 をクリックして 「No cost」 を選択。


-
「Google Cloud Innovators」 の登録を求められるので登録してください。完了すると毎月 35 クレジットが付与されます。


-
以下の 「Associate Data Practitioner 学習プログラム」 にアクセスして学習を開始しましょう!有料のラボも、付与されたクレジットで実行することができます。
1.5. NotebookLM と併用すれば学習効果倍増!
この記事の内容を NotebookLM に読み込ませて公開しています。音声や動画の解説、クイズやマインドマップを活用することで、学習効果を向上させることができます。
それでは、次のセクションからいよいよ解説のスタートです!さいごまでじっくり読んでくださいね。
2. データ パイプラインの基本をマスター!ETL と ELT
データ分析の最初のステップは、さまざまな場所に散らばった生データを、分析しやすい形に整え、分析基盤(データ ウェアハウス)に集めることです。この一連のデータの流れを 「データ パイプライン」 と呼びます。
このパイプラインの構築方法には、主に 「ETL」 と 「ELT」 という 2 つのアプローチがあります。この違いの理解は、適切な Google Cloud サービスを選択する上で不可欠です。
- ETL(Extract、Transform、Load)|データを抽出し、分析しやすいように変換(加工)してから、データ ウェアハウスに格納する、伝統的なアプローチです。(変換 → 格納)
- ELT(Extract、Load、Transform)|まず生のデータをそのままデータ ウェアハウスに格納し、分析の必要に応じて、データ ウェアハウスの強力な計算能力を使って 変換(加工) する、モダンなアプローチです。(格納 → 変換)
現在は、後述する BigQuery のような高性能なデータ ウェアハウスの登場により、ELT が主流になりつつあります。試験では、「どのタイミングでデータを変換するか」がサービス選定の鍵となります。
2.1. 要件で学ぶ!Google Cloud のデータ パイプライン ツール
Google Cloud には、データ パイプラインを構築するためのサービスが複数用意されています。「どこから来たデータ(データソース)」 を 「どのように処理したいか」 によって、適切なツールを使い分けることが重要です。

それぞれのサービスを、データの流れに沿って見ていきましょう。
ステップ 1|データの入り口となるサービス
まず、リアルタイムで発生し続ける「ストリーミング データ」を受け取るための入り口となるサービスです。
-
Pub/Sub|あらゆるイベントデータの受付窓口
Pub/Sub は、Google Cloud におけるメッセージング サービスの中核です。IoT デバイス、アプリケーションのログ、Web サイトのクリック情報など、絶え間なく発生する 「イベントデータ」 を、リアルタイムかつ大規模に受け取ることができます。
受け取ったデータは、後続の Dataflow などが処理するまでの間、確実に保持してくれます。

Pub/Sub サービスの概要(公式ドキュメントより引用)
-
Datastream|データベースの変更をリアルタイムにとらえる
Datastream は、CDC(Change Data Capture) という仕組みを使って、オンプレミスや他のクラウドにあるデータベース(Oracle、MySQL など)への変更(挿入、更新、削除)を、ほぼリアルタイムで検知し、BigQuery などにストリーミングできるサービスです。
-
BigQuery Data Transfer Service|SaaS からのデータ転送を自動化
BigQuery Data Transfer Service は、Google 広告や YouTube、Amazon S3 といった外部の SaaS やクラウド ストレージから BigQuery へのデータロードを、スケジュールに基づいて自動化してくれるサービスです。コーディングは不要で、画面上の簡単な設定だけで、定期的なデータ転送パイプラインを構築できます。
-
Database Migration Service|オンプレミス DB をダウンタイム最小限で移行
Database Migration Service(DMS)は、オンプレミスや他のクラウドで稼働している MySQL や PostgreSQL などのデータベースを、ダウンタイムを最小限に抑えながら Cloud SQL へと移行するためのフルマネージド サービスです。
前述の Datastream が主に分析基盤(BigQuery)への継続的な同期を目的としているのに対し、DMS は Cloud SQL への一度きりの移行(マイグレーション) に特化しています。CDC(Change Data Capture)の仕組みを活用して、移行中も元のデータベースへの変更をリアルタイムに同期し続けるため、最終的な切り替え時のサービス停止時間を極めて短くできるのが大きな特徴です。
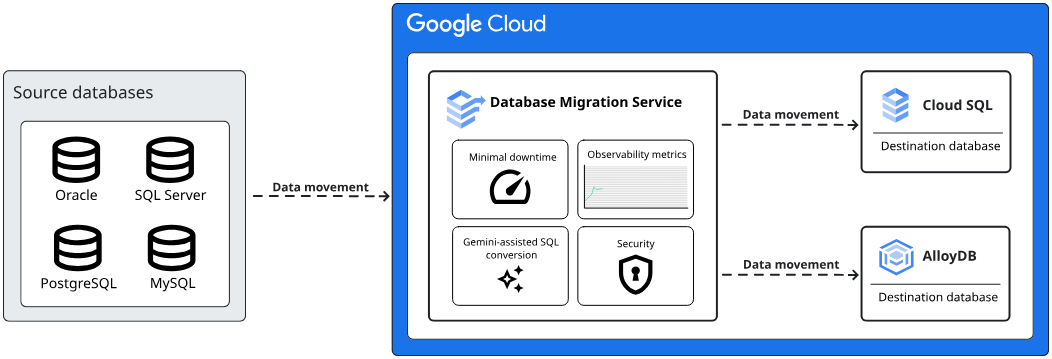
Database Migration Service の主な機能(公式ドキュメントより引用)
ステップ 2|データを加工・処理するサービス
次に、集められたデータを分析しやすいように変換・加工するためのサービスです。
-
Cloud Data Fusion|GUI でサクサク作る ETL ツール
GUI ベースのノーコード / ローコード ツールで、プログラミング知識がなくても視覚的にデータ パイプラインを構築できます。
-
Dataflow|テンプレートで手軽にパイプライン構築
Dataflow は、ストリーミング処理とバッチ処理の両方に対応する、フルマネージドでスケーラブルなデータ処理サービスです。
とくに強力なのが、Google があらかじめ用意している 「Dataflow テンプレート」 の存在です。
これは、一般的なデータ処理のパターンを実装した既製のパイプラインで、ユーザーはコードを書くことなく、画面上でパラメータを指定するだけで、信頼性の高いパイプラインを数分でデプロイできます。
例えば、Pub/Sub to BigQuery というテンプレートを使えば、Pub/Sub が受け取ったストリーミング データをリアルタイムで BigQuery に書き込む、という最も典型的なパイプラインを簡単に構築できます。

Dataflow と他の Google Cloud サービスを使用した一般的な ETL と BI ソリューション(公式ドキュメントより引用)
-
Dataproc|既存の Spark / Hadoop 資産をクラウドへ
Apache Spark や Hadoop の環境をマネージドで提供するサービス。クラスタ管理モデルとサーバーレス モデルがあります。
-
Dataform|BigQuery 内での ELT を強力にサポート
Dataform は、BigQuery 内でデータ変換ワークフロー(ELT)を開発、管理、デプロイするためのサービスです。SQL を拡張したSQLXという言語を使い、テーブルの作成、テスト、ドキュメント化までを一貫して行えます。Git と連携したバージョン管理機能も備えており、複数人での共同開発や、信頼性の高いデータ変換パイプラインの構築に適しています。
ステップ 3|イベント ドリブンな軽量パイプライン
-
Cloud Run Functions(旧 Cloud Functions) / Cloud Run の役割
すべてのデータパイプラインが、Dataflow のような大規模な処理を必要とするわけではありません。「Cloud Storage にファイルが置かれたら、それを BigQuery のテーブルにロードする」といった、比較的軽量で単純な処理は、イベント ドリブンなアーキテクチャが適しています。これは、特定の出来事(イベント)をきっかけ(トリガー)に、Cloud Run FunctionsやCloud Runといったサーバーレスのサービスを起動して処理を実行する考え方です。
ステップ 4|パイプライン全体を管理・自動化するサービス
さいごに、これらの複数のサービスを組み合わせた一連の流れを、自動で実行・管理するためのサービスをご紹介します。
-
Cloud Composer|パイプライン全体の指揮者(Apache Airflow)
Cloud Composer は、オープンソースで広く使われているワークフロー管理ツールApache Airflowのフルマネージ ドサービスです。オーケストラの指揮者のように、データパイプライン全体の処理の順序や依存関係を管理します。
ワークフローは、DAG(有向非巡回グラフ) という形式で定義され、Python コードを使って記述します。「Dataflow の処理が終わったら BigQuery のクエリを実行する」といった一連の流れを、柔軟かつコードで管理できるのが大きな特徴です。
模擬問題を解いてみる 1
問題
あなたのチームでは、毎日 Cloud Storage にアップロードされる CSV 形式の販売履歴データを、BigQuery に取り込む必要があります。取り込みの際、いくつかの不要な列を削除し、日付形式を整える簡単な変換処理が必要です。このパイプラインは、サーバーレスで、運用管理の手間を最小限に抑えたいと考えています。
選択肢
A. Dataproc クラスタをセットアップし、データ変換を行うための Spark ジョブを開発する。
B. Google が提供する Dataflow テンプレート「Cloud Storage Text to BigQuery」を利用し、変換処理を行うための簡単な JavaScript の UDF(ユーザー定義関数)を指定する。
C. Cloud Composer を使い、ファイルをダウンロードし、変換してからアップロードする一連の処理を Python で記述した DAG を作成する。
D. Cloud Run Functions を設定し、Cloud Storage へのファイル配置をトリガーにして、ファイルを一行ずつ読み込み変換して BigQuery にストリーミング挿入する。
解答と解説
正解|B
解説
このシナリオの鍵は、「サーバーレス」と「運用管理の手間を最小限」という要件です。
-
B(正解) |Dataflow はフルマネージドなサーバーレスサービスです。とくに Google 提供のテンプレートを使えば、インフラや複雑なコードを管理することなく、パラメータ設定(この場合は UDF の指定)だけで堅牢なパイプラインを構築できるため、要件に最も合致します。
-
A(不正解) |Dataproc はクラスタの管理が必要なため、サーバーレスではなく、運用管理の手間がかかります。「既存の Spark 資産を移行したい」といった明確な理由がない限り、このシナリオでは最適ではありません。
-
C(不正解) |Cloud Composer はパイプラインの処理そのものを実行するツールではなく、複数の処理の実行順序を管理するオーケストレーションツールです。このシナリオでは、処理自体が単一のパイプラインで完結するため、Cloud Composer は過剰な選択肢です。
-
D(不正解) |Cloud Run Functions はイベント ドリブンな軽量処理には適していますが、ファイル全体を処理するような ETL パイプラインとしては、エラーハンドリングや再試行の仕組みを自前で実装する必要があり、Dataflow テンプレートに比べて管理の手間が増えます。また、大規模なファイルの場合、実行時間の上限に達する可能性もあります。
模擬問題を解いてみる 2
問題
あなたのチームは、オンプレミスで稼働している Oracle データベースのデータを、ほぼリアルタイムで BigQuery に同期し、分析に活用したいと考えています。このデータベースには、新しい注文データが絶えず書き込まれており、その変更(挿入、更新)を即座に BigQuery に反映させる必要があります。インフラの管理負担を最小限に抑えつつ、この要件を実現するのに最適な Google Cloud サービスはどれですか?
