Java 25 で導入された Ahead-of-Time Method Profiling は事前に収集したプロファイル情報を利用して、JVMの起動時や実行時に最適化を適用する仕組みです。
これにより、従来のJITコンパイルのウォームアップ期間を短縮し、アプリケーションの全体的な性能を向上させると謳われています。
Spring Boot アプリケーションの起動時間と実行時のパフォーマンスを測定してみました。
JEP ドキュメントはこちらです。
Get Started
まずは基本的な使い方から始めてみましょう。
前提条件
当然ですが Java 25 が必要です。SDKMAN でインストールできる Oracle の 25-oracle を利用しました。
> java -version
java version "25" 2025-09-16 LTS
Java(TM) SE Runtime Environment (build 25+37-LTS-3491)
Java HotSpot(TM) 64-Bit Server VM (build 25+37-LTS-3491, mixed mode, sharing)
また以下私の環境です。
- Apple M4 Pro(Nov 2024)
- Memory:48GB
- CPU: 12 (8 performance and 4 efficiency)
- macOS Sequoia 15.6.1
1. Spring Boot アプリを作成
簡単な Spring Boot アプリを作成します。
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello() {
return "Hello, JEP 515!";
}
}
2. アプリケーションをビルド
これまでと特に変わりなくビルドします。ここでは Gradle を使っています。
./gradlew build
3. トレーニング実行(プロファイル収集)
このステップでは、実際の使用パターンを模倣してアプリケーションを実行し、プロファイル情報を収集します。
-XX:AOTMode=record オプションを指定して起動します。
# プロファイル収集モードで実行
java -XX:AOTMode=record -XX:AOTConfiguration=demo.aotconf -jar build/libs/demo-0.0.1-SNAPSHOT.jar
アプリが起動したら、別のターミナルで例えば以下のようにエンドポイントを複数回呼び出して負荷をかけます。
# 基本的なエンドポイントを複数回呼び出し
for i in {1..100}; do
curl http://localhost:8080/hello
sleep 0.1
done
トレーニングが終わったらアプリを停止します。
4. AOT キャッシュの生成
次に、収集したプロファイル情報を基に AOT キャッシュを生成します。
-XX:AOTMode=create オプションを指定して起動します。
> java -XX:AOTMode=create -XX:AOTConfiguration=demo.aotconf -XX:AOTCache=demo.aotcache -jar build/libs/demo-0.0.1-SNAPSHOT.jar
Reading AOTConfiguration demo.aotconf and writing AOTCache demo.aotcache
AOTCache creation is complete: demo.aotcache 107560960 bytes
> ll -trh demo.*
-rw-r--r--@ 1 tsubasa.a.nomura staff 104M 9 18 12:53 demo.aotconf
-rw-r--r--@ 1 tsubasa.a.nomura staff 103M 9 18 12:54 demo.aotcache
java コマンドが終了したら、demo.aotcache というファイルが生成されていることを確認します。
5. 最適化モードで実行
最後に、AOT キャッシュを利用してアプリケーションを起動します。
-XX:AOTMode=on オプションを指定して起動します。
java -XX:AOTMode=on -XX:AOTCache=demo.aotcache -jar build/libs/demo-0.0.1-SNAPSHOT.jar
起動時間の比較
実行時のパフォーマンスは後で詳しく測定しますが、まずは起動ログを確認してみましょう。実際に各モードで10回ずつ起動時間を測定した結果を以下に示します。
AOT キャッシュあり
java -XX:AOTMode=on -XX:AOTCache=demo.aotcache -jar build/libs/demo-0.0.1-SNAPSHOT.jar | grep "Started DemoApplication in"
2025-09-18T15:11:53.650+09:00 INFO 9453 --- [ main] [ ] com.example.demo.DemoApplication : Started DemoApplication in 1.096 seconds (process running for 1.255)
| 回数 | 起動時間 (秒) |
|---|---|
| 1 | 1.265 |
| 2 | 1.023 |
| 3 | 1.031 |
| 4 | 1.034 |
| 5 | 1.024 |
| 6 | 1.017 |
| 7 | 1.014 |
| 8 | 1.045 |
| 9 | 1.038 |
| 10 | 1.096 |
| 平均 | 1.059 |
AOTキャッシュなし
java -jar build/libs/demo-0.0.1-SNAPSHOT.jar | grep "Started DemoApplication in"
2025-09-18T15:11:20.085+09:00 INFO 8949 --- [ main] [ ] com.example.demo.DemoApplication : Started DemoApplication in 1.265 seconds (process running for 1.52)
| 回数 | 起動時間 (秒) |
|---|---|
| 1 | 1.666 |
| 2 | 1.635 |
| 3 | 1.625 |
