【Unity】PIXを使って、描画負荷を計測してみる
はじめに
PIXへの理解を深めるため、Unityのソフトシャドウ・ハードシャドウの描画負荷を計測してみました。
環境
OS: Windows 10
CPU: AMD Ryzen 9 3900X 12-Core Processor
GPU: NVIDIA GeForce RTX 2080 Ti
PIX Windows Edition
Version 2208.10
Unity 2021.3.9f1
Built-in Render Pipeline
PIXって何?
PIXを利用することで、ドローコールの中身を詳しく解析することができます。
シェーダーを実行した時に、どれくらいの時間がかかったのかを見ることもできます。
※PIXを利用してプロファイリングを行うには、WindowsプラットフォームでDevelopmentビルドする必要があります。
※モバイルには対応していません。
01. Sphereメッシュを描画
シーンを作成し、カメラの正面にSphereを配置します。

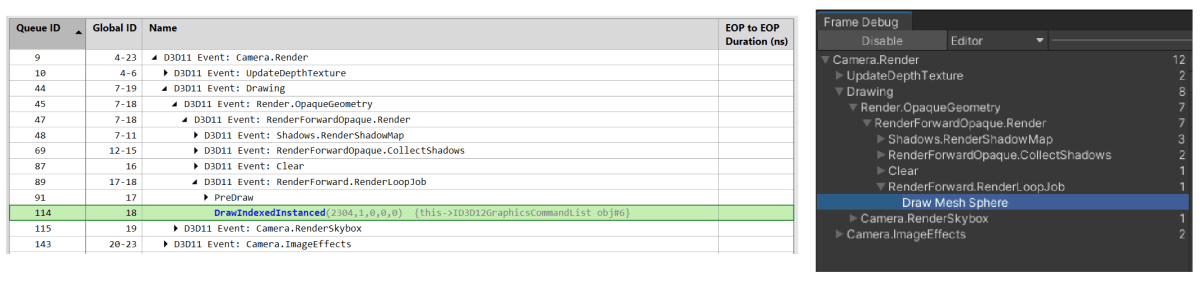
FrameDebuggerを見てみる
UnityのFrame Debuggerを利用して、ドローコールを見てみます。
Draw Mesh Sphere というドローコールにて、Sphereメッシュが描画されています。

PIXでドローコールを見る
次に、PIXを利用してキャプチャーしてみます。
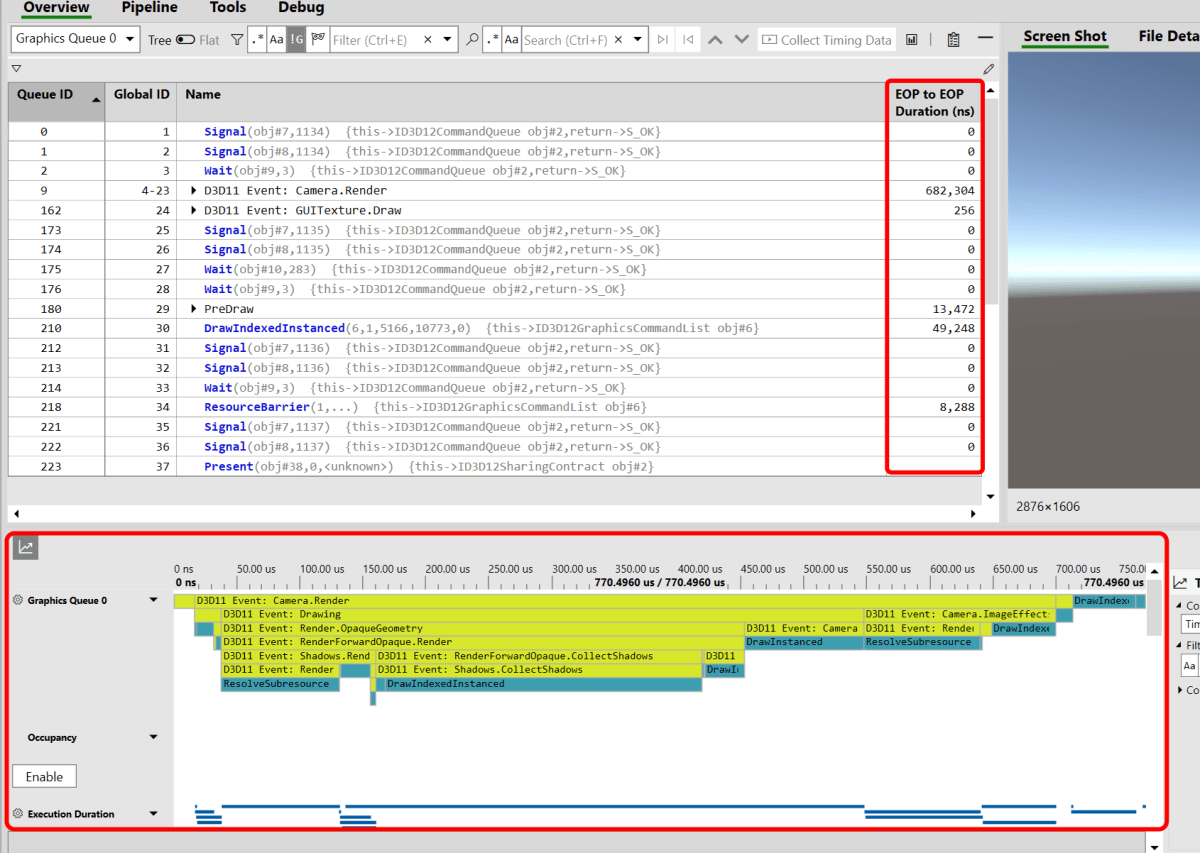
Camera.Renderというドローコールにて、シーンの描画が行われています

球を描画するドローコールを見てみる
RenderForward.RenderLoopJob というドローコールで、球が描画されています。
(Pipelineタブにて、描画の途中経過を見ることができます)
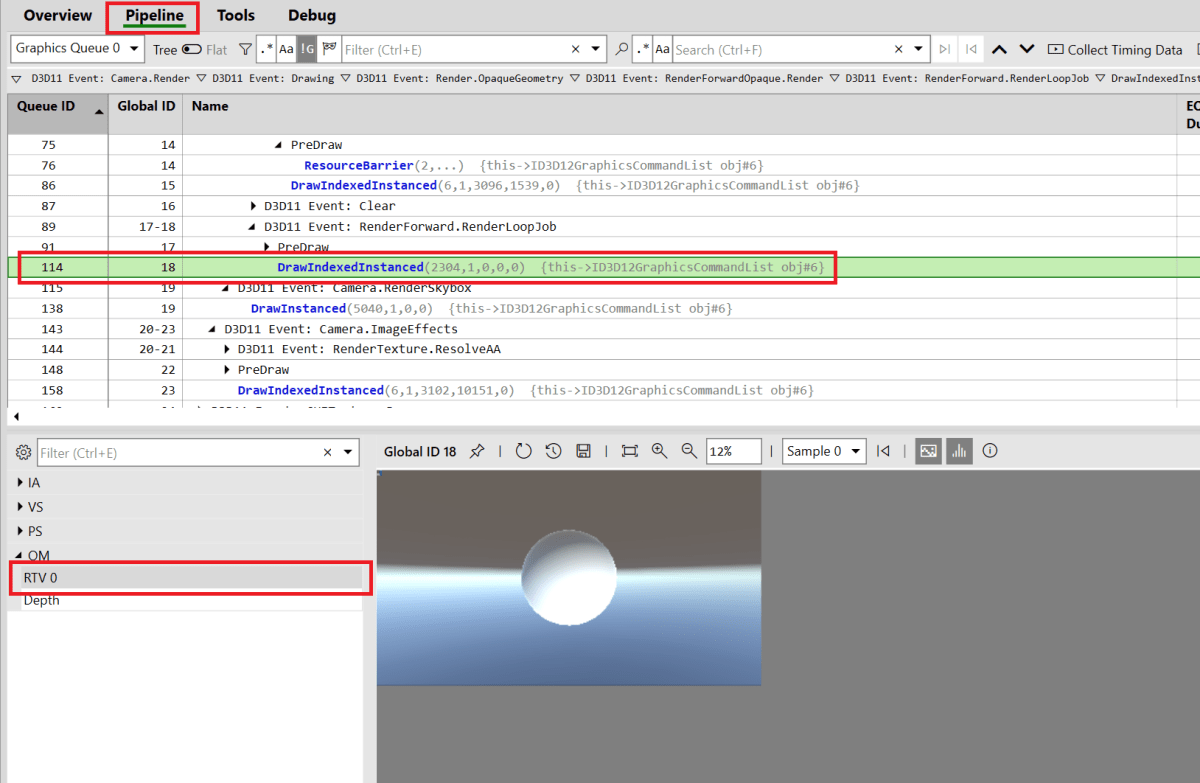
Unityのフレームデバッガー上で見れるドローコールとほぼ同じものがPIX上でも見れることが分かるかと思います。
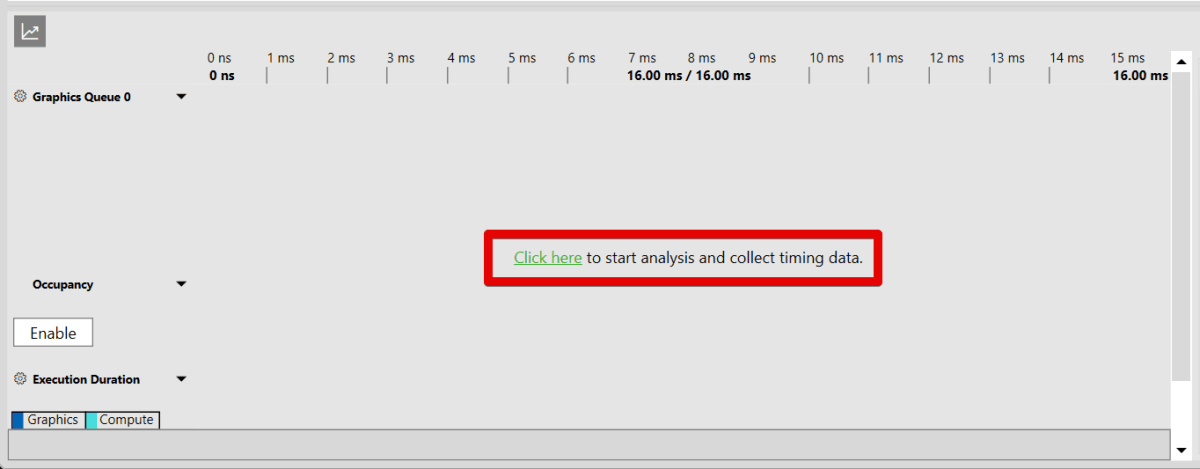
02. PIXで処理負荷を計測する
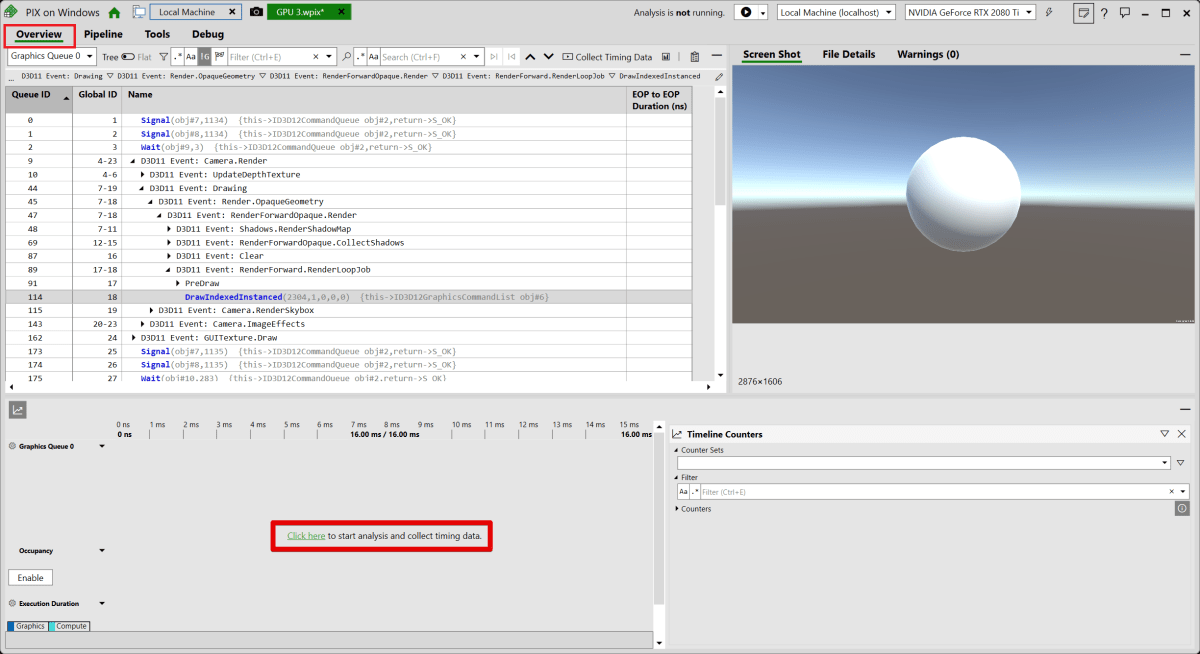
Click-here to start analysis and collect timing data .と書かれた文字をクリックすることで、処理時間を分析することができます。
結果
計測がうまくいくと、ドローコールの処理にかかった時間が表示されます。
PIXでエラーが発生した場合の対策
PIXでエラーが発生した場合の対策
PIXを初めて使用する場合、ほぼ確実にエラーが発生します。
ここでは、エラーの解決方法を紹介します。
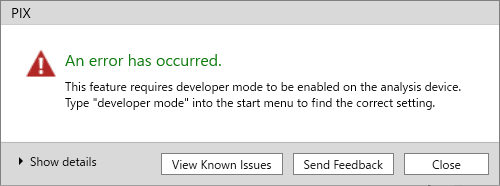
The feature requieres developer mode ~
開発者モードが無効な場合、以下のエラーが出ます。
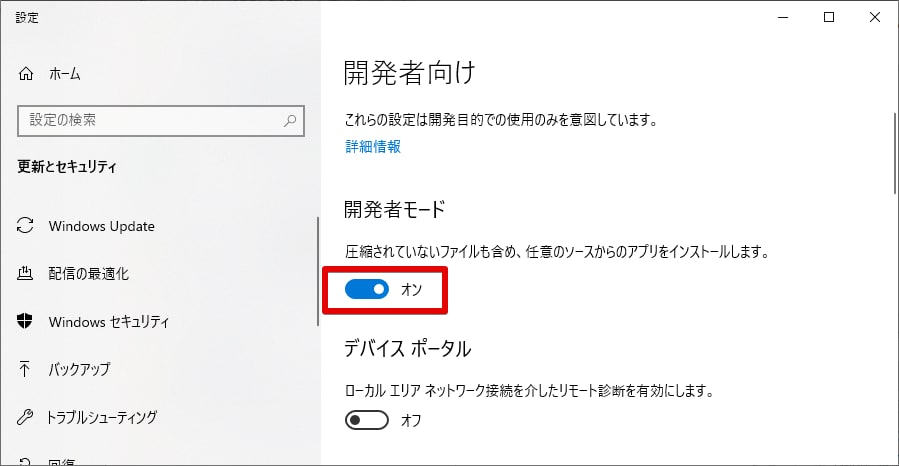
開発者モードをONにする手順
Windowsスタートメニューで、developer mode と入力すると「デバイスの検出を有効にする」
というメニューが出てくるので、これを選択します。

開発者モードを オンにします。
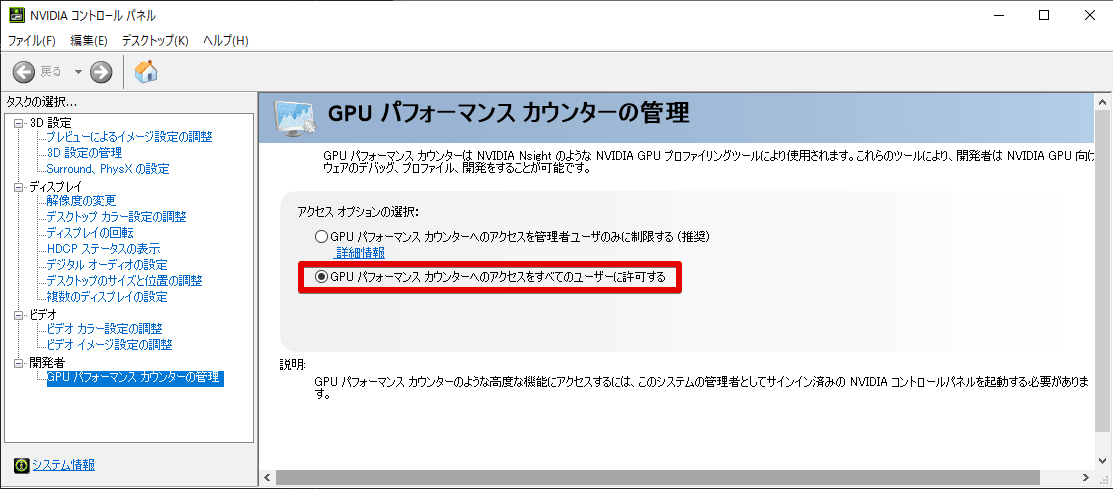
GPU Plugin Initialization Error
GPUパフォーマンスカウンターのアクセスを許可していない場合、以下のエラーが出ることがあります。

GPUパフォーマンスカウンターのアクセスを許可する手順
スタートメニューに「nvidia control panel」と入力し、 NVIDIA Control Panel を選択します。

「GPUパフォーマンス カウンターへのアクセスをすべてのユーザーに許可する」を選んでおきます。
03. 描画の重いところを調査してみる
Camera.Render
Camera.render に 682304ns かかっています。 (0.682 ms)

Camera.renderの中を見てみます。 Drawingが最も重く、0.5ms程かかっています。

処理負荷の比較
全体(Camera.Render)の中で行われている処理が、どれくらいの割合を占めているのかをまとめてみました。
影の描画が特に重いことが分かります。
| ドローコール | 処理時間[ms] | 割合[%] |
|---|---|---|
| D3D11 Event: Camera.Render | 0.682 | 100 |
| D3D11 Event: UpdateDepthTexture | 0.02 | 3.06 |
| D3D11 Event: Shadows.RenderShadowMap | 0.122 | 17.89 |
| D3D11 Event: RenderForwardOpaque.CollectShadows | 0.258 | 37.88 |
| D3D11 Event: RenderForward.RenderLoopJob | 0.03 | 4.75 |
| D3D11 Event: Camera.RenderSkybox | 0.09 | 13.81 |
| D3D11 Event: Camera.ImageEffects | 0.15 | 22.31 |
補足
RenderShadowMap は、シーンに存在する3Dオブジェクトをシャドウマップに描画するドローコールで、
CollectShadows はシャドウマップを参照して、影をスクリーン上に描画するドローコールです。
04. 影の描画負荷を調査する
Unityのプロファイラーを利用して、影の描画が重い原因を探っていきたいと思います。
FrameDebugger を確認する
FrameDebuggerで CollectShadows を見てみましょう。
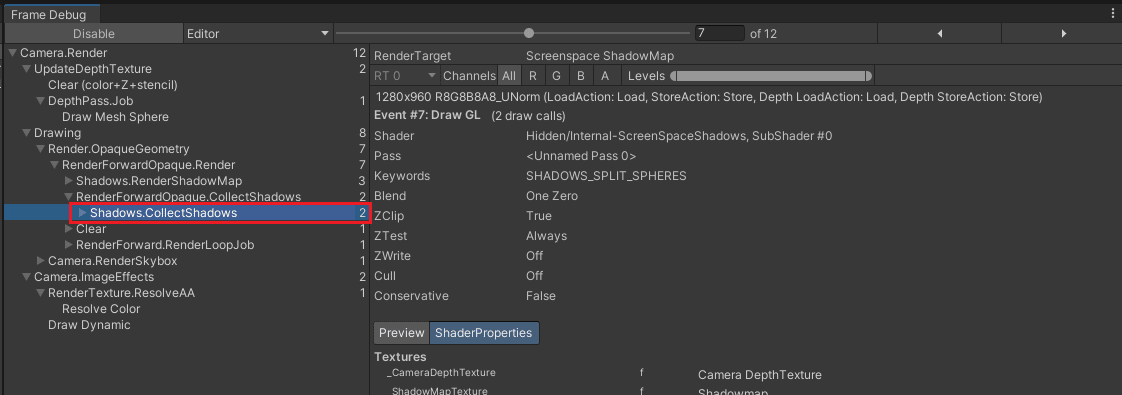
