LangGraph-supervisorで自作マルチAIエージェントを作る!
はじめに
昨今マルチAIエージェントって多様なサービスが出てきていますよね、どれも非常に魅力的です。一方で、パブリックなサービスはプライベートな企業向けサービスとしてはセキュリティや様々な社内問題があり導入できないことがほとんどで、社内向けに特化したマルチAIエージェントの開発は今だからこそ求められているように感じます。また、最近の様々なITベンダーのサービスを見ていくとアセット売り(※いわゆるすでにエージェントが組まれた既製品を販売)が多いですが、変化の多いAI業界で一度アセット導入をしてしまうと堅牢なはずがすぐに古くなってしまい、結局アップデートが定期的に必要になり維持費増につながりやすい等が懸念されます。そこで、自作するメリットがでてくるのでは?と私は感じています。今回の記事では実際に自作してみてどうだったか?という内容を報告していきます。
環境
python3.11 + 仮想環境(env)
メインライブラリ:LangGraoh-supervisor←LangGraphでは最新のライブラリ
使用LLM:GPT4.1 ※コンテキストウィンドウが大きいため利用
スーパーバイザー型のマルチAIエージェント
一般的にマルチAIエージェントは、スーパーバイザー型と協調型の2つに分類されますが、今回は最もベストプラクティスの多いスーパーバイザー型を対象とします。
ちなみにですが。。、スーパーバイザー型のベストプラクティスの多い理由は、各AIエージェントの制御のしやすさ、に起因していると思っています。経験的には、LLMでAIエージェントを振り分ける=つまり"分類器"として制御させるのってあんまり向いてないんじゃないのかな~と感じてます。
マルチAIエージェントのワークフロー
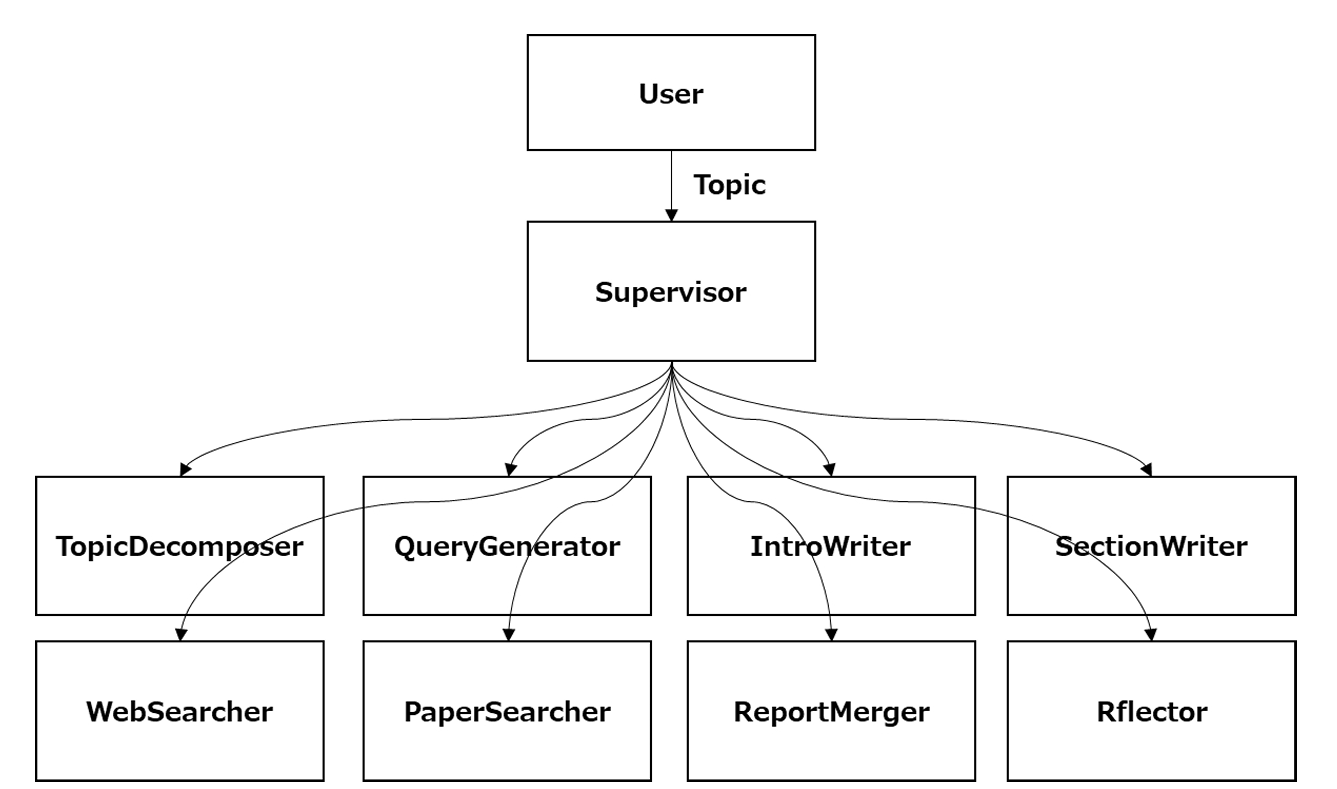
調査型のマルチAIエージェントを今回は作成します。調査対象は、ジェネラルなWeb情報と論文です。トピックに応じて、Web情報だけでなく論文も検索してもらいます。したがって、いわゆるDeep research的なワークフローでテストしていきます。Supervisorが各①~⑧を制御します。今回はワークフローに従う形で動かしました。
⓪Supervisor:各エージェントをマネージするオーケストレーションの役割を担う
①TopicDisposer:ユーザーから与えられたトピックをサブトピックに分解しプランニングを行う
②QueryGenerator:分解されたサブトピックから検索クエリーを生成する
③WebSearcher:検索クエリーを元に一般的な情報をWebを検索する
④PaperSearcher:技術的内容の場合に検索クエリーを元に論文も検索する
⑤IntroWriter:レポートのイントロダクションを書く
⑥SctionWriter:各セクションを書く
⑦ReportMerger:レポートをマージする
⑧Reflector:レポートのフォーマットや情報に過不足がないかをチェックする
実装
ライブラリのインポート。今回はバッグエンドはすべてLangChainで組みます。
コードは非常に長いため、一部抜粋となります。
import os
from langchain_openai import AzureChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor
from langchain_core.runnables.config import RunnableConfig
from duckduckgo_search import DDGS
import json
import streamlit as st
import arxiv
import time
from datetime import datetime
from prompts import (
report_planner_query_writer_instructions,
report_planner_instructions,
query_writer_instructions,
section_writer_instructions,
final_section_writer_instructions,
section_grader_instructions,
section_writer_inputs
)
レポートのフォーマットを指定します。
