AWSデータレイク入門:クラウド時代のデータ分析基盤
目次
- 概要
- データ基盤とは?
- データレイクとは?
- データレイクの全体像と関連するAWSサービス
- AWSを使用した構築事例(※一例)
- 最後に -Udemy入門コース紹介-
概要
この記事では、データレイクの基本概念と、データ基盤としての重要性について解説します。
データ基盤がなぜ必要なのか、どのような背景からその必要性が生じたのかを簡潔に説明し、分析の基盤としての役割を理解します。
また、データレイクとはどういったものなのか、データウェアハウスとどう異なるのかや
データレイクの基本的な構造と、それに関連するAWSサービスの概要を把握します。
データ基盤とは?
近年、デジタル化が進む中で、データを活用することが非常に重要視されています。
その一例として、データに基づいた意思決定が挙げられます。
こうしたデータ活用を支えるのが「データ基盤」です。
データ基盤とは、データを継続的に収集し、蓄積し、活用するためのシステムです。
たとえば、データ分析者は一時的に社内外からデータを集め、分析や効果検証を行うことができますが、企業の持続的な成長を支えるためには、しっかりとしたデータ基盤の構築が求められます。
もし企業内にデータ基盤が整っていない場合、データ活用のたびにさまざまなソースからデータを寄せ集める必要があります。これにはWebアプリケーションのデータベース、共有ファイルシステム内のスプレッドシート、さらには紙の契約書といった形式が含まれるかもしれません。
このような状況では、データ収集に多大な時間が費やされ、効率が大幅に損なわれます。
つまり、データ活用を真に実現するには、データ分析者だけでなく、適切に構築されたデータ基盤が不可欠であるということが理解できるでしょう。
では、そのデータ基盤のシステムについて見ていきましょう。
