はじめに
- 本記事は、社内の非エンジニア向けの BigQuery SQL入門ドキュメント の BigQueryの関数編 を公開したものです
- 良く使う関数はデータや分析の特性によって異なるので、あくまでも独断と偏見に基づく関数セレクションです
- カテゴリ内の関数の並び順はアルファベット順ではなく、個人的に良く使っていると思う順です
- 慣れてきたら BigQuery の公式リファレンス を確認することをおすすめします
- MySQL や PostgreSQL の利用経験はあるが BigQueryは初めてという社内メンバーをメインターゲットにしているので、そことの違いを補足しています
- 分析関数はBigQuery固有のものでもないので、他サイト等の解説を参考ください
https://cloud.google.com/bigquery/docs/reference/standard-sql/analytic-function-concepts
https://resanaplaza.com/2021/10/17/【ひたすら図で説明】一番やさしい-sql-window-関数(分/
https://qiita.com/tlokweng/items/fc13dc30cc1aa28231c5
変換関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/conversion_functions
CAST(expression AS typename [format_clause])
- typenameへの型変換を行う
- format_clause でフォマットすることも可能
CASTで良く使うデータ型
| 種類 |
型 |
| 数値型 |
● INT64(INT, SMALLINT, INTEGER, BIGINT, TINYINT, BYTEINT)
● NUMERIC(DECIMAL)
● BIGNUMERIC(BIGDECIMAL)
● FLOAT64 |
| 文字列型 |
● STRING |
| 日付型 |
● DATE |
| 日時型 |
● DATETIME |
| 時刻型 |
● TIME |
例
SELECT
FORMAT_DATE('%F %A %a.', DATE '2008-12-25') AS format_date,
CAST(DATE '2008-12-25' AS STRING FORMAT 'YYYY-MM-DD DAY DY.') AS cast_format
| format_date |
cast_format |
| 2008-12-25 Thursday Thu. |
2008-12-25 THURSDAY THU. |
日付関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/date_functions
CURRENT_DATE([time_zone])
- 指定したタイムゾーンの現在日付を返す
- MySQLとPostgreSQLにもある関数
- MySQLで良く使われる CURDATE は使えない
例
SELECT CURRENT_DATE('Asia/Tokyo')
DATE_TRUNC(date_expression, date_part)
- 指定した粒度まで日付を切り詰める
- 日別データを、週、月、年で集計する際に活用できる非常に便利な関数
- PostgreSQLにもある関数
例
SELECT
DATE_TRUNC('2008-12-25', YEAR) AS year,
DATE_TRUNC('2008-12-25', MONTH) AS month,
DATE_TRUNC('2008-12-25', WEEK) as week,
DATE_TRUNC('2008-12-25', WEEK(MONDAY)) as week_monday
| year |
month |
week |
week_monday |
| 2008-01-01 |
2008-12-01 |
2008-12-21 |
2008-12-22 |
DATE_ADD(date_expression, INTERVAL int64_expression date_part)
- 指定した時間間隔を DATE に追加する
- MySQLの + interval 1 day や PostgreSQLの + cast('1 days' as INTERVAL) は使えないが、日数だけであれば +/- 演算子が利用可能
- MySQLにもある関数
例
SELECT
DATE_ADD(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY) AS tomorrow,
DATE_ADD(CURRENT_DATE('Asia/Tokyo'), INTERVAL -1 DAY) AS yesterday,
CURRENT_DATE('Asia/Tokyo') + 1 AS tomorrow2
例
SELECT
DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY) AS yesterday,
DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 52 WEEK) AS weeks_52_ago,
CURRENT_DATE('Asia/Tokyo') - 1 AS yesterday2
EXTRACT(part FROM date_expression)
- 指定した日付の一部に対応する値が返す(part で単位を年、月、日などが指定できる)
- MySQLとPostgreSQLにもある関数
- MySQLで使える year, month, day は使えない
- PostgreSQLで使えるdate_part は使えない
例
SELECT
EXTRACT(DAY FROM DATE '2008-12-25') AS day,
EXTRACT(DAYOFWEEK FROM DATE '2008-12-25') AS day_of_week,
EXTRACT(DAYOFYEAR FROM DATE '2008-12-25') AS day_of_year,
EXTRACT(WEEK FROM DATE '2008-12-25') AS week,
EXTRACT(WEEK(MONDAY) FROM DATE '2008-12-25') AS week_monday,
EXTRACT(ISOWEEK FROM DATE '2008-12-25') AS iso_week,
EXTRACT(MONTH FROM DATE '2008-12-25') AS month,
EXTRACT(QUARTER FROM DATE '2008-12-25') AS quarter,
EXTRACT(YEAR FROM DATE '2008-12-25') AS year
| day |
day_of_week |
day_of_year |
week |
week_monday |
iso_week |
month |
quarter |
year |
| 25 |
5 |
360 |
51 |
51 |
52 |
12 |
4 |
2008 |
DATE_DIFF(date_expression_a, date_expression_b, date_part)
- 日付の差分を返す(date_part で単位を年、月、日などが指定できる)
- MySQLの DATEDIFF や PERIODDIFF は使えない
- PostgreSQLのように +/- で日数やINTERVAL型のようには使えない
例
SELECT
DATE_DIFF('2008-12-26', '2008-12-25', DAY) AS days_diff,
DATE_DIFF('2008-12-27', '2008-12-25', WEEK) AS weeks_diff,
DATE_DIFF('2008-12-28', '2008-12-25', WEEK) AS weeks_diff2,
DATE_DIFF('2008-12-31', '2008-12-25', MONTH) AS months_diff,
DATE_DIFF('2009-01-01', '2008-12-25', MONTH) AS months_diff2,
DATE_DIFF('2008-12-31', '2008-12-25', YEAR) AS years_diff,
DATE_DIFF('2009-01-01', '2008-12-25', YEAR) AS years_diff2
| days_diff |
weeks_diff |
weeks_diff2 |
months_diff |
months_diff2 |
years_diff |
years_diff2 |
