こんにちは!株式会社 COMPASS でエンジニアをしている安齋です。私はシステム開発部というエンジニアリングの組織に所属をしており、現在はLLMを利活用するための研究開発の一環で様々な取り組みを行っています。
今回は、画像で表現された問題データをOCRやLLMを使ってテキストデータとして扱えるようにした取り組みについて、技術選定から実際の解決アプローチまでをご紹介します。
この記事はこんな方におすすめ
- 株式会社COMPASSの技術的な取り組みについて知りたい方
- OCRサービスを使った開発の事例を知りたい方
- LLMの活用事例を探されている方
背景と解決したかった課題
COMPASSでは、AIが子どもたち一人ひとりに合った問題を出題する公教育向けのデジタル教材「Qubena(キュビナ)」を開発、提供しています。Qubenaは公教育での学びに必要な小学校、中学校向けの国語、算数・数学、理科、社会、英語の5教科の問題を搭載しており、その数は8万問以上となっています。
Qubenaに搭載されている問題は基本的にはテキストデータとして扱えるようになっており、教材の品質を向上するために、例えばどのような問題でどのような単語が使われているか、などのテキストベースでの情報検索ができるようになっています。
一方で、問題について上記のように基本的にはテキストデータとして扱えるようにはなっているものの、算数・数学の問題については数式やイラストを含むため、問題そのものを画像データとして取り扱っています。そのため、教材の品質向上のための取り組みや、今後LLMを用いた高度な問題の分析などを行うにあたって、一部の問題がテキストで表現されていないという点が大きな課題となっていました。

画像データとして扱われている問題。これをテキストで表現できるようにしたい。
画像データのテキスト化を行うにあたっては様々なアプローチが考えられ、人間の手でテキスト化を行うことも検討しました。しかし、算数・数学の問題については数も多く、人間の手で行う際は膨大な時間とコストがかかってしまうので、最新技術を駆使しながらこの課題に取り組むことしました。具体的には下記のステップで画像データをテキスト化していきました。
- OCRを用いた問題文、数式の抽出
- 抽出した問題文、数式をLLMを用いて校正
- イラストやグラフの内容の抽出
ここからはそれぞれのステップでの技術選定から、どのように実現したかをご紹介していきます。
OCRを用いた問題文、数式の抽出
まずは数式を含む問題文を適切に抽出する作業を行います。実際にQubenaで取り扱っている算数・数学の問題は画像データとして取り扱っていますが、画像データを制作するにあたってAdobe Illustratorを用いているので、制作過程においてはテキストデータを保持していることになります。したがって、元データからテキストデータを抽出するというアプローチも検討しました。
しかし、算数・数学の問題では数式が扱われることが多く、通常のテキストでは数式を表現することが難しかったため、Adobe Illustratorを用いた制作過程の中でも数式部分は画像として取り扱っています。そのため、問題文中にあるすべてのテキストを、数式も含めて全て抽出することは難しく、OCRを使うアプローチを採用しました。
OCRを用いるとなるとやはり精度が気になるところですが、一昔前のOCRとは違って、現在ではかなり高精度で数式やテキストの抽出ができるようになっています。そこで、代表的なOCRサービスを比較検討して、最も今回実現したいユースケースにマッチするOCRサービスを選定することにしました。実現したいユースケースに対して観点となるのは次の2点です。
- 数式が読み取れること
- ルビが読み取れること
前述したように、テキスト抽出のアプローチを検討する中でもネックになったポイントが数式の読み取りでした。なので、数式が正確に読み取れることは必須条件になります。また、Qubenaでは問題文の漢字に必要に応じてルビを振っており、OCRのアプローチで文字を抽出する際に、精度面でルビつきの文字でもしっかり読み取れる必要があります。そこで、上記観点を満たすと考えるサービスをリストアップし、検証をすることにしました。下記が候補となったサービスです。
-
Mathpix
- 数式を取り扱ったことがある人であれば一度は耳にしたことがあるであろう数式に特化したOCRツールです。
- 数式だけではなく化学式なども読み取る事が出来るので期待が大きい。
-
Azure AI Document Intelligence
- Microsoftが提供するOCRサービス。
- 印刷されたテキストや手書きのテキスト、表として表現されたデータを構造も含めて抽出できる。
- アドオンの一部に数式を抽出する機能があり(ocr.formula)、それを利用してみる。Mathpixに対してどれくらいの精度で抽出ができるかが楽しみ。
-
Vertex Document AI
- Googleが提供するOCRサービス。
- こちらも印刷されたテキストや手書きのテキストなどからテキスト情報を抽出するもの。
- Azure AI Document Intelligenceと同様にアドオンで数式抽出の機能あり(OCR add ons)。こちらもどれくらいの精度が出るのかが楽しみ。
それでは検証結果を見ていきましょう。
Mathpix
Mathpixを用いてテキスト抽出を行った結果がこちらになります。

