Building Your Own Product Copilotから学ぶソフトウェア開発とAIプロダクト開発の違い
マイクロソフトが公開しているAIプロダクトの開発に関わる26名のソフトウェアエンジニアへのインタビューをまとめたリサーチがあります。
さらっと読んだだけでもわかりみが深く、特にソフトウェアエンジニア視点から見た、AIプロダクト開発の特徴、課題の全体感・概要を知る上ではよくまとまっていそうだったので、読みながらまとめてみた。
サマリー
多くの企業がプロダクトにAIアシスタント機能を組み込もうとしているが、プロダクトへのAIの統合は多くのソフトウェアエンジニアにとって初めての経験であり、既存の開発プロセスやツールは、AI-poweredなアプリケーション開発に伴う課題には対応しきれていない。
Building Your Own Product Copilotは、AIアシスタントの開発に携わる26名のソフトウェアエンジニアにインタビュー、ブレインストーミングを実施し、課題やニーズをリサーチ・まとめた論文。
ちなみにインタビュー参加者の募集方法は以下の通り。開発プロセスでAIを活用しているエンジニアやデータサイエンス・機械学習バックグラウンドではなく、AI機能の開発に関わっているソフトウェアエンジニアにフォーカス当てている。
- 募集方方法
- Microsoft社内からの募集
- 14名のソフトウェアエンジニアを直接募集
- Copilot開発に携わっている既知の人材
- 外部からの募集
- UserInterviews.comを使用
- 12名のソフトウェアエンジニアを多様な企業・分野から募集
- Microsoft社内からの募集
- 選考基準
- 20の質問からなるアンケートを使用
- 除外基準:
- AIを開発プロセスで使用しているエンジニア(例:GitHub Copilot、ChatGPTのみの利用)
- データサイエンスや機械学習の豊富なバックグラウンドを持つ人材
- 包含基準:
- AI関連の機能や製品開発に週20時間以上従事している人材
主な差分・課題
インタビューの結果、判明した主な課題テーマは以下。
特にプロンプトエンジニアリングとテストに非常に時間とリソースを要しているとのこと。
| カテゴリ | 課題 |
|---|---|
| プロンプトエンジニアリング | - 試行錯誤の時間がかかるプロセス - モデル出力の一貫性の欠如 - コンテキストとトークン制限のバランス - プロンプトの管理が煩雑 |
| オーケストレーション | - 複雑なワークフローの作成 - 予測不可能な動作の管理 - マルチターン会話の管理 - モデルがループ・脱線した場合のハンドリング |
| テストとベンチマーク | - 従来のユニットテストが適用困難 - 標準化されたベンチマークや評価指標の不足 - カスタムテストソリューションの必要性 |
| 安全性、プライバシー、コンプライアンス | - 現実世界への影響に対する懸念 - ユーザーの同意と理解の必要性 - 責任あるAI |
| 知識とベストプラクティスの進化 | - 体系的な学習資料やベストプラクティスの不足 - コミュニティ主導の学習に依存 - 従来のソフトウェア開発とは異なるアプローチが必要 |
| 開発者体験 | - プロトタイプ開発と製品開発のツールの乖離 - プロジェクトセットアップや統合の困難さ |
プロンプトエンジニアリング
まず最初に調査結果の中で言及されているのはプロンプトエンジニアリングについて。
プロンプトエンジニアリングは、インタビュイーが慣れ親しんできたソフトウェアエンジニアリングと比べると未知の領域であり、あるインタビュイーは「これは科学というより芸術に近い」と表現している。
LLMモデルの予測不能な性質を扱うことに戸惑った様子を示す一方で、LLMモデルの汎化性によって実現可能なシナリオが増えたことにはポジティブな反応を示している。
さらに詳細にプロンプトエンジニアリングの主な課題について見てみる。
| 課題 | 説明 |
|---|---|
| 試行錯誤の時間がかかるプロセス | • アドホックな環境での実験が必要 • 多くの時間と労力を要する • 効率的な方法論の欠如 |
| プロンプト出力の制御 | • 構造的な形式での出力が困難 • 一貫性のある応答の生成の課題 • 予期せぬ出力形式への対応が必要 |
| コンテキストとトークン制限のバランス | • 限られたトークン数で十分なコンテキストを提供 • 大量の情報を圧縮する必要性 • 重要情報の選択と削除の判断が困難 |
| プロンプトの管理とトラッキング | • プロンプトの分解と管理が複雑 • バージョン管理の必要性 • パフォーマンスの継続的な検証と追跡が困難 |
| モデルの不安定性 | • 大規模言語モデルの応答が不安定 • 予測困難な動作への対応 • モデルの特性に合わせた調整が必要 |
| ツールの不足 | • 効率的なプロンプトエンジニアリングをサポートするツールが不足 • 既存のソフトウェア開発ツールとの統合が困難 |
試行錯誤の時間のかかるプロセス
プロンプトエンジニアリングの初期フェーズは、多くの場合OpenAIのPlaygroundのようなアドホックな環境での実験から始まる。
多くのインタビュイーが、Playgroundでとにかく色々書いてみて、動くかどうか探索するプロセスでプロンプトエンジニアリングを行っていると述べている。
最近はどのシーンにおいても、自分でプロンプトで書く機会は多少減ったが、探索的なプロセスになるというのはわかりみが深い。