| 1 |
0 |
1 |
0 |
1 |
0 |
1 |
DATE(timestamp_expression[, time_zone])
DATE(datetime_expression)
- DATE型の値を返す
- MySQLにもある関数
- PostgreSQLの make_date 相当
例
SELECT
DATE(2008, 12, 25) AS date_ymd,
DATE('2008-12-25 23:59:59') AS date_dt,
DATE('2008-12-25 05:30:00+09', 'Asia/Tokyo') AS date_jst
| date_ymd |
date_dt |
date_jst |
| 2008-12-25 |
2008-12-25 |
2008-12-25 |
FORMAT_DATE(format_string, date_expr)
- 指定された形式に従って日付をフォーマットする
- MySQL の DATE_FORMAT 相当となるが、引数の順番もフォーマットの指定方法も異なる
- PostgreSQLの TO_CHAR 相当となるが、引数の順番もフォーマットの指定方法も異なる
- 特に変換しなくても、SpreadやExcel等のツールでは日付型で認識され、週、月単位への切り詰めは DATE_TRUNC があり、 EXTRACT もあるので、利用するケースはあまりないかも
例
SELECT
FORMAT_DATE('%F %A %a.', DATE '2008-12-25') AS format_date,
CAST(DATE '2008-12-25' AS STRING FORMAT 'YYYY-MM-DD DAY DY.') AS cast_format
| format_date |
cast_format |
| 2008-12-25 Thursday Thu. |
2008-12-25 THURSDAY THU. |
LAST_DAY(date_expression[, date_part])
- date_expression の date_part 単位での最終日取得する
- デフォルトでは月の最終日
- MySQLにもある関数
例
SELECT LAST_DAY(DATE '2008-11-25') AS last_day
PARSE_DATE(format_string, date_string)
例
SELECT
PARSE_DATE('%F', '2008-12-25') AS date1,
PARSE_DATE('%Y/%m/%d', '2008/12/15') AS date2,
PARSE_DATE('%Y%m%d', CAST(20081215 AS STRING)) AS date3
| date1 |
date2 |
date3 |
| 2008-12-25 |
2008-12-15 |
2008-12-15 |
日時関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/datetime_functions
日付関数 と同様のため説明は省略
タイムスタンプ関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/timestamp_functions#timezone_definitions
日付関数 と同様のため説明は省略
文字列関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/string_functions
- 指定した値(複数可)を 1 つに連結する
- BYTES か、STRING にキャスト可能な型であれば、value にそのまま指定できる
-
連結演算子(||) でも同じことが可能
- MySQLとPostgreSQLにもある関数
例
SELECT
CONCAT('A', '-', 1) AS string1,
'A' || '-' || 1 AS string2,
FORMAT('%s-%d', 'A', 1) AS string3
| string1 |
string2 |
string3 |
| A-1 |
A-1 |
A-1 |
- 文字列型の文字数、バイト型のバイト数を返す
- 文字列のバイト数は BYTE_LENGTH でも可能
- MySQLのLENGTHはバイト単位なので、CHAR_LENGTH相当
- PostgreSQLにもある関数
例
SELECT
characters,
LENGTH(characters) AS string_example,
LENGTH(CAST(characters AS BYTES)) AS bytes_example,
BYTE_LENGTH(characters) AS byte_length_example,
FROM
UNNEST(['abcあ']) AS characters
| characters |
string_example |
bytes_example |
byte_length_example |
| abcあ |
4 |
6 |
6 |
- 文字列/バイトの先頭から指定文字数/バイト数の文字列を返す
例
SELECT LEFT('A001-001-01', 4) as left4
- 文字列/バイトの末尾から指定文字数/バイト数の文字列を返す
例
SELECT RIGHT('A001-001-01', 2) as right2
SUBSTR(value, position[, length])
- value に指定した文字列/バイトの position 文字目から length 文字数/バイト数の文字列を返す
例
SELECT SUBSTR('A001-001-01', 6, 3) as substr_6_3
REPLACE(original_value, from_value, to_value)
- original_value 内に出現するすべての from_value を to_value に置き換える
例
SELECT REPLACE('A001-001-01', '-', '_') as replace_example
| replace_example |
| A001_001_01 |
REGEXP_CONTAINS(value, regexp)
- value が re2正規表現 regexp に対して部分一致である場合にTRUE を返す
例
SELECT
email,
REGEXP_CONTAINS(email, r'^.+@(example\.com|example\.net)$') AS regexp_contains_example
FROM
UNNEST(['foo@example.com', 'bar@example.org', 'baz@example.net']) AS email
REGEXP_EXTRACT(value, regexp[, position[, occurrence]])
-
re2正規表現 regexp と一致する value 内の部分文字列を返す
- 一致がない場合、NULL を返す
- position を指定すると、value のこの位置から検索を開始する(それ以外は先頭から)
- 複数一致する場合は最初の一致を返すが、occurrence でそれ以外も指定可能
- 複数一致する場合に全部取得する場合は REGEXP_EXTRACT_ALL を使うと Array で取得できる
例
SELECT
email,
REGEXP_EXTRACT(email, r'^.*@(.*)$') AS mail_domain
FROM
UNNEST(['foo@example.com', 'bar@example.org', 'baz@example.net']) AS email
REGEXP_REPLACE(value, regexp, replacement)
-
re2正規表現 regexp と一致する value のすべての部分文字列を replacement に置き換えた 文字列を返す
- replacement 引数内でバックスラッシュでエスケープされた数字(\1~\9)を使用してグループと一致するテキストを regexp パターン内に挿入できる(\0 は一致するテキスト全体)
例
SELECT
REGEXP_REPLACE(heading, r'^# ([a-zA-Z0-9\s]+$)', '<h1>\\1</h1>') AS html
FROM
UNNEST(['# Heading', '# Another heading']) AS heading
| html |
| <h1>Heading</h1> |
| <h1>Another heading</h1> |
FORMAT(format_string_expression, data_type_expression[, ...])
