Open6
StepFunctionsでネストしたワークフローのRedrive挙動確認
テンプレートで提供されているこれを使う。

親ステートマシンからのRedrive
どちらも同じコードが使われているが1つ目はコールバック不要、2つ目はコールバック必要となっているので、コールバックの処理を削除してタイムアウトさせてみる。
console.log('Loading function');
const AWS = require('aws-sdk');
exports.lambda_handler = (event, context, callback) => {
console.log('event ' + JSON.stringify(event));
console.log('context ' + JSON.stringify(context));
const taskToken = event.TaskToken;
const message = event.Message;
const params = {
taskToken: taskToken,
output: "\"" + message + "\""
}
const stepfunctions = new AWS.StepFunctions();
callback(null)
// stepfunctions.sendTaskSuccess(params, function(err, data) {
// if (err) {
// console.log("Error", err);
// callback(null, err)
// } else {
// console.log("Success", data);
// callback(null);
// }
// });
}
{
"StartAt": "Start new workflow and wait for callback",
"States": {
"Start new workflow and wait for callback": {
"Comment": "Start an execution and wait for it to call back with a task token",
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.waitForTaskToken",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:188970983837:stateMachine:NestingPatternAnotherStateMachine-jnTiEDCysncq",
"Input": {
"NeedCallback": true,
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"TaskToken.$": "$$.Task.Token"
}
},
"End": true,
"TimeoutSeconds": 30
}
}
}
親側はエラー
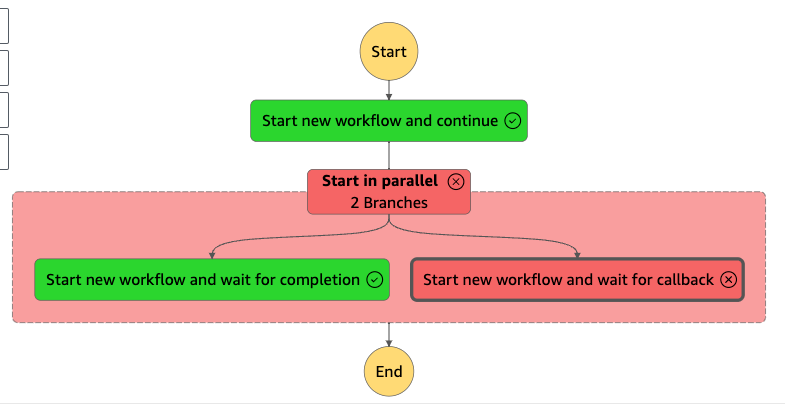
子は正常終了
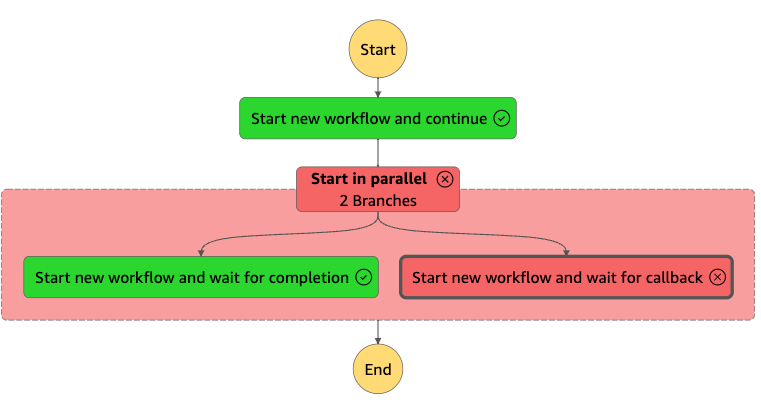
Redriveすると、同様に失敗する。
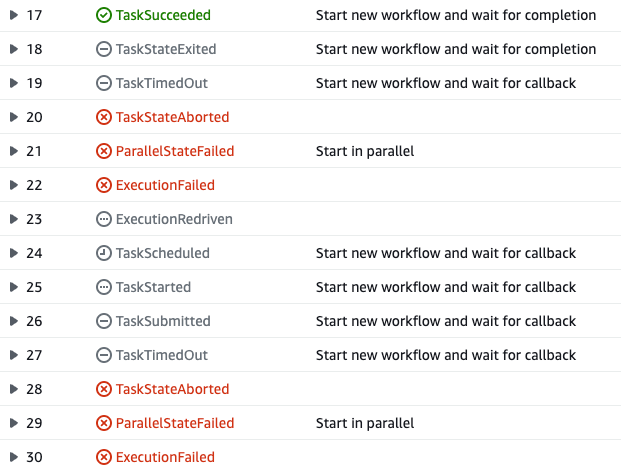
期待通り正常終了した片側のワークフローは実行されず、失敗したワークフローのみ再実行される。
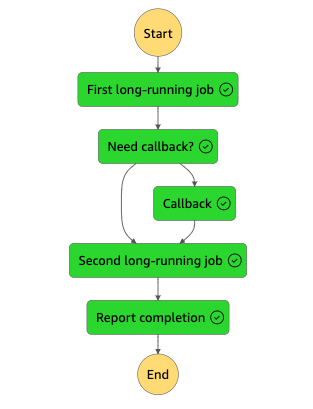
子のステートマシンからのRdrive
子のステートマシンからRedriveするとどうなる?
