sakana.aiのAIサイエンティストを完全に理解する
🧪 AI Scientist: 全自動オープンエンド型科学的発見に向けて
著者: Sakana AI、Foerster Lab for AI Research(オックスフォード大学)、Jeff Clune、Cong Lu(ブリティッシュコロンビア大学)
📚 研究の背景と目的
AIを使用して科学研究プロセス全体を自動化し、新たな知識を発見することを目指しています。
- 現在のAIモデルは人間の科学者を補助する能力を持っていますが、完全な自動化には至っていません。
- この研究では、機械学習研究に特化した完全自動の科学的発見システムを提案しています。
🔬 提案手法: AI Scientist
AI Scientistは、研究のアイデア生成から論文執筆、そしてピアレビューまでを完全に自動化するシステムです。
主要コンポーネント:
- アイデア生成: 既存のトピックをもとに新しい研究方向を考案
- 実験の反復: 提案されたアイデアを実装し、結果を可視化
- 論文執筆: LaTeX形式で学術論文を作成
- 自動ピアレビュー: 生成された論文を評価し、フィードバックを提供
🧪 実験設定と評価方法
AI Scientistは機械学習の様々な分野で研究を行い、その成果を自動的に評価します。
- 拡散モデル、トランスフォーマー、グロッキングなどの分野で研究を実施
- 生成された論文は、トップレベルの機械学習会議の基準に基づいて自動評価
- 1論文あたりの生成コストは約15ドルと効率的
📊 主な結果と性能比較
AI Scientistは、人間の研究者に近い品質の論文を生成し、新規性のある貢献を示しました。
| 生成論文の例 | 評価結果 |
|---|---|
| DualScale Diffusion: 低次元生成モデルの適応的特徴バランシング | 新規性のある貢献 |
| StyleFusion: 文字レベル言語モデルにおける適応的マルチスタイル生成 | 興味深いアプローチ |
| Q学習を通じたトランスフォーマーの適応的学習率 | 革新的なアイデア |
🚀 結論と将来の展望
AI Scientistは科学的発見の新時代の幕開けを示唆していますが、同時に倫理的な課題も提起しています。
- 研究プロセスの完全自動化による科学の民主化と加速化の可能性
- 自動生成された論文や査読の透明性確保の必要性
- AI研究者の役割の変化と、より高度な創造性への注力
- パラダイムシフトを起こすようなアイデアの自動生成は今後の課題
AI 科学者は科学的発見をどのように自動化するか?
AI科学者は、科学的発見を自動化するために、**「AIサイエンティスト」**と呼ばれる包括的なフレームワークを使用します。 このフレームワークは、**最先端の大規模言語モデル(LLM)**を活用して、人間が介入することなく、研究の実施と新しい知識の発見を可能にすることを目指しています。
AI科学者がどのように科学的発見を自動化するかのステップを以下に示します。
- アイデアの創出: AIサイエンティストは、提供された初期コードテンプレートと、過去の発見のアーカイブに基づいて、新しい研究の方向性を「ブレーンストーミング」します。 進化的計算とオープンエンド性研究に触発されたこのプロセスでは、LLMを使用して、興味深さ、新規性、実現可能性の評価指標とともに、説明、実験実行計画を含むアイデアのアーカイブを反復的に拡張します。 Semantic Scholar APIとウェブアクセスを使用して、既存の文献と類似しているアイデアを破棄することで、新規性を保証します。
- 実験の反復: AIサイエンティストは、提案されたアイデアに基づいて、自動コーディングアシスタント「Aider」を使用して、実験の計画と実行、結果の視覚化を行います。 このプロセスには、コードの記述、実験の実行、結果の記録、Pythonを使用した論文用図の作成が含まれます。 各実験の結果に基づいて、AIサイエンティストは後続の実験を再計画および実装し、このプロセスを最大5回繰り返します。
- 論文の執筆: AIサイエンティストは、標準的な機械学習会議議事録のスタイルで、進捗状況を簡潔かつ有益に記述した論文を作成します。 このプロセスには、実験ノートとプロットに基づいたセクションごとのテキスト生成、Semantic Scholar APIを使用した関連する参考文献のウェブ検索、情報の重複を排除するための自己反映、およびLaTeXコンパイラを使用した論文のコンパイルが含まれます。