選択肢
A. BigQuery Data Transfer Service を利用して、毎日深夜にデータをバッチ転送する。
B. Datastream を利用して、CDC(Change Data Capture)によりデータベースの変更をキャプチャし、BigQuery にストリーミングする。
C. Cloud Data Fusion を利用して、GUI でデータベースから BigQuery へのパイプラインを構築し、5分間隔で実行する。
D. 自社で開発したスクリプトを Compute Engine 上で実行し、定期的にデータベースの変更をポーリングして BigQuery に書き込む。
解答と解説
正解|B
解説
この問題の鍵は、「ほぼリアルタイム」「データベースの変更を同期」「管理負担を最小限に」という3つの要件です。
-
B(正解) |Datastream は、まさにこの CDC(Change Data Capture)のために設計されたフルマネージド サービスです。データベースへの変更をリアルタイムにとらえてストリーミングできるため、要件に完全に合致します。
-
A(不正解) |BigQuery Data Transfer Service は、SaaS やクラウド ストレージからのバッチ転送を目的としており、「リアルタイム」という要件を満たせません。
-
C(不正解) |Cloud Data Fusion は ETL / ELT パイプラインを構築できますが、実行はスケジュールベース(例|5 分ごと)となり、CDC のような「ほぼリアルタイム」の同期は実現できません。
-
D(不正解) |自社開発スクリプトは柔軟性がありますが、インフラ(Compute Engine)の管理やスクリプト自体のメンテナンスが必要となり、「管理負担を最小限に」という要件に反します。
模擬問題を解いてみる 3
問題
あなたはデータエンジニアとして、複数の部門で使われる複雑なデータ パイプラインを設計・運用しています。このパイプラインは、「Cloud Storage にファイルがアップロードされたら Dataflow ジョブを実行し、その処理が正常に完了したら BigQuery で集計クエリを実行し、最後に結果を別の Cloud Storage バケットに出力する」という一連の依存関係をもっています。このワークフロー全体を、コードベースで管理し、日次で自動実行したいと考えています。どのサービスを利用するのが最も適切ですか?
選択肢
A. Cloud Run Functions を使い、各ステップを個別の関数として実装し、互いに呼び出し合うようにする。
B. Cloud Composer を利用し、Python で処理の依存関係を DAG(有向非巡回グラフ)として定義し、ワークフローをオーケストレーションする。
C. Dataform を利用し、一連の処理を SQLX で記述して BigQuery 内で実行する。
D. Dataflow を利用し、すべての処理を単一の巨大なパイプラインとして Apache Beam で実装する。
解答と解説
正解|B
解説
このシナリオのポイントは、「複雑な依存関係」をもつ「複数のサービスにまたがるワークフロー」を「コードで管理し自動化する」点です。
-
B(正解) |Cloud Composer(マネージド Apache Airflow)は、まさにこのような複数のサービスをまたがる複雑なワークフローの依存関係を管理(オーケストレーション)するためのサービスです。Python で DAG を記述することで、柔軟かつ堅牢なパイプラインを構築できます。
-
A(不正解) |Cloud Run Functions は個々の軽量な処理には適していますが、複雑な依存関係の管理やエラーハンドリング、再試行などを自前で実装する必要があり、ワークフロー全体を管理するには不向きです。
-
C(不正解) |Dataform は BigQuery 内部の SQL 変換処理の管理に特化したツールであり、Dataflow や Cloud Storage の操作を含むパイプライン全体のオーケストレーションはできません。
-
D(不正解) |すべての処理を単一の Dataflow パイプラインにまとめることも不可能ではありませんが、処理の独立性が失われ、一部の処理だけを再実行するなどの柔軟な運用が困難になります。ワークフロー全体の「指揮者」としては、オーケストレーションツールである Cloud Composer がより適切です。
模擬問題を解いてみる 4
問題
あなたの会社のマーケティング部門では、プログラミング経験のない担当者が、日々のキャンペーン成果を分析したいと考えています。Cloud Storage にある広告費用データ(CSV)と、BigQuery にある顧客データを結合し、いくつかのデータ クレンジングを行った上で、新しい分析用テーブルを作成する必要があります。
担当者は、この一連のデータパイプラインをコードを書くことなく、グラフィカルな画面で構築・管理したいと望んでいます。この要件に最も適したサービスはどれですか?
選択肢
A. Cloud Data Fusion を利用し、GUI 上でソースとシンク、変換処理を定義する。
B. Dataflow を利用し、Apache Beam SDK を使って Python で変換処理を記述する。
C. Dataform を利用し、SQLX を使って BigQuery 内での変換処理を記述する。
D. BigQuery のコンソールから手動で CSV をロードし、SQL で変換処理を行う。
解答と解説
正解|A
解説
この問題の鍵は、「プログラミング経験のない担当者」が「コードを書くことなく、GUI で」パイプラインを構築したい、という点です。
-
A(正解) |Cloud Data Fusion は、まさにこのシナリオのために設計されたサービスです。豊富なコネクタと GUI ベースのビジュアル開発環境を提供し、非エンジニアでも直感的に ETL パイプラインを構築できます。
-
B(不正解) |Dataflow は非常に強力なデータ処理サービスですが、カスタムロジックの実装には Python や Java でのプログラミングが必要です。「コードを書くことなく」という要件に合致しません。
-
C(不正解) |Dataform は BigQuery 内部での SQL ベースの変換(ELT)を管理するツールです。Cloud Storage からデータを読み込む ETL 処理は行えず、また SQL の知識が必須です。
-
D(不正解) |手動での操作は自動化できず、継続的なパイプラインにはなりません。「パイプラインを構築・管理したい」という要件を満たせません。
模擬問題を解いてみる 5
問題
あなたは、BigQuery をデータ ウェアハウスとして利用しているデータ分析チームに所属しています。生データはすでに BigQuery のテーブルにロードされています。あなたのタスクは、この生データから、ビジネスレポートで利用するための信頼性の高いデータマートを構築することです。
このデータ変換処理はすべて SQL のみで完結させ、その SQL コード群を Git と連携してバージョン管理し、各テーブルに対してデータ品質のテストを自動実行できる、統制の取れた開発プロセスを導入したいと考えています。どのサービスが最も適していますか?
選択肢
A. Dataform を利用して、SQLX で変換ワークフローを定義し、Git リポジトリに接続する。
B. Cloud Composer を利用して、各 SQL クエリを実行するタスクを DAG として定義する。
C. BigQuery の「スケジュールされたクエリ」機能を利用して、順番に SQL を実行する。
D. Dataflow を利用して、BigQuery テーブルを読み込み、SQL 変換を実行して結果を書き戻す。
解答と解説
正解|A
解説
このシナリオのポイントは、「BigQuery 内部」で「SQL ベースの変換」を「Git でバージョン管理し、テストも行いたい」という、モダンな ELT 開発の要件です。
-
A(正解) |Dataform は、まさにこれらの要件を満たすために作られたサービスです。BigQuery 内の SQL 変換ワークフローの開発、バージョン管理、テスト、ドキュメント化を一貫してサポートします。
-
B(不正解)|Cloud Composer はパイプライン全体の実行順序を管理するオーケストレーションツールですが、SQL コード自体の開発、テスト、バージョン管理に特化した機能はもっていません。
-
C(不正解) |「スケジュールされたクエリ」は SQL を定期実行できますが、複雑な依存関係の管理、バージョン管理、テストといった高度な開発プロセスには対応できません。
-
D(不正解)|Dataflow は BigQuery の外部でデータを処理する ETL ツールです。「BigQuery 内部で完結」という要件に反します。
模擬問題を解いてみる 6
問題
あなたの会社のマーケティング チームは、日々の Google 広告の掲載結果データを BigQuery で分析し、ROI を可視化したいと考えています。このために、Google 広告のデータを毎日自動で BigQuery のデータセットにロードする仕組みが必要です。
このデータ連携は、エンジニアの手を借りずに、コーディングなしで、かつ信頼性の高いフルマネージドな方法で実現したいと考えています。どのサービスを利用するのが最も適切ですか?
選択肢
A. BigQuery Data Transfer Service を設定し、Google Ads 向けの転送を作成する。
B. Datastream を利用して、Google 広告のデータベースから変更をストリーミングする。
C. Cloud Run Functions で Google Ads API を呼び出す Python スクリプトを開発し、Cloud Scheduler で毎日実行する。
D. Google 広告の管理画面から毎日手動でレポートをダウンロードし、BigQuery にアップロードする。
解答と解説
正解|A
解説
この問題の鍵は、「Google 広告」という具体的な SaaS から、「コーディングなし」で「毎日自動で」データをロードしたい、という非常に明確な要件です。
-
A(正解) |BigQuery Data Transfer Service は、まさにこの目的のために提供されているサービスです。Google 広告、YouTube、Amazon S3 といった外部サービスから BigQuery への定期的なデータロードを、GUI 上の簡単な設定だけで自動化できます。
-
B(不正解)|Datastream は、Oracle や MySQL といったデータベースからの変更をリアルタイムに同期するためのサービスであり、Google 広告のような SaaS アプリケーションには対応していません。
-
C(不正解) |この方法でも実現可能ですが、「コーディングなし」「エンジニアの手を借りずに」という要件に明確に違反します。BigQuery Data Transfer Service は、このようなカスタム開発を不要にするためのマネージド サービスです。
-
D(不正解) |手動での運用は「毎日自動で」という要件を満たせず、ミスが発生しやすく非効率です。
3. オンライン業務を支えるデータベース|Cloud SQL
データ分析の世界では、分析対象となるデータがどこから来るのかを理解することも重要です。多くの場合、そのデータは Web サイトのバックエンドや基幹業務システムなど、日々の業務を支えるリレーショナル データベースで生まれています。
Google Cloud において、この役割を担うのが Cloud SQL です。
Cloud SQL は、MySQL、PostgreSQL、SQL Server といった、広く使われているリレーショナル データベースをフルマネージドで提供するサービスです。わずらわしいパッチ適用やバックアップ、レプリケーション設定などを Google に任せることができます。
3.1 BigQuery との役割分担|OLTP と OLAP
ここで重要なのが、Cloud SQL と BigQuery の明確な役割の違いです。
- Cloud SQL(OLTP)|オンライン トランザクション処理(Online Transaction Processing)が得意です。EC サイトでの注文処理のように、頻繁なデータの書き込み、更新、削除が発生するオンライン業務の裏側で使われます。
- BigQuery(OLAP)|オンライン分析処理(Online Analytical Processing)が得意です。過去の膨大な注文履歴を分析し、売上の傾向を把握するような、大量データの集計・分析で使われます。
日々の業務データは Cloud SQL に蓄積され、分析が必要になったタイミングで、そのデータを Datastream や Dataflow を使って BigQuery に連携する、というのが一般的な構成です。
3.2 高可用性(HA)構成|ゾーン障害に備える
Cloud SQL は、簡単な設定で高可用性(HA)構成を組むことができます。
これを有効にすると、プライマリ インスタンスとは別のゾーンに、同じ構成のスタンバイ インスタンスが自動で作成されます。万が一、プライマリ インスタンスで障害が発生しても、自動的にスタンバイ インスタンスに切り替わる(フェイルオーバーする)ため、サービスの停止時間を最小限に抑えることができます。
さらに、クロスリージョン レプリカを追加することで、リージョン単位の障害に対応するディザスタ リカバリ(DR) 構成も実現できます。

Cloud SQL の HA 構成(公式ドキュメントより引用)
模擬問題を解いてみる 7
問題
あなたの会社は、ユーザーが商品を注文できる新しい EC サイトを開発しています。このサイトでは、ユーザー登録、商品情報の管理、注文処理など、頻繁なデータの読み書きが発生します。データベースはフルマネージドで、MySQL 互換であることが要件です。また、単一のゾーンで障害が発生した場合でも、サービスの停止時間を最小限に抑え、自動的に復旧する仕組みが必要です。
この要件に最も適したソリューションはどれですか?