| 4 | 1.631 |
| 5 | 1.667 |
| 6 | 1.668 |
| 7 | 1.637 |
| 8 | 1.612 |
| 9 | 1.641 |
| 10 | 1.664 |
| 平均 | 1.645 |
起動時間は約 33% の短縮が確認できました。
また、ここまでの手順で分かるように、キャッシュの生成と起動時の指定以外、コードの変更やビルドの手順、依存関係の追加は不要です。
(参考) 起動後のパフォーマンス測定
それでは、起動時間以外の効果を見るためにより詳細な測定を行ってみます。
ただ、あくまでも私の環境で限定されたシナリオでの測定結果であり、アプリケーションの特性や使用パターンによって結果は大きく異なる可能性があるのであくまで参考として紹介します。
テスト用エンドポイント
Spring Boot のアプリケーションに以下のエンドポイントを追加してみました。
| エンドポイント | メソッド | 処理内容 | テスト対象 |
|---|---|---|---|
/research/simple-loop |
GET | 単純なループによる整数の累積加算 | 基本的なJVMの最適化効果 |
/research/complex-math |
GET | 三角関数、平方根、対数など複雑な数学演算の繰り返し | 数学ライブラリの最適化効果 |
/research/stream-processing |
GET | Stream APIを使用したデータの生成、フィルタリング、グループ化 | 関数型プログラミングパターンの最適化 |
/research/json-processing |
POST | Jackson ObjectMapperによるJSON変換を1000回繰り返し | リフレクション・シリアライゼーションの最適化 |
/business/complex-analytics |
POST | リフレクション、正規表現、BigDecimal計算、JSON変換、JPA操作の複合処理 | 複合的な実務処理の最適化 |
/business/framework-heavy |
GET | Spring Bean取得、Hibernateクエリ風処理、Stream集計 | フレームワーク依存処理の最適化 |
コード抜粋
// 単純なループ処理
@GetMapping("/simple-loop")
public Map<String, Object> simpleLoop(@RequestParam(defaultValue = "100000") int count) {
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
long duration = System.nanoTime() - start;
return Map.of("result", sum, "duration_ns", duration);
}
// 複雑な数学演算
@GetMapping("/complex-math")
public Map<String, Object> complexMath(@RequestParam(defaultValue = "50000") int count) {
long start = System.nanoTime();
double result = 0;
for (int i = 1; i <= count; i++) {
result += Math.sqrt(i) * Math.sin(i) + Math.cos(i) / Math.log(i);
}
long duration = System.nanoTime() - start;
return Map.of("result", result, "duration_ns", duration);
}
// Stream API + 集約処理
@GetMapping("/stream-processing")
public Map<String, Object> streamProcessing(@RequestParam(defaultValue = "10000") int count) {
long start = System.nanoTime();
List<String> data = IntStream.range(0, count)
.mapToObj(i -> "user-" + i + "@example.com")
.collect(Collectors.toList());
Map<String, List<String>> result = data.stream()
.filter(email -> email.contains("@"))
.collect(Collectors.groupingBy(
email -> email.substring(email.lastIndexOf(".") + 1),
Collectors.mapping(
email -> email.substring(0, email.indexOf("@")),
Collectors.toList()
)
));
long duration = System.nanoTime() - start;
return Map.of("groups", result.size(), "total_processed", count, "duration_ns", duration);
}
// JSON処理
@PostMapping("/json-processing")
public Map<String, Object> jsonProcessing(@RequestBody Map<String, Object> input) {
long start = System.nanoTime();
ObjectMapper mapper = new ObjectMapper();
try {
String jsonString = mapper.writeValueAsString(input);
for (int i = 0; i < 1000; i++) {
@SuppressWarnings("unchecked")
Map<String, Object> temp = mapper.readValue(jsonString, Map.class);
jsonString = mapper.writeValueAsString(temp);
}
@SuppressWarnings("unchecked")