- format_string_expressionをdata_type_expressionとしてフォーマットする
- 数値のカンマ区切りや、数値の頭ゼロ埋め等が可能
- C言語 の printf 関数と同様の仕様
- PostgreSQLにもある関数
- MySQLの FORMAT 相当だが引数の指定方法が異なる
例
SELECT
FORMAT("%'d", 123456789) AS format1,
FORMAT("%'+d", 123456789) AS format2,
FORMAT("%03d", 1) AS format3,
FORMAT("%'.3f", 123456789.0) AS format4,
| format1 |
format2 |
format3 |
format4 |
| 123,456,789 |
+123,456,789 |
001 |
123,456,789.000 |
%[flags][width][.precision]specifier
| specifier |
説明 |
| d または i |
10 進の整数 |
| f または F |
整数.小数。大文字小文字は非有限値の表記違い。 |
| s |
文字列 |
| flag |
説明 |
| 0 |
widthが指定されている場合スペースではなく、ゼロ(0)で数字の左側にパディング |
| ' |
10進数の場合はカンマ区切り形式へ |
| + |
正の数値であっても、結果の前にプラス記号またはマイナス記号(+ または -)を強制。デフォルトでは、負の数にのみ - 記号が前に付けられる。 |
数値を指定すると、この数値よりも短い場合、結果は空白スペースを使用してパディングされる。(flagで0指定した場合はゼロ(0)でパディングされる。
小数点の後に出力される桁数を 小数に .数値 で指定できる(デフォルトは6)
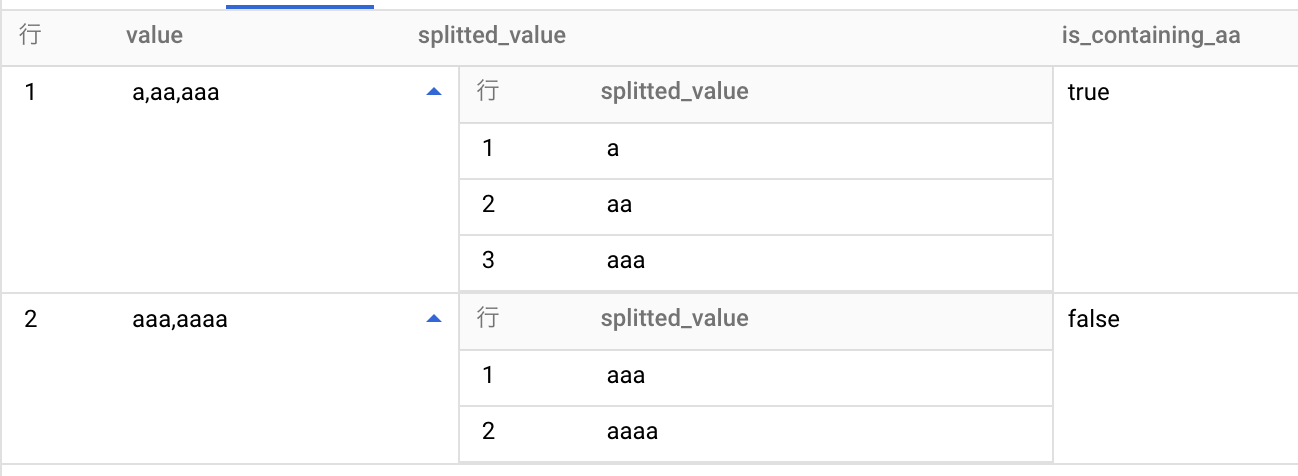
SPLIT(value[, delimiter])
- delimiter 引数を使用して value を分割した Array を返す
例
SELECT
value,
SPLIT(value) as splitted_value,
'aa' IN UNNEST(SPLIT(value)) AS is_containing_aa
FROM
UNNEST(['a,aa,aaa', 'aaa,aaaa']) AS value
TRIM(value_to_trim[, set_of_characters_to_remove])
- 前後の空白を除去する
- set_of_characters_to_remove で空白以外の文字列も指定可能
例
SELECT '#' || TRIM(' aaa ') || '#' as trim_example
NORMALIZE_AND_CASEFOLD(value[, normalization_mode])
-
Unicode正規化された文字列を返す
- 「1」「1」「①」など等価な文字の表記を統一できるのでNLPの前処理などで使う
- 大文字小文字を区別する場合は NORMALIZE を使う
- normalization_mode の違いは難しいが、NFKC を使うケースが多いかと
例
SELECT
value,
NORMALIZE_AND_CASEFOLD(value, NFC) AS NFC,
NORMALIZE_AND_CASEFOLD(value, NFD) AS NFD,
NORMALIZE_AND_CASEFOLD(value, NFKC) AS NFKC,
NORMALIZE_AND_CASEFOLD(value, NFKD) AS NFKD,
LENGTH(value) AS value_length,
LENGTH(NORMALIZE_AND_CASEFOLD(value, NFC)) AS NFC_length,
LENGTH(NORMALIZE_AND_CASEFOLD(value, NFD)) AS NFD_length,
LENGTH(NORMALIZE_AND_CASEFOLD(value, NFKC)) AS NFKC_length,
LENGTH(NORMALIZE_AND_CASEFOLD(value, NFKD)) AS NFKD_length
FROM
UNNEST(['1','1','①','a','A','a','A','ガ','ガ','㈱','(株)','(株)','神','神','㍍']) AS value
| value |
NFC |
NFD |
NFKC |
NFKD |
value_length |
NFC_length |
NFD_length |
NFKC_length |
NFKD_length |
| 1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
| 1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
| ① |
① |
① |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
| a |
a |
a |
a |
a |
1 |
1 |
1 |
1 |
1 |
| A |
a |
a |
a |
a |
1 |
1 |
1 |
1 |
1 |
| a |
a |
a |
a |
a |
1 |
1 |
1 |
1 |
1 |
| A |
a |
a |
a |
a |
1 |
1 |
1 |
1 |
1 |
| ガ |
ガ |
ガ |
ガ |
ガ |
2 |
2 |
2 |
1 |
2 |
| ガ |
ガ |
ガ |
ガ |
ガ |
1 |
1 |
2 |
1 |
2 |
| ㈱ |
㈱ |
㈱ |
(株) |
(株) |
1 |
1 |
1 |
3 |
3 |
| (株) |
(株) |
(株) |
(株) |
(株) |
3 |
3 |
3 |
3 |
3 |
| (株) |
(株) |
(株) |
(株) |
(株) |
3 |
3 |
3 |
3 |
3 |
| 神 |
神 |
