記事の内容
BigQuery の dry run は実行前にクエリスキャン量を測定することができます。
ただし様々なケースで dry run で提示されるスキャン量と実際のスキャン量が異なります。
この記事では dry run と実際のスキャン量が乖離しているケースを検証してまとめました。
記事を書いた動機
最近 AI エージェントに BigQuery を使ったデータ分析を任せようとしているのですが、高コストなクエリを連投されると困るため、コストに応じて処理を分岐することを考えています。
その時に dry run を使用することでクエリを実行する前にある程度コストを予測することができます。
しかし dry run と実際のコストが乖離する場合があることを経験しており、これを機に一通り調べておきたいと思い、ついでに調べた内容を記事として公開することにしました。
dry run とは
簡単に dry run の機能を紹介します。
BigQuery の公式ドキュメントによると次のとおりです。
- オンデマンド モードでの料金の見積もり
- クエリの検証
- キャパシティ モードでクエリによって処理されたおおよそのバイト数
ドライランはクエリスロットを使用しないため、ドライランの実行に対しては課金されません。ドライランによって返された見積もりを料金計算ツールで使用すると、クエリの費用を計算できます。
このようにクエリを実行する前にクエリを実行できるか検証したり、料金を見積もることができるため、AI の生成したクエリを検証するのにもってこいの機能です。
dry run は BigQuery コンソールで このクエリを実行すると、◯◯ B が処理されます。 と表示される他、 bq コマンドや各プログラミング言語のクライアントライブラリから実行することが可能です。
下準備
まずはデータセットを作ります。
- データセット作成
CREATE SCHEMA IF NOT EXISTS `verification-475911.dryrun_test`
OPTIONS(
location = 'asia-northeast1',
default_partition_expiration_days = NULL
);
続いてサンプルの基本となるテーブルを作成します。
後ほど検証に使用するため、パーティションのあるクラスタリングテーブルにします。
-- サンプルとしてクラスタリングテーブル作成
CREATE OR REPLACE TABLE
`verification-475911.dryrun_test.partitioned_clustered_table`
PARTITION BY
usage_date
CLUSTER BY category_id
OPTIONS (partition_expiration_days = NULL) AS
SELECT DATE(TIMESTAMP_ADD(TIMESTAMP '2025-01-01 00:00:00', INTERVAL x SECOND)) AS usage_date,
TIMESTAMP_ADD(TIMESTAMP '2025-01-01 00:00:00', INTERVAL x SECOND) AS usage_timestamp,
MOD(x, 5) AS category_id,
CONCAT('value_', CAST(MOD(x,100) AS STRING)) AS value_text FROM UNNEST(GENERATE_ARRAY(1, 1000000)) AS x
CROSS JOIN (
SELECT
y
FROM
UNNEST(GENERATE_ARRAY(1, 100)) AS y )
;
これで1億行の 3GB くらいのテーブルが出来上がりました。

プレビューを見るとこんな感じです。

usage_date にパーティションを、category_id にクラスタリングを入れています。
この後も必要なサンプルがあれば都度テーブル等を作成します。
なお、スクショでプロジェクトIDが書いてあったり隠されたりしてますが検証後プロジェクトは削除したので書いてあっても問題ありません。
dry run > 実際
クラスタ化テーブル
公式ドキュメントのクラスタ化テーブルの概要に次の記載があります。
クラスタ化テーブルに対してクエリを実行する場合、クエリを実行する前はスキャンされるストレージ ブロック数が不明なため、正確なクエリ費用の見積りを得られません。最終的な費用は、クエリの完了後に、スキャンされた特定のストレージ ブロックに基づいて求められます。
上記の通り実際の見積もりが得られません。
ということで実際にクエリを発行してみます。
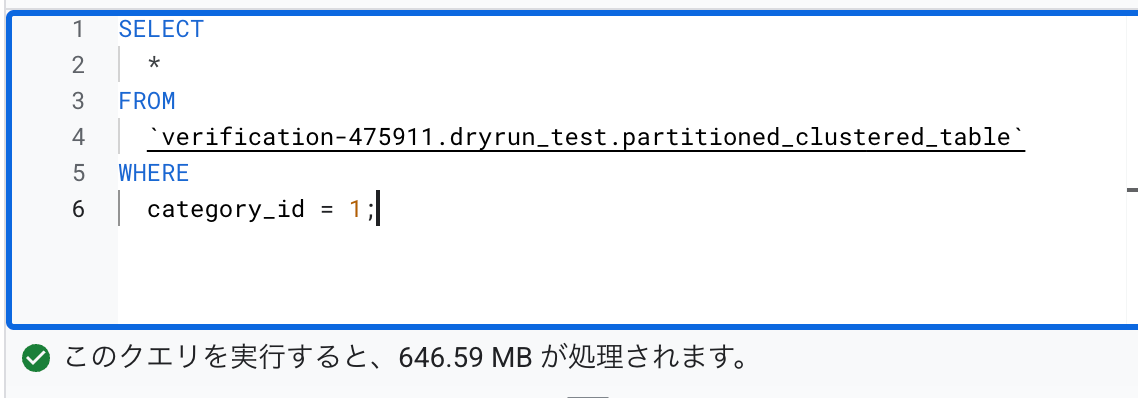
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table`
WHERE
category_id = 1
dry run では全量スキャンになっています。