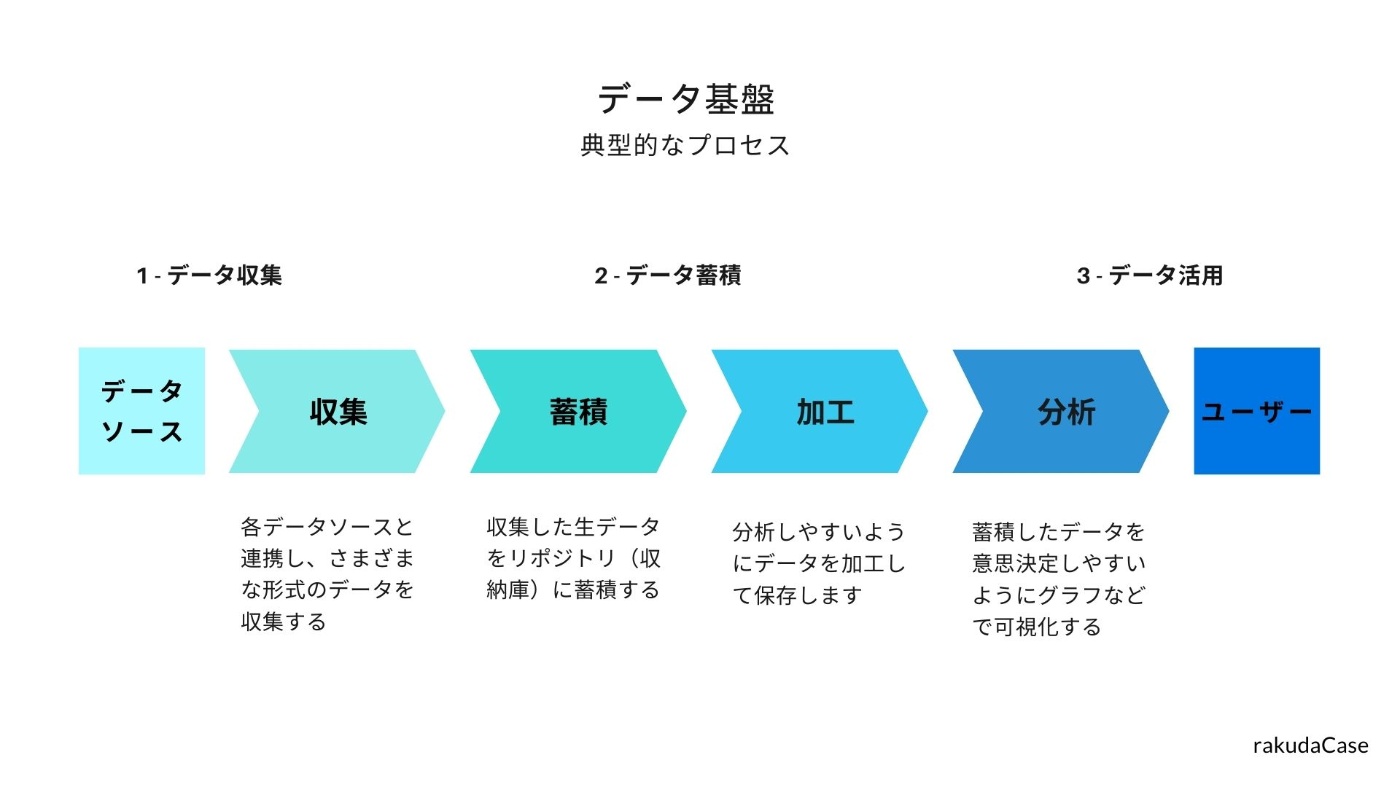
↑こちらは、データ基盤の典型的なプロセスになります。
この一連の流れは、大きく「データ収集」、「データ蓄積」、「データ活用」に分けられます。
- 各データソースと連携し、さまざまな形式のオリジナルのデータを収集する
- 収集したデータをリポジトリという収納庫に蓄積します
- そして、必要に応じて、分析しやすいようにデータを加工する
- その後、グラフなどで可視化して、ユーザーの意思決定をサポートします
このプロセスをシステム化することで、散らばったデータを定期的に収集、加工し、さまざまなユースケースに対応したデータ活用が可能になります。
そして、このデータ基盤を構築する方法の一つとして、データレイクを中心にしたアーキテクチャがあります。
データレイクとは?
データレイクは、文字通り「データの湖」を意味し、様々な形式のデータを一箇所に集約して保存するシステムです。
データレイクでは、データベースに保存された構造化データ、アプリケーションのログ、画像や音声ファイルなど、異なる形式のデータを一箇所で管理することが可能です。
これは、多様なデータソースからのデータを蓄積する場所として機能し、そのために「レイク(湖)」と呼ばれます。
そうですね、湖は自然な状態で水が溜まっており、様々な源からの水が集まっています。
この水は処理される前の原水であり、利用するためには適切な処理が必要です。

データレイクもこれと同様で、多様な形式やソースからのデータが原形で保持されており、使用する際には適切な処理や変換が必要になります。
利用前にはクレンジングや適切な変換が行われ、その変換後データもデータレイク上に保存することがあります。
新しいニーズに合わせて後から整理や分析を行うことが可能です。
(例:ECサイトの注文履歴データや顧客データのコピーをリポジトリに保存し、後から分析して売上データを抽出する場合、これをデータレイクと呼ぶこともできます。)