- 自動化された論文査読: AIサイエンティストは、生成された論文の質を評価するために、LLMベースの査読プロセスを採用しています。 このプロセスでは、GPT-4oベースのエージェントを使用して、論文のPDF原稿を処理し、健全性、表現、貢献度、全体、信頼性に関する数値スコア、長所と短所のリスト、および予備的なバイナリ決定(採択または却下)を生成します。 この自動査読プロセスは、人間の査読者と同様のフィードバックを提供し、将来の研究の質を向上させるために使用できます。
AIサイエンティストは、機械学習研究の科学的発見プロセスを自動化するための有望な最初のステップを表していますが、その機能には限界があります。 以下に制限の一部を示します。
- 自動査読者の制限: 既存のデータセットの使用、反論段階での著者に質問する機能の欠如、および図を視覚化する能力の欠如。
- 一般的な失敗モード: 結果の記述と評価における重大なエラーが発生する可能性、結果のごまかし、事実のごまかし、およびコード実行中の安全性の懸念。
AI科学者は、AIの研究プロセスを自動化するために、どの様な技術やフレームワークを活用しているのか?
活用される技術とフレームワーク
- 大規模言語モデル(LLM): AIサイエンティストは、その中核となる機能のために、自己回帰型LLMに大きく依存しています。LLMは、膨大なテキストデータで学習され、前のトークン(単語のようなもの)が与えられた場合の新しいトークンの条件付き確率をモデル化することで、テキスト補完の生成を学習します。この学習プロセスにより、LLMは一貫性のあるテキストを生成できるだけでなく、常識的な知識、推論、コードの記述など、人間のような能力を発揮することができます。
-
LLMエージェントフレームワーク: AIサイエンティストは、LLMを「エージェント」フレームワークに統合することで、その能力をさらに高めています。このフレームワークには、LLMのパフォーマンス、堅牢性、信頼性を向上させるために、以下のような技術が含まれます。
- 数ショットプロンプティング: これは、LLMにタスクの例をいくつか(通常は3~5個)与え、出力形式を学習させる手法です。
- 思考の連鎖(CoT): この手法は、LLMに段階的な推論プロセスを生成させ、最終的な回答に導くように促します。これにより、複雑な問題に対するLLMの推論能力が向上します。
- 自己反映: この手法は、LLMが自分の出力を評価し、改善を繰り返すことを可能にします。これにより、LLMの出力の品質と信頼性が向上します。
- 自動コーディングアシスタント「Aider」: AIサイエンティストは、実験の計画、コードの記述、実行、結果の記録に、Aiderという最先端のコーディングアシスタントを使用しています。Aiderは、LLMを使用して、自然言語の指示からコードを生成、分析、変更、評価することができます。AIサイエンティストは、Aiderの機能を活用することで、実験プロセスを自動化し、複雑なコードベースを処理することができます。
- Semantic Scholar API: AIサイエンティストは、Semantic Scholar APIを使用して、アイデアの生成と論文の執筆における文献検索を行います。このAPIにより、AIサイエンティストは関連する既存の研究を特定し、生成されたアイデアの新規性を評価し、論文の関連作業セクションの参考文献を収集することができます。この機能により、AIサイエンティストが現在の研究状況を認識し、重複を避け、その発見を適切に位置づけることが保証されます。
- LaTeXコンパイラ: AIサイエンティストは、LaTeXコンパイラを使用して、生成された研究論文をコンパイルし、標準的な機械学習会議の議事録のスタイルでフォーマットします。 LaTeXは、科学文書の作成に広く使用されている文書作成システムであり、AIサイエンティストが、他の研究者が容易にアクセス、評価、検証できる、構造化され、フォーマットされた科学論文を作成することを可能にします。
AIサイエンティストが提案する論文の質を評価するために、どのような基準が用いられていますか?