読み込ませた問題1とアウトプット
数式のところがどれだけ精度高く抽出できるかが一つ大きな課題だと思っていましたが、数式に特化したサービスということもあり、流石の認識精度です。数式に関しては正確に抽出できていますね!
ですが、もう一つの観点であるルビが読み取れること、については残念ながら期待する結果にはなりませんでした。

読み込ませた問題2とアウトプット。ルビが入っている状態だとかなり厳しい。
Mathpixは非常に高性能なOCRサービスではありますが、今回COMPASSで実現したいユースケースに対しては適していないということがわかりました。
Azure AI Document Intelligence
Azure AI Document Intelligenceを用いてテキスト抽出を行った結果がこちらになります。

画像中に含まれるテキスト、数式がある程度正確に読み取れているが、テキストと数式は別々に抽出される。(画面右のタブで切り替え)

ルビ入りの問題。若干ノイジーではあるもののMathpixよりはちゃんと認識できている。
Mathpixのように数式に特化したものではないので、数式の方が心配でしたが、数式に関しては問題なく認識ができている事がわかります。問題のルビが入った問題に関してですが、抽出のされ方に若干クセはありますがMathpixよりは読み取れています。
ですがやはり文字と数式が別々に抽出されたり、ノイズが入ってしまったりと、利用の候補とはなるものの、期待する要件を完全に満たしているかというとそうではないという結果になりました。
Vertex Document AI
Vertex Document AIを用いてテキスト抽出を行った結果がこちらになります。

文字と数式が一緒に出力されており、数式の認識精度も高い。

ルビ入りの問題。そもそもルビの領域の認識の精度がすごい。
結果としては、数式の認識もルビの認識も問題なく行えるという結果になりました。抽出できる情報という観点ではAzure AI Document Intelligenceも数式、ルビを抽出できてはいるのですが、結果を見ていただいて分かる通り、今回のユースケースにおいてはVertex Document AIのアウトプットが最も期待するものに近かったので、今回はVertex Document AIを採用することになりました。
抽出した問題文、数式をLLMを用いて校正
一つ前のステップで、Vertex Document AIによって数式と文字が抽出できました。しかし、数式と文字の抽出はできているものの、画像で表現された問題文を正確に表現するという目標に対してはまだまだギャップがある状態です。したがって、実際の問題画像データを見ながら、抽出された数式と文字を問題文の通りに組み立てていくという作業が必要になってきます。こちらもアプローチとしては人間の手でやるという方法も取り得なくもないのですが、やはり膨大な時間とコストがかかると考え、その作業をLLMに任せてみることにしました。そこで今回使ってみたのがGPT-4 Visionです。
GPT-4 Visionはテキストと画像を同時に処理をする事ができるマルチモーダルなLLMです。具体的には、画像に何が表現されているかの認識、認識結果に対する質疑応答、認識された画像についての説明ができます。例えば3本のりんごの木が写っている画像に対して、りんごの木が写っているという事実の認識、何本のりんごの木が写っていますか?という質問に対する回答、この画像にはりんごの木が3本写っていますという説明ができるというようなものです。これができるのであれば問題文を読んで、与えられたパーツを問題文通りに復元することもできるのではないかと考えました。
実際の作業としてはGPT-4 Visionに、抽出された数式と文字のデータと、対象となる問題の画像のデータを見比べて、問題文を再現させるようなプロンプトを与えました。実際にそれらを与えてみた結果がこちらになります。