神 |
神 |
神 |
1 |
1 |
1 |
1 |
1 |
| 神 |
神 |
神 |
神 |
神 |
1 |
1 |
1 |
1 |
1 |
| ㍍ |
㍍ |
㍍ |
メートル |
メートル |
1 |
1 |
1 |
4 |
4 |
JSON関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/json_functions
下記はレガシーなので利用非推奨
- JSON_EXTRACT
- JSON_EXTRACT_SCALAR
- JSON_EXTRACT_ARRAY
- JSON_EXTRACT_STRING_ARRAY
JSON_VALUE(json_string_expr[, json_path])
JSON_VALUE(json_expr[, json_path])
- JSON文字列又はJSON型の値からスカラー値を抽出する
- 最も外側の引用符を削除し、戻り値のエスケープを解除する
例
SELECT
json_text,
JSON_VALUE(json_text, "$.class.students[0].name") AS student_name,
JSON_VALUE(json_text, "$.class.students") AS students,
FROM
UNNEST(
[
'{"class" : {"students" : [{"name" : "Jane"}]}}',
'{"class" : {"students" : []}}',
'{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}'
]
) json_text
| json_text |
student_name |
students |
| {"class" : {"students" : [{"name" : "Jane"}]}} |
Jane |
(null) |
| {"class" : {"students" : []}} |
(null) |
(null) |
| {"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}} |
John |
(null) |
JSON_QUERY(json_string_expr, json_path)
JSON_QUERY(json_expr, json_path)
- JSON文字列又はJSON型の値からスカラー値以外(配列やオブジェクトなど)の値を抽出する
例
SELECT
json_text,
JSON_QUERY(json_text, "$.class.students[0].name") AS student_name,
JSON_QUERY(json_text, "$.class.students") AS students,
FROM
UNNEST(
[
'{"class" : {"students" : [{"name" : "Jane"}]}}',
'{"class" : {"students" : []}}',
'{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}'
]
) json_text
| json_text |
student_name |
students |
| {"class" : {"students" : [{"name" : "Jane"}]}} |
"Jane" |
[{"name":"Jane"}] |
| {"class" : {"students" : []}} |
(null) |
[] |
| {"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}} |
"John" |
[{"name":"John"},{"name":"Jamie"}] |
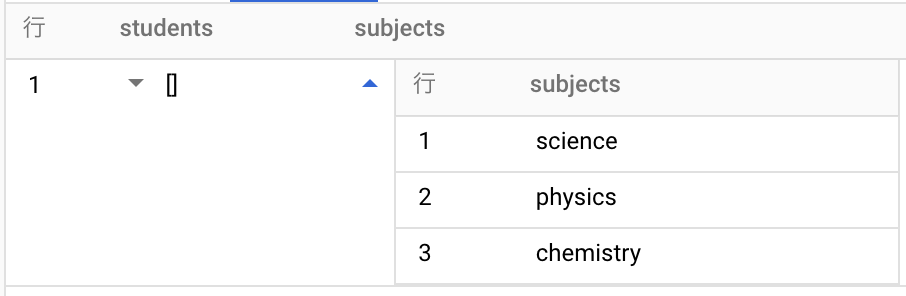
JSON_VALUE_ARRAY(json_string_expr[, json_path])
JSON_VALUE_ARRAY(json_expr[, json_path])
- JSON文字列又はJSON型の値からスカラー値(文字列、数値、またはブール値)の配列を抽出する
例
SELECT
JSON_VALUE_ARRAY(json_text,"$.class.students") AS students,
JSON_VALUE_ARRAY(json_text,"$.class.subjects") AS subjects
FROM
UNNEST(['{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}], "subjects" : ["science","physics","chemistry"]}}']) AS json_text
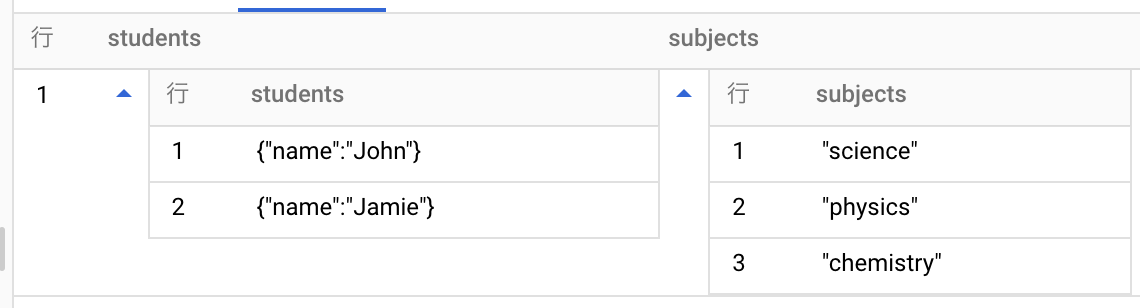
JSON_QUERY_ARRAY(json_string_expr[, json_path])
JSON_QUERY_ARRAY(json_expr[, json_path])
- JSON文字列又はJSON型の値から、配列やオブジェクトなどの JSON 値の配列と、文字列、数値、ブール値などの JSON スカラー値を抽出
例
SELECT
JSON_QUERY_ARRAY(json_text,"$.class.students") AS students,
JSON_QUERY_ARRAY(json_text,"$.class.subjects") AS subjects
FROM
UNNEST(['{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}], "subjects" : ["science","physics","chemistry"]}}']) AS json_text
Net関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/net_functions