Map<String, Object> finalResult = mapper.readValue(jsonString, Map.class);
long duration = System.nanoTime() - start;
return Map.of("original_keys", input.size(), "final_keys", finalResult.size(), "duration_ns", duration);
} catch (Exception e) {
return Map.of("error", e.getMessage());
}
}
// 複雑なビジネスロジック風
@PostMapping("/complex-analytics")
public Map<String, Object> complexAnalytics(@RequestBody Map<String, Object> inputData) {
long start = System.nanoTime();
// 1. 大量のクラス動的ロード(リフレクション)
List<Class<?>> loadedClasses = new ArrayList<>();
String[] classNames = {
"java.util.ArrayList", "java.util.HashMap", "java.util.TreeMap",
"java.util.LinkedList", "java.util.HashSet", "java.util.TreeSet",
"java.math.BigDecimal", "java.math.BigInteger", "java.lang.StringBuilder",
"java.text.SimpleDateFormat", "java.util.regex.Pattern", "java.util.concurrent.ConcurrentHashMap"
};
for (int i = 0; i < 100; i++) {
for (String className : classNames) {
try {
Class<?> clazz = Class.forName(className);
loadedClasses.add(clazz);
// メソッド情報も取得
Method[] methods = clazz.getDeclaredMethods();
} catch (ClassNotFoundException e) {
}
}
}
// 2. 正規表現処理
List<String> testData = IntStream.range(0, 10000)
.mapToObj(i -> String.format("user_%d@company_%d.example.com", i, i % 100))
.collect(Collectors.toList());
Pattern emailPattern = Pattern.compile("^[A-Za-z0-9+_.-]+@(.+)\\.[A-Za-z]{2,}$");
Pattern domainPattern = Pattern.compile("company_([0-9]+)\\.example\\.com");
Map<String, List<String>> processedData = testData.stream()
.filter(email -> emailPattern.matcher(email).matches())
.collect(Collectors.groupingBy(email -> {
var matcher = domainPattern.matcher(email);
return matcher.find() ? "company_" + matcher.group(1) : "unknown";
}));
// 3. 数値計算(BigDecimal使用)
Map<String, BigDecimal> calculations = new ConcurrentHashMap<>();
processedData.forEach((company, emails) -> {
BigDecimal sum = emails.stream()
.map(email -> new BigDecimal(email.hashCode()))
.reduce(BigDecimal.ZERO, BigDecimal::add);
BigDecimal result = sum
.multiply(new BigDecimal("1.08"))
.divide(new BigDecimal(emails.size()), 10, RoundingMode.HALF_UP)
.pow(2)
.sqrt(new java.math.MathContext(20));
calculations.put(company, result);
});
// 4. JSON変換とパース
ObjectMapper mapper = new ObjectMapper();
String jsonData = null;
Map<String, Object> parsedData = new HashMap<>();
try {
// 複雑なオブジェクト構造を作成
Map<String, Object> complexObject = new HashMap<>();
complexObject.put("timestamp", LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME));
complexObject.put("calculations", calculations);
complexObject.put("processedData", processedData);
complexObject.put("loadedClassCount", loadedClasses.size());
complexObject.put("inputData", inputData);
// JSON変換を繰り返し
for (int i = 0; i < 50; i++) {
jsonData = mapper.writeValueAsString(complexObject);
parsedData = mapper.readValue(jsonData, Map.class);
