今更だけど...AWS DeepRacer@社内コンペで優勝した!




はじめに
Zenn初投稿になります、SNGと申します。普段は輸送機械の車体制御~LLMを活用したアプリケーション領域(RAG,AIエージェント等)までマルチに従事しています!東大松尾研講座にも毎年参加しています。
その他、車系ブログも運営してます(笑)、よろしくお願いいたします。
さて、少し前に流行ったのか。。AWS DeepRacerを最近時勉強もかねて始め社内のコンペに出てみたところ想定外に優勝してしまいました。その技術トピックの話をしていきます。
AWS DeepRacerとは?
👇開発中のWeb検索エージェントで作成
ASW DeepRacerは、Amazon Web Services(AWS)が提供する実験プラットフォームです。ユーザーはこの小型レーシングカーを使って、強化学習(Reinforcement Learning、RL)のアルゴリズムを実際のレースで試すことができます。実際のレーシングカーではなく、シミュレーション環境や物理的なモデルカーで学ぶため、初心者から上級者まで気軽にチャレンジできます。
→正しい内容ですね。公式リンクはこちら。
実際のコンペでは、シミュレーション上で学習したモデルを実機にフラッシュし、走行させてタイムトライアル形式で競います。研修的な要素も含んでおり、機械学習だけでなくクラウドの使い方や実世界での動きまで短時間で勉強できるところが良いですね。
ちなみに。。、実機はラズベリーパイで動いており、後輪駆動でした。ダイナミクス的観点だと、リアをあえて滑らせアクセルを全開にさせるようなラリー走法もアリだなと感じました。
強化学習とは?
強化学習とは、試行錯誤を通じて「報酬を最大化するような行動」を学習するものです。赤ちゃんが転びながら少しづつ立つのを学んでいくのと似ていますね。人間の経験的に基づく行動の学習は強化学習に近いしいかもしれません。DeepRacerでは、この報酬をどう与えるか?を設計します。
実際にモデルを作る
ベストプラクティスを参考にする
いまや生成AIやLLM、エージェントの時代!真似てなんぼ!の時代です。
ネット上で、たくさん落ちています。
# パラメータ
speed = params['speed']
closest_waypoints = params['closest_waypoints'] # 車の現在地点から次に最も近い waypoint、前に最も近い waypoint
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
# カーブを曲がるために必要なステアリング角度に基づいて報酬を決定する
# 次の waypoint への方向を計算
track_direction = math.atan2(next_point[1] - prev_point[1],next_point[0] - prev_point[0]) # 値はラジアンで返す
track_direction = math.degrees(track_direction) # 角度で返すように変更
# 進行方向とトラック方向の差を計算
direction_diff = abs(track_direction - heading)
# カーブと直線では適正速度が異なる
if speed > 3.0:
reward += 10.0 # 直線では加速
elif (speed < 3.0) and (30 <= direction_diff):
reward += 5.0 # 曲線では多少減速
例えば、上記です。これは直線では速く走り、コーナーでは減速させる報酬です。
なんとなくこれを工夫していくのが結構よさそうです。
ベストプラクティスの問題点
上記のようなコードを作りこむほどに問題点が出てきました。
1. 実走行でまったく完走できない
シミュレーション上でタイムは速くても完走が全くできないモデルが出来上がってしまいました。
この原因として考えられるのは、実機のカメラのセンシングが光の影響や明暗で正しくできていないことが考えられます。

特に、上記コードのWaypointがコース上のオレンジの点にあたるのですが、カメラのセンシングを一度でも外すと次のウェイポイントの場所がわからなくなり、コースアウトしてしまうという挙動がみられました。
2. 過学習が起きやすい
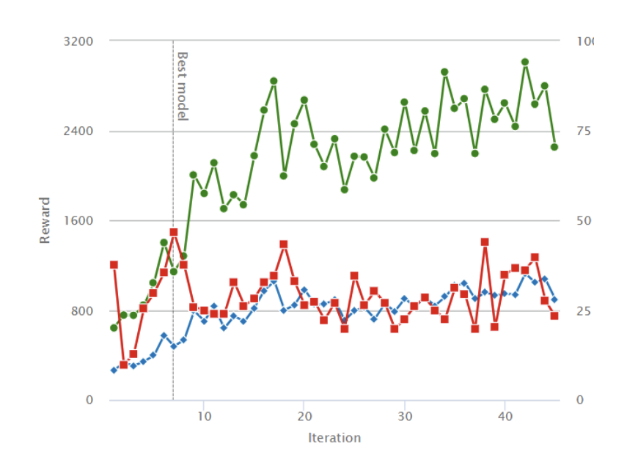
私がテストしていた中ではWaypointの報酬を与えると、過学習が起きやすいという結果が得られました。下記は特に良くなかった報酬の推移ですが、緑線がトレーニングの報酬の推移で、赤線がテストデータに該当します。緑線は学習が進むにつれ向上しますが、赤線はあまり向上していません。いろいろ原因はあると思いますが、報酬設計が複雑すぎると、エージェントが最適な行動をとれない可能性もでてきます。
報酬設計の見直し
実走行でのベストプラクティスの問題点から、報酬設計を見直しました。
報酬設計の見直し観点として、
- コースから車体が出ない
- できる限り速く走る
を前提に、
トレーニングで過学習を起こさずにテストデータでの結果をよくする報酬関数にするという観点を追加しました。
その結果、100行くらいあった報酬関数を徹底的に削除し、報酬設計のコードはたった6行になりました。
学習結果
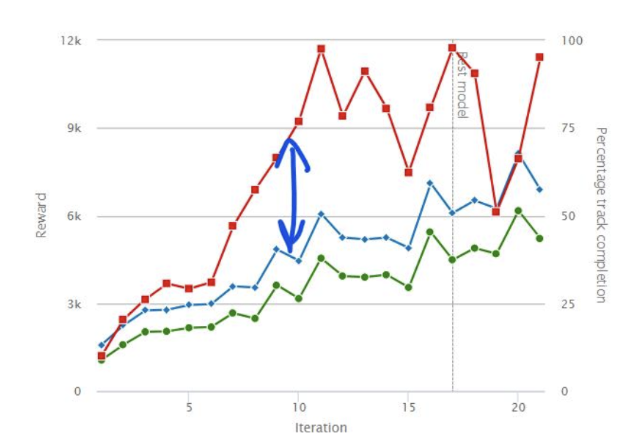
テストデータの結果が良くなるように、設計していったところ。。、
なんとトレーニングの結果よりもテストの結果のほうが圧倒的に優れたモデルが誕生しました!
※報酬関数は規約で公開できないため非公開
肝心のタイムは。。
今回はAtoZですが、最高タイムとしては6.986secをたたき出しました。(※走行環境によってかなり影響するので、必ずしもこのタイムが毎回出るとは限りません)ちなみに、シミュレーション上での最高タイムは8.2sec程度だったため、実世界の方が圧倒的に早かったです。実走行での完走率も70%程度と高いロバスト性を有すことができました。今回記事としては、載せられるようなものではないですが。。、Waypointを排した報酬での学習をすると、コースのラインの自由度が高くなるように学習が進行していることがわかりました。結果的に、コースではみ出そうになってもコースアウトしないようなモデルになったと考察されます。
まとめ
DeepRacerを通して、下記が学べました!
1. 実世界とシミュレーターでの剥離
2. ロバスト性の高いモデルの構築方針
などなど。非常に良い経験になりました。AWS DeepRacerの正式な大会は昨年までだったようですが、今後もこういったサービスはぜひ継続してほしいですね。
では!
#機械学習 #AI #AWS #deepracer
Discussion