Hidden/Internal-ScreenSpaceShadows の SubShader #2 (3番目のSubShader)が実行されています。
シェーダーキーワードは SHADOWS_SPLIT_SPHERES です。

実行シェーダーを確認してみる
Unity公式から Unity2021.3.9f1 の Built-in Shader をダウンロードし、
Internal-ScreenSpaceShadows.shaderを確認します。
実行されているシェーダーPassは以下になります。(ソフトシャドウの描画を行います)
Subshader {
Tags {"ShadowmapFilter" = "PCF_SOFT"}
Pass {
ZWrite Off ZTest Always Cull Off
CGPROGRAM
#pragma vertex vert
#pragma fragment frag_pcfSoft
#pragma multi_compile_shadowcollector
#pragma target 3.0
inline float3 computeCameraSpacePosFromDepth(v2f i)
{
return computeCameraSpacePosFromDepthAndVSInfo(i);
}
ENDCG
}
}
シェーダーアセンブリを確認する
シェーダーがどれくらい重いのかを確認するため、シェーダーアセンブリを確認してみます。
アセンブリの行数が多いほど、GPU上で多くの処理が実行されます。
Compile and show code ボタンをクリックすることで、シェーダーコンパイルできます。

ピクセルシェーダー(ps_4_0)のアセンブリ行数は144行となりました。
シェーダーコンパイル結果 (D3D)
//////////////////////////////////////////////////////
Keywords: SHADOWS_SPLIT_SPHERES
-- Hardware tier variant: Tier 1
-- Vertex shader for "d3d11":
// Stats: 19 math, 2 temp registers
Uses vertex data channel "Vertex"
Uses vertex data channel "TexCoord0"
Uses vertex data channel "TexCoord1"
Constant Buffer "UnityPerCamera" (144 bytes) on slot 0 {
Vector4 _ProjectionParams at 80
}
Constant Buffer "UnityPerCameraRare" (352 bytes) on slot 1 {
Matrix4x4 unity_CameraInvProjection at 160
}
Constant Buffer "UnityPerDraw" (176 bytes) on slot 2 {
Matrix4x4 unity_ObjectToWorld at 0
}
Constant Buffer "UnityPerFrame" (368 bytes) on slot 3 {
Matrix4x4 unity_MatrixVP at 272
}
Shader Disassembly:
//
// Generated by Microsoft (R) D3D Shader Disassembler
//
//
// Input signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// POSITION 0 xyzw 0 NONE float xyz
// TEXCOORD 0 xy 1 NONE float xy
// TEXCOORD 1 xyz 2 NONE float xyz
//
//
// Output signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_POSITION 0 xyzw 0 POS float xyzw
// TEXCOORD 0 xyzw 1 NONE float xyzw
// TEXCOORD 1 xyz 2 NONE float xyz
// TEXCOORD 2 xyz 3 NONE float xyz
// TEXCOORD 3 xyz 4 NONE float xyz
//
vs_4_0
dcl_constantbuffer CB0[6], immediateIndexed
dcl_constantbuffer CB1[14], immediateIndexed
dcl_constantbuffer CB2[4], immediateIndexed
dcl_constantbuffer CB3[21], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_input v2.xyz
dcl_output_siv o0.xyzw, position
dcl_output o1.xyzw
dcl_output o2.xyz
dcl_output o3.xyz
dcl_output o4.xyz
dcl_temps 2
0: mul r0.xyzw, v0.yyyy, cb2[1].xyzw
1: mad r0.xyzw, cb2[0].xyzw, v0.xxxx, r0.xyzw
2: mad r0.xyzw, cb2[2].xyzw, v0.zzzz, r0.xyzw
3: add r0.xyzw, r0.xyzw, cb2[3].xyzw
4: mul r1.xyzw, r0.yyyy, cb3[18].xyzw
5: mad r1.xyzw, cb3[17].xyzw, r0.xxxx, r1.xyzw
6: mad r1.xyzw, cb3[19].xyzw, r0.zzzz, r1.xyzw
7: mad r0.xyzw, cb3[20].xyzw, r0.wwww, r1.xyzw