// さらにネストした変換
String nested = mapper.writeValueAsString(parsedData);
parsedData = mapper.readValue(nested, Map.class);
}
} catch (Exception e) {
parsedData.put("error", e.getMessage());
}
// 5. データベース操作
List<User> generatedUsers = new ArrayList<>();
for (int i = 0; i < 100; i++) {
User user = new User();
user.setName("Generated_" + i);
user.setEmail("generated" + i + "@test.com");
user.setCreatedAt(LocalDateTime.now());
try {
userRepository.save(user);
generatedUsers.add(user);
} catch (Exception e) {
// H2 in-memory database might have issues
}
}
// 6. ユーザー統計計算
Map<String, Object> userStats = new HashMap<>();
try {
Map<String, UserService.UserStatsDto> statsResult = userService.calculateUserStatistics();
userStats.put("statistics", statsResult);
} catch (Exception e) {
userStats.put("error", "Statistics calculation failed");
}
long duration = System.nanoTime() - start;
return Map.of(
"duration_ns", duration,
"processedCompanies", processedData.size(),
"totalCalculations", calculations.size(),
"loadedClasses", loadedClasses.size(),
"generatedUsers", generatedUsers.size(),
"jsonProcessingCompleted", parsedData != null,
"userStats", userStats,
"executionSummary", Map.of(
"classLoading", "Completed dynamic class loading",
"regexProcessing", "Processed " + testData.size() + " email addresses",
"bigDecimalCalculations", "Performed complex financial calculations",
"jsonSerialization", "Completed 50 rounds of JSON processing",
"databaseOperations", "Generated and saved user records",
"streamProcessing", "Executed complex user statistics"
)
);
}
// Springコンテキスト使用エンドポイント
@GetMapping("/framework-heavy")
public Map<String, Object> frameworkHeavy() {
long start = System.nanoTime();
// 1. Spring Context から Bean を取得
List<String> beanNames = new ArrayList<>();
String[] allBeanNames = applicationContext.getBeanDefinitionNames();
for (String beanName : allBeanNames) {
try {
Object bean = applicationContext.getBean(beanName);
beanNames.add(beanName + ":" + bean.getClass().getSimpleName());
} catch (Exception e) {
// Some beans might not be available
}
}
// 2. Hibernateクエリ風の複雑な処理
List<User> allUsers = userRepository.findAll();
Map<String, Object> complexQuery = allUsers.stream()
.collect(Collectors.groupingBy(
user -> user.getCreatedAt().toLocalDate().getMonth().toString(),
Collectors.collectingAndThen(
Collectors.toList(),
users -> Map.of(
"count", users.size(),
"avgEmailLength", users.stream()
.mapToInt(u -> u.getEmail().length())
.average().orElse(0),
"names", users.stream()
.map(User::getName)
.sorted()
.collect(Collectors.toList())
)
)
));
long duration = System.nanoTime() - start;
return Map.of(
"duration_ns", duration,
"discoveredBeans", beanNames.size(),
"beanSample", beanNames.subList(0, Math.min(10, beanNames.size())),
"userQueryResults", complexQuery,
"totalUsers", allUsers.size()