よく共通の話題に上がるもので、データウェアハウスというものもあります。
データウェアハウスは、データを取り込む前に整形・清掃され、分析に適した形式に加工されてから格納されるシステムです。
データウェアハウスは「水道システム」に例えられます。水道システムでは、水が一定の基準に従って処理され、家庭や企業に直接送られます。この水はすぐに使用できる状態で、特定の目的(飲用、料理、洗濯など)に合わせて供給されます。
同様に、データウェアハウスでは、データが集められ、整理され、分析のために最適化されています。
ユーザーは特定の情報を簡単に取り出すことができ、そのデータはすぐに使用可能です。
(例:自社ECサイトだけでなく、外部ウェブサイトや店舗で商品を販売する場合、そのデータを統合し、加工して「売上」という指標を事前に集計し、保存します。これは分析担当者がスムーズにデータを扱えるようにするためです。)
データウェアハウスは、分析目的特化の加工したデータのみを保存し、すぐに利用できるように整理された「水道水」であり、
データレイクは、加工前の様々な原形データと分析準備の変換したデータを保存し、多用なニーズに対応できるような「湖」と見ることができます。
データレイクとデータウェアハウスは、それぞれ異なる役割と特性を持ち、データの整理と活用の過程で補完関係にあります。例えば、特定の企業データだけを保存していたデータウェアハウスが、新たなビジネス要求に直面した場合、データレイクの柔軟性が重宝されます。(そのためデータレイクハウスといったアーキテクチャもある)
データレイクの全体像と関連するAWSサービス
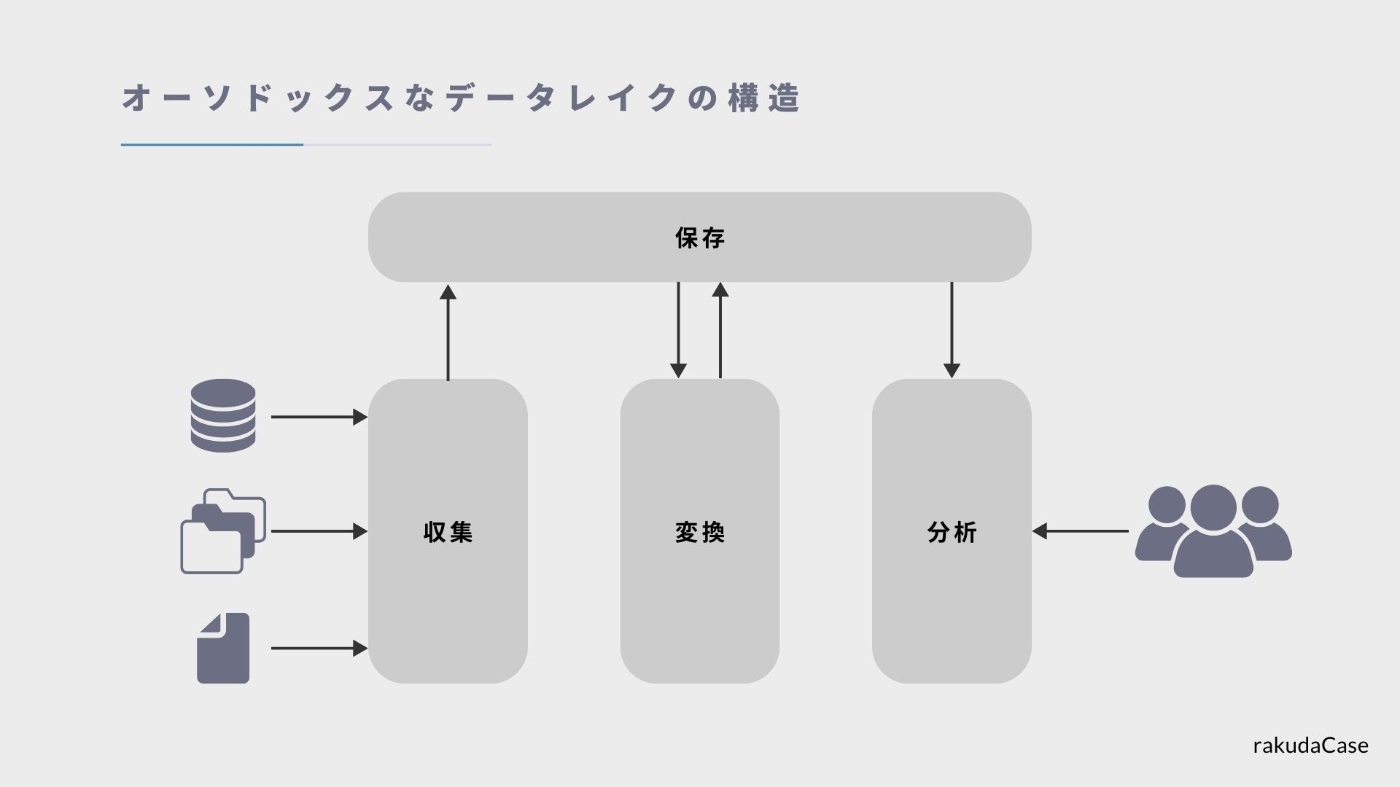
こちらは、データレイクを取り巻くオーソドックスな構造となっています。