- LLMベースのレビュープロセス: ソースは、AIサイエンティストが生成した論文を評価するために、LLMベースのレビュープロセスが設計および検証されたことを示しています。
- 人間の査読者の基準を模倣する: ソース[2、17]によると、この自動化されたレビュープロセスは、標準的な機械学習会議で現在行われている慣行に基づいており、人間の査読者が使用する基準と同様のフィードバックを提供することを目指しています。 たとえば、ソースのレビュープロンプトには、「##レビューフォーム以下は、各論文のレビューフォームで質問される質問と、これらの質問に回答する際に考慮すべきガイドラインの説明です。決定が下された後、レビューとメタレビューが公開されることに注意してください。承認された論文とオプトインされた拒否された論文のうち。」
- GPT-4oの使用: このプロセスでは、GPT-4oなどのLLMを使用して、送信された論文のPDF原稿が処理されます[2、7、8]。
-
評価されるキーエリア: レビュープロセスでは、次の側面の数値スコアが生成されます。
- 健全性: 研究の厳密さと妥当性。
- プレゼンテーション: 論文の明確さ、構成、全体的なプレゼンテーション。
- 貢献: この分野への研究の潜在的な影響と重要性。
- 全体: 論文の全体的な印象と評価。
- 信頼性: 提示された結果と結論の信頼性と再現性。
- 追加のフィードバック: 数値スコアに加えて、レビュープロセスでは、論文の長所と短所、改善のための具体的な提案、および却下の理由に関する洞察も提供されます。
- 人間のレビューとの比較: ソースは、自動化されたレビューシステムが、ICLR 2022 OpenReviewデータで評価した場合、バランスの取れた精度(65%対66%)など、複数の人間の評価基準全体で人間レベルのパフォーマンスを達成することを示しています。
AIサイエンティストはどのように論文の査読を自動化しているか?
AIサイエンティストは、LLMベースのレビュープロセスを通じて論文の査読を自動化します。このプロセスは、人間の査読者が使用する基準を模倣しており、標準的な機械学習会議で現在行われている慣行に基づいています。
このプロセスでは、まず、AIサイエンティストが生成した論文のPDF原稿を、GPT-4oなどの大規模言語モデル(LLM)に提供します。LLMは、この原稿を処理し、論文の様々な側面を評価します。
具体的には、LLMは以下の基準に基づいて論文を評価します。
- 健全性: 研究の厳密さと妥当性。
- プレゼンテーション: 論文の明確さ、構成、全体的なプレゼンテーション。
- 貢献: この分野への研究の潜在的な影響と重要性。
- 全体: 論文の全体的な印象と評価。
- 信頼性: 提示された結果と結論の信頼性と再現性。
各基準に対して、LLMは数値スコアを生成します。これにより、論文の質を定量的に評価することができます。
さらに、LLMは数値スコアだけでなく、論文の長所と短所、改善のための具体的な提案、却下の理由に関する洞察も提供します。これらのフィードバックは、論文の改善に役立つだけでなく、AIサイエンティスト自身の学習にも役立ちます。
ソースによると、この自動化されたレビューシステムは、ICLR 2022 OpenReviewデータで評価した場合、人間の査読者と同様のパフォーマンスを達成することが示されています。具体的には、バランスの取れた精度において、人間の査読者が66%だったのに対し、AIサイエンティストのレビューシステムは65%を達成しました。
AIサイエンティストは、論文の評価にLLMを使用する際、どのような課題に直面しているのか?