8: mov o0.xyzw, r0.xyzw
9: mul r0.y, r0.y, cb0[5].x
10: mul r1.xzw, r0.xxwy, l(0.500000, 0.000000, 0.500000, 0.500000)
11: mul r0.yzw, r0.yyyy, cb1[11].xxyz
12: mad r0.xyz, cb1[10].xyzx, r0.xxxx, r0.yzwy
13: add o1.zw, r1.zzzz, r1.xxxw
14: mov o1.xy, v1.xyxx
15: mov o2.xyz, v2.xyzx
16: add r1.xyz, r0.xyzx, -cb1[12].xyzx
17: add r0.xyz, r0.xyzx, cb1[12].xyzx
18: add r0.xyz, r0.xyzx, cb1[13].xyzx
19: add r1.xyz, r1.xyzx, cb1[13].xyzx
20: mov r1.w, -r1.z
21: mov o3.xyz, r1.xywx
22: mov r0.w, -r0.z
23: mov o4.xyz, r0.xywx
24: ret
// Approximately 0 instruction slots used
-- Hardware tier variant: Tier 1
-- Fragment shader for "d3d11":
// Stats: 113 math, 9 temp registers, 1 textures
Set 2D Texture "_CameraDepthTexture" to slot 0 sampler slot 1
Set 2D Texture "_ShadowMapTexture" to slot 1 sampler slot 0
Constant Buffer "$Globals" (64 bytes) on slot 0 {
Vector4 _ShadowMapTexture_TexelSize at 0
}
Constant Buffer "UnityPerCamera" (144 bytes) on slot 1 {
Vector4 _ZBufferParams at 112
Vector4 unity_OrthoParams at 128
}
Constant Buffer "UnityPerCameraRare" (352 bytes) on slot 2 {
Matrix4x4 unity_CameraToWorld at 288
}
Constant Buffer "UnityShadows" (416 bytes) on slot 3 {
Matrix4x4 unity_WorldToShadow[4] at 128
Vector4 unity_ShadowSplitSpheres[4] at 0
Vector4 unity_ShadowSplitSqRadii at 64
Vector4 _LightShadowData at 384
}
Shader Disassembly:
//
// Generated by Microsoft (R) D3D Shader Disassembler
//
//
// Input signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_POSITION 0 xyzw 0 POS float
// TEXCOORD 0 xyzw 1 NONE float xy
// TEXCOORD 1 xyz 2 NONE float xyz
// TEXCOORD 2 xyz 3 NONE float xyz
// TEXCOORD 3 xyz 4 NONE float xyz
//
//
// Output signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_Target 0 xyzw 0 TARGET float xyzw
//
ps_4_0
dcl_constantbuffer CB0[1], immediateIndexed
dcl_constantbuffer CB1[9], immediateIndexed
dcl_constantbuffer CB2[22], immediateIndexed
dcl_constantbuffer CB3[25], immediateIndexed
dcl_sampler s0, mode_comparison
dcl_sampler s1, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_input_ps linear v1.xy
dcl_input_ps linear v2.xyz
dcl_input_ps linear v3.xyz
dcl_input_ps linear v4.xyz
dcl_output o0.xyzw
dcl_temps 9
0: sample r0.xyzw, v1.xyxx, t0.xyzw, s1
1: mad r0.y, cb1[7].x, r0.x, cb1[7].y
2: div r0.y, l(1.000000, 1.000000, 1.000000, 1.000000), r0.y
3: add r0.z, -r0.y, r0.x
4: mad r0.y, cb1[8].w, r0.z, r0.y
5: add r0.x, -r0.x, l(1.000000)
6: add r1.xyz, -v3.xyzx, v4.xyzx
7: mad r0.xzw, r0.xxxx, r1.xxyz, v3.xxyz
8: mad r0.xzw, -v2.xxyz, r0.yyyy, r0.xxzw
9: mul r1.xyz, r0.yyyy, v2.xyzx
10: mad r0.xyz, cb1[8].wwww, r0.xzwx, r1.xyzx
11: mul r1.xyzw, r0.yyyy, cb2[19].xyzw