(データ基盤のプロセスがベースになっています)
一般的に四つの主要な要素で構成されています。
- 収集 - データの発生元からデータを集めるプロセス
- 保存 - データをストレージに保存し、データカタログを管理する
- 変換 - 保存したデータに対して適切な変換処理を行う
- 分析 - 変換済みのデータを活用する
この中で中心的な役割を果たすのが「保存」です。
通常、データレイクはデータ活用のための全体構造を指すことが多いですが、「保存」の要素自体を狭くデータレイクと定義することもあります。
収集、変換、分析の各プロセスは、基本的に保存したデータに対して読み書きを行います。
つまり、データレイクの構造は、データ保存を中心に、どのようにデータを収集し、蓄積されたデータをどのように変換し、そして変換されたデータをどう分析してビジネスに活かしていくかというプロセスを含んでいます。
それでは、こちらのプロセスに関連するAWSサービスについて見ていきましょう。
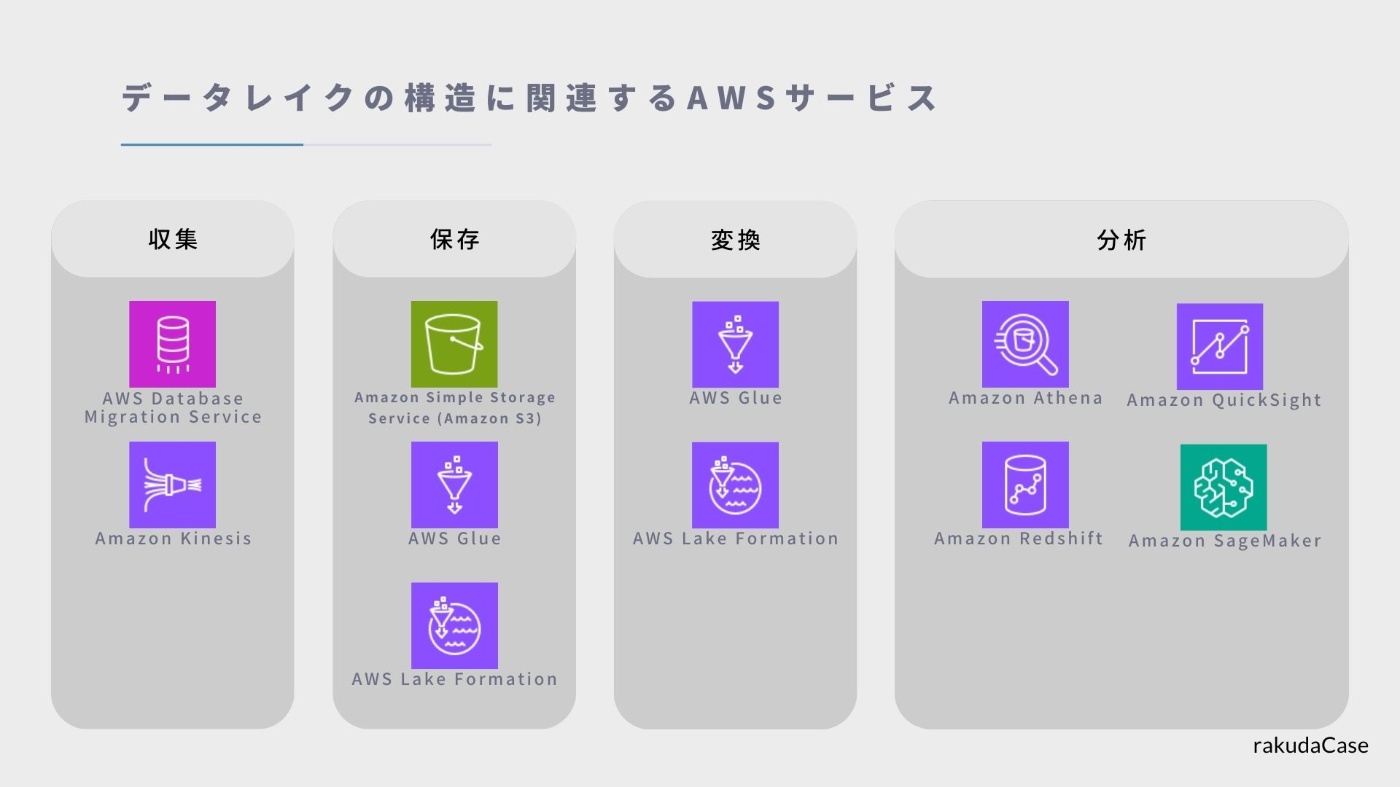
AWSのデータレイクは、Amazon S3を主な入出力先のストレージとして使用します。
データ収集には、リアルタイムデータストリームを収集できるAmazon Kinesisなどがあり
データの変換には、AWS Glueというデータの抽出、変換、書き出し等を行う処理に対応するサービスなどがあります。
データ分析には、サーバレスSQLによるクエリサービスAmazon Athenaや、データを可視化できるAmazon QuickSightといったツールも存在します。
Amazon Redshiftはデータウェアハウスとして機能するサービスですね。
(これらサービス以外にも多くのAWSサービスが存在しますので、基礎を学んだ後は、ご自身のニーズに合わせて適切なサービスを選択すると良いでしょう)