);
}
クライアントスクリプト
初めに手作業で数回測定してみると結構ばらつきがあり、キャッシュがない状態と変わらない、むしろ悪化するケースもありました。
回数を増やすためにエンドポイントに対してリクエストを投げるクライアントスクリプトを作成して、各エンドポイントの処理時間を測定してみました。
大まかにスクリプトは以下の処理を行います。
-
トレーニング実行
- プロファイル収集モードでSpring Bootアプリケーションを起動
- 各エンドポイントに対して50回ずつリクエストを送信してプロファイル情報を収集
- 収集したプロファイル情報を基にAOTキャッシュを生成
-
JVMの起動と待機
- キャッシュの有効と無効になったSpring Bootアプリケーションを起動
- ヘルスチェックエンドポイント(
/actuator/health)で起動完了を確認 - 15秒間のウォームアップ期間を設定
-
エンドポイントへのリクエスト
- 各エンドポイントに対して10回連続でリクエストを送信
- レスポンスから
duration_nsフィールドを抽出して処理時間を記録 - リクエストを送信したら測定クライアントプロセスを終了
-
分析
- 指定した回数テスト全体を繰り返し
- 各実行でキャッシュが有効な場合と無効な場合の両方を測定
- 改善率を計算
- 結果を可視化
実行
以下のクライアントスクリプトを実行します。
クライアントの起動停止をキャッシュ有無それぞれで10回繰り返し、1つのプロセスでエンドポイントに対して100回ずつリクエストを送信します。
uv run ./scripts/training_performance.py --requests-per-run 100
結果
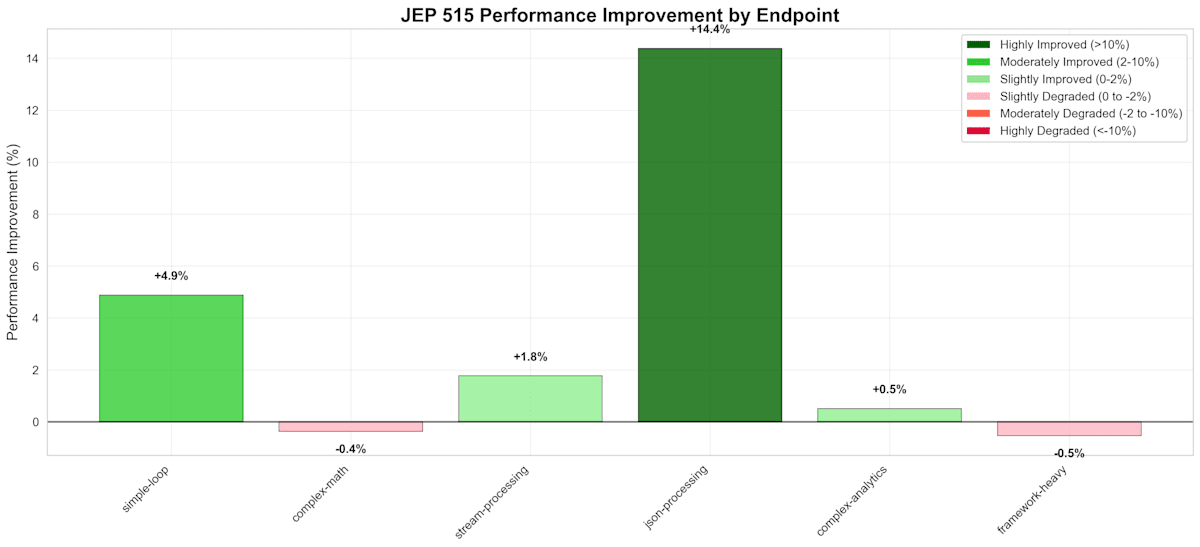
まとめると、JSON 処理で +14.4% と一番改善率が大きく、それ以外は -0.5% から +4.9% の性能差がありました。
とはいえばらつきもあり、誤差の範囲に入るものもあります。JSON 処理は文字列操作が多く、効果が出やすいのかもしれません。
一方で、ばらつきの度合い(Stability Change)は改善傾向にあるため、安定した性能が得られるようになる可能性があります。
もっとクラスロードが多いアプリケーションや動的な要素が多いアプリケーションでは効果があるかもしれません。
以下は結果です。
結果の詳細
================================================================================
JEP 515 PERFORMANCE ANALYSIS REPORT
================================================================================
Generated: 2025-09-20 11:00:06
Test Configuration: 10 process runs × 100 requests
AOT Cache Size: 117.6 MB
SUMMARY STATISTICS:
----------------------------------------
Total Endpoints Tested: 6
Improved Endpoints: 4
Degraded Endpoints: 2
Overall Average Improvement: +3.4%
DETAILED RESULTS:
----------------------------------------
Endpoint: simple-loop?count=1000000
Traditional JVM: 0.3ms ± 0.3ms
JEP 515: 0.3ms ± 0.1ms
Improvement: +4.9%
Stability Change: +59.4%
Endpoint: complex-math?count=1000000
Traditional JVM: 11.1ms ± 0.4ms
JEP 515: 11.2ms ± 0.3ms
Improvement: -0.4%
Stability Change: +21.0%
Endpoint: stream-processing?count=1000000
Traditional JVM: 50.0ms ± 28.5ms
JEP 515: 49.2ms ± 27.6ms
Improvement: +1.8%
Stability Change: +1.4%
Endpoint: json-processing
Traditional JVM: 1.5ms ± 3.2ms
JEP 515: 1.3ms ± 2.9ms
Improvement: +14.4%
Stability Change: -6.4%
Endpoint: complex-analytics
Traditional JVM: 70.7ms ± 19.9ms
JEP 515: 70.4ms ± 15.0ms
Improvement: +0.5%
Stability Change: +24.4%
Endpoint: framework-heavy
Traditional JVM: 4.7ms ± 1.1ms
JEP 515: 4.7ms ± 1.0ms
Improvement: -0.5%
Stability Change: +4.5%
以下はグラフで可視化したものです。
まとめ
事前にプロファイル情報を収集し、AOT キャッシュを生成することで、JVM の起動時間が改善されることが確認できました。
一方で事前に収集したプロファイル情報に基づいて最適化が行われるため、アプリケーションの特性や使用パターンによっては限定的な効果や効果があまり発揮できないパターンがありそうです。
特にバッチ処理や起動し続けているサーバーアプリケーションでは効果が薄い可能性があります。
コード変更なく処理速度を改善できる点は魅力的なので機会があれば実戦でも試してみたいと思います。
参考
AOT キャッシュの歴史が紹介されています。
AOTCacheOutput オプションを使うとトレーニング実行とキャッシュの生成が同時にできます。

楽天のエンジニアによる技術ブログです。このブログは公式ブログではなく有志で運営しています。 記事の内容は個人の見解であり、所属する企業や組織の立場、戦略、意見を代表するものではありません。
Discussion