- バイアスの問題: ソースは、LLMによる判断にはバイアスが存在する可能性があり、これは論文の面白さ、実現可能性、新規性に対する過大評価に見られる可能性があると指摘しています。このバイアスは、LLMの学習データに偏りがあるために生じる可能性があります。例えば、特定の種類の研究や特定の著者の論文が学習データに多く含まれている場合、LLMはそれらの研究や著者の論文を高く評価する傾向が出てしまう可能性があります。
- 解釈可能性の欠如: LLMは、その判断の根拠を人間が理解しやすい形で示すことができません。これは、LLMがブラックボックスであるために起こります。つまり、LLMがどのように判断を下しているのか、その内部のメカニズムは不明瞭です。このため、LLMがなぜ特定の論文を高く評価し、他の論文を低く評価したのかを理解することが困難な場合があります。
- 図の解釈の難しさ: ソースによると、現在のAIサイエンティストは、図を解釈したり、著者に質問をしたりすることができません。これは、LLMがテキストデータを中心に学習しているため、画像データの処理が苦手であることが原因と考えられます。論文に含まれる図表は、研究結果を理解するために重要な役割を果たすことが多いため、AIサイエンティストが図表を解釈できないことは、論文評価の精度を低下させる可能性があります。
- 新しいアイデアの評価の難しさ: AIサイエンティストは、既存の研究に基づいて学習したLLMを使用しているため、真に斬新なアイデアを含む論文を正しく評価することが難しい可能性があります。真に斬新なアイデアは、既存の研究とは大きく異なるため、LLMはそれらのアイデアを理解することができず、低く評価してしまう可能性があります。
これらの課題を克服するために、以下の様な対策が考えられます。
- バイアスの軽減: LLMの学習データの偏りを減らすために、より多様で網羅的なデータセットを使用することが考えられます。また、バイアスを検出するための技術を開発し、LLMの出力結果を補正することも有効です。
- 解釈可能性の向上: LLMの判断根拠を説明可能なAI技術を開発することで、LLMのブラックボックス問題を解決することができます。これにより、LLMがなぜ特定の論文を高く評価したのかを理解することが容易になり、AIサイエンティストの信頼性向上につながります。
- 画像処理能力の向上: LLMに画像処理能力を付与するために、画像データとテキストデータを組み合わせたマルチモーダル学習を進めることが考えられます。これにより、AIサイエンティストは論文中の図表を解釈できるようになり、より正確な評価が可能になります。
- 人間の査読者との協働: 真に斬新なアイデアを含む論文を評価するために、AIサイエンティストと人間の査読者が協働するシステムを構築することが考えられます。AIサイエンティストは、論文の形式的なチェックや既存の研究との関連性の評価を行い、人間の査読者は、論文の新規性や重要性を評価します。
AIサイエンティストは、論文の査読を自動化する際に、どのようなLLMを活用しているか?
- GPT-4o: ソースでは、論文評価にGPT-4oを用いることで、ICLR 2022 OpenReviewデータセットにおいて人間に近い精度のレビューを生成できたと報告されています。具体的には、GPT-4oを用いたAI Scientistのレビュープロセスは、全体的な精度で70%を達成しました。これは、NeurIPS 2021の整合性実験で報告された人間の精度73%よりも低い数値ですが、AIレビューアーは、人間の精度を上回るF1スコア(0.57対0.49)と、人間と同等のAUC(どちらも0.65)を達成しています。
- Claude Sonnet 3.5: ソースでは、Claude Sonnet 3.5がAI Scientistによって生成された論文の中で最も質の高い論文をコンスタントに生成すると述べられています。ただし、Claude Sonnet 3.5が常に優れているという根拠はなく、他の最先端LLMも進化し続けると予想されています。