Callback有りのジョブは例外を投げるように修正する。
console.log('Loading function');
const AWS = require('aws-sdk');
exports.lambda_handler = (event, context, callback) => {
console.log('event ' + JSON.stringify(event));
console.log('context ' + JSON.stringify(context));
const taskToken = event.TaskToken;
const message = event.Message;
const params = {
taskToken: taskToken,
output: "\"" + message + "\""
}
const stepfunctions = new AWS.StepFunctions();
stepfunctions.sendTaskSuccess(params, function(err, data) {
{
console.log("Error", data);
callback(null, "Error");
}
});
throw new Error("Unknown Error")
}
エラーになった。

親側はタイムアウトで認識される。
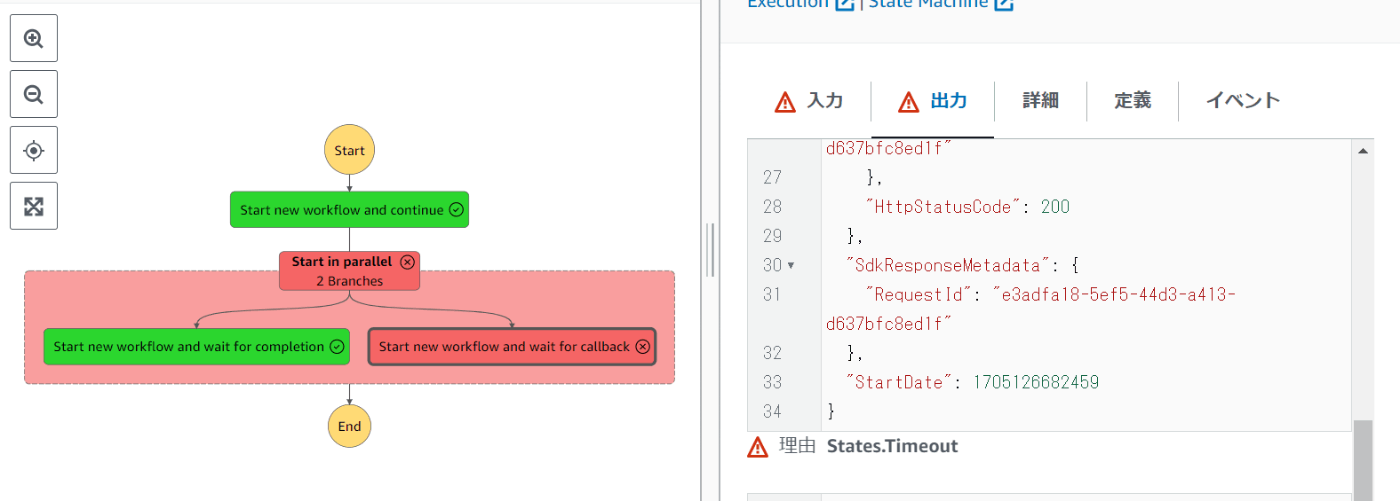
ここでLambdaのソースコードを元に戻して子のステートマシンを再実行する。
正常終了するが 親側は再開しない。 ネストの場合は親のステートマシンからの再処理が必要になるようだ。
親ステートマシンの待機中に子のステートマシンをRedriveする
以前の結果を受けて、親側のタイムアウトを十分大きくして待機中に子のステートマシンをRedriveしてみる。
"States": {
"Start new workflow and wait for callback": {
"Comment": "Start an execution and wait for it to call back with a task token",
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution.waitForTaskToken",
