kiroがまだ使えない😭ので自作した!コード生成する #2
はじめに
kiroがまだ”正式に”使えないので自作しましたシリーズ第2段です。今回は非常に長文記事です🙇
👇前回の記事はこちらです。
今回は実際にコード生成まで行い、実際の使い勝手を検討してみました。
P.S "正式"にと記載したのは、Waiting list待ちであるものの、HPのリンクからさかのぼればダウンロードはできるらしいです。。マジか(笑)
前回の振り返り
私が開発している自作Kiroは実際のKiroとは少々異なり、ユーザーに課題を聞くためのヒアリング議事録をインプットとしています。そのため下記のフローをまず通します。
全体アーキテクチャ概要
追加したワークフロー
もはやKiroとだいぶ違うものになっているかもしれません(笑)が、タスクに対し、1つ1つコードを生成し、LLMによる静的解析→人間が承認したら次のタスクへ。。という形で進む仕様です。正直タスクが多い場合はやや承認がだるいので、少々改善の余地ありですがこのままいきます。
コード抜粋
超MVPなので全然きれいにかけてません(笑)が、追加点は主に4点です。主にタスクを管理するエージェント、コードを生成するエージェント、コードを静的評価するエージェント、テストコード生成するエージェント、を追加しています。また長いので既存のもの以外は省略しています、差分のみ表示。
# MAXループ設定
max_loop = RunnableConfig(recursion_limit=100) # デフォルト25から拡張
# llmインスタンスの呼び出し
llm = llm
reasoning_llm = reasoning_llm
###########################################################################
# ヘルパー関数
###########################################################################
# 既存のものは省略
# プロジェクト名を生成
def generate_project_name(prompt: str) -> str:
"""プロンプトからプロジェクト名を生成"""
# プロンプトの最初の20文字程度を使用
base_name = prompt[:20].strip()
# 特殊文字を除去し、スペースをアンダースコアに変換
safe_name = "".join(c for c in base_name if c.isalnum() or c in (' ', '-', '_'))
safe_name = safe_name.replace(' ', '_').replace('-', '_')
# 日時を追加してユニークにする
from datetime import datetime
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
return f"{safe_name}_{timestamp}"
# プロジェクトベースで成果物を保存
def save_project_artifact(kind: str, content: str, project_name: str, outdir: Path = Path("projects")):
"""プロジェクトごとに成果物を保存"""
project_dir = outdir / project_name
project_dir.mkdir(parents=True, exist_ok=True)
fname = f"{kind}.md"
(project_dir / fname).write_text(content, encoding="utf-8")
print(f"📄 Saved: {project_dir / fname}")
# 後方互換性のため
def save_step_markdown(kind: str, content: str, outdir: Path = Path("output")):
"""成果物をステップごとにMarkdown保存(追記形式も可)"""
outdir.mkdir(exist_ok=True)
fname = f"{kind}.md"
(outdir / fname).write_text(content, encoding="utf-8")
# 生成されたコードをプロジェクト内に保存
def save_generated_code_files(code_content: str, task_title: str, task_index: int, project_name: str, outdir: Path = Path("projects")):
"""生成されたコードをプロジェクト内に保存"""
project_dir = outdir / project_name / "code"
project_dir.mkdir(parents=True, exist_ok=True)
# コード内容を解析してファイル構造を抽出
files_to_save = parse_code_content(code_content, task_title, task_index)
# ファイルを保存
saved_files = []
for filename, content in files_to_save:
# ディレクトリ構造を作成
file_path = project_dir / filename
file_path.parent.mkdir(parents=True, exist_ok=True)
# ファイルを保存
file_path.write_text(content, encoding='utf-8')
saved_files.append(str(file_path))
print(f"📁 Saved: {file_path}")
# 保存されたファイル一覧を記録
summary_file = project_dir / f"task_{task_index}_files.txt"
summary_content = f"Task: {task_title}\nGenerated Files:\n" + "\n".join(f"- {f}" for f in saved_files)
summary_file.write_text(summary_content, encoding='utf-8')
return saved_files
def parse_code_content(code_content: str, task_title: str, task_index: int):
"""コード内容を解析してファイル構造を抽出"""
lines = code_content.split('\n')
files_to_save = []
# パターン1: "1) filename.ext" のような形式
current_file = None
current_content = []
in_code_block = False
code_block_lang = None
for i, line in enumerate(lines):
stripped_line = line.strip()
# ファイル名のパターンを検出(数字) ファイル名.拡張子)
if (stripped_line.startswith(('1)', '2)', '3)', '4)', '5)', '6)', '7)', '8)', '9)', '10)', '11)', '12)')) and
any(ext in stripped_line for ext in ['.py', '.md', '.txt', '.env', '.json', '.js', '.ts', '.html', '.css'])):
# 前のファイルがあれば保存
if current_file and current_content:
files_to_save.append((current_file, '\n'.join(current_content)))
# 新しいファイルを開始
current_file = stripped_line.split(') ', 1)[1] if ') ' in stripped_line else stripped_line
current_content = []
in_code_block = False
code_block_lang = None
# パターン2: "```" で囲まれたコードブロック
elif line.startswith('```'):
if in_code_block:
# コードブロック終了
in_code_block = False
if current_file and current_content:
files_to_save.append((current_file, '\n'.join(current_content)))
current_file = None
current_content = []
code_block_lang = None
else:
# コードブロック開始
in_code_block = True
# 言語指定を取得
lang_part = line[3:].strip()
if lang_part:
code_block_lang = lang_part
# 次の行がファイル名の可能性
if i + 1 < len(lines) and lines[i + 1].strip():
potential_filename = lines[i + 1].strip()
if any(ext in potential_filename for ext in ['.py', '.md', '.txt', '.env', '.json', '.js', '.ts', '.html', '.css']):
current_file = potential_filename
current_content = []
# パターン3: Directory structure セクション
elif ("Directory structure" in line or
("```" in line and ("├──" in line or "│" in line)) or
"This delivers:" in line or
"AI Review:" in line):
# ディレクトリ構造や説明をスキップ
continue
# ファイル内容を追加
elif current_file and not line.startswith('```'):
current_content.append(line)
# 最後のファイルを保存
if current_file and current_content:
files_to_save.append((current_file, '\n'.join(current_content)))
# ファイル構造が見つからない場合、全体を一つのファイルとして保存
if not files_to_save:
# タスク名からファイル名を生成
safe_task_name = "".join(c for c in task_title if c.isalnum() or c in (' ', '-', '_')).rstrip()
safe_task_name = safe_task_name.replace(' ', '_')
filename = f"task_{task_index}_{safe_task_name}.py"
files_to_save.append((filename, code_content))
return files_to_save
# ステート定義
class DevState(TypedDict, total=False):
prompt: str
project_name: str
project_desc: str
spec: str
design: str
tasks: List[Dict]
code_diff: str
test_report: str
event: str
tech_constraints: str
generated_code: str
code_review: str
test_code: str
current_task_index: int
#######################################################################