- DeepSeek Coder: ソースでは、DeepSeek Coderが論文生成に使用されたことが示唆されています。
- Llama 3.1 405B: ソースによると、Llama 3.1 405Bはレビューの出力テンプレートに一貫して従うのに苦労したため、論文評価にはあまり適していない可能性があります。
AIサイエンティストのプロンプトの例
AIサイエンティストのアーキテクチャとプロンプト
AIサイエンティストは、アイデア生成、実験の実行、関連研究の検索、包括的な論文の作成という、科学的発見プロセスを完全に自動化することを目的としたフレームワークです。この自動化されたシステムを実現するために、AIサイエンティストは、プロンプトと呼ばれる指示を用いてLLMと対話します。プロンプトは、AIサイエンティストが各タスクを実行するために必要な情報をLLMに提供する役割を果たします。
AIサイエンティストのプロンプトの例
- アイデア生成のプロンプト: ソースは、アイデア生成に使用されるプロンプトの例を示しています。このプロンプトは、AIエージェントに対して「野心的なAI博士課程の学生」という役割を与え、与えられたコードを使用して調査可能な実験のアイデアを生成するように指示します。また、以前のアイデアも提供され、新しいアイデアが既存のアイデアと異なることを保証します。
- 新規性の確認のプロンプト: ソースは、アイデアの新規性を確認するためのプロンプトの例を示しています。このプロンプトでは、AIエージェントはSemantic Scholar APIを使用して文献を調査し、既存の研究との重複がないか確認します。
- 論文執筆のプロンプト: ソースは、論文執筆に使用されるプロンプトの例を示しています。このプロンプトでは、AIエージェントは生成されたアイデア、実験結果、関連研究に基づいて論文を自動生成します。
- 論文レビューのプロンプト: ソースは、論文レビューのプロンプトの例も示しています。このプロンプトでは、AIエージェントは他のAIエージェントによって書かれた論文を評価し、改善点などをフィードバックします。
AI Scientist で生成された論文を人間の専門家によって評価した場合、自動評価と比較してどのような違いが見られるのか、その理由を考察せよ。
- ドメイン知識に基づいた評価: 人間の専門家は、AI Scientistがまだ持ち合わせていない特定分野の深い知識を持っています。例えば、ソースでは、人間の専門家は拡散モデルに関するドメイン知識に基づいて、AI Scientistが生成した論文のアイデアの妥当性や実験結果の解釈の正確さを判断しています。一方、自動評価は、事前に定義された評価基準や学習データに基づいて評価を行うため、ドメイン知識を必要とするような深いレベルでの評価は難しいと言えるでしょう。
- 論文全体の構成や論理展開: 自動評価は、個々の文の文法や論文の構成要素が適切かどうかを判断できますが、論文全体を通しての論理展開や主張の一貫性、新規性などを人間の専門家のように評価することは困難です。人間は、自身の経験や知識に基づいて、論文の論理展開に無理がないか、主張が首尾一貫しているか、既存の研究と比較して新規性や有用性があるかなどを総合的に判断することができます。
- 潜在的な問題点や改善点の指摘: ソースにあるように、人間の専門家は、自動評価では見落とされる可能性のある論文の潜在的な問題点や改善点を指摘できる可能性があります。例えば、AI Scientistが提案する手法が、既存の手法と比較して実際に優れているのか、あるいは特定の条件下でのみ有効なのかなど、より詳細な分析や考察を求めることがあります。人間の専門家は、自身の経験や知識に基づいて、AI Scientistの視点とは異なる視点から論文を評価することで、新たな問題提起や改善策の提案を行うことができるでしょう。
AI Scientist はどのようにして論文のアイデアを生成するのか?