"Parameters": {
"StateMachineArn": "arn:aws:states:ap-northeast-1:188970983837:stateMachine:NestingPatternAnotherStateMachine-jnTiEDCysncq",
"Input": {
"NeedCallback": true,
"AWS_STEP_FUNCTIONS_STARTED_BY_EXECUTION_ID.$": "$$.Execution.Id",
"TaskToken.$": "$$.Task.Token"
}
},
"End": true,
"TimeoutSeconds": 999999
}
子のステートマシンがエラーになり、親のステートマシンは待機中。

その間にソースコードを元に戻して子のステートマシンをRedriveする。
この場合は 待機中の親ステートマシンが継続される。
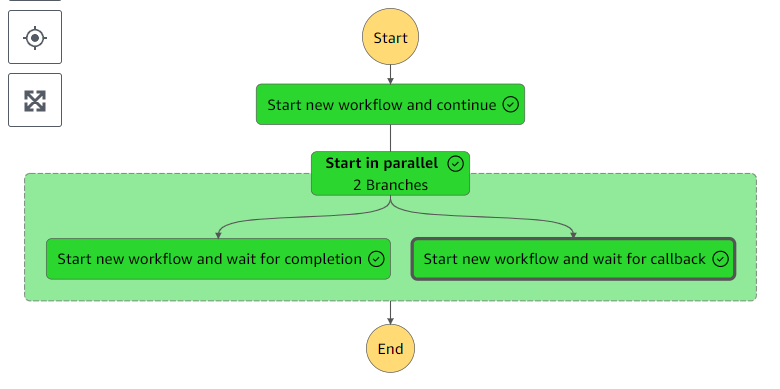
エラーハンドリングした場合のRedrive
StepFunctionsでエラー通知などする場合、再実行はどこから行われるのか。
今回は状態をFailに遷移させて確認してみる。

子のステートマシンはさっきの検証と同様に意図的にエラーを起こすので親側はタイムアウトエラーになった。
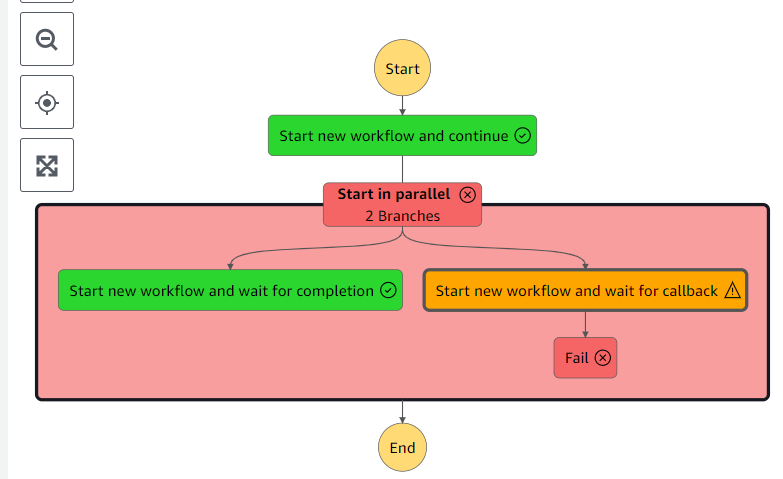
この状態でRedriveしてみるが、Failが再実行されるだけだった。
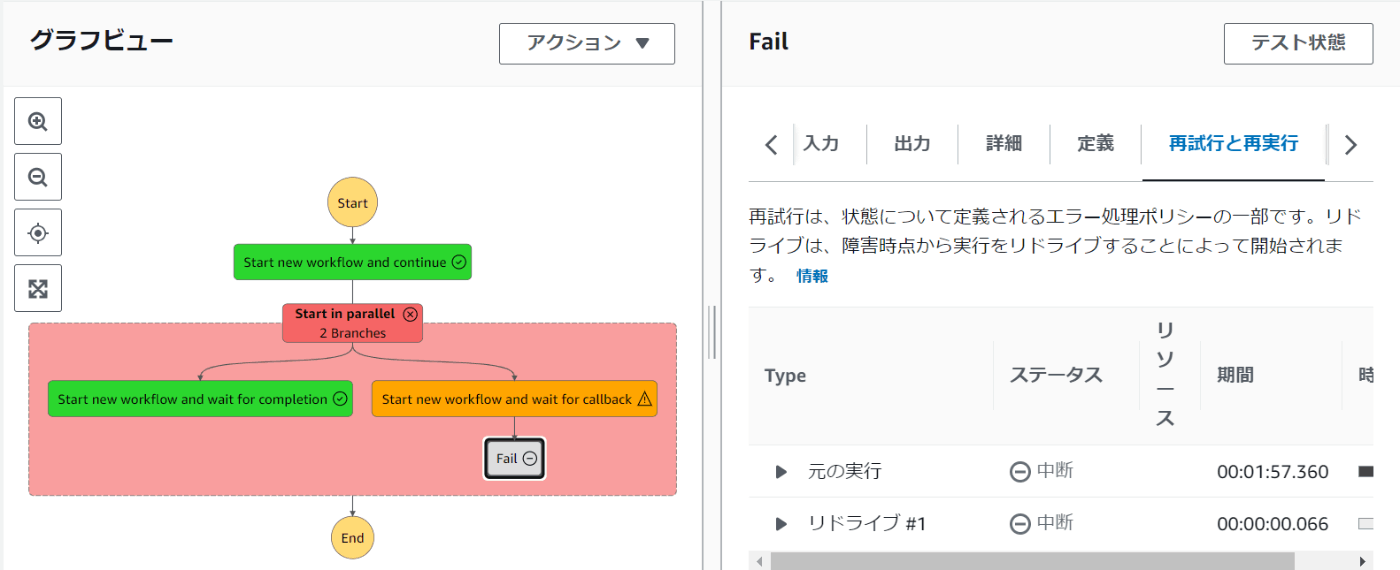
Redriveを想定したネストしたステートマシンの設計方針
こんな感じだろうか。
- エラーハンドリングは子のステートマシンで行う
- 親ステートマシンでRedriveをする場合
- タイムアウトは最低限の時間を設定する
- 子のステートマシンは冪等性を保つように設計する
- 子のステートマシンでRedriveする場合
- 親ステートマシンのタイムアウトは十分に大きくする
親ステートマシンのタイムアウトを極端に長くするのはコスト的に望ましくない、冪等性を持たせるのが難しい場合は無理にネストせずにイベントブリッジやSQSで疎結合に保つのが良いのかもしれない。