# ドキュメント生成
#######################################################################
# コードを実装するエージェント
def generate_code(state: DevState) -> DevState:
"""設計ドキュメントとタスクからコードを生成"""
if "current_task_index" not in state:
state["current_task_index"] = 0
if state["current_task_index"] >= len(state["tasks"]):
return state
current_task = state["tasks"][state["current_task_index"]]
if current_task["done"]:
state["current_task_index"] += 1
return generate_code(state)
prompt = INSTRUCTION_FOR_CODE_AGENT.format(
design=state['design'],
task=current_task['title'],
tech_constraints=state.get('tech_constraints', '')
)
resp = reasoning_llm.invoke(prompt)
state["generated_code"] = msg_text(resp)
# コードをファイルに保存
save_project_artifact(f"code_task_{state['current_task_index']}",
f"# Generated Code for Task: {current_task['title']}\n\n```\n{state['generated_code']}\n```",
state['project_name'])
# コードを実際のファイルとして保存
save_generated_code_files(state["generated_code"], current_task['title'], state["current_task_index"], state['project_name'])
return state
# コードレビューを実行するエージェント
def review_code(state: DevState) -> DevState:
"""生成されたコードをレビュー"""
if "generated_code" not in state:
return state
current_task = state["tasks"][state["current_task_index"]]
prompt = INSTRUCTION_FOR_CODE_REVIEW_AGENT.format(
code=state['generated_code'],
design=state['design'],
task=current_task['title']
)
resp = reasoning_llm.invoke(prompt)
state["code_review"] = msg_text(resp)
# レビュー結果をファイルに保存
save_project_artifact(f"code_review_task_{state['current_task_index']}",
f"# Code Review for Task: {current_task['title']}\n\n{state['code_review']}",
state['project_name'])
return state
# テストコードを生成するエージェント
def generate_tests(state: DevState) -> DevState:
"""生成されたコードのテストを生成"""
if "generated_code" not in state:
return state
current_task = state["tasks"][state["current_task_index"]]
prompt = INSTRUCTION_FOR_TEST_AGENT.format(
code=state['generated_code'],
design=state['design'],
task=current_task['title']
)
resp = reasoning_llm.invoke(prompt)
state["test_code"] = msg_text(resp)
# テストコードをファイルに保存
save_project_artifact(f"test_code_task_{state['current_task_index']}",
f"# Test Code for Task: {current_task['title']}\n\n```\n{state['test_code']}\n```",
state['project_name'])
return state
# タスク完了をマークするエージェント
def complete_task(state: DevState) -> DevState:
"""現在のタスクを完了としてマーク"""
if "current_task_index" in state and state["current_task_index"] < len(state["tasks"]):
current_task = state["tasks"][state["current_task_index"]]
current_task["done"] = True
state["current_task_index"] += 1
# 進捗を表示
completed = sum(1 for task in state["tasks"] if task["done"])
total = len(state["tasks"])
print(f"\n🎉 Task completed! Progress: {completed}/{total}")
# 完了したタスクをファイルに保存
save_project_artifact("completed_tasks",
f"# Completed Tasks\n\n" +
"\n".join([f"- {task['title']} {'✅' if task['done'] else '⏳'}"
for task in state["tasks"]]),
state['project_name'])
# 全タスク完了時にプロジェクト構造を保存
if completed == total:
save_project_structure(state)
return state
def save_project_structure(state: DevState):
"""プロジェクト全体の構造を保存"""
outdir = Path("projects") / state['project_name']
project_file = outdir / "PROJECT_STRUCTURE.md"
structure_content = f"""# プロジェクト構造
## プロジェクト概要
{state.get('project_desc', 'N/A')}
## 要件仕様
{state.get('spec', 'N/A')}
## 設計ドキュメント
{state.get('design', 'N/A')}
## 実装タスク
{chr(10).join([f"- {task['title']} {'✅' if task['done'] else '⏳'}" for task in state.get('tasks', [])])}
## 生成されたファイル
このディレクトリには以下のファイルが生成されています:
"""
# 生成されたファイル一覧を取得
if outdir.exists():
for file_path in outdir.rglob("*"):
if file_path.is_file() and file_path.name != "PROJECT_STRUCTURE.md":
relative_path = file_path.relative_to(outdir)
structure_content += f"- {relative_path}\n"
project_file.write_text(structure_content, encoding='utf-8')
print(f"📋 Project structure saved: {project_file}")
# プロジェクト情報ファイルも作成
project_info_file = outdir / "PROJECT_INFO.md"
info_content = f"""# プロジェクト情報
## プロジェクト名
{state['project_name']}
## 作成日時
{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
## プロンプト
{state.get('prompt', 'N/A')}
## 進捗状況
- プロジェクト説明: ✅
- 要件定義: ✅
- 設計: ✅
- タスク計画: ✅
- コード生成: {'✅' if state.get('current_task_index', 0) >= len(state.get('tasks', [])) else '⏳'}
- テスト生成: {'✅' if state.get('current_task_index', 0) >= len(state.get('tasks', [])) else '⏳'}
## ディレクトリ構造
{state['project_name']}/
├── PROJECT_INFO.md # このファイル
├── PROJECT_STRUCTURE.md # プロジェクト構造
├── project_description.md # プロジェクト説明
├── requirements.md # 要件定義
├── design.md # 設計ドキュメント
├── tasks.md # タスク一覧
├── completed_tasks.md # 完了タスク
└── code/ # 生成されたコード
├── task_0_files.txt
├── task_1_files.txt
└── ...
"""
project_info_file.write_text(info_content, encoding='utf-8')
print(f"📋 Project info saved: {project_info_file}")
#######################################################################
# ヒューマンフィードバック
#######################################################################
def task_review(state: DevState):
# タスク一覧レビュー(編集/承認の都度呼び出しされる想定)
view = "\n".join(f"- {t['title']}" for t in state["tasks"])
action, instr = _approve_dialog("TASK LIST REVIEW", view)
if action == "approve":
save_project_artifact("tasks", f"# Tasks\n\n{view}", state['project_name'])
state.pop("redo", None)
return state
rewritten = llm.invoke(
f"""
Rewrite the task list per instruction (one task per line).
# design
{state['view']}
# Instruction
{instr}
# Guidelines
- Provide only the revised design document.
- Do not include any unnecessary information.
- Display the entire revised all task **without omission**.