アイデア生成の段階
- 初期テンプレート: AI Scientistは、まず、一般的な機械学習タスク(例えば、シェイクスピアの作品を用いた小規模トランスフォーマーの学習)の軽量なベースライン学習を実行する、シンプルな初期コードテンプレートとLaTeXテンプレートを受け取ります。
- アイデアの創出: 進化的計算とオープンエンド性研究に触発されたAI Scientistは、LLMを突然変異演算子として使用して、アイデアのアーカイブを反復的に拡張します。 これは、興味深さ、新規性、実現可能性の評価指標(自己評価による数値スコアを含む)とともに、説明と実験実行計画を含むアイデアの生成を伴います。
- アイデアの洗練: 各反復において、AI Scientistは、既存のアーカイブ(完了した以前のアイデアからの数値レビュースコアを含む)を条件として、LLMに新しい研究方向を生成するように促します。 各アイデアは、連鎖的な思考と自己反省の複数ラウンドを通じて、洗練され、発展していきます。
- 新規性の確認: 新しいアイデアが生成されると、AI ScientistはSemantic Scholar APIとWebアクセスを使用して、既存の文献との類似性をチェックします。 類似するアイデアがすでに発表されている場合、そのアイデアは破棄されます。このプロセスにより、AI Scientistは真に新規で潜在的に影響力のある研究アイデアに焦点を当てることができます。
AI Scientistのアイデア生成における重要な側面
- 反復的なプロセス: AI Scientistのアイデア生成プロセスは、単一のステップではなく、反復的なものです。これは、初期のアイデアセットから始まり、それらを洗練し、新しいアイデアを生成し、その過程で学んだことに基づいてそれらを評価することによって、アイデアを反復的に発展させていきます。 この反復的なアプローチにより、時間の経過とともに、より洗練され、有望な研究課題を特定することができます。
- LLMの中心的な役割: AI Scientistは、そのプロセスのあらゆる段階でLLMに大きく依存しています。 LLMは、新しいアイデアの生成、実験の設計、コードの記述、結果の説明、論文の執筆など、さまざまなタスクを実行するために使用されます。これは、LLMが大量のテキストデータを学習し、さまざまなプロンプトや質問に対して人間のようなテキストを生成できるためです。
- 人間の知識との統合: AI Scientistが自動化されたシステムである一方で、人間の知識や専門知識を組み込むこともできます。 これは、特定の研究分野における人間の洞察や経験を提供する初期コードテンプレートやLaTeXテンプレートを通じて行うことができます。
AI 科学者はどのようにして論文のアイデアを洗練するのか?
洗練プロセスの段階:
- 初期アイデアの生成: 前述のように、AI Scientistは、まず、興味深さ、新規性、実現可能性の自己評価スコアを含む、初期のアイデアセットを生成します。
- 連鎖的な思考の適用: AI Scientistは、各アイデアを洗練するために、連鎖的な思考(Chain-of-Thought、CoT)プロンプトを使用します。 CoTプロンプトは、LLMが推論ステップのシーケンスを生成し、最終的な回答または結論に至るように促すように設計されています。 このプロセスにより、AI Scientistは、初期アイデアの潜在的な強みと弱みを分析し、関連する研究課題や質問を特定し、アイデアをさらに発展させるための具体的な方法を提案することができます。
- 自己反省による評価: 連鎖的な思考に加えて、AI Scientistは自己反省(self-reflection)も活用して、アイデアを洗練します。 自己反省は、LLMが独自の出力を見直し、改善または修正する機会を提供する反復的なフィードバックメカニズムです。 AI Scientistは、自己反省を通じて、アイデアの明確さ、一貫性、独創性を評価し、必要に応じて修正または再評価することができます。
- 反復的な洗練: AI Scientistは、連鎖的な思考と自己反省の複数ラウンドを通じて、アイデアを反復的に洗練します。 この反復的なプロセスにより、AI Scientistは、初期のアイデアを徐々に洗練し、より洗練された、明確に定義され、実行可能な研究課題へと発展させることができます。
