DagsterのSensorでイベントドリブンにジョブ実行する
ファイル生成や外部APIレスポンスの状態変化のようなある種のイベント発生をトリガーにしてデータパイプラインを実行したいケースはよくあることかと思います。
今回、DagsterのSensorを使って根本的に課題解決した事例があり、特に重複実行防止の機能があるのが便利だったので、事例も交えてDagsterのSensorについて解説したいと思います。
Dagsterについては過去の Tech Blog をご覧ください。少し前ですが、概要やコンセプトなどは大きく変わりないです。
DagsterのSensorとは?
Sensorは、Dagster内部または外部のイベントや条件を監視し、条件が満たされたときに自動的にアクションを実行する仕組みです。従来の時間ベースのスケジューリングとは異なり、イベント駆動でのパイプライン実行を簡単にできるようになります。
Sensorを使うメリット
DagsterでSensorを使う大きな恩恵として、外部イベントや状態の変化をトリガーとして イベント駆動でパイプラインを自動的に実行できる 点があります。
Dagsterでは op(一般的なスケジューラーでタスクに当たる概念)内で外部状態を監視するロジックを書くことも可能ですが、Sensorを使うことで以下のようなメリットがあります。
- 外部状態の監視とトリガーの分離
- Sensorは外部システム(ファイルの到着、APIの応答、DBの更新など)を定期的に監視し、条件を満たした場合のみジョブやアセットの実行を開始する。 これにより、データパイプラインの処理自体のロジックと、実行タイミングの制御を明確に分離できる。
- 効率的なリソース利用
- Sensorはバックグラウンドで定期的に軽量なチェックを行い、必要なときだけパイプラインを起動する。opやアセット内で監視処理をすると、無駄な実行やポーリングが発生しやすくなり、リソース効率が悪くなってしまう。
- 再利用性・テスト容易性
- Sensorは単体でテスト可能な関数として実装でき、再利用やユニットテストがしやすい設計になっている。
- 重複実行防止機能
-
run_keyというユニークな識別子を使って2回目の実行をスキップし、意図しない重複実行を防ぐことが簡単にできる。また、これにより実装するソースコード量が減り簡潔なロジックを実現できる。
Sensorを利用したジョブ実行の事例
私達の事例の1つとして、Google AnalyticsのデータをBigQueryテーブルにDaily Export[1]しており、昨日の日付のtable_suffixを持つテーブルが作成されたらパイプラインジョブを実行するケースで今回Sensorを利用しました。
ソースコードは下記のようになりました (記事公開向けに一部変更しています)。
@sensor(
job=daily_process_example_job, # Sensor成功時に実行するジョブ
minimum_interval_seconds=1800, # 30分間隔でSensorを起動
default_status=DefaultSensorStatus.RUNNING,
)
def check_for_ga4_table_update():
jst = timezone('Asia/Tokyo')
table_suffix = (datetime.now(jst) - timedelta(days=1)).strftime('%Y%m%d') # 昨日
table_id = f'analytics_259999999.events_{table_suffix}'
try:
bq_client.get_table(table_id) # テーブル存在確認