URLやIPアドレスを加工するときに便利な関数がある
例
SELECT
url,
NET.HOST(url) AS host,
NET.REG_DOMAIN(url) AS domain,
NET.PUBLIC_SUFFIX(url) AS suffix
FROM
UNNEST(['https://raksul.com/guide/','//novelty.raksul.com/guide/']) AS url
集計関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/aggregate_functions
- ここであげている集計関数は全てOVER句を指定すると分析関数として利用可能
例
抽出元テーブル
| customer_id |
amount |
order_date |
payment_method |
| 1 |
100 |
2008-12-25 |
credit |
| 2 |
200 |
2008-12-25 |
bank |
| 3 |
300 |
2008-12-25 |
credit |
| 1 |
1000 |
2009-12-26 |
credit |
| 2 |
2000 |
2009-12-26 |
bank |
| 3 |
3000 |
2009-12-26 |
credit |
| 1 |
10000 |
2010-12-24 |
invoice |
SELECT
customer_id,
COUNT(*) AS count_order,
COUNT(DISTINCT payment_method) AS count_distinct_payment_method,
SUM(amount) AS sum_amount,
AVG(amount) AS avg_amount,
MIN(order_date) AS min_order_date,
MAX(order_date) AS max_order_date,
STRING_AGG(payment_method) as payment_methods,
COUNT(CASE WHEN payment_method = 'credit' THEN 1 END) as count_credit,
COUNT(IF(payment_method = 'bank', 1, NULL)) as count_bank,
COUNTIF(payment_method = 'invoice') as count_invoice,
SUM(CASE WHEN payment_method = 'credit' THEN amount ELSE 0 END) AS sum_credit_amount,
SUM(IF(payment_method = 'bank', amount, 0)) AS sum_bank_amount,
SUM(IF(payment_method = 'invoice', amount, 0)) AS sum_bank_amount
FROM
UNNEST([
struct(1 AS customer_id, 100 AS amount, DATE '2008-12-25' as order_date, 'credit' as payment_method),
struct(2 AS customer_id, 200 AS amount, DATE '2008-12-25' as order_date, 'bank' as payment_method),
struct(3 AS customer_id, 300 AS amount, DATE '2008-12-25' as order_date, 'credit' as payment_method),
struct(1 AS customer_id, 1000 AS amount, DATE '2009-12-26' as order_date, 'credit' as payment_method),
struct(2 AS customer_id, 2000 AS amount, DATE '2009-12-26' as order_date, 'bank' as payment_method),
struct(3 AS customer_id, 3000 AS amount, DATE '2009-12-26' as order_date, 'credit' as payment_method),
struct(1 AS customer_id, 10000 AS amount, DATE '2010-12-24' as order_date, 'invoice' as payment_method)
]) AS orders
GROUP BY
customer_id
| customer_id |
count_order |
count_distinct_payment_method |
sum_amount |
avg_amount |
min_order_date |
max_order_date |
payment_methods |
count_credit |
count_bank |
count_invoice |
sum_credit_amount |
sum_bank_amount |
sum_bank_amount_1 |
| 1 |
3 |
2 |
11100 |
3700.0 |
2008-12-25 |
2010-12-24 |
credit,credit,invoice |
2 |
0 |
1 |
1100 |
0 |
10000 |
| 2 |
2 |
1 |
2200 |
1100.0 |
2008-12-25 |
2009-12-26 |
bank,bank |
0 |
2 |
0 |
0 |
2200 |
0 |
| 3 |
2 |
1 |
3300 |
1650.0 |
2008-12-25 |
2009-12-26 |
credit,credit |
2 |
0 |
0 |
3300 |
0 |
0 |
COUNT(
[DISTINCT]
expression
)
[OVER (...)]