"""
)
state["tasks"] = [{"title": l.strip(), "done": False}
for l in msg_text(rewritten).splitlines() if l.strip()]
save_project_artifact("tasks", "# Tasks\n\n" + "\n".join(f"- {t['title']}" for t in state["tasks"]), state['project_name'])
state["redo"] = True
return state
# コードレビュー(ヒューマンフィードバック)
def code_review_human(state: DevState):
"""生成されたコードのヒューマンレビュー"""
if "generated_code" not in state:
return state
current_task = state["tasks"][state["current_task_index"]]
review_content = f"Task: {current_task['title']}\n\nGenerated Code:\n{state['generated_code']}\n\nAI Review:\n{state.get('code_review', 'No AI review available')}"
while True:
action, instr = _approve_dialog("CODE REVIEW", review_content)
if action == "approve":
return state
if any(w in instr for w in ["再実装", "作り直し", "regenerate"]):
# コードを再生成
return "regenerate_code"
# コードを改善
state["generated_code"] = msg_text(llm.invoke(
f"Improve this code per instruction:\n\n{state['generated_code']}\n\nInstruction: {instr}"
))
# 改善されたコードをファイルに保存
save_project_artifact(f"code_task_{state['current_task_index']}_revised",
f"# Revised Code for Task: {current_task['title']}\n\n```\n{state['generated_code']}\n```",
state['project_name'])
# 修正されたコードを実際のファイルとして保存
save_generated_code_files(state["generated_code"], f"{current_task['title']}_revised", state["current_task_index"], state['project_name'])
review_content = f"Task: {current_task['title']}\n\nRevised Code:\n{state['generated_code']}"
#######################################################
# グラフの定義
#######################################################
def build_graph() -> StateGraph:
kiro = StateGraph(DevState)
# 各ノードを追加
kiro.add_node("proj_desc", describe_project) # プロジェクト説明自動生成
kiro.add_node("proj_desc_rev", proj_desc_review) # プロジェクト説明レビュー
kiro.add_node("spec", expand_spec) # 要件定義自動生成
kiro.add_node("spec_rev", spec_review) # 要件定義レビュー
kiro.add_node("design", generate_design) # 設計自動生成
kiro.add_node("design_rev", design_review) # 設計レビュー
kiro.add_node("tasks", plan_tasks) # タスク自動生成
kiro.add_node("task_rev", task_review) # タスクリストレビュー
# コード生成関連のノード
kiro.add_node("generate_code", generate_code) # コード生成
kiro.add_node("review_code", review_code) # AIコードレビュー
kiro.add_node("code_review_human", code_review_human) # ヒューマンコードレビュー
kiro.add_node("generate_tests", generate_tests) # テスト生成
kiro.add_node("complete_task", complete_task) # タスク完了
# ノード遷移を設定
kiro.add_edge(START, "proj_desc") # 開始→プロジェクト説明
kiro.add_edge("proj_desc", "proj_desc_rev") # 説明→レビュー
# 条件分岐(state["redo"]がTrueなら再レビュー、なければ次へ)
kiro.add_conditional_edges(
"proj_desc_rev",
lambda state: "redo" if state.get("redo") else "next",
{
"redo": "proj_desc_rev", # 再レビュー
"next": "spec", # 承認時のみ次へ
}
)
kiro.add_edge("spec", "spec_rev")
kiro.add_conditional_edges(
"spec_rev",
lambda state: "redo" if state.get("redo") else "next",
{
"redo": "spec_rev",
"next": "design",
}
)
kiro.add_edge("design", "design_rev")
kiro.add_conditional_edges(
"design_rev",
lambda state: "redo" if state.get("redo") else "next",
{
"redo": "design_rev",
"next": "tasks",
}
)
kiro.add_edge("tasks", "task_rev")
kiro.add_conditional_edges(
"task_rev",
lambda state: "redo" if state.get("redo") else ("skip_code" if state.get("skip_code") else "next"),
{
"redo": "task_rev",
"skip_code": END, # コード生成をスキップ
"next": "generate_code", # タスク承認後、コード生成開始
}
)
# コード生成フロー
kiro.add_edge("generate_code", "review_code") # コード生成→AIレビュー
kiro.add_edge("review_code", "code_review_human") # AIレビュー→ヒューマンレビュー
# ヒューマンレビューの条件分岐
kiro.add_conditional_edges(
"code_review_human",
lambda state: "regenerate_code" if state.get("event") == "regenerate_code" else "next",
{
"regenerate_code": "generate_code", # 再生成
"next": "generate_tests", # 承認時、テスト生成
}
)
kiro.add_edge("generate_tests", "complete_task") # テスト生成→タスク完了
# タスク完了後の条件分岐
kiro.add_conditional_edges(
"complete_task",
lambda state: "continue_coding" if state.get("current_task_index", 0) < len(state.get("tasks", [])) else "finish",
{
"continue_coding": "generate_code", # 次のタスクがある場合
"finish": END, # 全タスク完了
}
)
app = kiro.compile()
return app
# CLI
def main():
ap = argparse.ArgumentParser(description="LangGraph プロジェクト自動ワークフロー(要件定義・設計・コード生成)")
ap.add_argument("-p", "--prompt", help="ヒアリング内容(自然言語)")
ap.add_argument("--event", choices=["save", "commit"])
ap.add_argument("--skip-code", action="store_true", help="コード生成をスキップして要件定義・設計のみ実行")
args = ap.parse_args()
prompt = args.prompt or input("📝 ユーザーヒアリング議事録を入力してください: ").strip()
project_name = generate_project_name(prompt)
print(f"🚀 Starting project: {project_name}")
initial_state: DevState = {
"prompt": prompt,
"project_name": project_name,
"tech_constraints": load_tech_constraints(tech_const_path),
}
if args.event:
initial_state["event"] = args.event
if args.skip_code:
initial_state["skip_code"] = True
result = build_graph().invoke(initial_state,max_loop)
print(json.dumps(result, indent=2, ensure_ascii=False))
if __name__ == "__main__":
main()
実際の振る舞い
コードを実行すると、プロジェクトフォルダが生成され、その中にファイルがどんどん生成されていきます。

👇コードは下記に生成されます。

上記のように記載してみましたが、見にくいので下記に整理しました。
成果物と中間生成物
1. プロジェクト全体メタ情報
| ファイル/フォルダ | 生成タイミング | 内容・目的 |
|---|---|---|
PROJECT_INFO.md |
すべてのタスク完了時 | プロジェクト名・作成日時・元プロンプト・各フェーズの進捗状況・最終的なディレクトリ構造をまとめた “概要 README”。 |
PROJECT_STRUCTURE.md |
すべてのタスク完了時 | プロジェクトのアウトライン(説明 / 要件 / 設計 / タスク一覧 / 生成ファイル一覧)を一覧化。あとで “どこに何があるか” をひと目で確認できる。 |
2. ドキュメントフェーズの成果物
| ファイル | 生成タイミング | 内容 |
|---|---|---|
project_description.md |
describe_project 完了後 |
ユーザーヒアリングを要約したプロジェクト説明。(再レビューで上書きされる) |
requirements.md |
expand_spec 完了後 |
EARS 形式などで表した要件定義。技術制約もここに反映。 |
design.md |
generate_design 完了後 |
アーキテクチャ図の文章説明、モジュール設計、データフローなどを含む設計ドキュメント。 |
tasks.md |
plan_tasks 完了後 |
実装タスクリスト。1 行 1 タスクで列挙。 |
completed_tasks.md |
タスク完了ごとに更新 | 各タスクの進捗を ✅ / ⏳ で表示。 |

👉このようにタスクの進捗が確認できます。
3. 実装フェーズの成果物
| ファイル / フォルダ | 生成タイミング | 内容 |
|---|---|---|
code_task_<n>.md |
generate_code 実行直後 |
「Task: <タイトル>」見出し+コード全文を ``` で囲った記録用 Markdown。 |
code/ フォルダ |
generate_code 実行直後 |
生成コード本体。parse_code_content() が① コードブロックや番号付きリストからファイル名を抽出し ② そのままの階層で物理ファイルを書き出す。 |
code/task_<n>_files.txt |
同上 | 「どのタスクでどのファイルを生成したか」を一覧で記録。CI で “差分だけ” テストしたいときに便利。 |
code_task_<n>_revised.md |
人間レビューで「改善」指示時 | 改善後のコード全文を保存。合わせて code/ 内の実ファイルも上書き/追加。 |
4. レビューフェーズの成果物
| ファイル | 生成タイミング | 内容 |
|---|---|---|
code_review_task_<n>.md |
review_code 完了後 |
LLM による静的解析コメント、設計との整合性チェック、改善提案などを Markdown で保存。 |
5. テストフェーズの成果物
| ファイル/フォルダ | 生成タイミング | 内容 |
|---|---|---|
test_code_task_<n>.md |
generate_tests 実行直後 |
タスク用テストコードを記録用に Markdown 形式で格納。 |
code/tests/ |
同上 |
.py 形式の実行可能テスト(pytest / unittest)。CI やローカルで pytest を叩けばそのまま動く。 |
6. その他補助ファイル
| ファイル/役割 | 詳細 |
|---|---|
tech_constraints.md(読み込み専用) |
スクリプト起動時に読み込み、LLM へのプロンプトへ注入。プロジェクト直下には複製されない。 |
The following technologies must be strictly used in this system.