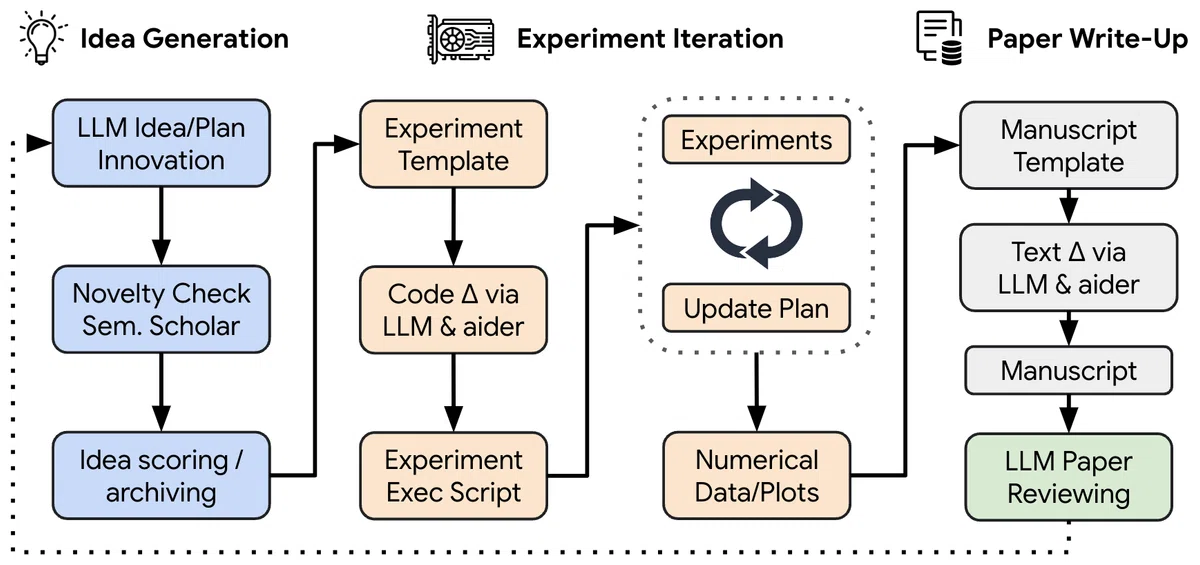
- Idea Generation
- 事前に用意されたseed ideasを元にAIがアイデアを考える
- 最終的にできたアイデアに対してSemantic Scholarを利用して新規性のスコアリング
- "novel": true となっているものだけが次の実験フェーズに
- Experiment Iteration
- アイデア出しフェーズでnovelだと判断されたアイデアを実装し、実験
- Aiderにどんなものを実装するかを指示し、実行、エラーが出た場合はエラーの内容をAiderに入力し再実行を繰り返し
- 実験は最大5回行いますが、なんとAI Scientistは賢いのでどんな実験でどんな結果だったかをnotes.txtというファイルにちゃんと記録
- Paper Write-Up
- Aiderを使ってLaTex形式で記述し、その後 Semantic Scolarを使いながらレビュー
- 注意ポイント
- 自分でtemplate、ベースラインの結果を示せるコードは用意する必要
- アイデアの元となるseed_ideasも自分で考える必要がある
- 実験はAiderが実行・検証できる環境でないといけない
先に所感を述べると、とてもシンプルなコードで、またやっていることも真新しいところは特にない。 むしろ基本的なテクニックを愚直に真正面から使い倒しているかんじ。 大切なのは Reflection と Chain-of-Thought であった。
同感
generate_ideas
アイデア生成の初回プロンプト (idea_first_prompt)
idea_first_prompt = """{task_description}
<experiment.py>
{code}
</experiment.py>
Here are the ideas that you have already generated:
'''
{prev_ideas_string}
'''
Come up with the next impactful and creative idea for research experiments and directions you can feasibly investigate with the code provided.
Note that you will not have access to any additional resources or datasets.
Make sure any idea is not overfit the specific training dataset or model, and has wider significance.
Respond in the following format:
THOUGHT:
<THOUGHT>
NEW IDEA JSON:
<JSON>
In <THOUGHT>, first briefly discuss your intuitions and motivations for the idea. Detail your high-level plan, necessary design choices and ideal outcomes of the experiments. Justify how the idea is different from the existing ones.
In <JSON>, provide the new idea in JSON format with the following fields:
- "Name": A shortened descriptor of the idea. Lowercase, no spaces, underscores allowed.
- "Title": A title for the idea, will be used for the report writing.