- COUNT(*) の場合は行数、 expression の場合は NULL 以外の行数を返す
- 条件式(CASEやIF)を使ってNULLにすることで条件付きカウントが可能
- COUNTIF を使うと条件付きカウントをすっきり書ける場合もある
- COUNT(*) は性能悪いので COUNT(0) や COUNT(1) を使うと良いというデマがあるがそんなことはないので COUNT(*) を使うで良い
- DISTINCT を指定すると重複しない値の数を返す
SUM(
[DISTINCT]
expression
)
[OVER (...)]
- NULL 以外の値の合計を返す
- expression に条件式を書くことで条件付き合計が可能
MAX(
expression
)
[OVER (...)]
MIN(
expression
)
[OVER (...)]
AVG(
[DISTINCT]
expression
)
[OVER (...)]
STRING_AGG(
[DISTINCT]
expression [, delimiter]
[ORDER BY key [{ASC|DESC}] [, ... ]]
[LIMIT n]
)
[OVER (...)]
- 非 NULL 値を結合して得られた値(STRING または BYTES のいずれか)を返す
- DISTINCT を指定すると重複を除いた値を集約して結果を返す
- ORDER BY で値の順序を指定できる
- LIMIT で出力数の最大値を指定できる
- mysql の GROUP_CONCAT 相当
ナビゲーション関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/navigation_functions
-
分析関数のサブセット
- 現在の行を基にしてウィンドウ フレーム内の別の行に対していくつかの value_expression が計算される
FIRST_VALUE (value_expression [{RESPECT | IGNORE} NULLS])
- 現在のウィンドウ フレーム内の最初の行の value_expression の値を返す
- IGNORE NULLS を指定すると NULL 値が除外される
LAST_VALUE (value_expression [{RESPECT | IGNORE} NULLS])
- 現在のウィンドウ フレーム内の最後の行の value_expression の値を返す
- IGNORE NULLS を指定すると NULL 値が除外される
- FIRST_VALUE の ORDER BY の ASC/DESC で対応した方がパフォーマンスが良いケースが多い
NTH_VALUE (value_expression, constant_integer_expression [{RESPECT | IGNORE} NULLS])
- 現在のウィンドウ フレーム内の N 番目の行の value_expression の値を返す
- IGNORE NULLS を指定すると NULL 値が除外される
- 先行する 1 つの行の value_expression の値をデフォルトで1つ返す
- offset の値を変更すると、どれだけ後の行が返されるか指定できる
- 指定したオフセットの行がウィンドウ枠内に存在しない場合は、オプションの default_expression が使用さる
LEAD (value_expression[, offset [, default_expression]])
- 後続の 1 つの行の value_expression の値をデフォルトで1つ返す
- offset の値を変更すると、どれだけ後の行が返されるか指定できる
- 指定したオフセットの行がウィンドウ枠内に存在しない場合は、オプションの default_expression が使用さる
PERCENTILE_CONT (value_expression, percentile [{RESPECT | IGNORE} NULLS])
- value_expression に対して指定されたパーセンタイル値を計算
- percentile に 0.5 を指定すると 中央値(Median)となる
- percentile に 0.25 を指定すると 第一四分位となる
- percentile に 0.75 を指定すると 第三四分位となる
番号付け関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/numbering_functions
-
分析関数のサブセット
- 指定されたウィンドウ内の行の位置に基づいて、各行に整数値を割り当てる
- 各パーティションの各行の順位(1開始)を返す
- 同一順位が複数あると、次のランク値がその分飛ぶ
- 各パーティションの各行の順位(1開始)を返す
- 同一順位が複数あても次のランク値は+1だけされる
NTILE(constant_integer_expression)
- ソートしたデータを constant_integer_expression で指定された数のグループに均等にグルーピングする
- デシル分析をする際に便利
統計集計関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/statistical_aggregate_functions
BigQueryの統計処理の関数はそこまで充実していないため、BigQuery上で t検定等したい場合は、UDFで外部JavaScript(Jstatなど)を利用する方法がある
https://lab.mo-t.com/blog/bigquery-udf
CORR ピアソン相関係数
CORR(
X1, X2
)
[OVER (...)]
STDDEV_POP(
[DISTINCT]
expression
)
[OVER (...)]
STDDEV_SAMP(
[DISTINCT]
expression
)
[OVER (...)]