選択肢
A. BigQuery を使用して注文データを保存する。
B. Compute Engine インスタンスに MySQL をインストールし、運用する。
C. 高可用性(HA)構成を有効にした Cloud SQL for MySQL インスタンスを作成する。
D. 単一インスタンスの Cloud SQL for MySQL を作成し、定期的にバックアップを取得する。
解答と解説
正解|C
解説
この問題の鍵は、「頻繁なデータの読み書き(OLTP)」、「フルマネージド」、そして 「ゾーン障害からの自動復旧」 という 3 つの要件をすべて満たすサービスを選択することです。
-
C(正解) |Cloud SQL はフルマネージドなリレーショナル データベースであり、EC サイトのバックエンドのような OLTP ワークロードに最適です。さらに、高可用性(HA)構成を有効にすることで、ゾーン障害発生時にスタンバイ インスタンスへ自動的にフェイルオーバーするため、すべての要件を満たします。
-
A(不正解) |BigQuery は、大量データの分析(OLAP)に特化したデータ ウェアハウスです。頻繁な行単位の更新や削除が発生する OLTP ワークロードには適していません。
-
B(不正解) |Compute Engine 上で MySQL を自己管理する方法は、「フルマネージド」という要件に反します。OS のパッチ適用、バックアップ、可用性の担保などをすべて自前で行う必要があり、運用負荷が非常に高くなります。
-
D(不正解) |単一インスタンスの Cloud SQL では、ゾーン障害が発生した場合に自動で復旧しません。バックアップからのリストアには手動での対応が必要となり、サービスの停止時間が長くなるため、「自動的に復旧」という要件を満たせません。
模擬問題を解いてみる 8
問題
あなたの会社は、オンプレミスで稼働しているウェブサイトのバックエンドとして、長年 MySQL データベースを運用してきました。このデータベースを Google Cloud に移行し、運用負荷を削減したいと考えています。移行先のデータベースは、引き続き MySQL 互換のリレーショナル データベースである必要があります。
最も重要な要件は、移行作業中もウェブサイトのサービスを停止させないよう、ダウンタイムを可能な限り最小限に抑えることです。この要件を満たす、最も適切な移行方法はどれですか?
選択肢
A. Database Migration Service を利用して、Cloud SQL for MySQL への継続的なレプリケーションを設定し、最後に切り替える。
B. Datastream を利用して、BigQuery にデータベースの変更をリアルタイムに同期する。
C. データベースのバックアップを取得し、Cloud Storage にアップロード後、新しい Cloud SQL インスタンスに手動でインポートする。
D. Compute Engine インスタンスをセットアップし、オンプレミスと VPN を接続して、手動でデータを同期するスクリプトを実行する。
解答と解説
正解|A
解説
この問題の鍵は、移行先が Cloud SQL(MySQL 互換) であること、そして「ダウンタイムを最小限に抑える」という最重要要件です。
-
A(正解) |Database Migration Service は、まさにこのシナリオのために設計されたフルマネージド サービスです。CDC(Change Data Capture)技術を利用して、移行元と移行先の差分を継続的に同期するため、最終的な切り替え(カットオーバー)時のダウンタイムを数分レベルに抑えることが可能です。
-
B(不正解) |Datastream は、主に分析目的で BigQuery にデータを同期するためのサービスです。移行先が Cloud SQL ではないため、このシナリオには適していません。
-
C(不正解) |バックアップとリストアによる方法は、シンプルですが、バックアップを取得してからリストアが完了するまでの間、データベースへの書き込みを停止する必要があり、長時間のダウンタイムが発生します。
-
D(不正解) |自前でスクリプトを開発・運用する方法は、インフラの管理やスクリプトの品質担保など、運用負荷が非常に高くなります。また、ダウンタイムを最小限に抑える仕組みを自作するのは極めて困難です。
4. データ分析の心臓部!BigQuery 徹底解説
データ パイプラインを通って集められたデータは、どこかに貯めて分析する必要があります。その中心的な役割を担うのが、この試験の主役とも言える 「BigQuery」 です。
BigQuery は、Google が提供する サーバーレス で フルマネージド な データ ウェアハウス です。
- サーバーレス|サーバーの性能や台数を気にする必要はありません。
- フルマネージド|面倒な運用や管理はすべて Google が行います。
- データ ウェアハウス|分析のために、超巨大なデータを蓄積しておくための「倉庫」です。
つまり BigQuery は、データの保管と分析に必要なインフラ管理を Google に任せられる、スケーラブルなデータ分析基盤です。私たちはデータを用意し、分析の指示(クエリ)を出すことに集中できます。
4.1. BigQuery の仕組み|なぜ速いのか
BigQuery の高い性能の秘密は、 「ストレージ(保管機能)」と「コンピュート(計算機能)が完全に分離している」 アーキテクチャにあります。

BigQuery アーキテクチャ(公式ドキュメントより引用)
データを保管する場所と、そのデータを処理する頭脳(CPU)が別々に設計されているため、それぞれを独立して大規模に拡張(スケール)させることが可能です。私たちがクエリを実行すると、Google のもつ多数のサーバーが一斉に計算を始めるイメージです。このため、テラバイト級、ペタバイト級のデータであっても、高速に結果を返します。
4.2. データの取り込みとスキーマ|倉庫にデータを入れる
BigQuery にデータを取り込む方法はいくつかありますが、試験でよく問われるのは Cloud Storage からのバッチロードです。
このバッチロードを簡単にする機能の一つが スキーマの自動検出 です。
通常、データを取り込む際には、テーブルの列名やデータ型といった構造(スキーマ)を事前に定義する必要があります。しかし、Cloud Storage 上の CSV や JSON、Parquet、Avro といった形式のファイルであれば、BigQuery がファイルの中身を解析して、このスキーマを自動で定義してくれます。これにより、データロードの手間を大幅に削減できます。
半構造化データの扱い|JSON 型
ログデータのように、キーと値の組み合わせが柔軟に変化するデータを「半構造化データ」と呼びます。BigQuery には、このようなデータをネイティブに扱うための JSON 型が用意されています。STRING 型としてテキストで格納するよりも、クエリのパフォーマンスやコスト面で有利です。
4.3. コストと性能を最適化する重要機能
BigQuery を使いこなす上で絶対に欠かせないのが、「パーティショニング」 と 「クラスタリング」 です。この 2 つは、クエリの 性能を上げ、料金を節約するための二大機能であり、試験でも頻出します。
-
パーティショニング|テーブルを日付で仕切る
パーティショニングは、巨大なテーブルを日付などの単位で小さな区画(パーティション)に分割する機能です。本棚を年代別に仕切るようなイメージです。
例えば、日付でパーティション分割された売上テーブルに対して「昨日の売上データだけ見たい」というクエリを実行すると、BigQuery は「昨日」の区画だけをスキャンします。テーブル全体をスキャンしないため、処理するデータ量が減り、結果的にクエリは速くなり、料金も安くなります。
また、パーティションには有効期限を設定することもできます。例えば、「作成から 180 日が経過したパーティションは自動的に削除する」といったルールを定義することで、古いデータを自動で整理(ハウスキーピング) し、ストレージ コストを管理できます。
-
クラスタリング|仕切った中でデータを並べ替える
クラスタリングは、パーティション分割された各区画の中で、さらに指定した列(例|顧客 ID や商品カテゴリ)の値に基づいてデータを並べ替えておく機能です。年代別に仕切った本棚の中で、さらに著者名のあいうえお順に本を並べるイメージです。
これにより、「特定の日付の、特定の顧客 ID のデータ」を探すような場合に、BigQuery はさらに効率よく目的のデータを見つけ出せます。

クラスタリング(公式ドキュメントより引用)

クラスタ化テーブルとパーティション分割テーブルを組み合わせる(公式ドキュメントより引用)
4.4. データの扱い方をマスターする
外部テーブル|データを BigQuery に入れずにクエリする
「データは Cloud Storage に置いたまま、BigQuery でクエリしたい」そんなときに使うのが外部テーブルです。データを BigQuery のストレージにロードしないため、ストレージ料金はかかりませんが、クエリの性能は BigQuery の中にデータをもつネイティブ テーブルに比べて劣ります。
マテリアライズド ビュー|クエリ結果を保存して高速化
マテリアライズド ビューは、クエリ結果をあらかじめ計算して物理的に保存しておく機能です。ダッシュボードで使われるような、毎回同じ集計クエリを繰り返し実行する場合に絶大な効果を発揮します。
BigQuery が裏側で自動的に結果を最新の状態に保ってくれるため、ユーザーは複雑なクエリを何度も実行する必要がなくなり、表示速度が劇的に向上し、コストも削減できます。
コネクテッド シート|スプレッドシートから BigQuery を操作
コネクテッド シートは、Google スプレッドシートから、数億行もの BigQuery のデータに直接接続し、分析できる機能です。使い慣れたスプレッドシートのインターフェースで、ピボット テーブルやグラフ作成、関数を使った集計などを、BigQuery のパワーを活用して実行できます。

コネクテッド シート(公式ドキュメントより引用)
4.5. 試験で問われる SQL|ウインドウ関数
この試験では、具体的な SQL の知識、とくに分析でよく使われるウインドウ関数の理解が問われることがあります。
ウインドウ関数は、RANK() や ROW_NUMBER() に代表されるもので、例えば「カテゴリごとの売上ランキングを計算する」といった、通常の GROUP BY だけでは難しい集計を可能にします。
4.6. 試験で問われるセキュリティと権限管理
BigQuery では、誰がどのデータに、どこまでアクセスできるかを細かく制御できます。最小権限の原則に従って、適切な権限を付与することが重要です。
IAM によるアクセス制御
BigQuery の権限管理で最も重要な考え方の一つが、「クエリを実行する権限」 と 「データそのものを閲覧する権限」 が分離されている点です。
例えば、新人のデータ アナリストに、特定のデータセット(例|sales_analytics)に対してのみクエリを実行させたい、しかし他の機密データ(例|hr_data)は見せたくない、というケースを考えます。
この場合、最小権限の原則に従って、以下の 2 種類のロールを適切なレベルで組み合わせるのが正解です。
-
プロジェクト レベルで
BigQuery ジョブユーザー ロールを付与する。
これにより、アナリストはプロジェクト内でクエリを実行することができます。 -
データセット レベル(
sales_analytics)でBigQuery データ閲覧者ロールを付与する。
これにより、アナリストはその特定のデータセットのデータを 「閲覧する権利」 を得ます。
この 2 つが揃って初めて、アナリストは sales_analytics データセットに対してクエリを実行し、結果を見ることができます。hr_data データセットには閲覧権限がないため、クエリを実行しようとしても失敗します。
試験で覚えておくべき主要なロールは以下の通りです。
| IAM ロール | 主な権限 |
|---|---|
| BigQuery ジョブユーザー | ジョブ(クエリ、ロードなど)を実行する権限。データへのアクセス権は含まない。 |
| BigQuery データ閲覧者 | テーブルのデータを閲覧する権限。ジョブの実行権限は含まない。 |
| BigQuery データ編集者 | データ閲覧に加え、テーブルの作成、更新、削除ができる。 |
| BigQuery 管理者 | プロジェクト内のすべての BigQuery リソースに対する完全な権限をもつ。 |
承認済みビュー|見せたいデータだけを安全に共有
元のテーブルへのアクセス権をユーザーに与えることなく、ビュー(仮想的なテーブル)を通して、許可されたデータだけを見せる仕組みです。例えば、「個人情報列を除いた集計結果だけを共有したい」といった場合に最適です。
行レベル・列レベルのセキュリティ|さらに細かいアクセス制御
より厳密な制御が必要な場合は、以下の機能を使います。
- 行レベルのセキュリティ|ユーザーの属性などに基づいて、特定の行だけを表示する(例|営業担当者には、自分の担当顧客の行だけを見せる)。
- 列レベルのセキュリティ|特定の列をマスキング(隠蔽)したり、アクセスを制限したりする(例|アナリストには、個人情報が含まれる列へのアクセスを許可しない)。
透過的な暗号化|GMEK、CMEK、CSEK
Google Cloud に保存されるデータは、何もしなくても Google が管理する鍵(GMEK) によってデフォルトで暗号化されています。しかし、より厳格なセキュリティ要件に応えるため、以下の選択肢も用意されています。
-
CMEK(顧客管理の暗号鍵) |
Cloud KMSを使って、ユーザー自身が鍵を管理します。 - CSEK(顧客指定の暗号鍵) |ユーザーがオンプレミスなどで管理する鍵を、暗号化・復号の都度、提供します。(ただし、Cloud Storage などでは利用できますが、BigQuery は CSEK に対応していません)
4.7. SQL だけで機械学習!?BigQuery ML