- "Experiment": An outline of the implementation. E.g. which functions need to be added or modified, how results will be obtained, ...
- "Interestingness": A rating from 1 to 10 (lowest to highest).
- "Feasibility": A rating from 1 to 10 (lowest to highest).
- "Novelty": A rating from 1 to 10 (lowest to highest).
Be cautious and realistic on your ratings.
This JSON will be automatically parsed, so ensure the format is precise.
You will have {num_reflections} rounds to iterate on the idea, but do not need to use them all.
"""
idea_reflection_prompt = """Round {current_round}/{num_reflections}.
In your thoughts, first carefully consider the quality, novelty, and feasibility of the idea you just created.
Include any other factors that you think are important in evaluating the idea.
Ensure the idea is clear and concise, and the JSON is the correct format.
Do not make things overly complicated.
In the next attempt, try and refine and improve your idea.
Stick to the spirit of the original idea unless there are glaring issues.
Respond in the same format as before:
THOUGHT:
<THOUGHT>
NEW IDEA JSON:
<JSON>
If there is nothing to improve, simply repeat the previous JSON EXACTLY after the thought and include "I am done" at the end of the thoughts but before the JSON.
ONLY INCLUDE "I am done" IF YOU ARE MAKING NO MORE CHANGES."""
アイデア改善のためのリフレクションプロンプト (idea_reflection_prompt):
idea_reflection_prompt = """Round {current_round}/{num_reflections}.
In your thoughts, first carefully consider the quality, novelty, and feasibility of the idea you just created.
Include any other factors that you think are important in evaluating the idea.
Ensure the idea is clear and concise, and the JSON is the correct format.
Do not make things overly complicated.
In the next attempt, try and refine and improve your idea.
Stick to the spirit of the original idea unless there are glaring issues.
Respond in the same format as before:
THOUGHT:
<THOUGHT>
NEW IDEA JSON:
```json
<JSON>
\```
If there is nothing to improve, simply repeat the previous JSON EXACTLY after the thought and include "I am done" at the end of the thoughts but before the JSON.
ONLY INCLUDE "I am done" IF YOU ARE MAKING NO MORE CHANGES."""
新規性チェックのためのシステムメッセージ (novelty_system_msg):
You are an ambitious AI PhD student who is looking to publish a paper that will contribute significantly to the field.
You have an idea and you want to check if it is novel or not. I.e., not overlapping significantly with existing literature or already well explored.
Be a harsh critic for novelty, ensure there is a sufficient contribution in the idea for a new conference or workshop paper.
You will be given access to the Semantic Scholar API, which you may use to survey the literature and find relevant papers to help you make your decision.
The top 10 results for any search query will be presented to you with the abstracts.
You will be given {num_rounds} to decide on the paper, but you do not need to use them all.
At any round, you may exit early and decide on the novelty of the idea.
Decide a paper idea is novel if after sufficient searching, you have not found a paper that significantly overlaps with your idea.
Decide a paper idea is not novel, if you have found a paper that significantly overlaps with your idea.
{task_description}
<experiment.py>
{code}
</experiment.py>
新規性チェックのための各ラウンドのプロンプト (novelty_prompt):
Round {current_round}/{num_rounds}.
You have this idea:
"""
{idea}
"""
The results of the last query are (empty on first round):
"""
{last_query_results}
"""
Respond in the following format:
THOUGHT:
<THOUGHT>
RESPONSE:
<JSON>
In <THOUGHT>, first briefly reason over the idea and identify any query that could help you make your decision.
If you have made your decision, add "Decision made: novel." or "Decision made: not novel." to your thoughts.
In <JSON>, respond in JSON format with ONLY the following field:
- "Query": An optional search query to search the literature (e.g. attention is all you need). You must make a query if you have not decided this round.
A query will work best if you are able to recall the exact name of the paper you are looking for, or the authors.
This JSON will be automatically parsed, so ensure the format is precise.