🧩
PythonからPDFファイルをテキスト化する(pypdfium2/pypdf編)
Pythonを使いPDFファイルをテキスト抽出する機会があったので、pypdfium2とpypdfの使い方をメモ。
現時点では、比較できるほど使い込んではいない。
要件
- 言語は日本語
- 複数ページのPDFファイル
- レイアウトは1段
- Pythonから使いたい
- スピードは不要
選定
GitHub 上にPythonのPDFライブラリを様々な観点から比較しているベンチマークレポジトリがある
具体的には、テキスト抽出(Text Extraction Quality)の上位は以下の通り
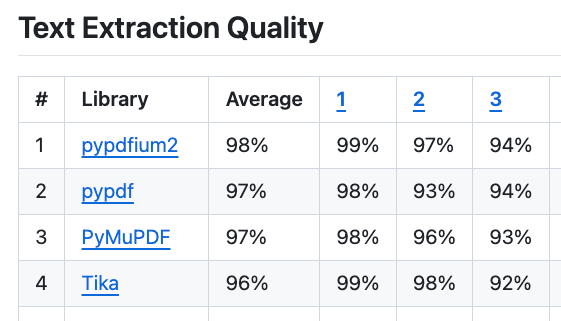
上位3ライブラリの中から、 pypdfium2 と pypdf で実際にテキスト抽出するところまでを動作確認
pypdfium2
精度が一番よかった pypdfium2 は Google が提供する pdfium の Python バインディング。
$ pip install -U pypdfium2 でインストール完了
読み取るだけなら、使い方は極めて簡単。
'''
複数ページのPDFファイルをテキスト表示
$ pip install -U pypdfium2
'''
import sys
import pypdfium2 as pdfium
pdf = pdfium.PdfDocument(sys.argv[1])
for page in pdf:
textpage = page.get_textpage()
text = textpage.get_text_range()
print(text)
pypdf
精度が2番手の pypdf は20年近い歴史のある PDF ライブラリ。
pdfium のような外部ライブラリに依存せず、Pythonだけで書かれている。
2023年から pypdf のブランディングになっているが、歴史的には、オーナーシップの変更等により pyPdf → PyPDF2 → PyPDF3/PyPDF4 → PyPDF2 → pypdf(今ココ)という変遷をたどっている。
$ pip install -U pypdf cryptography でインストール完了
PDFファイルがパスワード保護されている場合、 pypdf.errors.DependencyError: cryptography>=3.1 is required for AES algorithm というエラーが発生するため、 cryptography ライブラリもインストールが必要。
読み取るだけなら、使い方は極めて簡単。
'''
複数ページのPDFファイルをテキスト表示
$ pip install -U pypdf cryptography
'''
import sys
from pypdf import PdfReader
reader = PdfReader(sys.argv[1])
for page in reader.pages:
text = page.extract_text()
print(text)
Discussion