BigQuery のすごいところは、ただデータを高速に分析できるだけではありません。なんと、使い慣れた SQL を書くだけで、機械学習モデルを作成し、予測を実行できる機能、「BigQuery ML」 を備えています。
通常、機械学習モデルの構築には、Python などのプログラミング言語や、専門的なライブラリ、そして深い数学的な知識が必要でした。しかし BigQuery ML は、その常識を覆します。データ アナリストが SQL スキルをそのまま活かして、データの前処理からモデルのトレーニング、評価、予測までを一気通貫で BigQuery 内で完結させることができます。
4.8. BigQuery ML でできること|CREATE MODEL
BigQuery ML の基本は、CREATE MODEL という SQL 文です。この SQL を実行するだけで、BigQuery は指定されたデータを使って自動的に機械学習モデルを構築してくれます。
CREATE MODEL `mydataset.sales_forecast_model`
OPTIONS(
MODEL_TYPE='ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL='sale_date',
TIME_SERIES_DATA_COL='sales'
) AS
SELECT
sale_date,
sales
FROM
`mydataset.sales_table`;
この例では、過去の売上データ(sales_table)から、将来の売上を予測する時系列モデル(ARIMA_PLUS)を作成しています。モデルが作成された後は、ML.FORECAST という関数を使って、未来の売上を簡単に予測できます。
試験では、「何をしたいか」という目的に応じて、適切な MODEL_TYPE を選択できるかが問われます。
| 目的 | モデルタイプ(例) | ユースケース |
|---|---|---|
| 数値を予測する(回帰) |
LINEAR_REG線形回帰 |
顧客の年齢から購入金額を予測する |
| どちらか一方を予測する(二項分類) |
LOGISTIC_REGロジスティック回帰 |
顧客がキャンペーンに反応するか否かを予測する |
| 複数の選択肢から予測する(多項分類) |
LOGISTIC_REG ロジスティック回帰 |
問い合わせ内容をカテゴリ(製品、料金、その他)に分類する |
| データをグループ分けする(クラスタリング) |
KMEANSK 平均法クラスタリング |
購買履歴から顧客を複数のセグメントに分類する |
| 未来の数値を予測する(時系列) |
ARIMA_PLUS単変量時系列モデル |
過去のデータから来月の製品需要を予測する |
4.9. モデルの品質を監視する|データスキューとドリフト
作成した機械学習モデルを運用する上で、データスキューとデータドリフトという 2 つの概念を理解しておくことが重要です。
- データスキュー|トレーニングに使ったデータと、実際に予測を行う本番のデータとの間に分布のズレがある状態。
- データドリフト|時間の経過と共に、本番データの傾向が変化してしまうこと。
これらの状態に陥ると、モデルの予測精度は著しく低下します。
BigQuery ML は Vertex AI と統合されているため、Vertex AI Model Monitoring と連携して、BigQuery ML で作成した機械学習モデルの品質を監視したりチェックすることもできます。
4.10. Vertex AI との連携|Gemini を SQL で呼び出す
BigQuery ML は、Google Cloud の統合 AI プラットフォームである Vertex AI とも連携できます。とくに注目すべきは、Vertex AI 上の生成 AI モデル(Gemini など) を BigQuery から 「リモートモデル」 として呼び出せる機能です。
これにより、例えば BigQuery 上の製品レビューのテキストデータに対して、SQL を使って ML.GENERATE_TEXT 関数を実行し、「このレビューの感情を分析して」といった指示を出すことが可能になります。SQL だけで、非構造化データであるテキストの分析まで行えるのは、非常に強力です。
4.11. AutoML|ノーコードで最高精度のモデルを
もう一つ、試験で理解しておくべきサービスが AutoML です。
AutoML は、GUI ベースのノーコード ツールで、データセットをアップロードするだけで、Google がもつ最先端の機械学習技術を使って自動的に最適なモデルを探索し、構築してくれるサービスです。
BigQuery ML と AutoML は、どちらも機械学習を簡単に利用できるサービスですが、使い分けが重要です。
- BigQuery ML|データ アナリストが SQL のワークフローの中で、手早くモデルを構築し、試行錯誤したい場合に適しています。
- AutoML|ML の専門知識がないユーザーが、GUI 操作で、可能な限り高い精度のモデルを求めている場合に最適です。
模擬問題を解いてみる 9
問題
あなたのチームは、Web サイトのアクセスログを BigQuery で分析しています。テーブルには数年分のデータが蓄積されており、クエリはつねに過去 30 日間など、特定の期間を log_date 列で絞り込んで実行されます。分析のたびにテーブル全体がスキャンされてしまい、クエリのコストと実行時間が課題となっています。
この問題を解決し、コストとパフォーマンスを最適化する最も効果的な方法は何ですか?
選択肢
A. クエリの LIMIT 句を使い、スキャンする行数を減らす。
B. log_date 列でテーブルをクラスタリングする。
C. log_date 列でテーブルを時間単位パーティション分割する。
D. ログデータをすべて外部テーブルとして Cloud Storage に保持する。
解答と解説
正解|C
解説
この問題の鍵は、「つねに日付列で絞り込む」クエリの「コストとパフォーマンスを改善したい」という要件です。
-
C(正解) |時間単位パーティショニングは、まさにこのためにある機能です。日付やタイムスタンプ列でテーブルを物理的に分割(パーティションを作成)することで、クエリ実行時に BigQuery がスキャンする必要があるのは、日付フィルタに合致するパーティションのみになります。これにより、スキャンするデータ量が劇的に減り、コスト削減と高速化が実現します。
-
A(不正解) |
LIMIT句は、クエリの結果セットの行数を制限するだけで、クエリが最初にスキャンするデータ量を減らすわけではありません。したがって、コスト削減にはつながりません。 -
B(不正解) |クラスタリングは、データを並べ替えておく機能であり、フィルタリングの性能を向上させますが、スキャンするデータ量そのものを減らす効果はパーティショニングほど大きくありません。まずパーティショニングでスキャン範囲を限定するのが基本です。
-
D(不正解) |外部テーブルはデータを BigQuery にロードせずにクエリできる便利な機能ですが、一般的にネイティブ テーブルよりパフォーマンスは劣ります。パフォーマンス改善が目的であるため、不適切です。
模擬問題を解いてみる 10
問題
あなたは、アプリケーションから出力される大量のログデータを BigQuery で管理しています。分析クエリは、まず timestamp 列で特定の期間に絞り込んだ後、さらに「どのユーザーが(user_id)」「どのような種類(event_type)のログを出力したか」で頻繁にフィルタリングされます。
このクエリのパフォーマンスを最大化し、コストを最小化するための最も最適なテーブル設計はどれですか?
選択肢
A. timestamp 列でパーティション分割し、user_id と event_type 列でクラスタリングする。
B. user_id 列と event_type 列でパーティション分割する。
C. timestamp、user_id、event_type の 3 つの列でクラスタリングする。
D. timestamp 列でクラスタリングし、user_id と event_type 列でパーティション分割する。
解答と解説
正解|A
解説
このシナリオのポイントは、フィルタリングの優先順位です。まず「期間で大きく絞り込み」、その中で「特定のキーでさらに絞り込む」という典型的な分析パターンです。
-
A(正解) |まず
timestamp列でパーティション分割することで、BigQuery がスキャンするデータ量を期間で物理的に限定します。これがコスト削減に最も効果的です。その上で、各パーティション内のデータをuser_idとevent_typeで並べ替えておく(クラスタリングする)ことで、さらにフィルタリングの性能が向上します。これがベスト プラクティスです。 -
B、D(不正解) |パーティション分割は、通常、日付 / タイムスタンプ列、またはカーディナリティ(種類)が多すぎない列に対して行います。
user_idのような非常に多くの種類をもつ列でパーティション分割するのは非効率であり、推奨されません。 -
C(不正解) |パーティショニングを行わずにクラスタリングだけを行うと、クエリのたびにテーブル全体をスキャンする必要があり、コスト削減効果が限定的です。
模擬問題を解いてみる 11
問題
あなたは、BI ツールでリアルタイムの売上ダッシュボードを運用しています。このダッシュボードは、数億行のトランザクション テーブルから、商品カテゴリごと、地域ごとの売上合計などを集計する非常に複雑なクエリを 1 分ごとに実行しており、表示の遅延と高額なクエリ料金が問題になっています。
このダッシュボードの表示速度を劇的に改善し、クエリ料金を大幅に削減するには、どの BigQuery の機能を利用するのが最も効果的ですか?
選択肢
A. トランザクション テーブルを日付でパーティション分割する。
B. クエリ結果をキャッシュするマテリアライズド ビューを作成する。
C. クエリ結果を定期的に別の通常テーブルに書き出す、スケジュールされたクエリを設定する。
D. BI ツールからの同時実行クエリ数を増やす。
解答と解説
正解|B
解説
この問題の鍵は、「繰り返し実行される重い集計クエリ」の「パフォーマンスとコスト」を改善したいという明確な要件です。
-
B(正解) |マテリアライズド ビューは、まさにこのために設計された機能です。クエリの結果を物理的に保持し、元のテーブルが更新されると自動的に差分を更新してくれます。BI ツールは、この事前に計算済みの結果に対してクエリを実行するだけで済むため、速度が劇的に向上し、コストも大幅に削減できます。
-
A(不正解) |パーティショニングは有効な最適化手法ですが、クエリの集計処理自体の計算負荷を減らすものではありません。マテリアライズド ビューは計算結果そのものを保存するため、より直接的な解決策です。
-
C(不正解) |スケジュールされたクエリでも似たようなことは可能ですが、更新の頻度や差分更新の賢さ(インクリメンタル更新)の点でマテリアライズド ビューに劣ります。また、マテリアライズド ビューは BigQuery がクエリを自動的に書き換えて利用してくれるため(スマート チューニング)、より透過的で効率的です。
-
D(不正解) |同時実行数を増やすことは、パフォーマンスの改善にはつながらず、むしろコストを増大させる可能性があります。
模擬問題を解いてみる 12
問題
あなたのチームに、新しくジュニア データ アナリストが加わりました。そのアナリストには、プロジェクト内の marketing_dataset というデータセットに対するクエリの実行と、その結果の閲覧を許可する必要があります。
ただし、セキュリティ ポリシー上、そのアナリストには marketing_dataset のテーブルを変更・削除する権限や、同プロジェクト内の finance_dataset のような他のデータセットを閲覧する権限を与えてはなりません。最小権限の原則に従い、付与すべき IAM ロールの最も適切な組み合わせはどれですか?
選択肢
A. データセット レベル(marketing_dataset)で BigQuery データ編集者 ロールを付与する。
B. プロジェクト レベルで BigQuery データ閲覧者 ロールを付与する。
C. プロジェクト レベルで BigQuery ユーザー ロールを付与する。
D. プロジェクト レベルで BigQuery ジョブユーザー ロールを、データセット レベル(marketing_dataset)で BigQuery データ閲覧者 ロールを付与する。
解答と解説
正解|D
解説
BigQuery の権限管理における最も重要なポイントの一つが、「ジョブ(クエリ)を実行する権限」と「データにアクセスする権限」が分離されていることです。
-
D(正解) |これが最小権限の原則に従ったベスト プラクティスです。プロジェクト レベルで「クエリ実行の許可(
ジョブユーザー)」を与え、アクセスを許可したい特定のデータセットにのみ「データ閲覧の許可(データ閲覧者)」を与えることで、権限を厳密に制御できます。 -
A(不正解) |データ編集者ロールは、テーブルの作成・更新・削除権限を含むため、権限が過剰です。
-
B(不正解) |プロジェクト レベルでデータ閲覧者を付与すると、プロジェクト内のすべてのデータセット(
finance_datasetを含む)が閲覧可能になってしまい、要件に違反します。 -
C(不正解) |
BigQuery ユーザーロールは、データセットの作成など、クエリ実行と閲覧以上の権限を含んでおり、最小権限の原則に反します。
模擬問題を解いてみる 13
問題
あなたは、顧客の個人情報を含む販売トランザクションの生データテーブルを管理しています。このデータを外部のコンサルタントと共有する必要がありますが、彼らには個人情報(顧客名、住所など)を見せることなく、日次・商品カテゴリ別の集計売上データのみを閲覧させたいと考えています。
生データテーブルへのアクセス権を直接付与せず、データをコピーすることもなく、この要件を満たす最も安全で効率的な方法は何ですか?