If an item is left blank, any appropriate technology may be used for that area.
- Frontend: Python
- Backend: Python
- Program code:Python
- Framework: streamlit
- Data Store: unnecessary
- Authentication: unnecessary
- External APIs: openai
👆今回はこちらのような記載をしています。
今回のインプット:議事録
仮想のヒアリング議事録を使います。ヒアリング議事録は、最終的な結論がチャットBotとなるような内容です。
ユーザーヒアリング議事録
日付: 2025年7月25日
参加者:
* 田中(ユーザー・営業部)
* 山本(開発担当)
* SNG(ファシリテーター)
## 1. 業務上の課題
**田中:**
「最近、お客様からの問い合わせが増えていて、電話やメール対応にかなり時間がかかっています。特によくある質問に同じ内容を繰り返し回答している状況です。」
**山本:**
「FAQは一応ウェブサイトに載せていますが、見てもらえていないことが多いみたいですね。」
## 2. 現在の対応方法
**田中:**
「基本的には電話かメールでの対応です。チャットは一部使っていますが、ほとんど手動です。」
**SNG:**
「手動のチャット対応はどうですか?」
**田中:**
「すぐ返せないことも多いですし、営業時間外の問い合わせは翌日まで対応できません。」
## 3. 求める改善
**田中:**
「できれば、お客様が自分で簡単に疑問を解決できる仕組みが欲しいです。」
**山本:**
「問い合わせ対応の工数を減らしたい、というのが本音です。」
## 4. アイデア出し
**SNG:**
「例えば、チャットボットのような自動応答の仕組みがあれば、よくある質問への対応は自動化できるかもしれません。夜間や休日の対応も可能になります。」
**田中:**
「それはいいですね。お客様もすぐに回答が得られれば満足度が上がると思います。」
## 5. 結論
**SNG:**
「本日のヒアリングを受けて、問い合わせ対応の効率化と顧客満足度の向上のために、まずは小規模なPoCとしてチャットボットを導入・検証してはいかがでしょうか。」
**田中:**
「ぜひ、PoCを通じてチャットボット導入の方向で進めてほしいです。」
---
## 6. 次のアクションプラン(PoCからスタート)
### 6.1 PoC実施の目的
* チャットボット導入による問い合わせ対応時間の短縮効果を定量的に検証する。
* FAQ自己解決率向上と顧客満足度への寄与を測定する。
### 6.2 ストーリーの流れ
1. **PoC開始(小さく早く試す)**: 上位10件のFAQを対象にチャットボット応答を構築。
2. **効果測定**: 自己解決率や対応時間を定量的に計測し、ユーザー満足度アンケートを実施。
3. **正式導入判断**: KPI達成度に基づき、さらなるFAQ拡充や他チャネル連携を検討。
4. **拡大/改善**: 全FAQや新規問い合わせカテゴリへの対応範囲拡大、AI学習データの継続的改善。
### 6.3 スコープ
* FAQ上位10件を対象に自動応答シナリオを構築。
* 対象チャネル: Webサイト埋め込みチャットウィジェット。
* 営業時間内外を含む問い合わせに対応。
### 6.4 体制と役割
| 役割 | 担当 | 主なタスク |
| ------------ | --- | ------------------ |
| PoCリード | 山本 | シナリオ作成、ボット設定、技術検証 |
| FAQ提供 | 田中 | FAQ選定・文面調整、業務ヒアリング |
| 進捗管理/ファシリテート | SNG | スケジュール管理、週次レビュー |
### 6.5 スケジュール(案)
| 期間 | タスク |
| ---------------- | ----------- |
| 2025/08/01〜08/07 | FAQ選定・文面確定 |
| 2025/08/08〜08/21 | ボット開発・テスト |
| 2025/08/22〜08/31 | 本番環境 PoC 実施 |
| 2025/09/01〜09/05 | 結果分析・レポート作成 |
### 6.6 成功指標(KPI)
* 自己解決率 60% 以上
* 平均対応時間 30% 削減
* 顧客満足度 (CSAT) +10 ポイント
### 6.7 次のステップ
* 2025年9月第1週にPoC結果レビューを行い、正式導入可否を決定。
* 導入が決定した場合は、FAQ拡充および他チャネル連携へフェーズ2を開始。
実行結果
プロジェクト内容
# Project Description
## プロジェクト概要
### 1. 目的
本プロジェクトの目的は、問い合わせ対応の効率化と顧客満足度の向上を図るために、チャットボットを導入し、その効果を検証することです。具体的には、FAQの自己解決率を向上させ、問い合わせ対応時間を短縮することを目指します。
### 2. 背景
営業部では、最近お客様からの問い合わせが増加しており、電話やメールでの対応に多くの時間を費やしています。特によくある質問に対して同じ内容を繰り返し回答している状況です。現在、FAQはウェブサイトに掲載されていますが、十分に活用されていないため、問い合わせ対応の工数削減が求められています。
### 3. ステークホルダー
- 田中様(ユーザー・営業部):FAQの選定と文面調整、業務ヒアリングを担当
- 山本様(開発担当):シナリオ作成、ボット設定、技術検証を担当
- SNG様(ファシリテーター):スケジュール管理、週次レビューを担当
### 4. 業務フロー概要
1. **PoC開始(小さく早く試す)**
- 上位10件のFAQを対象にチャットボット応答を構築します。
2. **効果測定**
- 自己解決率や対応時間を定量的に計測し、ユーザー満足度アンケートを実施します。
3. **正式導入判断**
- KPI達成度に基づき、さらなるFAQ拡充や他チャネル連携を検討します。
4. **拡大/改善**
- 全FAQや新規問い合わせカテゴリへの対応範囲拡大、AI学習データの継続的改善を行います。
### 5. システムスコープ
- FAQ上位10件を対象に自動応答シナリオを構築します。
- 対象チャネルはWebサイト埋め込みチャットウィジェットです。
- 営業時間内外を含む問い合わせに対応します。
### 6. 成功指標(KPI)
- 自己解決率 60% 以上
- 平均対応時間 30% 削減
- 顧客満足度 (CSAT) +10 ポイント
### 7. 前提条件と制約
- PoCは2025年8月1日から開始し、9月第1週に結果レビューを行います。
- PoCの結果に基づき、正式導入の可否を決定します。
- 導入が決定した場合は、FAQ拡充および他チャネル連携へフェーズ2を開始します。
- チャットボットの導入により、夜間や休日の問い合わせにも対応可能となることを目指します。
本プロジェクトを通じて、問い合わせ対応の効率化と顧客満足度の向上を実現し、営業部の業務負荷を軽減することを期待しています。
要求
# Requirements
Requirements Specification
### Overview
本仕様書は、問い合わせ対応の効率化と顧客満足度の向上を目的としたチャットボットシステムの導入に関する要件を定義します。本システムは、PythonおよびStreamlitを用いて開発され、OpenAIのAPIを活用してFAQの自動応答を実現します。
### Requirement 1: FAQ自動応答機能
- **User Story**: 営業部の担当者として、よくある質問に対して自動で回答できるようにしたい。これにより、問い合わせ対応の時間を削減し、顧客満足度を向上させたい。
- **Acceptance Criteria**:
- WHEN ユーザーがFAQに関する質問をチャットウィジェットに入力する THEN チャットボットが適切な回答を自動で返す。
- WHEN FAQに該当する質問がない場合 THEN チャットボットが「担当者が後ほど対応します」と案内する。
- **Success Criteria**:
- 自己解決率 60% 以上