こちらは、Langchain open deep researchのベストプラクティスを活用します。
format = """
# Report Format
1.Introduction
- A brief overview of the topic area
2.Main Body Sections
- Each section focuses on a subtopic provided by the user
3.Conclusion
- One structural element (list or table) to summarize the main body
- A concise summary of the report
"""
Web検索のAPIはDuckDuckgoを利用します。下記のように設定します。
LangGraph-supervisorの面白いところは、ドキュメンテーション文字列を書かないとマルチAIエージェントのToolとして認識されない点でした(笑)
# Web検索
def web_search(query):
"""Search the web for information for all queries."""
time.sleep(2.0) # 2秒待機
# クエリ
with DDGS() as ddgs:
results = list(ddgs.text(
keywords=query, # 検索ワード
region='wt-wt', # リージョン 日本は"jp-jp",指定なしの場合は"wt-wt"
safesearch='off', # セーフサーチOFF->"off",ON->"on",標準->"moderate"
timelimit=None, # 期間指定 指定なし->None,過去1日->"d",過去1週間->"w",
# 過去1か月->"m",過去1年->"y"
max_results=5 # 取得件数
))
# レスポンスの表示
for line in results:
# "title"キーの値を抽出して表示
if "title" in line:
print(line["title"])
return str(results), "検索結果"
各エージェントは下記のように設定します。例えば、Web検索エージェントには、Toolとして上記のWeb検索をToolとして登録します。こちらのプロンプト設定も、Langchain open deep researchのベストプラクティスを活用しました。LangGraph-supervisorのリポジトリのプロンプトは意図した動きになりませんでした。
# Web検索エージェント
web_search_agent = create_react_agent(
model=llm,
tools=[web_search],
name="WebResearcher",
prompt="""You are a general web researcher with access to web search.
<Report topic>
{topic}
</Report topic>
<Report organization>
{report_organization}
</Report organization>
<Task>
Your goal is to search the web for all queries.
</Task>
"""
)
Supervisorに各エージェントをToolとして登録し、LangGraphお決まりのグラフをコンパイルします。
# Supervisorの作成
m_agents = create_supervisor(
[web_search_agent,
planning_agent,
Introduction_writer_agent,
section_writer_agent,
marge_writer_agent,
query_generation_agent,
report_check_agent,
research_paper_search_agent,
reflector_agent],
model=llm,
prompt=system_prompt
)
# グラフのコンパイル
app = m_agents.compile()
上記で実装はほぼ完了です。グラフコンパイル後はいわゆるLangGraphと同じ動かし方をさせることでアプリケーションとして動作します。
簡単なUIの用意
①シンプルなチャット画面