選択肢
A. 集計クエリを実行する承認済みビューを作成し、コンサルタントにそのビューへのアクセス権のみを付与する。
B. テーブルの個人情報列に対して列レベルのセキュリティを設定し、コンサルタントにテーブルへのアクセス権を付与する。
C. コンサルタントが必要な都度、あなたがクエリを実行して結果を CSV で送付する。
D. 毎日バッチ処理を実行し、集計結果を別のテーブルに書き出して、そのテーブルへのアクセス権を付与する。
解答と解説
正解|A
解説
このシナリオの鍵は、「元データへのアクセスは防ぎつつ」「データのサブセット(集計結果)だけを」「データをコピーせずに」共有したいという点です。
-
A(正解) |承認済みビューは、まさにこの目的のための機能です。ビュー(仮想テーブル)の定義者(あなた)が元テーブルへのアクセス権をもっていれば、ビューの利用者(コンサルタント)は元テーブルへの権限がなくても、ビューを通して許可されたデータ(集計結果)にのみアクセスできます。
-
B(不正解) |列レベルのセキュリティは、特定の列へのアクセスを制御しますが、コンサルタントは依然としてテーブル全体にアクセスできてしまい、集計されていない他のデータ(個人情報以外のトランザクション詳細など)が見えてしまいます。集計結果のみを見せたい、という要件には承認済みビューがより適切です。
-
C(不正解) |手動での対応は非効率であり、スケールしません。
-
D(不正解) |この方法でも要件は満たせますが、集計結果を保持するための余分なストレージ コストが発生し、データの鮮度もバッチ処理のタイミングに依存します。承認済みビューの方がより効率的でリアルタイムです。
模擬問題を解いてみる 14
問題
ある企業では、全社の売上データを単一のテーブルで管理しており、テーブルには各国の営業マネージャーの情報も含まれています。データ ガバナンスの要件として、各営業マネージャーは、自分が担当する国のデータのみを閲覧できるようにし、他の国のデータには一切アクセスできないようにする必要があります。
このアクセス制御を、ユーザーのログイン ID に基づいて動的に行い、単一のテーブルを維持しながら実現するには、どの BigQuery のセキュリティ機能を利用すべきですか?
選択肢
A. IAM 条件
B. 行レベルのセキュリティ
C. 列レベルのセキュリティ
D. 承認済みビュー
解答と解説
正解|B
解説
この問題のポイントは、「ログイン ユーザーに応じて」「閲覧できる行を動的に」フィルタリングしたい、という要件です。
-
B(正解) |行レベルのセキュリティは、まさにこのための機能です。テーブルに対して「ユーザーのメールアドレスが、その行の担当マネージャー列の値と一致する場合にのみアクセスを許可する」といったルールを定義することで、同じテーブルを参照しても、ログイン ユーザーごとに表示される行を動的に制御できます。
-
A(不正解) |IAM 条件は、特定の日時や IP アドレスなど、リソースへのアクセスを許可するか否かを制御するもので、テーブルの内容(行) をフィルタリングするものではありません。
-
C(不正解) |列レベルのセキュリティは、特定の列(例|給与情報)を隠すための機能であり、行をフィルタリングすることはできません。
-
D(不正解) |承認済みビューでも似たような制御は可能ですが、マネージャーごと(国ごと)にビューを作成する必要があり、管理が煩雑になります。行レベルのセキュリティは、単一のポリシーでこれを実現できるため、よりスケーラブルです。
-
模擬問題を解いてみる 15
問題
あなたは、小売企業のデータ アナリストとして、来月の売上を予測するプロジェクトを任されました。BigQuery には、過去 2 年間の日々の売上額を記録したテーブル(daily_sales) があり、sale_date(日付)と revenue(売上額)の列が含まれています。
この過去の時系列データを利用して、今後 30 日間の日々の売上額を予測するための機械学習モデルを BigQuery ML で構築する場合、CREATE MODEL 文で指定する MODEL_TYPE として最も適切なものはどれですか?
選択肢
A. KMEANS(K 平均法クラスタリング)
B. LOGISTIC_REG(ロジスティック回帰)
C. LINEAR_REG(線形回帰)
D. ARIMA_PLUS(時系列モデル)
解答と解説
正解|D
解説
この問題の鍵は、「過去のデータに基づき」「未来の数値を予測する」という時系列予測の要件です。
-
D(正解) |
ARIMA_PLUSは、まさにこのような時系列データを分析し、将来の値を予測するために設計された BigQuery ML のモデルタイプです。季節性やトレンドを考慮した高度な予測が可能です。 -
A(不正解) |K 平均法は、データをいくつかのグループに分ける「クラスタリング」のためのモデルであり、未来を予測するものではありません。
-
B(不正解) |ロジスティック回帰は、「購入するか / しないか」といった 2 択の結果を予測する「分類」のためのモデルです。売上額のような連続した数値の予測には使えません。
-
C(不正解) |線形回帰は、他の特徴量(例:広告費、天気)から数値を予測する「回帰」モデルですが、
ARIMA_PLUSのようにデータがもつ時間的な順序や季節性を専門的に扱うことはできません。
模擬問題を解いてみる 16
問題
あるデータ アナリストが、顧客がキャンペーンに反応するかどうかを予測するモデルを、SQL スキルを活かして迅速に構築したいと考えています。データはすべて BigQuery にあり、複雑なプログラミングや環境構築は避け、SQL のワークフローの中で手早く仮説検証を行いたいと思っています。
このアナリストのニーズに最も適したサービスはどれですか?
選択肢
A. BigQuery ML
B. AutoML Tables
C. Colab Enterprise
D. Vertex AI Pipelines
解答と解説
正解|A
解説
この問題の鍵は、「データ アナリスト」が「SQL スキルを活かして」「手早く」モデルを構築したい、という点です。
-
A(正解) |BigQuery ML は、まさにデータ アナリストが使い慣れた SQL を使って、データの前処理からモデルのトレーニング、予測までを一気通貫で行えるように設計されたサービスです。このシナリオに完璧に合致します。
-
B(不正解) |AutoML は、GUI ベースで高精度なモデルを自動構築するサービスで、ML の専門知識がないビジネス ユーザーなどに最適です。「SQL スキルを活かしたい」というアナリストのニーズとは少し異なります。
-
C(不正解) |Colab Enterprise は、データ サイエンティストが Python を使って高度な分析やカスタムモデル開発を行うためのノートブック環境です。SQL だけでなく、より柔軟なプログラミングが求められる場合に選択します。
-
D(不正解) |Vertex AI Pipelines は、ML ワークフロー全体を自動化・管理するための、より専門的で大規模な開発向けのサービスです。手早く仮説検証したいというニーズには過剰です。
模擬問題を解いてみる 17
問題
あなたのチームは、データレイクとして Cloud Storage を活用しており、そこには他部門から提供される Parquet 形式のファイルが日々追加されています。あなたは、これらのファイルを BigQuery にロード(移動)することなく、現在のデータの状態でどのような傾向があるか、一時的な探索的分析を BigQuery のインターフェースから直接行いたいと考えています。
この要件を満たす最も効率的な方法は何ですか?
選択肢
A. Cloud Shell を使い、gcloud コマンドで Parquet ファイルをダウンロードしてから分析する。
B. Dataproc クラスタを使い、Spark SQL で Parquet ファイルを読み込んで分析する。
C. Dataflow ジョブを起動して、Parquet ファイルを BigQuery のネイティブ テーブルにロードする。
D. BigQuery で、Cloud Storage 上の Parquet ファイルをデータソースとする外部テーブルを作成する。
解答と解説
正解|D
解説
この問題のポイントは、「データを移動することなく」「一時的な探索的分析」を「BigQuery のインターフェースから」行いたい、という点です。
-
D(正解) |外部テーブルは、まさにこの目的のための機能です。Cloud Storage 上のファイルをあたかも BigQuery のテーブルであるかのように見せかけ、直接クエリを実行できます。データの移動が不要なため、ストレージ コストを二重にもつことなく、迅速に分析を開始できます。
-
A(不正解) |ファイルをローカルにダウンロードする方法は、データが大規模な場合には現実的ではなく、非効率です。
-
B(不正解) |Dataproc でも Parquet ファイルの分析は可能ですが、「BigQuery のインターフェースから」という要件に反します。
-
C(不正解) |データを BigQuery にロードするのは、継続的な分析や高いパフォーマンスが求められる場合に適しています。「一時的な探索的分析」には、外部テーブルの方が手軽で迅速です。
模擬問題を解いてみる 18
問題
あなたの会社の経理チームは、長年 Google スプレッドシートを主要な分析ツールとして使用してきました。今回、数億行に及ぶ大規模な取引履歴データが BigQuery に格納されましたが、経理チームのメンバーは SQL に慣れていません。
彼らが、使い慣れたスプレッドシートのインターフェース(ピボット テーブル、グラフ、関数など)をそのまま使い、BigQuery 上の大規模なデータに直接接続して分析できるようにするには、どの機能を紹介するのが最も適切ですか?