実際には1つのクラスタのみが課金され5分の1程度になっています。

数分経過後に再度クエリを実行すると、dry runの結果にクラスタリングが考慮されるようになります。
存在しないクラスタを指定しようとすると 0B になります。

category_id = 1 に対してもともとこのクラスタに入っていたのと同じ量のデータを入れてみます。
INSERT INTO
`verification-475911.dryrun_test.partitioned_clustered_table`
SELECT
DATE(TIMESTAMP_ADD(TIMESTAMP '2025-01-01 00:00:00', INTERVAL x SECOND)) AS usage_date,
TIMESTAMP_ADD(TIMESTAMP '2025-01-01 00:00:00', INTERVAL x SECOND) AS usage_timestamp,
MOD(x, 5) AS category_id,
CONCAT('value_', CAST(MOD(x,100) AS STRING)) AS value_text
FROM
UNNEST(GENERATE_ARRAY(1, 1000000)) AS x
CROSS JOIN (
SELECT
y
FROM
UNNEST(GENERATE_ARRAY(1, 100)) AS y )
WHERE MOD(x, 5) = 1 ;
この直後に dry run で category_id = 2 を見てみると、もともと category_id = 2 に入っていたデータ量 + category_id = 1 に入れたデータ量が表示されています。

存在しない category_id を指定すると、先程 category_id = 1 に入れたデータ量が表示されています。

しばらく時間をおいてから再度見ると実際の値が表示されています。


おそらく公式ドキュメントのBigQuery の内部: 列メタデータ インデックス(CMETA)の力に記載しているようなことが関係しているのではないかと思います。
INNER JOIN でパーティション列が絞り込まれる
INNER JOIN でパーティション列が絞り込まれる場合、パーティションが効いて実際のスキャン量は減ります。
しかし dry run ではそれが反映されません。
-- INNER JOIN でパーティション列で絞り込むためのテーブルを作成する
CREATE OR REPLACE TABLE `verification-475911.dryrun_test.join_right_small`
AS
SELECT
x AS category_id,
DATE_ADD(DATE('2025-01-01'), INTERVAL x DAY) AS usage_date
FROM
UNNEST(GENERATE_ARRAY(0, 4)) AS x;
-- INNER JOIN でパーティション列で絞り込んだクエリ
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table` AS t1
INNER JOIN
`verification-475911.dryrun_test.join_right_small` AS t2
USING(usage_date)
;
dry run では全量分が表示されています。

実際にはパーティション列で絞られている分はコストがかかっていません。

キャッシュが効いている
一度次のクエリを実行しておいて、もう一度実行しようとすると dry run はキャッシュを考慮せずに見積もりを出しますが、実際には課金されるバイト数は 0 B になります。
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table`;
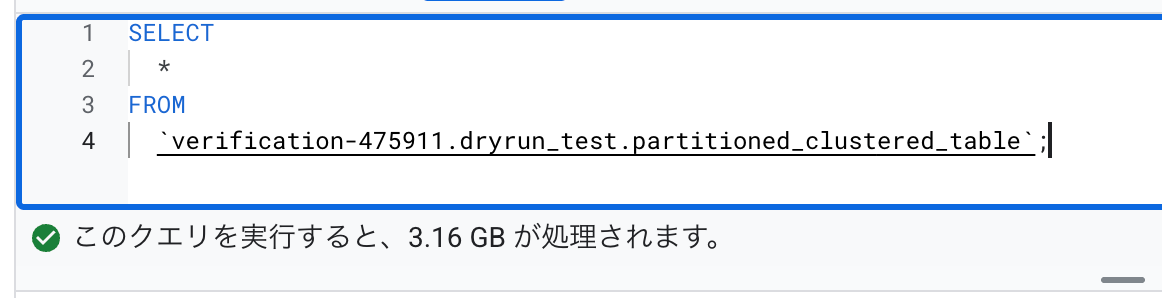

dry run < 実際
dry run よりも実際のコストのほうが高いので特に注意が必要です。
外部テーブル
外部テーブルに対しては 0 B と推定されますが実際には課金されます。
公式ドキュメントのクエリの実行のドライランにも次の記載があります。
注: 外部データソースを使用する連携クエリのドライランで、行が返されても 0 バイトの下限が報告される場合があります。これは、実際のクエリが完了するまで、外部テーブルで処理されるデータの量が確定できないためです。連携クエリを実行すると、このデータの処理に引き続き費用がかかります。
適当なCSVファイルを作ります。
usage_date,category_id,user_id,value
2025-01-01,1,u001,100
2025-01-02,2,u002,200
2025-01-03,1,u003,300
外部テーブルを作成します
CREATE OR REPLACE EXTERNAL TABLE `verification-475911.dryrun_test.external_csv_example`
OPTIONS (
format = 'CSV',
uris = ['gs://verification-dryrun-test/sample.csv'],
skip_leading_rows = 1
);
クエリを実行します。
SELECT
*
FROM
`verification-475911.dryrun_test.external_csv_example`
;
0 Bと表示されました。