②実行中はどのエージェントが動いてるかを表示

トピックによっては5~分程度かかるので、簡単なUIで表示できるように遊びました。。
実行結果
実行中
ユーザーが与えたトピック:”Deepseekの技術一覧”
👇Web検索中

👇論文検索中

→自律的な検索が行われいいかんじです👍
レポート生成結果

→Deepseekの技術を深堀して調査レポートとして整理してくれています。
検証してわかったこと
ツールへ登録する各エージェントの名前は超重要
コードを書いて実行しているときに各エージェントの前の付け方が適当だと、スーパーバイザーが正しく呼べなかったりすることがありました。シンプルでわかりやすい名前にすると適切にスーパーバイザーが呼び出せました。
o系をスーパーバイザーに設定するとWeb検索をしない事態発生
OpenAI社のo系のリーズニングモデルのほうがエージェントの仕組みとして有用に働くと想定していましたが、o3-mini等はWeb検索等を行わず自らの知識を使用する傾向にありました。
検索したWeb情報の日付を変えてしまう時がある
検索した情報ページの日付が2025.4.7の場合に、2024.4.7とレポートの日付を間違えてしまう時もありました。同様に検索クエリーを生成する場合にも、2024年トいうキーワードを入れてしまう時があります。GPT4.1はモデル自身が学習データに起因して2024年であると思い込んでいるようでした。実用上はこういったハルシネーションへの対策は結構大事ですね。
検証してわからなかったこと
スーパーバイザー+サブスーパーバイザーの動作
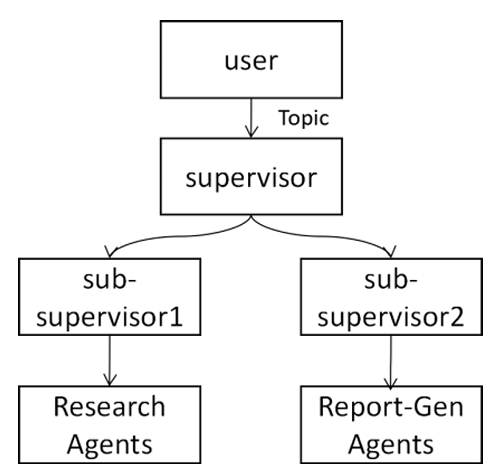
なんとなくよさそうだと思った上記のアーキテクチャとして、サブのスーパーバイザーを下流にも設け、トップレベルスーパーバイザーが各エージェントに口出しをしない(=ワークフローの順を変えたりさせない等)ようなアーキテクチャでも検証を実施しましたが、そのままだとうまく動作しませんでした。プロンプトのチューニングやAIエージェントに与えるタスクの分解の粒度がかなり重要そうです。
まとめ
今回自作のマルチAIエージェントを作成しました。
ビッグテック系だけでなくOSSのフレームワークも充実し随分と簡単に開発ができるようになったのは非常に良いことですし、社内RAG等を繋いだり&Toolとして社内専用アプリを登録していくと一気に用途の幅が広がりそうです。
一方で、あくまでプロンプティングによる指示のためか、結構指示通りに従わない箇所も散見されたので、LLMのプロンプティングによる制御も現実解として見えてきたのかな、という印象も返って受けました。今後のLLM、生成AI分野の動向にも注目です。
Discussion