選択肢
A. BigQuery の CSV エクスポート機能
B. コネクテッド シート
C. Looker Studio
D. 承認済みビュー
解答と解説
正解|B
解説
この問題の鍵は、「スプレッドシートのインターフェース」で「BigQuery の大規模データに直接接続」したいという、ビジネス部門のユーザーからの具体的な要望です。
-
B(正解) |コネクテッド シートは、まさにこの課題を解決するために開発された機能です。Google スプレッドシートから、BigQuery のパワーを活用して数億行規模のデータを直接、かつ高速に操作できます。ユーザーは SQL を書く必要がありません。
-
A(不正解) |BigQuery からデータを CSV としてエクスポートする方法では、スプレッドシートの行数上限(約 1,000 万行)をすぐに超えてしまい、数億行のデータを扱うことはできません。
-
C(不正解) |Looker Studio は高機能な BI(可視化)ツールですが、「スプレッドシートのインターフェースで分析したい」というユーザーの要望には直接応えるものではありません。
-
D(不正解) |承認済みビューは、データへのアクセスを制御するためのセキュリティ機能であり、分析インターフェースを提供するものではありません。
5. データレイクの基盤!Cloud Storage の賢い使い方
これまでのセクションで、データ パイプラインやデータ ウェアハウスについて見てきました。では、それらの処理の元となる、あらゆる形式の生データはどこに置いておけばよいのでしょうか。その答えが Cloud Storage です。
Cloud Storage は、画像、動画、ログファイル、CSV、Parquet など、どんな形式のファイル(オブジェクト)でも、容量を気にせずそのまま保存できる、非常にスケーラブルなオブジェクト ストレージ サービスです。
分析の世界では、このように加工前のあらゆるデータを一箇所に集めて貯めておく場所を 「データレイク」 と呼びます。Cloud Storage は、まさにこのデータレイクの基盤として最適なサービスです。
5.1. ストレージ クラスの選択|コストと可用性のバランス
Cloud Storage の大きな特徴は、データのアクセス頻度に応じて、複数の 「ストレージ クラス」 を使い分けられる点です。適切なクラスを選ぶことで、ストレージのコストを大幅に削減できます。

Nearline、Coldline、Archive は保管料金が安い代わりに、データの読み取り料金が Standard より高く設定されており、また、最小保存期間(その期間内にデータを削除しても、最小保存期間分の料金は必ず課金される仕組み)が設けられています。
5.2. ライフサイクル管理|データを自動で最適化
「最初は頻繁に使うけど、30 日経ったらほとんどアクセスしなくなる」といったデータはよくあります。オブジェクトのライフサイクル管理機能を使えば、このようなデータのストレージ クラスを自動で変更したり、削除したりするルールを設定できます。
例えば、以下のようなルールを設定できます。
-
ルール1|作成から 30 日が経過したオブジェクトを、
StandardからNearlineに移動する。 - ルール2|作成から 365 日が経過したオブジェクトを削除する。
この機能を活用することで、手動での管理の手間をなくし、つねにストレージ コストを最適な状態に保つことができます。
5.3. Autoclass|ストレージ クラスを完全自動最適化
ライフサイクル管理よりもさらに手軽にコストを最適化したい場合に便利なのが Autoclass 機能です。
バケットでこの機能を有効にすると、Cloud Storage がオブジェクトへのアクセス パターンを自動的に監視し、アクセスされなくなったデータを Standard から Nearline へ、さらに Coldline、Archive へと、最適なストレージ クラスに自動で移動してくれます。逆に、アーカイブされていたデータにアクセスがあれば、自動で Standard に戻してくれます。
ライフサイクルルールの詳細な設定は不要で、管理の手間を最小限に抑えたい場合に非常に有効です。
5.4. データの保護と権限管理
- バージョニング|オブジェクトのバージョニングを有効にすると、ファイルを上書きしたり削除したりしても、以前のバージョンが保持されます。これにより、誤った操作をしてしまった場合でも、簡単にデータを復元できます。
-
ロケーション|バケット(オブジェクトの入れ物)を作成する際には、データの保存場所(ロケーション)を選択します。
- リージョン|特定の 1 つのリージョン(例|東京)にデータを保存します。低レイテンシが求められる場合に最適です。
- デュアルリージョン|特定の 2 つのリージョンにデータを保存し、冗長化します。片方のリージョンで障害が起きても、もう片方からアクセスできます。
- マルチリージョン|大陸レベル(例|アジア)で、複数のリージョンにデータを分散して保存します。最も高い可用性を提供します。ただし、ユーザーがリージョンを指定することはできません。
-
均一なバケットレベルのアクセス制御(Uniform Bucket-Level Access)
これは、Cloud Storage のセキュリティを考える上で非常に重要な設定です。Cloud Storage の権限管理には、「きめ細かい(Fine-grained)」と「均一(Uniform)」 の 2 つのモードがあります。
- きめ細かい|従来のアクセス制御リスト(ACL)を使い、バケット内のオブジェクトごとに個別の権限を設定できます。柔軟性が高い反面、管理が複雑になり、意図しない設定ミスにつながる可能性があります。
- 均一|バケット内のすべてのオブジェクトに対する権限管理を IAM のみに統一します。ACL は無効化され、IAM で一貫したポリシーを適用できるため、管理が簡素化されセキュリティが向上します。
Google Cloud ではこの 「均一なバケットレベルのアクセス制御」を有効にすることが推奨されています(ベスト プラクティス)。
5.5. Cloud Storage へのデータ移行
オンプレミスのファイルサーバーや、他のクラウド ストレージから、大量のデータを Cloud Storage にもってくる際には、専用の転送サービスを利用します。
Storage Transfer Service|オンラインでのデータ転送
- Storage Transfer Service は、Amazon S3 やオンプレミスのファイルサーバーなど、さまざまなソースから Cloud Storage へのオンラインでのデータ転送を、マネージドで実行するサービスです。
転送のスケジューリングといった基本的な機能に加え、転送対象を絞り込むフィルタ機能(包含 / 除外プレフィックスなど)や、ジョブの並列 / 直列実行を調整することで、転送速度の最適化や API 制限の回避といった、より高度な制御が可能です。
Transfer Appliance|オフラインでのデータ転送
- Transfer Appliance は、ネットワーク帯域が限られていたり、ペタバイト級の非常に巨大なデータを転送したりする場合に利用する、物理的なアプライアンスです。
このアプライアンスがデータセンターに送付され、データをコピーしたのち、Google に返送することで、安全かつ高速にデータを Cloud Storage にアップロードできます。
模擬問題を解いてみる 19
問題
あなたの会社では、アプリケーションから出力される操作ログを、分析目的ですべて Cloud Storage に保存しています。このログデータは、最初の 30 日間はトラブルシューティングのために頻繁にアクセスされますが、次の 150 日間は月に 1 回程度の定期監査で利用され、それ以降はコンプライアンス要件のために 5 年間、ほとんどアクセスのない状態で保持する必要があります。
この要件を満たしつつ、ストレージ コストを継続的に、かつ自動で最適化する最も適切な設定はどれですか?
選択肢
A. バケットでバージョニングを有効にし、古いバージョンを定期的に手動で削除する。
B. すべてのログデータを最初から Archive ストレージ クラスに保存する。
C. オブジェクトのライフサイクル管理ポリシーを設定し、経過日数に応じてストレージ クラスを Standard から Nearline、さらに Coldline へと自動的に移行させる。
D. Autoclass 機能を有効にして、アクセス パターンに応じたストレージ クラスの最適化と、5 年経過したデータの自動削除を行う。
解答と解説
正解|C
解説
この問題の鍵は、「経過日数に応じてアクセス頻度が明確に決まっている」データの「ストレージ コストを自動で最適化したい」という点です。
-
C(正解) |オブジェクトのライフサイクル管理は、まさにこのためにある機能です。「作成から 30 日後に Nearline へ」「180 日後に Coldline へ」といった明確なルールを定義することで、人間の手を介さずに、自動でストレージ クラスを最適なものに変更し、コストを最小化できます。
-
A(不正解) |バージョニングは誤削除からの復旧を目的としており、コスト最適化の機能ではありません。また、手動での運用は「自動で」という要件を満たせません。
-
B(不正解) |最初の 30 日間は頻繁にアクセスされるため、いきなり Archive に保存すると、データの読み取り料金が高額になってしまい、トータルコストが逆に増加します。
-
D(不正解) |Autoclass はアクセス パターンが予測できない場合に有効な機能ですが、この問題のようにルールが明確な場合はライフサイクル管理の方が確実です。また、Autoclass はオブジェクトの削除は自動で行いません。
模擬問題を解いてみる 20
問題
あなたの会社は、オンプレミスのデータセンターにあるファイルサーバー(NFS)で管理している 200TB の画像データを、すべて Cloud Storage に移行することを決定しました。データセンターには十分なネットワーク帯域があり、オンラインでのデータ転送が可能です。
移行作業の信頼性を担保し、管理の手間を最小限に抑えたいと考えています。この要件に最も適したサービスはどれですか?
選択肢
A. Storage Transfer Service を利用して、オンプレミスからの転送ジョブを作成する。
B. Transfer Appliance を Google にリクエストし、データをコピーして返送する。
C. Compute Engine インスタンスを複数台立て、gcloud コマンドを使って並列でアップロードするスクリプトを自作する。
D. Google ドライブに一度すべてのデータをアップロードし、そこから Cloud Storage に移動する。
解答と解説
正解|A
解説
この問題のポイントは、「オンラインで」「大規模なファイルデータ」を「マネージドな方法で」移行したい、という点です。
-
A(正解) |Storage Transfer Service は、まさにこの目的のためのフルマネージド サービスです。オンプレミスの NFS や POSIX ファイルシステム、他のクラウド ストレージ(Amazon S3 など)から Cloud Storage への、信頼性の高い大規模なオンラインデータ転送を実現します。
-
B(不正解) |Transfer Appliance は、ネットワーク帯域が限られている、またはペタバイト級の超大規模データを移行する場合に使うオフラインの物理アプライアンスです。このシナリオではオンライン転送が可能なので、不適切です。
-
C(不正解) |gcloud を使ったスクリプトでも移行は可能ですが、エラーハンドリング、再試行、整合性チェックなどをすべて自前で実装する必要があり、「管理の手間を最小限に」という要件に反します。
-
D(不正解) |Google ドライブは個人のファイルを扱うためのサービスであり、数百テラバイト規模のデータ移行を目的としたツールではありません。
模擬問題を解いてみる 21
問題
あなたは、ネットワーク接続が非常に遅い山間部の研究所に、過去 10 年分の観測データを収めた 800TB のストレージサーバーを設置しています。このデータを分析のため、Google Cloud Storage にアップロードする必要がありますが、現在のネットワーク環境ではオンラインでの転送に数年かかってしまう計算です。
この状況で、データを安全かつ現実的な時間で Cloud Storage に移行するための最も適切な方法はどれですか?
選択肢
A. ネットワーク回線を増強し、gcloud コマンドで少しずつアップロードする。
B. Storage Transfer Service を設定し、オンラインでの転送をスケジュールする。
C. Transfer Appliance という物理的なアプライアンスを取り寄せ、データをコピーした上で Google に郵送する。
D. すべてのデータを一度 USB ドライブにコピーし、都市部の高速なネットワーク環境にもち込んでアップロードする。
解答と解説
正解|C
解説
この問題の鍵は、「ネットワーク接続が非常に遅い」環境から、「ペタバイト級の非常に巨大なデータ」を移行したい、という明確な制約です。
-
C(正解) |Transfer Appliance は、まさにこのようなオフラインでの大規模データ移行のために提供されているサービスです。ネットワーク帯域の制約を受けずに、物理メディアを使って安全かつ高速にデータを Google Cloud に送ることができます。
-
A(不正解) |ネットワーク回線の増強はコストと時間がかかり、現実的ではありません。
-
B(不正解) |Storage Transfer Service はオンラインでの転送を前提としたサービスです。ネットワークがボトルネックとなっているこの状況では、利用できません。
-
D(不正解) |800TB ものデータを個人用の USB ドライブで運ぶのは、セキュリティ、信頼性、作業量のいずれの観点からも現実的な方法ではありません。
6. 高度なデータ探索と分析|Colab Enterprise
BigQuery ML や AutoML は、SQL や GUI を使って手軽に機械学習を実践できる強力なツールです。しかし、より複雑なデータ分析や、独自のアルゴリズムを使ったモデル開発を行いたいデータ サイエンティストにとっては、プログラミング言語である Python を使える環境が不可欠です。
このニーズに応えるのが Colab Enterprise です。
Colab Enterprise は、Google Cloud のセキュリティと連携機能を備えた、フルマネージドな Python ノートブック環境です。おなじみの Jupyter ノートブックのインターフェースで、BigQuery や Cloud Storage 上のデータに簡単にアクセスし、高度なデータ分析や探索的データ解析(EDA)を行うことができます。
6.1. 他のツールとの使い分け
- BigQuery ML|SQL で手早くモデルを作りたいデータ アナリスト向け。
- AutoML|GUI で高精度なモデルを作りたいビジネス ユーザー向け。
- Colab Enterprise|Python を使って、より柔軟なデータ分析やカスタムモデル開発を行いたいデータ サイエンティストや ML エンジニア向け。
模擬問題を解いてみる 22
問題
あなたは機械学習エンジニアとして、BigQuery にあるデータを使って新しい予測モデルのプロトタイプを開発しています。モデルの精度を高めるため、pandas や scikit-learn といった専門的な Python ライブラリを使い、複雑な特徴量エンジニアリング(データの前処理や加工)を行う必要があります。
この探索的な分析とプロトタイピングの作業を、対話的なノートブック環境で迅速に行い、その結果をチームメンバーと簡単に共有したいと考えています。本格的な大規模トレーニングにかける前の、この試行錯誤のフェーズに最も適したサービスはどれですか?