12: mad r1.xyzw, cb2[18].xyzw, r0.xxxx, r1.xyzw
13: mad r0.xyzw, cb2[20].xyzw, r0.zzzz, r1.xyzw
14: add r0.xyzw, r0.xyzw, cb2[21].xyzw
15: add r1.xyz, r0.xyzx, -cb3[0].xyzx
16: dp3 r1.x, r1.xyzx, r1.xyzx
17: add r2.xyz, r0.xyzx, -cb3[1].xyzx
18: dp3 r1.y, r2.xyzx, r2.xyzx
19: add r2.xyz, r0.xyzx, -cb3[2].xyzx
20: dp3 r1.z, r2.xyzx, r2.xyzx
21: add r2.xyz, r0.xyzx, -cb3[3].xyzx
22: dp3 r1.w, r2.xyzx, r2.xyzx
23: lt r1.xyzw, r1.xyzw, cb3[4].xyzw
24: movc r2.xyz, r1.xyzx, l(-1.000000,-1.000000,-1.000000,0), l(-0.000000,-0.000000,-0.000000,0)
25: and r1.xyzw, r1.xyzw, l(0x3f800000, 0x3f800000, 0x3f800000, 0x3f800000)
26: add r2.xyz, r2.xyzx, r1.yzwy
27: max r1.yzw, r2.xxyz, l(0.000000, 0.000000, 0.000000, 0.000000)
28: mul r2.xyz, r0.yyyy, cb3[13].xyzx
29: mad r2.xyz, cb3[12].xyzx, r0.xxxx, r2.xyzx
30: mad r2.xyz, cb3[14].xyzx, r0.zzzz, r2.xyzx
31: mad r2.xyz, cb3[15].xyzx, r0.wwww, r2.xyzx
32: mul r2.xyz, r1.yyyy, r2.xyzx
33: mul r3.xyz, r0.yyyy, cb3[9].xyzx
34: mad r3.xyz, cb3[8].xyzx, r0.xxxx, r3.xyzx
35: mad r3.xyz, cb3[10].xyzx, r0.zzzz, r3.xyzx
36: mad r3.xyz, cb3[11].xyzx, r0.wwww, r3.xyzx
37: mad r2.xyz, r3.xyzx, r1.xxxx, r2.xyzx
38: dp4 r1.x, r1.xyzw, l(1.000000, 1.000000, 1.000000, 1.000000)
39: mul r3.xyz, r0.yyyy, cb3[17].xyzx
40: mad r3.xyz, cb3[16].xyzx, r0.xxxx, r3.xyzx
41: mad r3.xyz, cb3[18].xyzx, r0.zzzz, r3.xyzx
42: mad r3.xyz, cb3[19].xyzx, r0.wwww, r3.xyzx
43: mad r2.xyz, r3.xyzx, r1.zzzz, r2.xyzx
44: mul r3.xyz, r0.yyyy, cb3[21].xyzx
45: mad r3.xyz, cb3[20].xyzx, r0.xxxx, r3.xyzx
46: mad r0.xyz, cb3[22].xyzx, r0.zzzz, r3.xyzx
47: mad r0.xyz, cb3[23].xyzx, r0.wwww, r0.xyzx
48: mad r0.xyz, r0.xyzx, r1.wwww, r2.xyzx
49: mad r1.yz, r0.xxyx, cb0[0].zzwz, l(0.000000, 0.500000, 0.500000, 0.000000)
50: round_ni r1.yz, r1.yyzy
51: mad r0.xy, r0.xyxx, cb0[0].zwzz, -r1.yzyy
52: add r0.z, -r1.x, r0.z
53: add r0.z, r0.z, l(1.000000)
54: add r1.xw, -r0.xxxy, l(1.000000, 0.000000, 0.000000, 1.000000)
55: min r2.xy, r0.xyxx, l(0.000000, 0.000000, 0.000000, 0.000000)
56: mad r1.xw, -r2.xxxy, r2.xxxy, r1.xxxw
57: add r1.xw, r1.xxxw, l(2.000000, 0.000000, 0.000000, 2.000000)
58: mul r2.xy, r1.xwxx, l(0.081632, 0.081632, 0.000000, 0.000000)
59: mov r3.y, r2.x
60: max r1.xw, r0.xxxy, l(0.000000, 0.000000, 0.000000, 0.000000)
61: add r4.xyzw, r0.xxyy, l(0.500000, 1.000000, 0.500000, 1.000000)
62: mad r1.xw, -r1.xxxw, r1.xxxw, r4.yyyw
63: mul r4.xyzw, r4.xxzz, r4.xxzz
64: add r1.xw, r1.xxxw, l(2.000000, 0.000000, 0.000000, 2.000000)
65: mul r5.z, r1.x, l(0.081632)
66: mul r6.z, r1.w, l(0.081632)
67: mad r5.yw, r0.xxxx, l(0.000000, -0.081632, 0.000000, 0.081632), l(0.000000, 0.163264, 0.000000, 0.081632)
68: mad r1.xw, r4.xxxz, l(0.500000, 0.000000, 0.000000, 0.500000), -r0.xxxy