実際には課金されます。

DDL ステートメントを使用している
DDL ステートメントを使用しているとその後は推定が実行されません。
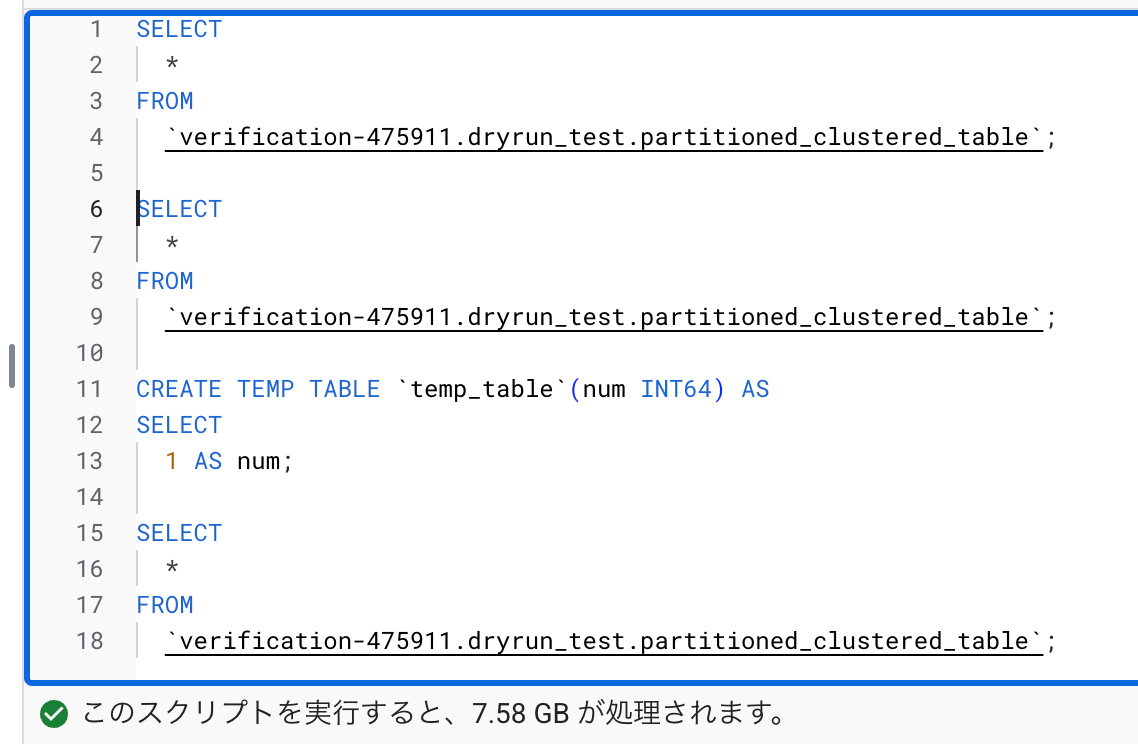
一例として以下のように途中に CREATE TEMP TABLE 実行するクエリを試します。
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table`;
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table`;
CREATE TEMP TABLE `temp_table`(num INT64) AS
SELECT
1 AS num;
SELECT
*
FROM
`verification-475911.dryrun_test.partitioned_clustered_table`;
本来であれば3回呼び出しているので10GB程度のスキャンが想定されます(キャッシュの考慮なし)が、dry run では 7 GB 程度になっており、 CREATE TEMP TABLE 後は dry run が走っていないことがわかります。
他にも公式ドキュメントのマルチステートメント クエリのドライランにはDMLを使用したケースやCALLステートメントを使用した場合などのケースが記載されています。ぜひご確認ください。
終わりに
今回検証した以外にも dry run と実際が乖離しているケースはあると思います。
dry run の結果だけでクエリ利用量を完全にコントロールすることはできないため、BigQuery の API 制限をかけたり定期的に実際の利用量を確認することが重要です。
他にも dry run と実際が乖離するケースがあればぜひコメント下さい。

学習eポータル+AI型教材「Qubena(キュビナ)」を開発している株式会社COMPASSです! 弊社に興味をお持ちいただいた方はキャリア登録をお願いします!最新情報や求人情報をお届けします! →app.crm.i-myrefer.jp/entry/qubena/14pXH9t0sDocJgU7TD1q
Discussion