プロンプト出力の制御
LLMモデルの出力をそのままエンドユーザーに表示するのでなければ、システム・プログラム内で扱いやすい、何かしら構造的な形式で出力を得たいところ。
JSON、Markdown形式での出力を多くのインタビュイーが試しているが、逆に壊れたJSONが出力された際のハンドリングへの対応が求められたりと苦戦している様子が伺える。
コンテキストとトークン制限のバランス
最近はかなりコンテキストウィンドウも拡張されたため、課題感は薄れたが、コンテキストを出来るだけ与えたい vs トークン制限のジレンマの話。
- 短い指示(例:「このコードをリファクタリングして」)からコンテキストを理解する
- 大量の情報を限られたトークン数に圧縮する
- 必要に応じて情報を「選択的に切り捨てる」
プロンプトの管理とトラッキング
いわゆるプロンプトをどう分割するか、効果的なプロンプトテンプレート、管理方法、さらには継続的にプロンプトを評価するための実験管理ツールの必要性が話題に上がっている。
実験管理ツールは、日本の企業においても発信が多く、選択肢も増えて、だいぶ市民権を得たのではないか。
- 初期の問題:「1つのプロンプトで多くのことを行うのは間違い」
- 解決策:プロンプトを例、指示/ルール、テンプレート、その他の資産に分解
- 結果:「プロンプトのライブラリのようなものができあがる」
個人的には、「プロンプトのライブラリのようなものができあがる」という点に関しては、最初の頃にオレオレプロンプトライブラリとか作ったなーというのを思い出して、懐かしくなった。
オーケストレーション
ほとんどのプロダクトでは、複数のプロンプトのオーケストレーション・評価が必要で、一つのプロンプトだけで完結することは少ないだろう。
今ならフローエンジニアリングも近しいテーマになりそう。
| 概念/課題 | 説明 |
|---|---|
| 意図検出とルーティング | • ユーザーの入力から意図を検出 • 適切なプロンプトにルーティング • 応答の解釈と後処理が必要 |
| コマンド機能の制限 | • 多くのコパイロットでコマンド実行が制限的 • 安全性の観点から自動実行に慎重 |
| 長期的な対話と計画 | • シングルターンの対話からマルチターンへの拡張が困難 • エージェントベースのアプローチによる解決策 |
| ループと脱線 | • モデルがループに陥ったり、タスクから外れやすい • タスク完了の正確な認識が困難 |
テストとベンチマーク
プロンプトエンジニアリングと同様に、多くの時間/リソースを割いたとされているのがテスト・ベンチマーク。
最近は手法としてはLLM as a Judgeなどのアプローチも増えてる印象。
また内容よりも合格/不合格の基準と構造に焦点を当てたテスト手法、メタモルフィックテスティングの紹介もされている。
| 課題 | 説明 |
|---|---|
| flaky test問題 | • 生成モデルの応答が毎回異なる • 従来のアサーションベースのテストが困難 • 結果の一貫性の欠如 |
| テストデータの管理 | • 手動でキュレーションされた入出力例の大規模なデータセットが必要 • プロンプトやモデルの変更に伴う更新の困難さ |
| ベンチマークの不在 | • 標準化されたベンチマークの欠如 • 各チームが独自のベンチマークを作成する必要性 |
| 評価指標の不明確さ | • 「十分に良い」パフォーマンスを定義する明確な基準の欠如 • 性能改善の評価が困難 |
| 人手によるラベリングの課題 | • 大規模なラベル付きデータセットの作成が必要 • 時間とコストがかかる作業 |
| リソース制約 | • テスト実行のコストが高い • 大規模なテストスイートの実行が困難 |
安全性、プライバシー、コンプライアンス
特に対話型サービス、エンドユーザーから自由な入力を受け付ける場合は、ガードレールやモデレーションの重要性が高まる。
テレメトリとプライバシーのバランスも、開発者視点だとinput/outputを確認できると捗るのは事実だが、何も制限なし!というのは現実的ではなさそう。そしてバランスをどう取るかは各々のドメインで温度感は変わりそう。
| 課題 | 説明 |
|---|---|
| 安全性の確保 | • ユーザーの安全を守るガードレールの設置 • 意図しない有害な対話の防止 • 幅広い使用環境での安全性担保 |
| 対話の制御 | • 不適切な話題への発展防止 • コンテンツフィルタリングの実装 • ルールベースの分類子と手動ガードリストの使用 |
| プライバシー保護 | • 個人識別情報の漏洩防止 • サードパーティモデル使用時のデータ保護 • 内部モデルのホスティングによるリスク軽減 |
| テレメトリとプライバシーのバランス | • ユーザー行動の把握とプライバシー保護の両立 • 限定的なデータ収集による機能改善の制約 • 生成コンテンツの品質評価の難しさ |
| 責任あるAI評価 | • コンプライアンスと安全性の包括的レビュー • 複雑で時間のかかる評価プロセス • 新たな評価基準と方法論の必要性 |
| 有害コンテンツの検出 | • 広範なカテゴリーの有害コンテンツの自動検出 • 大規模かつ複雑なフィルタリングシステムの構築 • 出荷前の厳格な基準達成の必要性 |
開発者体験
とても端的にまとめてしまうと、まだまだ開発のエコシステム・ツールが発展途上というお話。
最近は選択肢は色々増えてきたが、逆にツールの学習と比較に時間がかかってる気はする...