### Requirement 2: 営業時間外対応機能
- **User Story**: 営業部の担当者として、営業時間外でもお客様が問い合わせを行えるようにしたい。これにより、顧客の利便性を向上させたい。
- **Acceptance Criteria**:
- WHEN 営業時間外に問い合わせが行われた場合 THEN チャットボットが自動応答を行い、必要に応じて翌営業日に担当者が対応する旨を伝える。
### Requirement 3: FAQ管理機能
- **User Story**: 営業部の担当者として、FAQの内容を簡単に更新・管理したい。これにより、常に最新の情報を提供したい。
- **Acceptance Criteria**:
- WHEN FAQの内容を更新する必要がある場合 THEN 管理画面からFAQを編集し、即時に反映される。
### Requirement 4: 効果測定機能
- **User Story**: 開発担当者として、チャットボットの効果を定量的に測定したい。これにより、導入の有効性を判断したい。
- **Acceptance Criteria**:
- WHEN PoC期間中 THEN 自己解決率や平均対応時間を計測し、結果をレポートとして出力する。
- **Success Criteria**:
- 平均対応時間 30% 削減
- 顧客満足度 (CSAT) +10 ポイント
### Requirement 5: ユーザー満足度調査機能
- **User Story**: 営業部の担当者として、チャットボット利用後の顧客満足度を把握したい。これにより、サービス改善に役立てたい。
- **Acceptance Criteria**:
- WHEN チャットボットの利用が終了した場合 THEN ユーザーに満足度アンケートを表示し、フィードバックを収集する。
### Requirement 6: PoC実施と評価
- **User Story**: 開発担当者として、PoCを通じてチャットボットの導入効果を検証したい。これにより、正式導入の判断材料としたい。
- **Acceptance Criteria**:
- WHEN PoCが終了した場合 THEN 結果を分析し、正式導入の可否を決定するための報告書を作成する。
### Requirement 7: チャットウィジェットの埋め込み
- **User Story**: 開発担当者として、Webサイトにチャットウィジェットを埋め込みたい。これにより、ユーザーが簡単にアクセスできるようにしたい。
- **Acceptance Criteria**:
- WHEN Webサイトが表示された場合 THEN チャットウィジェットが画面の右下に表示される。
以上が、チャットボットシステムの要件仕様です。これらの要件を基に、PoCを通じてシステムの有効性を検証し、正式導入の判断を行います。
設計書
# Design
```markdown
# FAQチャットボットシステム 技術設計書
## 1. システム概要・目的
本システムは、PythonおよびStreamlitを用い、OpenAI APIを活用してFAQ自動応答を実現するチャットボットを構築します。
主な目的は以下のとおりです。
- 問い合わせ対応の効率化
- 顧客満足度向上(CSAT +10ポイント)
- 営業時間外でも対応可能
- PoCによる自己解決率60%以上、平均対応時間30%削減の実証
---
## 2. 全体アーキテクチャ
```mermaid
graph TD
subgraph Frontend
A[Streamlit Web UI]
A --> B[チャットウィジェット]
A --> C[FAQ管理画面]
A --> D[レポート画面]
end
subgraph Backend (Streamlit App)
E[Chat Service]
F[OpenAI API Client]
G[FAQリポジトリ (JSONファイル)]
H[ログ/メトリクス収集モジュール]
end
A -->|API呼び出し| E
E -->|質問→FAQ検索| G
E -->|未ヒット時API呼び出し| F
E -->|応答生成| F
E -->|応答返却| A
E -->|ログ書き出し| H
D -->|データ取得| H
C -->|FAQ CRUD| G
(以下省略)
タスク
タスクはコード生成する上で非常に重要でした。あまりにざっくりなタスクだとうまくコード生成できないことが後々分かったので、プロンプトをチューニングし具体的なタスクに落とし込みました。
# Tasks
- # Implementation Plan
- ## Phase 1: 環境構築とプロジェクト設定
- - [ ] 1.1 requirements.txt の作成 (requirements.txt) // Python 依存関係(Streamlit, openai, annoy, pandas など)を定義
- - [ ] 1.2 .env.example の作成 (.env.example) // 環境変数テンプレート(OPENAI_API_KEY, ADMIN_PASSWORD など)を準備
- - [ ] 1.3 Dockerfile の作成 (Dockerfile) // Python3.10 ベースのコンテナ、依存関係インストールを記述
- - [ ] 1.4 docker-compose.yml の作成 (docker-compose.yml) // dev/stg/prod 各環境のローカル起動設定
- - [ ] 1.5 Streamlit シークレット設定ファイル初期化 (.streamlit/secrets.toml) // 管理者パスワード用途の設定記述
- ## Phase 2: コアバックエンドモジュール実装
- ### 2.1 FAQリポジトリ関連
- - [ ] 2.1.1 FAQモデル定義 (models/faq.py) // FAQItem, FAQItemWithSimilarity の Pydantic スキーマを実装
- - [ ] 2.1.2 FAQRepository 基本 CRUD 実装 (repositories/faq_repository.py) // load_all, upsert, delete メソッドを実装
- - [ ] 2.1.3 類似度検索ロジック実装 (repositories/faq_repository.py) // Annoy を用いたベクトル化+search_similar を実装
- ### 2.2 OpenAI クライアント
- - [ ] 2.2.1 OpenAIClient クラス実装 (clients/openai_client.py) // GPT-4.1 呼び出しと例外ハンドリングを実装
- - [ ] 2.2.2 モック OpenAIClient 作成 (clients/mock_openai_client.py) // ユニットテスト向けに固定応答を返すモックを実装
- ### 2.3 ChatService
- - [ ] 2.3.1 ChatService クラス実装 (services/chat_service.py) // handle_message 内で時間外判定、FAQ検索、OpenAI 呼出しを統合
- - [ ] 2.3.2 営業時間判定関数実装 (utils/business_time.py) // is_business_hour を作成・テスト
- - [ ] 2.3.3 キャッシュ機能実装 (services/cache.py) // TTL5分の質問→回答キャッシュを追加
- ## Phase 3: Streamlit UI 開発
- ### 3.1 チャットウィジェット
- - [ ] 3.1.1 メインチャットページ実装 (app.py) // ユーザー入力欄と回答表示ロジックを実装
- - [ ] 3.1.2 チャット履歴コンポーネント (components/chat_widget.py) // メッセージバブル UI を実装
- ### 3.2 FAQ管理画面
- - [ ] 3.2.1 FAQ一覧表示ページ実装 (pages/admin_faq.py) // テーブル表示と FAQRepository.load_all 呼び出し
- - [ ] 3.2.2 FAQ編集モーダルコンポーネント (components/faq_modal.py) // 追加・編集フォームとバリデーションを実装