yield RunRequest(run_key=table_id)
except NotFound:
yield SkipReason(f'Table {table_id} not found')
except Exception as e:
yield SkipReason(f'Getting table {table_id} failed with error {str(e)}')
従来はDaily Exportされている毎日の時刻(+一定のバッファ)を目安にパイプラインジョブを時間でスケジュール実行していましたが、たまにバッファを越える遅延があり、手動でジョブを再実行している課題がありました。
また、バッファを長く取りすぎると、Google AnalyticsのDaily Export後、パイプラインで集計された昨日の実績をなるべく早く確認したいデータ利用者のニーズを満たすことが難しくなります。
Sensorを利用することで、これらの課題を解決することができました。
- たまに起こる失敗の手動リカバリを根絶
- 出発点となる更新自体をトリガーとすることで最短で昨日の実績を確認できるようになった
ちなみに、Sensorの実行履歴は下記のようにWebUIから確認できます。実際に実行されたRunRequestがある場合が緑色です。
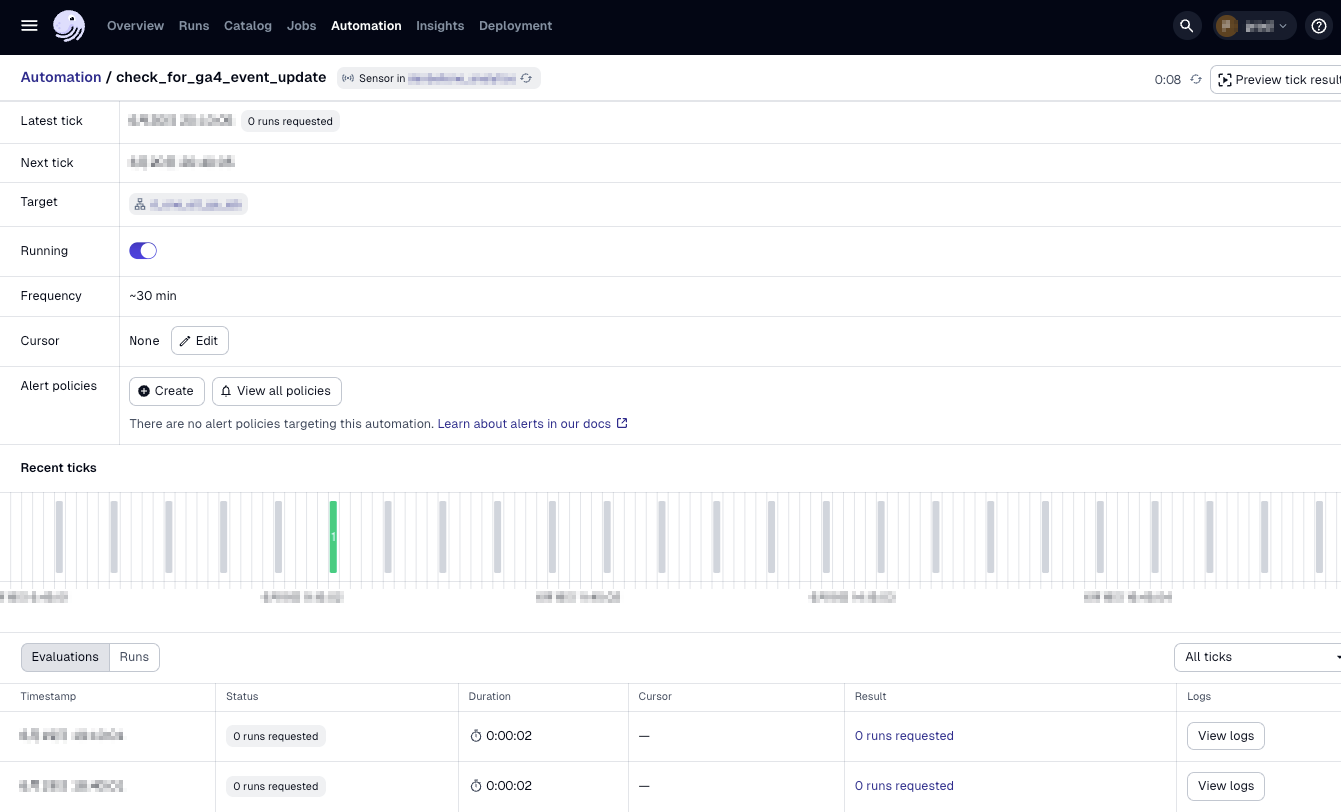
Sensorを使わない場合 (手動での重複防止ロジック)
Sensorを使わない場合だと、重複防止ロジックを自分で実装する必要があり、Sensorを利用した場合と比べて下記のような少し冗長なソースコードになり、注意を払って実装する箇所も増えてしまいます。
※重複する部分が多いため折りたたみで記載
Source code
def check_for_ga4_table_update():
jst = timezone('Asia/Tokyo')
table_suffix = (datetime.now(jst) - timedelta(days=1)).strftime('%Y%m%d') # 昨日
table_id = f'analytics_259999999.events_{table_suffix}'
try:
bq_client.get_table(table_id) # テーブル存在確認
# 既に処理済みかチェック(自分で実装すると)
# 実行するジョブで処理されるテーブルの1つが今日更新されてないかチェックする場合
downstream_table_id = 'warehouse.downstream_table'
table = bq_client.get_table(downstream_table_id) # テーブル取得
last_modified_time = datetime.fromtimestamp(table.modified / 1000, tz=jst)
today = datetime.now(jst).date()
# 更新日が今日より前なら未処理とみなしジョブ実行する
if last_modified_time.date() < today:
yield RunRequest()
else
yield SkipReason(f'Already processed')
except NotFound:
yield SkipReason(f'Table {table_id} not found')
except Exception as e:
yield SkipReason(f'Getting table {table_id} failed with error {str(e)}')
なぜrun_keyを渡せば重複実行されないのか?