近似集計関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/approximate_aggregate_functions
正確な結果ではなく、近似的な結果だが、性能が良い関数
APPROX_TOP_COUNT(
expression, number
)
- expression の最頻値(MODE)の STRUCT型(value, count)の配列を返す
- number パラメータで、返される要素の数を指定できる
APPROX_TOP_SUM(
expression, weight, number
)
- weight の合計の 最大値 の expression の STRUCT型(value, sum)の配列を返す
- number パラメータで、返される要素の数を指定できる
APPROX_QUANTILES(
[DISTINCT]
expression, number
[{IGNORE|RESPECT} NULLS]
)
- expression の値のグループに対する近似境界の値の配列を返す
- number で作成する変位値の数を指定できる(配列の要素数は number + 1)
- 最初の要素は近似最小値であり、最後の要素は近似最大値
- 中央値は PERCENTILE_CONT(0.5, x) よりも APPROX_QUANTILES(x, 2)[OFFSET(1)] の方が高速
配列関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/array_functions
ARRAY_TO_STRING(array_expression, delimiter[, null_text])
- array_expression 内の要素を delimiter で連結した文字列を返す
- NULL値はデフォルト無視されが、 null_text を指定することもできる
例
WITH items AS (
SELECT ['coffee', 'tea', 'milk' ] as list
UNION ALL
SELECT ['cake', 'pie', NULL] as list
)
SELECT
ARRAY_TO_STRING(list, ',') AS text,
ARRAY_TO_STRING(list, ',', 'NULL') AS text_null
FROM
items
| text |
text_null |
| coffee,tea,milk |
coffee,tea,milk |
| cake,pie |
cake,pie,NULL |
GENERATE_DATE_ARRAY(start_date, end_date[, INTERVAL INT64_expr date_part])
- start_date から end_date のデフォルト1日間隔の日付の配列を返す
- INTERVAL で間隔は指定できる
-
UNNEST と合わせてカレンダーテープルを作る際に便利
例
SELECT
*
FROM
UNNEST(GENERATE_DATE_ARRAY('2016-10-05', '2016-10-08')) AS date
| date |
| 2016-10-05 |
| 2016-10-06 |
| 2016-10-07 |
| 2016-10-08 |
SAFE.接頭辞
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-reference?hl=ja#safe_prefix
- 関数の先頭に SAFE. 接頭辞を付けると、エラーではなく NULL が返される
便利な演算子
関数ではないが使い方を忘れがちな演算子をいくつか
unnest_operator:
{
UNNEST( array_expression )
| UNNEST( array_path )
| array_path
}
[ as_alias ]
[ WITH OFFSET [ as_alias ] ]
as_alias:
[AS] alias
- ARRAY を受け取り、ARRAY 内の各要素を 1 行にしてテーブルを返す
- STRUCT型のARRAYの場合、STRUCT 内の各フィールドについてそれぞれ別個の列が生成される
- WITH OFFSET 句は、オフセット値を含む別の列を返す
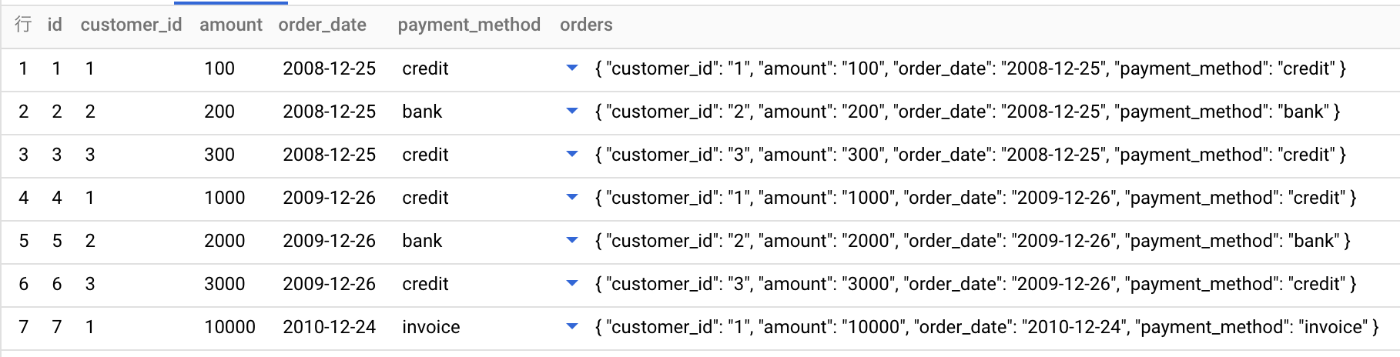
FROM句での利用例
SELECT
offset + 1 as id,
* except(offset),
orders
FROM
UNNEST(ARRAY<STRUCT<customer_id INT64, amount INT64, order_date DATE, payment_method STRING>>[
(1, 100, '2008-12-25', 'credit'),
(2, 200,'2008-12-25', 'bank'),
(3, 300,'2008-12-25', 'credit'),
(1, 1000,'2009-12-26', 'credit'),
(2, 2000,'2009-12-26', 'bank'),
(3, 3000,'2009-12-26', 'credit'),
(1, 10000,'2010-12-24', 'invoice')
]) AS orders WITH OFFSET
IN 演算子での利用例
SELECT
value,
SPLIT(value) as splitted_value,
'aa' IN UNNEST(SPLIT(value)) AS is_containing_aa
FROM
UNNEST(['a,aa,aaa', 'aaa,aaaa']) AS value
ネストされた配列のフラット化例
入力テーブル(nested)
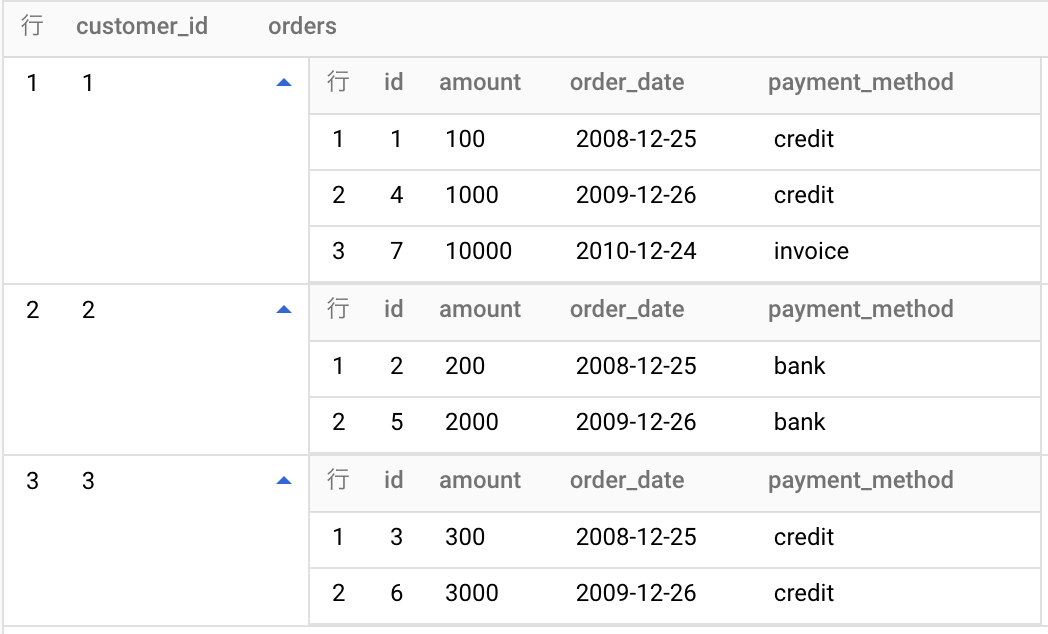
WITH base AS (
SELECT
offset + 1 as id,
* except(offset),
orders
FROM
UNNEST(ARRAY<STRUCT<customer_id INT64, amount INT64, order_date DATE, payment_method STRING>>[
(1, 100, '2008-12-25', 'credit'),
(2, 200,'2008-12-25', 'bank'),
(3, 300,'2008-12-25', 'credit'),
(1, 1000,'2009-12-26', 'credit'),
(2, 2000,'2009-12-26', 'bank'),