- - [ ] 3.2.3 FAQ削除機能実装 (pages/admin_faq.py) // 削除ボタン押下時に delete を呼び出し、再ロード
- ### 3.3 レポート画面
- - [ ] 3.3.1 メトリクスサービス実装 (services/metrics_service.py) // JSONL から自己解決率・平均応答時間を計算
- - [ ] 3.3.2 レポートページ実装 (pages/admin_report.py) // KPI グラフ表示と CSV/PDF ダウンロード機能
- ### 3.4 認証・アクセス制御
- - [ ] 3.4.1 管理画面認証ロジック実装 (utils/auth.py) // st.secrets と入力パスワード比較でアクセス制限
- ## Phase 4: 追加機能実装
- ### 4.1 CSAT アンケート機能
- - [ ] 4.1.1 SurveyResponse モデル定義 (models/survey.py) // Pydantic で評価・コメントスキーマを定義
- - [ ] 4.1.2 アンケート投稿モジュール実装 (modules/survey_module.py) // submit メソッドでログ出力
- - [ ] 4.1.3 アンケートフォームコンポーネント (components/survey_form.py) // チャット終了後に表示する UI
- ### 4.2 PoC レポート自動生成
- - [ ] 4.2.1 KPI 計測スクリプト作成 (scripts/poc_metrics.py) // 収集ログから自己解決率・応答時間を集計
- - [ ] 4.2.2 ReportService 実装 (services/report_service.py) // generate_report で PoC レポート生成
- ### 4.3 ウィジェット埋め込み
- - [ ] 4.3.1 埋め込みスクリプト作成 (static/widget.js) // 任意サイトに貼るだけで右下チャットウィジェット表示
- - [ ] 4.3.2 スクリプト連携ロジック追加 (app.py) // ウィジェット経由の API 呼出しまたは iframe 表示
- ## Phase 5: テスト
- ### 5.1 ユニットテスト
- - [ ] 5.1.1 FAQRepository テスト (tests/test_faq_repository.py) // load_all, upsert, delete, search_similar の単体
- - [ ] 5.1.2 OpenAIClient テスト (tests/test_openai_client.py) // 正常応答・例外時の挙動検証
- - [ ] 5.1.3 ChatService テスト (tests/test_chat_service.py) // 時間外, FAQヒット, AI呼び出しの分岐を検証
- ### 5.2 E2E テスト
- - [ ] 5.2.1 pytest+selenium セットアップ (tests/e2e/conftest.py) // WebDriver 設定、アプリ起動フック
- - [ ] 5.2.2 チャットフロー E2E テスト (tests/e2e/test_chat_flow.py) // 質問→回答→アンケート一連動作検証
- ## Phase 6: デプロイと運用準備
- - [ ] 6.1 Helm チャート作成 (deploy/helm/) // dev/stg/prod 環境用テンプレートを実装
- - [ ] 6.2 Kubernetes マニフェスト整備 (deploy/k8s/) // Deployment, Service, Ingress 等の YAML を準備
- - [ ] 6.3 CI/CD パイプライン設定 (/.github/workflows/) // build→unit test→e2e test→helm deploy を実装
- - [ ] 6.4 監視・ログ収集設定 (monitoring/) // JSONL ログ保持・メトリクス収集、Prometheus/Grafana 連携準備
生成されたコード
すべてを表示するとかなり多いので、抜粋とさせていただきます。
メインのapp.pyが下記のコードです。自作のモジュールをたくさんインポートしています。
import streamlit as st
import uuid
import pandas as pd
from datetime import datetime
from faq_repository import FAQRepository, FAQItem
from openai_client import OpenAIClient
from chat_service import ChatService
from logger import Logger
# Initialize components
openai_client = OpenAIClient()
faq_repo = FAQRepository(openai_client=openai_client)
logger = Logger()
chat_service = ChatService(faq_repo, openai_client, logger)
# Streamlit layout
st.set_page_config(page_title="FAQ Chatbot System", layout="wide")
# Sidebar for navigation
page = st.sidebar.selectbox("ページ選択", ["Chat", "FAQ管理", "レポート"])
if page == "Chat":
st.title("チャットウィジェット")
if "history" not in st.session_state:
st.session_state.history = []
user_input = st.text_input("質問を入力してください。", key="input")
if st.button("送信"):
if user_input:
user_id = st.session_state.get("user_id", str(uuid.uuid4()))
st.session_state["user_id"] = user_id
reply = chat_service.handle_message(user_id, user_input)
st.session_state.history.append(("ユーザー", user_input))
st.session_state.history.append(("Bot", reply))
st.experimental_rerun()
# Display chat history
for speaker, text in st.session_state.history:
if speaker == "ユーザー":
st.markdown(f"**{speaker}**: {text}")
else:
st.markdown(f"> **{speaker}**: {text}")
# At the end of session, show survey once
if st.session_state.history:
if "survey_done" not in st.session_state:
st.subheader("このチャットの満足度を教えてください")
rating = st.slider("評価 (1-5)", 1, 5, 3)
comment = st.text_area("コメント (任意)")
if st.button("送信", key="survey"):
logger.log_survey(
user_id=st.session_state.user_id,
session_id=str(uuid.uuid4()),
rating=rating,
comment=comment if comment else None
)
st.session_state.survey_done = True
st.success("ご回答ありがとうございます!")