Sensorが同じrun_keyを渡したRunRequestでジョブを実行した場合、Dagsterは以下のように動作します:
-
初回実行:
run_keyを持つRunRequestが返される -
ジョブ実行:Dagsterがジョブを実行し、
run_keyを記録 -
2回目以降の実行:その後、同じ
run_keyが渡されても、既に実行済みなのでスキップする
この重複実行防止の仕組みを実際に下記辺りのソースコードから追ってみると、、(今どき追ってくれるのはAIですが)
重複実行防止の流れ
-
Sensor評価: SensorがRunRequestを
run_key付きで返す -
既存実行検索: データベースから同じ
run_keyを持つ既存実行を検索 -
重複チェック: 既存実行が存在、かつ
NOT_STARTED以外のステータスの場合はスキップ (ここで重複実行防止) -
新規実行作成: 重複がない場合のみ新しい実行を作成し、
run_keyをタグとして付与 -
状態更新: Sensor stateに最後の
run_keyを記録
上記のような仕組みとなっているようです。
つまり、run_keyによる重複実行防止は、データベースレベルでの検索と状態管理により実現されており、センサーの信頼性と冪等性を保証しているようです。素敵。
その他のSensorの実装例
Sensorはその他に下記のようなケースでも使うことができるかなと思います。他にも役立つ使い方が色々ありそうですね。今回1つ1つ解説は割愛しますので、気になった方はDagster Docsを参照してみてください。
データベースの変更監視してジョブ実行
@sensor(job=sync_user_data_job)
def database_change_sensor(context):
# 最後のチェック以降に新しいレコードがあるかチェック
new_records = check_for_new_user_records(context.cursor)
if new_records:
yield RunRequest(
run_config={"ops": {"my_asset": {"config": {"records": new_records}}}}
)
yield SkipReason("No new records")
外部APIの状態監視してジョブ実行
@sensor(job=process_api_data_job)
def api_status_sensor(context):
response = requests.get("https://api.example.com/status")
if response.json().get("data_ready"):
yield RunRequest()
yield SkipReason("API data not ready")
ファイル検知して複数ジョブ並列実行
@sensor(job=process_files_job)
def multi_file_sensor(context):
files = glob.glob("/data/*.csv")
for file in files:
yield RunRequest(
run_key=f"process_{os.path.basename(file)}",
run_config={"ops": {"my_asset": {"config": {"file_path": file}}}}
)
my_jobが成功したらSlackに通知
@run_status_sensor(
monitored_jobs=[my_job],
run_status="SUCCESS" # 成功時のみ発火
)
def notify_on_success(context):
def notify_slack(message: str):
client = WebClient(token="xoxb-your-slack-token")
client.chat_postMessage(channel="#your-channel", text=message)
run = context.dagster_run
message = f"✅ Dagster job `{context.dagster_run.job_name}` succeeded!"
notify_slack(message)
まとめ
データパイプラインの運用において、「いつ実行するか」は「何を実行するか」と同じくらい重要な問題です。従来の時間によるスケジューリングでは、データの到着タイミングが不定期な場合に手動での調整が必要になったり、無駄な実行が発生したりと、運用負荷が高くなりがちでした。
DagsterのSensorは、このような課題への柔軟な解決策になる可能性があります。本事例で見たように、データの到着を直接監視することで、手動リカバリの必要性をなくし、データ利用者が求める最短でのデータ集計を実現できました。
特にrun_keyによる重複実行防止の仕組みを利用すれば、誤って意図せず同じジョブを複数回実行するのを防ぎつつ、複雑になりがちな状態管理ロジックを簡潔に実装できるのは大きな恩恵があります。興味を持った方はぜひ試してみてください!
-
なお、Google AnalyticsにはテーブルにStreaming Insertする仕組みもありますが、追加費用がかかるため利用していません。 ↩︎

Discussion