(3, 3000,'2009-12-26', 'credit'),
(1, 10000,'2010-12-24', 'invoice')
]) AS orders WITH OFFSET
),
nested AS (
SELECT
customer_id
, ARRAY_AGG(struct(id, amount, order_date, payment_method)) AS orders
FROM
base
GROUP BY
customer_id
)
SELECT
o.id,
n.customer_id,
o.amount,
o.order_date,
o.payment_method
FROM
nested n
CROSS JOIN UNNEST(n.orders) AS o
ORDER BY
o.id
| id |
customer_id |
amount |
order_date |
payment_method |
| 1 |
1 |
100 |
2008-12-25 |
credit |
| 2 |
2 |
200 |
2008-12-25 |
bank |
| 3 |
3 |
300 |
2008-12-25 |
credit |
| 4 |
1 |
1000 |
2009-12-26 |
credit |
| 5 |
2 |
2000 |
2009-12-26 |
bank |
| 6 |
3 |
3000 |
2009-12-26 |
credit |
| 7 |
1 |
10000 |
2010-12-24 |
invoice |
FROM from_item[, ...] pivot_operator
pivot_operator:
PIVOT(
aggregate_function_call [as_alias][, ...]
FOR input_column
IN ( pivot_column [as_alias][, ...] )
) [AS alias]
as_alias:
[AS] alias
- 行を列に変換する
- Rのtidyrのspread, pivot_wider 相当
例
WITH produce AS (
SELECT
*
FROM
UNNEST(ARRAY<STRUCT<product STRING, sales INT64, quarter STRING, year INT64>>[
('Kale',51,'Q1',2020),
('Kale',23,'Q2',2020),
('Kale',45,'Q3',2020),
('Kale',3,'Q4',2020),
('Kale',70,'Q1',2021),
('Kale',85,'Q2',2021),
('Apple',77,'Q1',2020),
('Apple',0,'Q2',2020),
('Apple',1,'Q1',2021)
]) AS produce
)
SELECT
*
FROM
produce
PIVOT(
SUM(sales)
FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4')
)
| product |
year |
Q1 |
Q2 |
Q3 |
Q4 |
| Kale |
2020 |
51 |
23 |
45 |
3 |
| Kale |
2021 |
70 |
85 |
|
|
| Apple |
2020 |
77 |
0 |
|
|
| Apple |
2021 |
1 |
|
|
|
FROM from_item[, ...] unpivot_operator
unpivot_operator:
UNPIVOT [ { INCLUDE NULLS | EXCLUDE NULLS } ] (
{ single_column_unpivot | multi_column_unpivot }
) [unpivot_alias]
single_column_unpivot:
values_column
FOR name_column
IN (columns_to_unpivot)
multi_column_unpivot:
values_column_set
FOR name_column
IN (column_sets_to_unpivot)
values_column_set:
(values_column[, ...])
columns_to_unpivot:
unpivot_column [row_value_alias][, ...]
column_sets_to_unpivot:
(unpivot_column [row_value_alias][, ...])
unpivot_alias and row_value_alias:
[AS] alias
- 列を行に変換する
- Rのtidyrの gather, pivot_longer 相当
例
WITH produce AS (
SELECT
*
FROM
UNNEST(ARRAY<STRUCT<product STRING, sales INT64, quarter STRING, year INT64>>[
('Kale',51,'Q1',2020),
('Kale',23,'Q2',2020),
('Kale',45,'Q3',2020),
('Kale',3,'Q4',2020),
('Kale',70,'Q1',2021),
('Kale',85,'Q2',2021),
('Apple',77,'Q1',2020),
('Apple',0,'Q2',2020),
('Apple',1,'Q1',2021)
]) AS produce
)
, pivoted AS (
SELECT
*
FROM
produce
PIVOT(
SUM(sales)
FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4')
)
)
SELECT
*
FROM
pivoted
UNPIVOT(sales FOR quarter IN (Q1, Q2, Q3, Q4))
| product |
year |
sales |
quarter |
| Kale |
2020 |
51 |
Q1 |
| Kale |
2020 |
23 |
Q2 |
| Kale |
2020 |
45 |
Q3 |
| Kale |
2020 |
3 |
Q4 |
| Kale |
2021 |
70 |
Q1 |
| Kale |
2021 |
85 |
Q2 |
| Apple |
2020 |
77 |
Q1 |
| Apple |
2020 |
0 |
Q2 |
| Apple |
2021 |
1 |
Q1 |

Discussion
追記予定