elif page == "FAQ管理":
st.title("FAQ管理画面")
pwd = st.text_input("管理者パスワード", type="password")
if pwd != st.secrets.get("admin_password", ""):
st.error("パスワードが違います")
st.stop()
# Load and display FAQs
faqs = faq_repo.load_all()
df = pd.DataFrame([{
"ID": f.id,
"質問": f.question,
"回答": f.answer,
"タグ": ",".join(f.tags),
"更新日": f.updated_at.strftime("%Y-%m-%d %H:%M:%S")
} for f in faqs])
st.dataframe(df)
st.subheader("FAQ追加 / 編集")
edit_id = st.text_input("FAQ ID (編集時のみ)")
q = st.text_input("質問")
a = st.text_area("回答")
tags = st.text_input("タグ (カンマ区切り)")
col1, col2 = st.columns(2)
with col1:
if st.button("保存"):
if not q or not a:
st.error("質問と回答は必須です")
else:
item = FAQItem(
id=edit_id if edit_id else f"faq-{uuid.uuid4()}",
question=q,
answer=a,
tags=[t.strip() for t in tags.split(",") if t.strip()],
updated_at=datetime.utcnow()
)
faq_repo.upsert(item)
st.success("保存しました。ページをリロードしてください。")
with col2:
if edit_id and st.button("削除"):
faq_repo.delete(edit_id)
st.success("削除しました。ページをリロードしてください。")
elif page == "レポート":
st.title("レポート画面")
chat_logs = logger.load_chat_logs()
if not chat_logs:
st.info("チャットログがありません")
else:
df = pd.DataFrame(chat_logs)
# KPI: 自己解決率
total = len(df)
solved = df["is_faq"].sum()
ratio = solved / total * 100
avg_time = df["response_time"].mean()
st.metric("自己解決率 (%)", f"{ratio:.1f}")
st.metric("平均応答時間 (秒)", f"{avg_time:.2f}")
st.subheader("応答時間分布")
st.bar_chart(df["response_time"])
# CSV download
csv = df.to_csv(index=False).encode("utf-8")
st.download_button(
label="CSVダウンロード",
data=csv,
file_name="chat_report.csv",
mime="text/csv"
)
自作のchat_servicesモジュールは下記です。いい感じです(笑)
import json
import logging
from datetime import datetime
from typing import Optional
from .faq_repository import FAQRepository, FAQItemWithSimilarity
from .openai_client import OpenAIClient
from .utils import is_business_hour
# Constants
THRESHOLD: float = 0.7
OUT_OF_HOURS_MSG: str = (
"ただいま営業時間外のため、ご対応は翌営業日となります。"
)
PENDING_MESSAGE: str = "担当者が後ほど対応します。"
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
class ChatService:
"""
ChatService orchestrates incoming user messages, performs business-hour checks,
FAQ similarity search, falls back to OpenAI GPT when necessary, and logs each interaction.
"""
def __init__(self, faq_repo: FAQRepository, openai_client: OpenAIClient) -> None:
"""
Initialize ChatService.
:param faq_repo: Instance of FAQRepository for FAQ operations.
:param openai_client: Instance of OpenAIClient for GPT calls.
"""
self.faq_repo = faq_repo
self.openai_client = openai_client
def handle_message(self, user_id: str, message: str) -> str:
"""
Process a user's message and return an appropriate response.
Steps:
1. Check if current time is within business hours.
2. If out of hours, return OUT_OF_HOURS_MSG.
3. Search local FAQ by similarity.
4. If similarity >= THRESHOLD, return the FAQ answer.
5. Else, call OpenAI API to generate a response.
6. If OpenAI fails, return PENDING_MESSAGE.
7. Log the interaction in JSONL format via the standard logger.
:param user_id: Unique identifier of the user/session.
:param message: The incoming user question/text.
:return: Bot response string.
"""
start_time = datetime.utcnow()
response: str = ""
faq_hit: bool = False
try:
# Business hour check
now = datetime.now()
if not is_business_hour(now):
response = OUT_OF_HOURS_MSG
else:
# FAQ similarity search
faq_with_sim: FAQItemWithSimilarity = self.faq_repo.search_similar(message)
if faq_with_sim.similarity >= THRESHOLD:
response = faq_with_sim.answer
faq_hit = True
else:
# Fallback to OpenAI GPT
ai_response: Optional[str] = self.openai_client.generate(message)
if ai_response is None:
response = PENDING_MESSAGE
else:
response = ai_response
except Exception as e:
# Catch-all for unexpected errors
logger.error(
f"[ChatService] error handling message for user_id={user_id}: {e}",
exc_info=True
)
response = PENDING_MESSAGE
finally:
# Logging the interaction as a JSONL record
end_time = datetime.utcnow()
duration = (end_time - start_time).total_seconds()
log_record = {
"timestamp": start_time.isoformat(),
"user_id": user_id,
"request": message,
"response": response,
"faq_hit": faq_hit,
"response_time_sec": duration
}
try:
logger.info(json.dumps(log_record, ensure_ascii=False))
except Exception as log_exc:
logger.error(
f"[ChatService] failed to log interaction: {log_exc}",
exc_info=True
)
return response
👇ディレクトリもいい感じで分けてくれるので、見やすいのも表示にGoodです。

静的解析の結果
# Test Code for Task: - [ ] 2.3.2 営業時間判定関数実装 (utils/business_time.py) // is_business_hour を作成・テスト
(中間省略)
Explanation of what's covered:
- `test_weekday_identification`: ensures Mon–Fri vs. Sat/Sun logic.
- `test_time_boundaries`: exercises opening/closing second‐level boundaries.
- `test_microsecond_precision`: proves that microsecond deltas just before/after boundaries behave correctly.
- `test_timezone_aware_datetime`: shows that aware datetimes are accepted and no implicit timezone conversion is done.
- `test_invalid_type_raises`: verifies that garbage inputs raise sensible errors.
- `test_batch_performance`: a lightweight performance check over 10 000 calls.
These tests are isolated, fast, and cover all critical code‐paths in `utils/business_time.py`
(以下省略)
要約すると、- [ ] 2.3.2 営業時間判定関数実装 (utils/business_time.py)のタスクに対し、業務時間判定関数とテストは仕様通り正しく実装済み。未使用import削除とテスト強化(境界・タイムゾーン)で更に良くなる。安全性・性能問題なし。と書いてあります。
テストコード生成
import pytest
from datetime import datetime, time, timedelta, timezone
from utils.business_time import is_business_hour
# Helper to find a date in Jan 2024 matching a target weekday
# Jan 1, 2024 is a Monday (weekday=0)
JAN_2024_FIRST = datetime(2024, 1, 1)
def date_for_weekday(target_weekday: int) -> datetime:
"""
Return a datetime on 2024-01 that falls on the given weekday,
preserving the time 00:00:00.
Monday=0 ... Sunday=6
"""
delta_days = (target_weekday - JAN_2024_FIRST.weekday()) % 7
return JAN_2024_FIRST + timedelta(days=delta_days)
@pytest.mark.parametrize("weekday,is_business", [
(0, True), # Monday
(1, True), # Tuesday
(2, True), # Wednesday
(3, True), # Thursday
(4, True), # Friday
(5, False), # Saturday
(6, False), # Sunday
])
def test_weekday_identification(weekday, is_business):
"""
Check that weekdays Monday–Friday are considered weekdays,
weekends are not, ignoring time of day.
"""
dt = date_for_weekday(weekday)
# at noon, business hours only if weekday < 5
dt_noon = dt.replace(hour=12, minute=0, second=0)
assert is_business_hour(dt_noon) is is_business
@pytest.mark.parametrize(
"hour,minute,second,expected",
[
# exactly at opening
(9, 0, 0, True),
# one microsecond before opening
(8, 59, 59, False),
(8, 59, 59, False),
# exactly at closing
(18, 0, 0, True),
# one second after closing
(18, 0, 1, False),
# deep inside business hours
(15, 30, 45, True),
# early morning well before
(0, 0, 0, False),
# late night
(23, 59, 59, False),
],
)
def test_time_boundaries(hour, minute, second, expected):
"""
Confirm that only times between 09:00:00 and 18:00:00 inclusive
return True on a known weekday.
"""
# Pick a known weekday: Wednesday (weekday=2)
dt_wed = date_for_weekday(2)
test_dt = dt_wed.replace(hour=hour, minute=minute, second=second)
assert is_business_hour(test_dt) is expected
def test_microsecond_precision():
"""
The function ignores microseconds (only comparisons on time()),
so two datetimes differing only by microsecond should behave the same.