AWSを使用した構築事例(※一例)
AWSを使用した構築事例をさらっと。
(※データ収集の自動化には触れず、データの保存から分析までのプロセスに重点を置いています)
初心者にも取り組みやすいシンプルな構成として
「Amazon S3を中心とした小規模なデータ基盤の構築」があります。
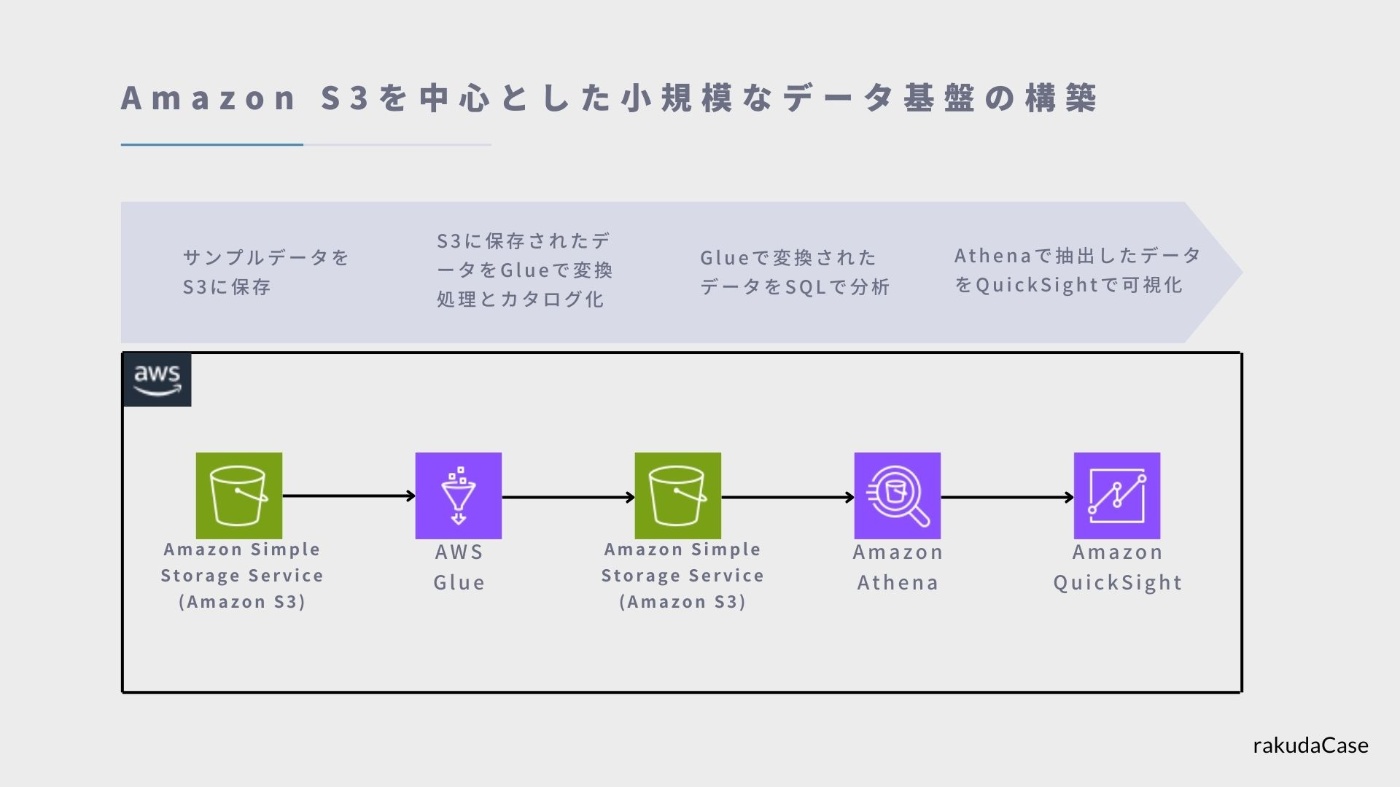
- まず、サンプルデータをAmazon S3に保存し、このデータを使用してデータの抽出や変換を行います
- データ変換には、AWS GlueのETL機能を活用します。ビジュアルインターフェースを使用してデータを分析前の最適な形に整えます
- 変換前後のデータはすべてS3で一元管理されます
- 変換されたデータは、サーバレスSQLサービスであるAthenaを用いてアドホックに分析されます
- 最後に、Athenaで抽出したデータをQuickSightを使って視覚的に表現します
最後に -Udemy入門コース紹介-
この記事を読んでデータ基盤やデータレイクに少しでも興味を持たれた方は、ぜひ私が講師を務めるUdemyのコース「安心して学べるAWSデータレイク入門:S3からQuickSightまでステップバイステップ」をご覧ください。 ※割引クーポンを配布中(有効期限:2024/09/07) クーポン利用希望の方は上記リンクからどうぞ
このコースでは、本記事に関連するデータレイクの基本概念から始まり、Amazon S3でのデータ保存、AWS Glueによるデータ変換とカタログ化、Athenaを用いたデータ分析、そしてQuickSightを使ったデータの可視化まで、実践的なステップバイステップで学べます。初心者からデータエンジニア、さらにはビジネス分析に興味のある方まで、どなたでも安心して学べる内容となっています。興味のある方はぜひご参加ください。
Discussion