69: mul r4.xy, r4.ywyy, l(0.040816, 0.040816, 0.000000, 0.000000)
70: mul r6.xy, r1.wxww, l(0.081632, 0.081632, 0.000000, 0.000000)
71: mov r5.x, r6.y
72: mad r3.xz, r0.xxxx, l(-0.081632, 0.000000, 0.081632, 0.000000), l(0.081632, 0.000000, 0.163264, 0.000000)
73: mov r3.w, r4.x
74: mov r2.w, r4.y
75: add r4.xyzw, r3.xyzw, r5.xyzw
76: div r3.xyzw, r3.xyzw, r4.xyzw
77: add r3.xyzw, r3.xyzw, l(-3.500000, -1.500000, 0.500000, 2.500000)
78: mul r3.xyzw, r3.wxyz, cb0[0].xxxx
79: mad r6.yw, r0.yyyy, l(0.000000, -0.081632, 0.000000, 0.081632), l(0.000000, 0.163264, 0.000000, 0.081632)
80: mad r2.xz, r0.yyyy, l(-0.081632, 0.000000, 0.081632, 0.000000), l(0.081632, 0.000000, 0.163264, 0.000000)
81: add r5.xyzw, r2.xyzw, r6.xyzw
82: div r2.xyzw, r2.xyzw, r5.xyzw
83: add r2.xyzw, r2.xyzw, l(-3.500000, -1.500000, 0.500000, 2.500000)
84: mul r2.xyzw, r2.xwyz, cb0[0].yyyy
85: mul r6.xyzw, r4.xyzw, r5.xxxx
86: mov r7.xzw, r3.yyzw
87: mov r7.y, r2.x
88: mad r8.xyzw, r1.yzyz, cb0[0].xyxy, r7.xyzy
89: sample_c_lz r0.x, r8.xyxx, t1.xxxx, s0, r0.z
90: sample_c_lz r0.y, r8.zwzz, t1.xxxx, s0, r0.z
91: mul r0.y, r0.y, r6.y
92: mad r0.x, r6.x, r0.x, r0.y
93: mad r0.yw, r1.yyyz, cb0[0].xxxy, r7.wwwy
94: mov r3.y, r7.y
95: mad r1.xw, r1.yyyz, cb0[0].xxxy, r3.xxxy
96: sample_c_lz r1.x, r1.xwxx, t1.xxxx, s0, r0.z
97: sample_c_lz r0.y, r0.ywyy, t1.xxxx, s0, r0.z
98: mad r0.x, r6.z, r0.y, r0.x
99: mad r0.x, r6.w, r1.x, r0.x
100: mul r6.xyzw, r4.xyzw, r5.yyyy
101: mov r7.y, r2.z
102: mad r8.xyzw, r1.yzyz, cb0[0].xyxy, r7.xyzy
103: sample_c_lz r0.y, r8.xyxx, t1.xxxx, s0, r0.z
104: sample_c_lz r0.w, r8.zwzz, t1.xxxx, s0, r0.z
105: mad r0.x, r6.x, r0.y, r0.x
106: mad r0.x, r6.y, r0.w, r0.x
107: mad r0.yw, r1.yyyz, cb0[0].xxxy, r7.wwwy
108: mov r3.z, r7.y
109: mad r1.xw, r1.yyyz, cb0[0].xxxy, r3.xxxz
110: sample_c_lz r1.x, r1.xwxx, t1.xxxx, s0, r0.z
111: sample_c_lz r0.y, r0.ywyy, t1.xxxx, s0, r0.z
112: mad r0.x, r6.z, r0.y, r0.x
113: mad r0.x, r6.w, r1.x, r0.x
114: mul r6.xyzw, r4.xyzw, r5.zzzz
115: mul r4.xyzw, r4.xyzw, r5.wwww
116: mov r7.y, r2.w
117: mad r5.xyzw, r1.yzyz, cb0[0].xyxy, r7.xyzy
118: sample_c_lz r0.y, r5.xyxx, t1.xxxx, s0, r0.z
119: sample_c_lz r0.w, r5.zwzz, t1.xxxx, s0, r0.z
120: mad r0.x, r6.x, r0.y, r0.x
121: mad r0.x, r6.y, r0.w, r0.x
122: mad r0.yw, r1.yyyz, cb0[0].xxxy, r7.wwwy
123: mov r2.xzw, r7.xxzw
124: mov r3.w, r7.y
125: mad r1.xw, r1.yyyz, cb0[0].xxxy, r3.xxxw
126: sample_c_lz r1.x, r1.xwxx, t1.xxxx, s0, r0.z
127: sample_c_lz r0.y, r0.ywyy, t1.xxxx, s0, r0.z
128: mad r0.x, r6.z, r0.y, r0.x
129: mad r0.x, r6.w, r1.x, r0.x
130: mad r5.xyzw, r1.yzyz, cb0[0].xyxy, r2.xyzy
131: mad r0.yw, r1.yyyz, cb0[0].xxxy, r2.wwwy