選択肢
A. Vertex AI のカスタムトレーニングジョブ
B. AutoML Tables
C. Colab Enterprise
D. BigQuery ML
解答と解説
正解|C
解説
この問題の鍵は、「機械学習エンジニア」が「専門的な Python ライブラリ」を使い、「対話的なノートブック環境で試行錯誤したい」という、プロフェッショナルなモデル開発の初期段階の要件です。
-
C(正解) |Colab Enterprise は、まさにこの目的のためのフルマネージドなノートブック環境です。Google Cloud のサービスとシームレスに連携し、Python を使った高度なデータ分析や、カスタムモデルの迅速なプロトタイピング、チームでの共同作業を可能にします。
-
A(不正解) |Vertex AI のカスタムトレーニングは、プロトタイピングが完了した後の、本格的な大規模トレーニングを実行するためのサービスです。「対話的な試行錯誤」のフェーズには適していません。
-
B(不正解) |AutoML Tables は GUI ベースのノーコード・ローコードツールであり、Python を使った複雑でカスタムな前処理を行いたいという要件には合致しません。
-
D(不正解) |BigQuery ML は SQL を使ってモデルを構築するサービスです。
pandasなどの Python ライブラリを自由に使いたいという、機械学習エンジニアのニーズには応えられません。
7. 複数サービスを横断するデータ ガバナンス|Dataplex
Cloud Storage にデータレイクを、BigQuery にデータ ウェアハウスを構築しましたが、データがさまざまな場所に分散すると、「どこに、どんなデータが、どのような品質で存在するのか」が分からなくなる、という新たな課題が生まれます。
この、組織全体のデータに対する 「ガバナンス(統治)」 を一元的に実現するサービスが Dataplex です。Dataplex は、Cloud Storage や BigQuery 上に分散しているデータを、まるで一つの場所にあるかのように管理、保護、統治するための統合管理コンソールです。
7.1. Dataplex の主な役割
Dataplex は、図書館の司書のように、組織のデータという資産を整理し、誰もが安心して利用できる状態を保ちます。
- データカタログ|組織内のデータアセットを自動的に検出し、検索可能なカタログを作成します。
- データ品質管理|データが正確か、期待されるフォーマットに準拠しているかなどをチェックするルールを定義し、自動で監視します。
- データリネージ|データがどこから来て、どのように変換されたのか、その足跡を追跡します。
- 一元的なセキュリティ|データレイク、データマートにまたがって、一貫したセキュリティ ポリシーを適用します。
Dataplex では、データを以下の階層構造で管理します。
- レイク(Lake) |特定のデータドメインやビジネス ユニット(例|マーケティング部門)を表す論理的なグループです。
-
ゾーン(Zone) |レイク内の区画で、データの状態に応じて分割します。
- Raw Zone|未加工の生データを格納します(例|Cloud Storage バケット)。
- Curated Zone|クレンジング、変換、検証済みのデータを格納します(例|BigQuery データセット)。
- アセット(Asset) |ゾーンにマッピングされる、Cloud Storage バケットや BigQuery データセットといった物理的なリソースです。
7.2. データの可視化と共有!Looker ファミリーと BigQuery Sharing
BigQuery を使ってデータから貴重なインサイトを見つけ出しても、それがただの数字の羅列では、他の人には伝わりません。分析結果をグラフや表を使って分かりやすく表現(可視化)し、チームや組織で共有して初めて、データはビジネス上の意思決定に活かされます。
このデータの「さいごの出口」を担うのが、Looker ファミリー(Looker Studio、Looker Studio Pro、Looker)と BigQuery Sharing の機能群です。
Looker Studio|手軽に始めるデータ可視化
Looker Studio(旧データポータル)は、無料で利用できる、非常に高機能なセルフサービス BI ツールです。
ドラッグ & ドロップの簡単な操作で、BigQuery をはじめとするさまざまなデータソースに接続し、インタラクティブなレポートやダッシュボードを作成できます。
Looker Studio Pro|チームでの利用とガバナンス強化
Looker Studio Pro は、無料版の Looker Studio の全機能に加え、チームでの利用や企業のガバナンスを強化するための機能を追加した有料版です。
チーム ワークスペース機能により、部署単位でのコンテンツ管理が可能になったり、Google Cloud の公式サポートが受けられたりと、より安心して組織的に利用できる基盤が提供されます。
Looker|組織全体のデータ活用を促進する BI プラットフォーム
Looker は、Looker ファミリーの最上位に位置する、エンタープライズ向けの BI プラットフォームです。
最大の特徴は、LookML という独自のモデリング言語を使って、「セマンティック レイヤ」を構築できる点にあります。セマンティック レイヤとは、物理的なデータベースと最終的な利用者との間に位置し、複雑なデータを「売上」「顧客数」といった分かりやすいビジネス用語に翻訳してくれる中間層のことです。
LookML を使って、このセマンティック レイヤに「売上 = 商品価格 × 数量」といったビジネス指標を一度だけ定義すれば、組織内の誰もがその共通の定義に基づいてデータを分析できるようになります。
これにより、「人によって売上の集計方法が違う」といった混乱を防ぎ、組織全体で一貫したデータ活用(データ ガバナンス)を実現します。
結局、どれを使えばいいの?目的別ツール選択ガイド
それぞれのツールの特徴を理解した上で、目的別にどう使い分けるかを整理しておきましょう。
-
すぐに・手軽に・無料で可視化したい →
Looker Studio- 個人のデータ アナリストや小規模なチームが、手元のデータを使って素早くダッシュボードを作成するのに最適です。
-
全社で指標を統一し、統制の取れた分析環境を構築したい →
Looker- データ ガバナンスを最優先し、「信頼できる唯一の指標」を全社に提供したいエンタープライズ向けの選択肢です。
-
統制された指標を、手軽な UI で使いたい →
Looker Studio Pro+Looker- Looker で定義した信頼できるデータモデル(セマンティック レイヤ)をデータソースとして、Looker Studio の直感的なインターフェースでダッシュボードを作成する、というハイブリッドな使い方が可能です。
BigQuery Sharing(旧 Analytics Hub)|データセットを安全に共有
Looker ファミリーが分析結果である「インサイト」を共有するのに対し、BigQuery Sharing はデータそのものを共有するための機能群です。
その中でもとくに、組織をまたいでデータセットを安全に共有する仕組みが BigQuery Data Exchange です。
共有できるアセットは BigQuery のデータセットだけでなく、Pub/Sub のトピックなども対象です。
- Publisher と Subscriber|データを共有する側(Publisher)が、共有したいデータセットを「リスティング」として公開します。データを利用したい側(Subscriber)は、そのリスティングを購読することで、自身のプロジェクト内に、共有データセットへの読み取り専用リンク(リンクされたデータセット)を作成できます。
データ自体はコピーされず、元の場所から移動しないため、Publisher はつねにデータの所有権と統制を維持したまま、安全にデータを共有できます。
模擬問題を解いてみる 23
問題
あなたの会社では、データレイクが Cloud Storage に、データ ウェアハウスが BigQuery に構築されており、データが複数の場所に分散しています。データセキュリティチームは、これらの分散したデータに対して一貫したアクセス ポリシーを適用するのに苦労しています。また、アナリストは「どこに、どんなデータがあるのか分からない」「このデータがどのように作られたのか追跡できない(データリネージ)」という課題を抱えています。
これらの課題を解決し、データ資産の横断的な発見、セキュリティ管理、リネージ追跡を可能にする統合データ ガバナンス基盤として、最も適切なサービスはどれですか?
選択肢
A. IAM をプロジェクト全体に適用し、権限を統一する。
B. Dataplex を利用して、レイクとゾーンを定義し、データアセットをアタッチする。
C. BigQuery ですべてのテーブルに厳密な権限を設定し、Cloud Storage へのアクセスは個別に管理する。
D. Data Catalog ですべてのデータアセットにタグを付け、手動で管理する。
解答と解説
正解|B
解説
この問題の鍵は、Cloud Storage と BigQuery という複数のサービスにまたがるデータに対して、「発見・セキュリティ・リネージ」といった統合的なガバナンスを実現したい、という点です。
-
B(正解) |Dataplex は、まさにこの目的のために設計されたサービスです。Cloud Storage や BigQuery 上のデータを単一の管理画面で統治し、データカタログ、データ品質、データリネージ、一元的なセキュリティ ポリシーの適用などを実現します。
-
A(不正解) |IAM は権限管理の根幹ですが、それだけではデータカタログやリネージといった機能は提供されません。
-
C(不正解) |これは現状の課題そのものであり、統合的な解決策ではありません。セキュリティ ポリシーが分散し、管理が複雑化します。
-
D(不正解) |Data Catalog は Dataplex の中核機能の一つですが、Dataplex はカタログ機能に加え、セキュリティやデータ品質管理なども含んだ、より包括的なガバナンスソリューションです。
模擬問題を解いてみる 24
問題
あなたは、独自の市場分析データを保有する企業に勤めています。この価値あるデータを、複数の企業に対して有料で提供する新しいデータ ビジネスを立ち上げたいと考えています。
BigQuery のデータセットを、安全かつスケーラブルな方法で外部の顧客(サブスクライバー)に共有し、データの所有権は自社で維持したまま、顧客が自身のプロジェクトから直接クエリできるようにするデータマーケットプレイスを構築するには、どのサービスが最も適していますか?
選択肢
A. 顧客ごとに承認済みビューを作成し、個別にアクセス権を付与する。
B. BigQuery Sharing(Analytics Hub) を利用して、共有データセットのリスティングを公開する。
C. データを定期的に Cloud Storage バケットにエクスポートし、顧客にそのバケットへのアクセス権を付与する。
D. Dataplex を利用して、外部組織をレイクのメンバーとして追加する。
解答と解説
正解|B
解説
この問題のポイントは、「複数の外部企業」に対して、「スケーラブル」な方法で「データを共有・販売」したいという、データ マーケットプレイスの要件です。
-
B(正解) |BigQuery Sharing(Analytics Hub) は、まさにこの目的のためのサービスです。組織間で BigQuery のデータセットを安全に共有するためのプラットフォームであり、リスティングとしてデータを公開することで、多数のサブスクライバーに対して効率的にデータを提供できます。
-
A(不正解) |承認済みビューは、特定の相手とデータのサブセットを共有するのに有効ですが、不特定多数の顧客を管理するようなスケーラブルなモデルには適していません。
-
C(不正解) |データをコピーして共有する方法は、自社がデータの所有権と統制を維持しにくくなり、また、顧客はつねに最新のデータにアクセスできません。
-
D(不正解) |Dataplex は、主に組織内部のデータ ガバナンスを目的としたサービスであり、外部向けのデータ共有マーケットプレイスを構築するためのものではありません。
模擬問題を解いてみる 25
問題
ある小規模なスタートアップのプロジェクト マネージャーが、プロジェクトの進捗状況をまとめた Google スプレッドシートのデータを、チームメンバーに分かりやすく可視化して共有したいと考えています。
彼には BI ツールの予算がなく、また技術的な専門知識もありません。無料で利用でき、直感的なドラッグ&ドロップ操作でインタラクティブなダッシュボードを作成できるツールとして、最も適切なものはどれですか?
選択肢
A. Looker
B. Google スプレッドシートのグラフ機能
C. Colab Enterprise
D. Looker Studio
解答と解説
正解|D
解説
このシナリオの鍵は、「無料」「非技術者」「直感的な操作」「ダッシュボード作成」という 4 つの要件です。
-
D(正解) |Looker Studio(旧データポータル)は、これらの要件に完璧に合致する無料のセルフサービス BI ツールです。Google スプレッドシートを含む様々なデータソースに簡単に接続し、コーディングなしでインタラクティブなダッシュボードを作成できます。
-
A(不正解) |Looker は、LookML というモデリング言語を特徴とするエンタープライズ向けの有料 BI プラットフォームであり、「無料」という要件に合致しません。
-
B(不正解) |スプレッドシートの組み込みグラフ機能も便利ですが、複数のグラフや表を組み合わせたインタラクティブなダッシュボードを作成するには、専用の BI ツールである Looker Studio の方がはるかに高機能で適しています。
-
C(不正解) |Colab Enterprise は、データ サイエンティストが Python を使って分析を行うためのコードベースのノートブック環境であり、「非技術者」「直感的な操作」という要件とは正反対です。
模擬問題を解いてみる 26
問題
あなたの会社では、営業、マーケティング、財務の各部門が、それぞれ独自の方法で「アクティブ ユーザー数」を計算しており、会議で報告される数値が食い違うという問題が頻発しています。
データチームは、この問題を解決するため、「アクティブ ユーザー」の定義や計算ロジックを一度だけ記述すれば、組織内の全部門がそれを共通の指標として利用できる仕組みを導入したいと考えています。このような一元管理されたビジネスロジック(セマンティック レイヤ)を構築し、全社的なデータ ガバナンスを実現するのに最も適した BI プラットフォームはどれですか?