| 課題 | 説明 |
|---|---|
| 豊富なエコシステムの初期採用 | • プロトタイプ開発では豊富な機能を持つライブラリ(例:LangChain)を選択 • 実際の製品開発時には異なるアプローチが必要 |
| ツール学習の負担 | • 多様なツールの学習と比較に時間がかかる • 顧客の問題に集中したいが、ツールの学習に時間を取られる • ツールエコシステムのナビゲーションに疲労感 |
| 体系的な設計プロセスの不足 | • 個々のコンポーネントを分解して開発するワークフローの欠如 • プロンプトの事前条件と事後条件を個別に定義する機能の必要性 • 検証機能の組み込みへの要望 |
| 統合されたワークフローの不在 | • プロンプトエンジニアリング、オーケストレーション、テスト、ベンチマーク、パフォーマンス、テレメトリを統合したワークフローの欠如 • 多様なツールを組み合わせて使用する必要性 |
まとめ
2023年12月公開で、その時と比較して状況が変わってる点もありますが、大半は今でも課題・特徴ではあり、ソフトウェアエンジニアリングとの差分としてわかりやすい・伝わりやすいものが多かった印象です。
今回はほぼ割愛しましたが、課題への対応法・手法の提案も一部行われており、気になる方はぜひ本文をご覧になってみてください
参考までに、以下はインタビューを経て完成した開発の大枠のフローの図の様です。
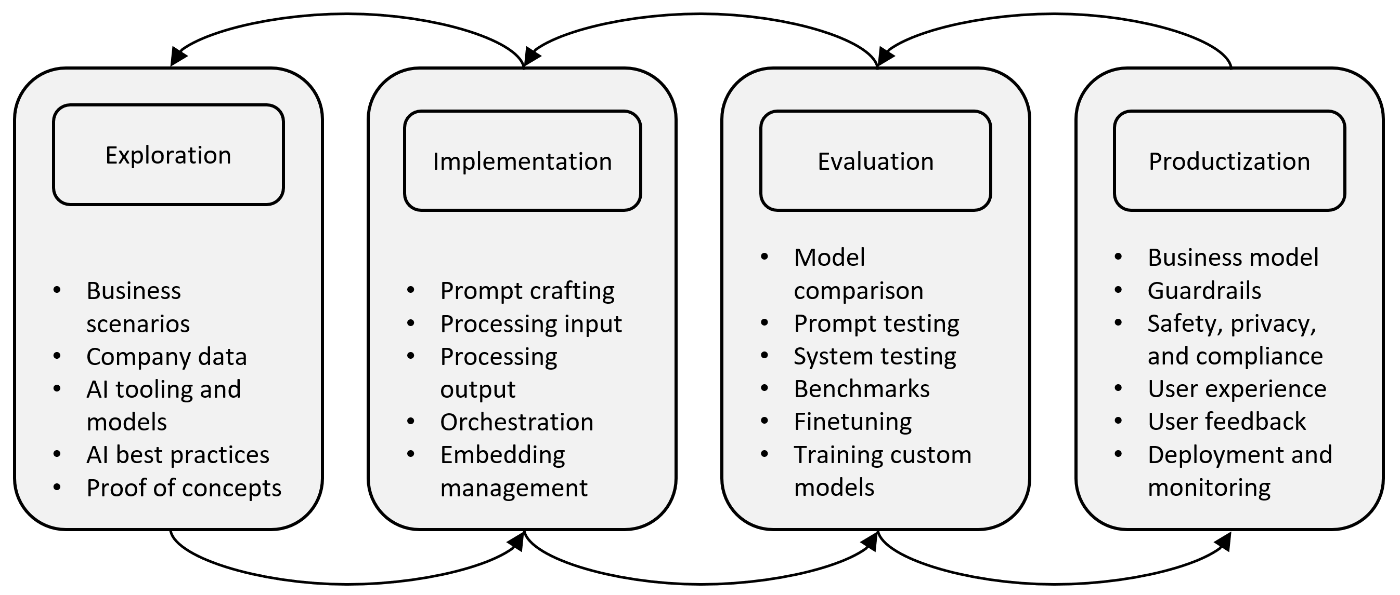
引用: 3.2.Procedure - Building Your Own Product Copilot: Challenges, Opportunities, and Needs
今回の内容とは趣旨がずれますが、Gihutb Copilot, Cursor、Replit Agent、さらにはv0、GPT Engineer、そしてウェイトリストのまま音沙汰がないDevin等による開発プロセスの変化も待ち受けているので、今後も色々楽しくなりそうです。
今回は以上です!
Discussion