132: mov r3.y, r2.y
133: mad r1.xy, r1.yzyy, cb0[0].xyxx, r3.xyxx
134: sample_c_lz r1.x, r1.xyxx, t1.xxxx, s0, r0.z
135: sample_c_lz r0.y, r0.ywyy, t1.xxxx, s0, r0.z
136: sample_c_lz r0.w, r5.xyxx, t1.xxxx, s0, r0.z
137: sample_c_lz r0.z, r5.zwzz, t1.xxxx, s0, r0.z
138: mad r0.x, r4.x, r0.w, r0.x
139: mad r0.x, r4.y, r0.z, r0.x
140: mad r0.x, r4.z, r0.y, r0.x
141: mad r0.x, r4.w, r1.x, r0.x
142: add r0.y, -cb3[24].x, l(1.000000)
143: mad o0.xyzw, r0.xxxx, r0.yyyy, cb3[24].xxxx
144: ret
// Approximately 0 instruction slots used
05. ハードシャドウの描画負荷を計測する
ハードシャドウは、ソフトシャドウより軽量に動作するそうです。
負荷にどの程度の違いがあるのか気になるので、PIXで描画負荷を計測してみようと思います。

PIXで処理負荷を計測する
PIXを使って処理負荷を計測し、ソフトシャドウとハードシャドウの処理負荷を比較してみます。
Camera.Render
Drawingの処理時間が20%ほど減少しています。(約0.1ms 減少)

CollectShadows に関しては、処理時間が 約50% になっています。(約0.12ms 減少)

シェーダーを見てみる
FrameDebuggerにて、CollectShadowsドローコールを見てみます。
Hidden/Internal-ScreenSpaceShadows の SubShader #0 (最初のSubShader) が実行されていました。

実行されているシェーダーPassは以下になります。(ハードシャドウの描画を行います)
// ----------------------------------------------------------------------------------------
// Subshader for hard shadows:
// Just collect shadows into the buffer. Used on pre-SM3 GPUs and when hard shadows are picked.
SubShader {
Tags{ "ShadowmapFilter" = "HardShadow" }
Pass {
ZWrite Off ZTest Always Cull Off
CGPROGRAM
#pragma vertex vert
#pragma fragment frag_hard
#pragma multi_compile_shadowcollector
inline float3 computeCameraSpacePosFromDepth(v2f i)
{
return computeCameraSpacePosFromDepthAndVSInfo(i);
}
ENDCG
}
}
こちらをシェーダーコンパイルすると、
ピクセルシェーダー(ps_4_0) のアセンブリ行数は54行になります。
ソフトシャドウの場合、アセンブリ行数は144行だったので処理負荷が大幅に軽くなっていると推測できます。
D3Dコンパイル結果
//////////////////////////////////////////////////////
Keywords: SHADOWS_SPLIT_SPHERES
-- Hardware tier variant: Tier 1
-- Vertex shader for "d3d11":
// Stats: 19 math, 2 temp registers
Uses vertex data channel "Vertex"
Uses vertex data channel "TexCoord0"
Uses vertex data channel "TexCoord1"
Constant Buffer "UnityPerCamera" (144 bytes) on slot 0 {
Vector4 _ProjectionParams at 80
}
Constant Buffer "UnityPerCameraRare" (352 bytes) on slot 1 {
Matrix4x4 unity_CameraInvProjection at 160
}
Constant Buffer "UnityPerDraw" (176 bytes) on slot 2 {
Matrix4x4 unity_ObjectToWorld at 0
}
Constant Buffer "UnityPerFrame" (368 bytes) on slot 3 {
Matrix4x4 unity_MatrixVP at 272
}
Shader Disassembly:
//
// Generated by Microsoft (R) D3D Shader Disassembler
//
//
// Input signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// POSITION 0 xyzw 0 NONE float xyz
// TEXCOORD 0 xy 1 NONE float xy
// TEXCOORD 1 xyz 2 NONE float xyz
//
//
// Output signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_POSITION 0 xyzw 0 POS float xyzw