選択肢
A. Looker Studio に、各部門が従うべき計算方法のガイドラインを共有する。
B. BigQuery に、公式の計算ロジックを実装したビューを作成し、各部門がそれを使うように依頼する。
C. Looker を導入し、LookML というモデリング言語で「アクティブ ユーザー」の定義を一元化して管理する。
D. Dataplex を使って、各部門が作成したテーブルに「公式」「非公式」のタグを付ける。
解答と解説
正解|C
解説
この問題のポイントは、単にデータを可視化するだけでなく、「ビジネス指標の定義を全社で統一したい」という、高度なデータ ガバナンスの要件です。
-
C(正解) |Looker の最大の特徴は、LookML というモデリング言語を使って、データモデルとビジネスロジックを一元管理できる点にあります。「アクティブ ユーザー」の定義を LookML で一度記述すれば、全社のユーザーがその信頼できる単一の定義に基づいて分析を行うことができ、指標の混乱を防ぎます。
-
A(不正解) |ガイドラインの共有は、遵守を個人の努力に依存するため、根本的な解決にはなりません。システム的な統制が必要です。
-
B(不正解) |BigQuery のビューで計算ロジックを共通化するのは良いアプローチですが、Looker のように、ユーザーフレンドリーな探索機能や、より高度なアクセス制御、BI プラットフォームとしての総合的な機能は提供されません。
-
D(不正解) |Dataplex は物理的なデータ資産(テーブルなど)のガバナンスには有効ですが、BI レイヤーで使われる「ビジネス指標の定義」そのものを統制するものではありません。
8. パイプラインの安定稼働を支える監視と運用
データの世界では、パイプラインは作って終わりではありません。それが毎日、安定して稼働することで価値を生み出します。
このセクションでは、構築したパイプラインを安定稼働させるための「監視(モニタリング)」と「運用」に欠かせない 3 つのツールについて、その役割分担を分かりやすく解説します。
8.1. Dataflow ジョブ UI|パイプラインの健康診断
Dataflow でパイプラインを実行すると、Google Cloud コンソールに専用の管理画面(ジョブ UI)が表示されます。これは、実行中のパイプラインの「健康状態」をリアルタイムで確認できる、いわば健康診断のようなものです。
この画面を見れば、
- データがどのステップを、どれくらいの量で流れているか
- 処理に時間がかかっているボトルネックはどこか
- エラーが発生していないか
といったパイプラインの実行状況が一目で分かります。パイプラインのパフォーマンスを視覚的に理解し、チューニングのヒントを得るための入り口です。
8.2. Cloud Monitoring|パイプラインの監視
Cloud Monitoring は、Google Cloud 全体のリソースを監視するための、より広範囲な監視システムです。Dataflow パイプラインに対しても、CPU 使用率や処理の遅延(システムラグ)といったさまざまな指標(メトリクス)を収集し、ダッシュボードで可視化することができます。
Monitoring の最も重要な役割は、「異常が発生したら、知らせてくれる」アラート機能です。例えば、「パイプラインの処理遅延が 10 分を超えたらメールで通知する」といったルールを設定しておくことで、問題の発生をプロアクティブ(能動的)に検知し、迅速に対応できます。
8.3. Cloud Logging|エラーの「原因」を突き止める
もし、Cloud Monitoring のアラートが鳴ったり、Dataflow のジョブが失敗してしまったら、次はその「原因」を突き止めなければなりません。その時に活躍するのが、Cloud Logging です。
Cloud Logging には、パイプラインが実行中に出力したすべてのログメッセージが記録されています。ジョブが失敗した場合は、ここに「なぜ失敗したのか」を示す詳細なエラー メッセージが残されています。エラー箇所を特定し、プログラムのどの部分に問題があったのかをデバッグするための、最も重要な手がかりとなります。
模擬問題を解いてみる 27
問題
あなたは、毎日実行される重要な Dataflow パイプラインを運用しています。ある朝、パイプラインの処理が通常より大幅に遅れていることに気づきました。まずは、パイプラインのどの処理ステップでデータが滞留しているのか、実行状況を視覚的に確認してボトルネックを特定したいと考えています。
この状況で、最初に確認すべき最も適切な場所はどこですか?
選択肢
A. Cloud Logging で、slow というキーワードを含むログを検索する。
B. Dataflow ジョブ UI を開き、各ステップの処理状況とウォーターマークを確認する。
C. Cloud Monitoring で、CPU 使用率のダッシュボードを確認する。
D. BigQuery で、パイプラインが出力したテーブルの行数が増えているか確認する。
解答と解説
正解|B
解説
この問題の鍵は、「実行中のパイプライン」の「ボトルネックを視覚的に特定したい」という、パフォーマンス問題の初期調査の要件です。
-
B(正解) |Dataflow ジョブ UI は、パイプラインの各ステップをグラフィカルに表示し、データの流れや処理にかかっている時間(システムラグ)、どこでデータが滞留しているかを視覚的に確認できるため、ボトルネックを特定する最初のステップとして最も適しています。
-
A(不正解) |Cloud Logging は、エラーが発生した場合や、詳細なログメッセージを確認するのには役立ちますが、パフォーマンスのボトルネックを視覚的に把握するのには適していません。
-
C(不正解) |Cloud Monitoring のダッシュボードは、CPU 使用率などの全体的な傾向を把握するのには有効ですが、「どのステップで」滞留しているかという、より詳細な情報を得るには Dataflow ジョブ UI が適しています。
-
D(不正解) |最終的な出力テーブルを確認するだけでは、パイプラインの途中のどこで問題が発生しているのかを特定することはできません。
模擬問題を解いてみる 28
問題
あなたは、ストリーミング データを取り込む Dataflow パイプラインを 24 時間 365 日体制で運用しています。今後、何らかの問題でパイプラインの処理遅延(データ鮮度)が 15 分を超えた場合に、運用チームが即座に問題を検知できるよう、自動でアラート通知を受け取る仕組みを導入する必要があります。
この要件を実現するために設定すべきサービスはどれですか?
選択肢
A. Cloud Functions を使って、定期的にパイプラインの状態をチェックする関数を作成する。
B. Cloud Monitoring で、Dataflow の「システムラグ」メトリクスに対するアラートポリシーを作成する。
C. Cloud Logging で、特定のログが出力されたら通知するログベースのアラートを設定する。
D. Dataflow ジョブ UI を定期的に手動で確認するルールをチームで徹底する。
解答と解説
正解|B
解説
このシナリオのポイントは、「特定のしきい値(15分)を超えたら」「プロアクティブ(能動的)にアラートで通知する」という、継続的な監視の仕組みを構築したい点です。
-
B(正解) |Cloud Monitoring は、Google Cloud リソースのメトリクスを監視し、しきい値に基づいたアラートを送信するための中心的なサービスです。「システムラグ」というまさにこの目的に合ったメトリクスを使ってアラートポリシーを作成するのが、最も標準的で効果的な方法です。
-
A(不正解) |この方法でも実現可能ですが、監視のためだけにカスタムコードを開発・運用する必要があり、標準機能である Cloud Monitoring を使うのに比べてはるかに手間がかかります。
-
C(不正解) |ログベースのアラートも強力な機能ですが、今回の「処理遅延」のような数値ベースのメトリクス監視には、Cloud Monitoring のメトリクスベースのアラートの方がより直接的で適しています。
-
D(不正解) |手動での確認は、「自動で」という要件を満たせず、24 時間体制の運用では現実的ではありません。
模擬問題を解いてみる 29
問題
夜間に実行されたバッチ処理の Dataflow パイプラインが、今朝確認したところ「失敗」のステータスで停止していました。あなたは、このジョブがなぜ失敗したのか、根本的な原因を調査する必要があります。
エラーの原因を特定するための最も詳細な情報(スタック トレースやエラー メッセージなど) を見つけるには、どのツールを確認すべきですか?
選択肢
A. Cloud Monitoring のダッシュボードで、エラー発生時刻の CPU 使用率を確認する。
B. Dataflow ジョブ UI を見て、どのステップで失敗したかを確認する。
C. Cloud Logging を開き、失敗した Dataflow ジョブ ID に関連付けられたエラーログを確認する。
D. Cloud Storage に保存されているパイプラインのソースコードを読み返す。
解答と解説
正解|C
解説
この問題の鍵は、すでに「失敗したジョブ」の「根本的な原因(エラー メッセージ)」を調査したい、というトラブルシューティングの要件です。
-
C(正解) |Cloud Logging は、すべての Google Cloud サービスからのログを一元的に集約する場所です。Dataflow ジョブが失敗した場合、その原因となった例外やエラー メッセージの詳細なログが必ずここに出力されます。原因究明のためには、まずここを確認するのが鉄則です。
-
A(不正解) |CPU 使用率は、パフォーマンスの問題を示唆することはあっても、ジョブが失敗した直接的なエラー メッセージを提供してくれるわけではありません。
-
B(不正解) |Dataflow ジョブ UI は、「どのステップで」失敗したかを視覚的に特定するのには役立ちますが、「なぜ」失敗したのかという詳細なエラー メッセージ自体は表示されません。UI で場所を特定し、Logging で原因を調べる、という流れが一般的です。
-
D(不正解) |ソースコードを読み返すことは最終的に必要になるかもしれませんが、まずはエラーログを見て、どこに問題があるかの見当をつけるのが効率的なトラブルシューティングです。
9. まとめ|合格への最終チェックリスト
ここまで、本当にお疲れ様でした!
データ パイプラインの構築から、BigQuery を使った高度な分析、機械学習、そして結果の可視化・共有まで、Associate Data Practitioner 認定資格の合格に必要な知識を巡る長い旅も、いよいよゴールです。
さいごに、これまで学んできた知識を整理し、合格を確実にするための最終チェックリストと、私からのメッセージをお伝えします。
9.1. 各サービスの役割をもう一度おさらいしよう
試験では、「この要件に最適なサービスはどれか?」という問いが繰り返し出題されます。頭の中を整理するために、各サービスがデータ ライフサイクルのどの役割を担うのか、もう一度確認しておきましょう。
-
データの収集・取込(Ingestion)
-
Pub/Sub、Datastream(ストリーミング) -
BigQuery Data Transfer Service、Storage Transfer Service(バッチ)
-
-
データの保管(Storage)
-
Cloud Storage(データレイク|あらゆる形式の生データ) -
Cloud SQL(OLTP|日々の業務データ) -
BigQuery(データ ウェアハウス|分析用の大規模データ)
-
-
データの処理・変換(Processing & Transformation)
-
Dataflow、Dataproc、Cloud Data Fusion(ETL) -
Dataform、BigQuery(ELT) -
Cloud Run Functions / Run(イベント ドリブンな軽量処理)
-
-
データの分析・機械学習(Analysis & ML)
-
BigQuery(SQL での高速分析) -
BigQuery ML、AutoML、Colab Enterprise(モデル構築と予測)
-
-
データの統治(Governance)
-
Dataplex(データカタログ、品質管理、セキュリティ)
-
-
データの可視化・共有(Visualization & Sharing)
-
Looker ファミリー(BI ダッシュボード) -
BigQuery Sharing(データセットの共有)
-
9.2 合格をつかむための 3 ステップ
この記事で得た知識を合格に結びつけるために、以下の 3 ステップで学習を進めることをお勧めします。
-
「流れ」をつかむ|まずはこの記事全体を読み通し、データがどのように集められ、価値に変わっていくのか、その大きなストーリーを理解してください。個別の知識を暗記する前に、全体像を把握することが重要です。
-
「違い」を理解する|次に、「なぜこの場面では Dataflow で、あちらの場面では Dataproc なのか?」「承認済みビューと行レベルのセキュリティはどう使い分けるのか?」といった、類似サービスの明確な違いを自分の言葉で説明できるようにしましょう。試験で問われるのは、まさにこの「適切な使い分け」です。
-
「手を動かす」 |さいごに、少しだけでもいいので、実際に Google Cloud に触れてみてください。無料枠(無料トライアル) を活用して Cloud Storage にファイルをアップロードしたり、BigQuery の一般公開データセットに対してクエリを実行してみるだけでも、知識の定着度が格段に変わります。
Google Cloud 無料トライアルのはじめ方については、こちらの記事を参考にしてください。
10. さいごに
この Associate Data Practitioner という資格の学習を通じてみなさんが得られるものは、単なるツールの知識だけではありません。それは、現代のビジネスに不可欠な 「データをどのようにして価値に変えるか」という普遍的な思考プロセスそのものです。
技術は日々進化していきますが、ここで学んだデータ活用の基本的な考え方や勘所は、これからみなさんがどのようなキャリアを歩んだとしても、必ず強力な武器になるはずです。
この記事が、みなさんにとってデータの世界への扉を開く、鍵となることを心から願っています。
自信をもって試験に臨んでください。応援しています!
Discussion