"""
base = date_for_weekday(3).replace(hour=9, minute=0, second=0, microsecond=0)
dt_exact = base
dt_micro_after = base.replace(microsecond=1)
dt_micro_before = base - timedelta(microseconds=1)
assert is_business_hour(dt_exact) is True
# dt_micro_after.time() > 09:00:00, so still business hours
assert is_business_hour(dt_micro_after) is True
# dt_micro_before.time() is 08:59:59.999999 -> before business
assert is_business_hour(dt_micro_before) is False
def test_timezone_aware_datetime():
"""
An aware datetime will be treated by its local time component,
since .time() and .weekday() still work. No timezone conversion is done.
"""
# Pick Thursday at 10:00 UTC
tz_dt = date_for_weekday(3).replace(hour=10, minute=0, second=0, tzinfo=timezone.utc)
assert tz_dt.tzinfo is not None
# 10:00 UTC on a Thursday is within business bounds by local clock
assert is_business_hour(tz_dt) is True
# Move the same moment to just after closing in UTC
tz_after = tz_dt.replace(hour=18, minute=0, second=1)
assert is_business_hour(tz_after) is False
@pytest.mark.parametrize("bad_input", [
None,
123,
"2024-01-03T10:00:00",
datetime, # the class, not an instance
])
def test_invalid_type_raises(bad_input):
"""
Passing anything other than a datetime instance should raise
an AttributeError when .weekday() or .time() is missing.
"""
with pytest.raises((AttributeError, TypeError)):
is_business_hour(bad_input)
def test_batch_performance():
"""
A simple micro‐benchmark: apply the function to 10_000 datetimes
and assert that it's still very fast (< 0.1s).
"""
import time as _time
# Generate 10k datetimes spanning business and non-business hours
start = date_for_weekday(0).replace(hour=0)
datetimes = [
start + timedelta(minutes=i * 1)
for i in range(10_000)
]
t0 = _time.perf_counter()
results = [is_business_hour(dt) for dt in datetimes]
elapsed = _time.perf_counter() - t0
# We don't assert specific result patterns here, just that it completed quickly
assert elapsed < 0.1, f"Performance regression: took {elapsed:.3f}s"
# And that we got 10k boolean results
assert len(results) == 10_000
assert all(isinstance(r, bool) for r in results)
- 曜日判定のテスト
平日(月~金)は営業時間内ならTrue、土日は常にFalseになるか確認 - 時間境界のテスト
営業開始・終了時刻ピッタリや、その直前直後など「境界値」で判定が正しいかどうか - マイクロ秒単位の精度
秒未満の差異(09:00:00.000001など)でも期待通りの挙動か - タイムゾーン対応
タイムゾーン付きdatetimeでも、ローカル時刻だけを見て判定していることを確認 - 異常入力(型エラー)のハンドリング
datetime以外の入力(None, 数字, 文字列, クラス本体など)でエラー(AttributeError/TypeError)が出ることを確認 - パフォーマンステスト
10,000件のdatetimeに対し、関数を0.1秒以内で高速に判定できるか検証
👉そこそこ網羅的なテストプラン(異常系・境界値系)を立てれていそうです。
mocアプリを起動!
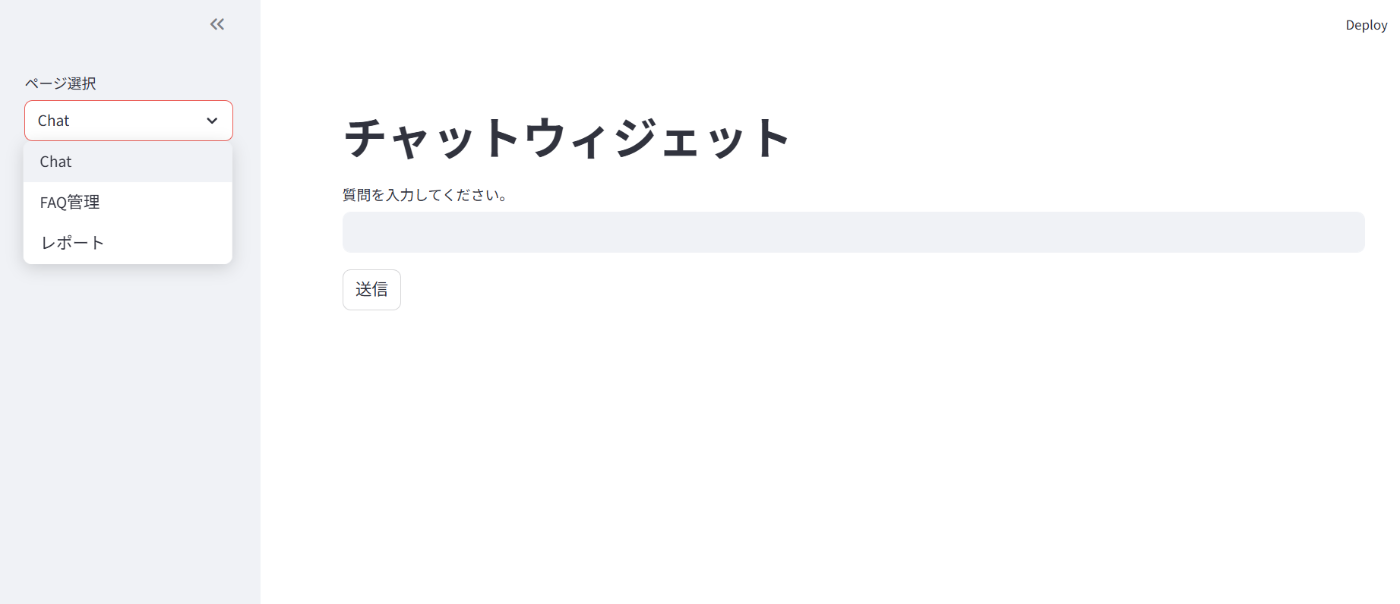
カッコいいデザインではないけど、ちゃんと動いた!
やはり要件にカッコいいデザインとは?をちゃんと入れないとダメですね。
まとめ
とりあえず超MVPですが、コード生成をタスクごとに行い、テストプランや静的解析を1ユースケースですが自動化することができました。課題としては非常にやり取りが多いことと実行時間を要してしまったことです。ヒューマンフィードバックが今回のユースケースでも56回(笑)、APIの実行回数は100回以上と非常に多くなってしまいました苦笑
もしかしたら、この手の仕様書駆動型のコード生成はE2Eで実行するというよりは、もう少しプロジェクト自体の粒度を落として実行する方がベストプラクティスを得られやすいかもしれません。
私の所感としてはやはりクラスの切り方や関数の粒度が自分の温度感と合わないことが正直多かったというところですね。
また、もしかしたら、すでにそういう使われ方をしている方も多いかもしれませんが。。(笑)、kiroみたいなアプリで要件だけざっくり整理し、Cursor等に投げてVibecodingするというのも結構ありな気がしてます。そのため、今後は要件定義するところをもうちょっと精度アップし、コード生成は別のツールで行う、という方針に切り替えたいと思っています。
もしご興味あれば!
今は完全に趣味で開発してますが、ossとして汎用性を持たせて公開することも検討しています。もしご興味ある方いましたら一緒に開発してブラッシュアップしましょう!🔥
SNGの連絡先
※完全に趣味であり営利目的ではありません
Discussion