// TEXCOORD 0 xyzw 1 NONE float xyzw
// TEXCOORD 1 xyz 2 NONE float xyz
// TEXCOORD 2 xyz 3 NONE float xyz
// TEXCOORD 3 xyz 4 NONE float xyz
//
vs_4_0
dcl_constantbuffer CB0[6], immediateIndexed
dcl_constantbuffer CB1[14], immediateIndexed
dcl_constantbuffer CB2[4], immediateIndexed
dcl_constantbuffer CB3[21], immediateIndexed
dcl_input v0.xyz
dcl_input v1.xy
dcl_input v2.xyz
dcl_output_siv o0.xyzw, position
dcl_output o1.xyzw
dcl_output o2.xyz
dcl_output o3.xyz
dcl_output o4.xyz
dcl_temps 2
0: mul r0.xyzw, v0.yyyy, cb2[1].xyzw
1: mad r0.xyzw, cb2[0].xyzw, v0.xxxx, r0.xyzw
2: mad r0.xyzw, cb2[2].xyzw, v0.zzzz, r0.xyzw
3: add r0.xyzw, r0.xyzw, cb2[3].xyzw
4: mul r1.xyzw, r0.yyyy, cb3[18].xyzw
5: mad r1.xyzw, cb3[17].xyzw, r0.xxxx, r1.xyzw
6: mad r1.xyzw, cb3[19].xyzw, r0.zzzz, r1.xyzw
7: mad r0.xyzw, cb3[20].xyzw, r0.wwww, r1.xyzw
8: mov o0.xyzw, r0.xyzw
9: mul r0.y, r0.y, cb0[5].x
10: mul r1.xzw, r0.xxwy, l(0.500000, 0.000000, 0.500000, 0.500000)
11: mul r0.yzw, r0.yyyy, cb1[11].xxyz
12: mad r0.xyz, cb1[10].xyzx, r0.xxxx, r0.yzwy
13: add o1.zw, r1.zzzz, r1.xxxw
14: mov o1.xy, v1.xyxx
15: mov o2.xyz, v2.xyzx
16: add r1.xyz, r0.xyzx, -cb1[12].xyzx
17: add r0.xyz, r0.xyzx, cb1[12].xyzx
18: add r0.xyz, r0.xyzx, cb1[13].xyzx
19: add r1.xyz, r1.xyzx, cb1[13].xyzx
20: mov r1.w, -r1.z
21: mov o3.xyz, r1.xywx
22: mov r0.w, -r0.z
23: mov o4.xyz, r0.xywx
24: ret
// Approximately 0 instruction slots used
-- Hardware tier variant: Tier 1
-- Fragment shader for "d3d11":
// Stats: 51 math, 4 temp registers, 1 textures
Set 2D Texture "_CameraDepthTexture" to slot 0 sampler slot 1
Set 2D Texture "_ShadowMapTexture" to slot 1 sampler slot 0
Constant Buffer "UnityPerCamera" (144 bytes) on slot 0 {
Vector4 _ZBufferParams at 112
Vector4 unity_OrthoParams at 128
}
Constant Buffer "UnityPerCameraRare" (352 bytes) on slot 1 {
Matrix4x4 unity_CameraToWorld at 288
}
Constant Buffer "UnityShadows" (416 bytes) on slot 2 {
Matrix4x4 unity_WorldToShadow[4] at 128
Vector4 unity_ShadowSplitSpheres[4] at 0
Vector4 unity_ShadowSplitSqRadii at 64
Vector4 _LightShadowData at 384
}
Shader Disassembly:
//
// Generated by Microsoft (R) D3D Shader Disassembler
//
//
// Input signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_POSITION 0 xyzw 0 POS float
// TEXCOORD 0 xyzw 1 NONE float xy
// TEXCOORD 1 xyz 2 NONE float xyz
// TEXCOORD 2 xyz 3 NONE float xyz
// TEXCOORD 3 xyz 4 NONE float xyz
//
//
// Output signature:
//
// Name Index Mask Register SysValue Format Used
// -------------------- ----- ------ -------- -------- ------- ------
// SV_Target 0 xyzw 0 TARGET float xyzw
//
ps_4_0
dcl_constantbuffer CB0[9], immediateIndexed
dcl_constantbuffer CB1[22], immediateIndexed
dcl_constantbuffer CB2[25], immediateIndexed
dcl_sampler s0, mode_comparison
dcl_sampler s1, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_input_ps linear v1.xy
dcl_input_ps linear v2.xyz
dcl_input_ps linear v3.xyz
dcl_input_ps linear v4.xyz
dcl_output o0.xyzw
dcl_temps 4
0: sample r0.xyzw, v1.xyxx, t0.xyzw, s1
1: mad r0.y, cb0[7].x, r0.x, cb0[7].y
2: div r0.y, l(1.000000, 1.000000, 1.000000, 1.000000), r0.y
3: add r0.z, -r0.y, r0.x
4: mad r0.y, cb0[8].w, r0.z, r0.y
5: add r0.x, -r0.x, l(1.000000)
6: add r1.xyz, -v3.xyzx, v4.xyzx
7: mad r0.xzw, r0.xxxx, r1.xxyz, v3.xxyz
8: mad r0.xzw, -v2.xxyz, r0.yyyy, r0.xxzw
9: mul r1.xyz, r0.yyyy, v2.xyzx
10: mad r0.xyz, cb0[8].wwww, r0.xzwx, r1.xyzx
11: mul r1.xyzw, r0.yyyy, cb1[19].xyzw
12: mad r1.xyzw, cb1[18].xyzw, r0.xxxx, r1.xyzw
13: mad r0.xyzw, cb1[20].xyzw, r0.zzzz, r1.xyzw
14: add r0.xyzw, r0.xyzw, cb1[21].xyzw
15: add r1.xyz, r0.xyzx, -cb2[0].xyzx
16: dp3 r1.x, r1.xyzx, r1.xyzx
17: add r2.xyz, r0.xyzx, -cb2[1].xyzx
18: dp3 r1.y, r2.xyzx, r2.xyzx
19: add r2.xyz, r0.xyzx, -cb2[2].xyzx
20: dp3 r1.z, r2.xyzx, r2.xyzx
21: add r2.xyz, r0.xyzx, -cb2[3].xyzx
22: dp3 r1.w, r2.xyzx, r2.xyzx
23: lt r1.xyzw, r1.xyzw, cb2[4].xyzw
24: movc r2.xyz, r1.xyzx, l(-1.000000,-1.000000,-1.000000,0), l(-0.000000,-0.000000,-0.000000,0)
25: and r1.xyzw, r1.xyzw, l(0x3f800000, 0x3f800000, 0x3f800000, 0x3f800000)
26: add r2.xyz, r2.xyzx, r1.yzwy
27: max r1.yzw, r2.xxyz, l(0.000000, 0.000000, 0.000000, 0.000000)
28: mul r2.xyz, r0.yyyy, cb2[13].xyzx
29: mad r2.xyz, cb2[12].xyzx, r0.xxxx, r2.xyzx
30: mad r2.xyz, cb2[14].xyzx, r0.zzzz, r2.xyzx
31: mad r2.xyz, cb2[15].xyzx, r0.wwww, r2.xyzx
32: mul r2.xyz, r1.yyyy, r2.xyzx
33: mul r3.xyz, r0.yyyy, cb2[9].xyzx
34: mad r3.xyz, cb2[8].xyzx, r0.xxxx, r3.xyzx
35: mad r3.xyz, cb2[10].xyzx, r0.zzzz, r3.xyzx
36: mad r3.xyz, cb2[11].xyzx, r0.wwww, r3.xyzx
37: mad r2.xyz, r3.xyzx, r1.xxxx, r2.xyzx
38: dp4 r1.x, r1.xyzw, l(1.000000, 1.000000, 1.000000, 1.000000)
39: mul r3.xyz, r0.yyyy, cb2[17].xyzx
40: mad r3.xyz, cb2[16].xyzx, r0.xxxx, r3.xyzx
41: mad r3.xyz, cb2[18].xyzx, r0.zzzz, r3.xyzx
42: mad r3.xyz, cb2[19].xyzx, r0.wwww, r3.xyzx
43: mad r2.xyz, r3.xyzx, r1.zzzz, r2.xyzx
44: mul r3.xyz, r0.yyyy, cb2[21].xyzx
45: mad r3.xyz, cb2[20].xyzx, r0.xxxx, r3.xyzx
46: mad r0.xyz, cb2[22].xyzx, r0.zzzz, r3.xyzx
47: mad r0.xyz, cb2[23].xyzx, r0.wwww, r0.xyzx
48: mad r0.xyz, r0.xyzx, r1.wwww, r2.xyzx
49: add r0.z, -r1.x, r0.z
50: add r0.z, r0.z, l(1.000000)
51: sample_c_lz r0.x, r0.xyxx, t1.xxxx, s0, r0.z
52: add r0.y, -cb2[24].x, l(1.000000)
53: mad o0.xyzw, r0.xxxx, r0.yyyy, cb2[24].xxxx
54: ret
// Approximately 0 instruction slots used
Discussion