問題例1。左から順にインプットした画像、インプットしたテキスト、アウトプットされたテキスト。

問題例2。左から順にインプットした画像、インプットしたテキスト、アウトプットされたテキスト。緑で表現された空欄も空欄として出力してくれている、素晴らしい!
このように、問題文がかなり正確に再現されていますね!精度的にどこまでのものが出来上がるかという心配はあったのですが、最新のLLMの凄さを思い知りました。。
イラストやグラフの内容の抽出
ここまでの工程で問題文を再現するというところまではOCR、LLMを組み合わせることによって実現できました。ですが、問題の多くにはイラストやグラフが用いられており、それが一体何を表しているかというところまではまだわかりません。問題に対してどのようなイラストやグラフが用いられているかという内容がテキストで抽出できれば、問題データを完全にテキストで表現できることになります。そこで、校正に用いたGPT-4 Visionを用いて、問題に含まれているイラストやグラフの内容の抽出を行ってみました。
具体的には、校正のステップで再現された問題文と、問題画像をインプットとし、問題画像の内容を<figure>タグ内にテキストで表現させるプロンプトを GPT-4 Vision に与えました。実際にそれらを与えてみた結果がこちらになります。

左から順にインプットした画像、インプットしたテキスト、アウトプットされたテキスト。問題に用いられている図形がどういった図形かを正確に表現してくれています

左から順にインプットした画像、インプットしたテキスト、アウトプットされたテキスト。こちらは線の色まで表現してくれています。
このように、かなり正確にイラストに関する内容を説明してくれました!
GPT-4 Visionを用いた画像についての説明はかなりチューニングの幅が広く、画像についての説明を求めた際に問題を解くのに不必要な説明などが含まれたり、説明量が膨大になったりしてしまう事があったので、適切な形でアウトプットをするようにプロンプトの工夫を行いました。一方で、アウトプットの幅が広く、他にも色々なシーンで応用できそうだなと感じました。
まとめ
今回は画像データとして扱われていた算数・数学の問題を下記のステップでテキストデータに落とし込みました。
- Vertex Document AIを用いて、画像データに含まれる数式、ルビを含むテキスト情報の抽出
- GPT-4 Visionを用いて、1で抽出された情報を校正
- GPT-4 Visionを用いて、画像データに含まれるイラストのテキスト化
問題画像をテキストデータとして扱えることによって、より詳細な問題同士の類似度判定や、問題間の相関分析などができるようになり、今後より良い教材を提供するにあたっての土台部分が出来上がったと考えています。今回抽出したデータをさらに利活用した事例についてはまた別記事で紹介させていただければと思います。
また、人の手を介在させると非常に工数のかかる作業も、こういった技術の組み合わせで効率的に解決できるようになってきました。今後もCOMPASSでは最新技術を駆使した課題解決を行っていきたいと考えています。
最後に、ここまでお読みいただいてありがとうございました。本記事が皆様の課題解決の一助になれば幸いです。
おまけ
ここまで読んでいただいた方はお気づきかもしれないですが、LLMがこんなに綺麗に問題文読めるなら最初からLLMに渡せばいいじゃん?というご意見もあるかと思います。ですが、事前の検証段階ではGPT-4 VisionやGemini Proでは文字、数式認識の精度が期待を下回っており、OCRサービスを用いるという選択をした背景がありました。そして、本検証を行っていたのが2024年の1月頃だったのですが、LLMの進化のスピードは私たちの想像よりもはるかに早く、2024年3月4日にはAnthropic社より次世代AIモデルのClaude3が発表されました。Claude3はニーズに合わせた3つのモデル(Opus、Sonnet、Haiku)が用意されており、精度に優れたOpusではGPT-4を上回るデータが示されています。
そこで、再度OCR+LLMで行っていた問題文、数式の抽出と、抽出した問題文、数式の校正をClaude3 Opusで検証してみました。(そして記事の執筆最中にまさに検証していた内容になるのでおまけパートに記載しています)
まずは数式がちゃんと読み取れるかの検証。

数式がメインの問題での検証結果。あれ?めちゃめちゃいい感じに出てる?
結果として数式の認識精度としては驚くほどの精度で抽出できました。これは期待できるかもしれません。次に、ルビが入っている問題でも検証してみました。

ルビそのものは読めているものの、全体的な抽出精度がいまいち。
ルビが読めているという点は良いのですが、たとえば選択肢の前の文章が抽出できていなかったり、選択肢そのものが抽出できていなかったりします。他の問題画像でも色々試してみましたが、必要なものが全て抽出されないという傾向が目立ちましたので、OCRに比べるとやはり精度は落ちてしまうという結果になりました。また、一部の問題ではそもそも日本語の認識精度が低いという例も見られました。

パッと見はできてそうな気はしますが、「ろくじょう」「らんしゅう」など、問題に記載されていない文字列も含まれている。
このように、問題の表現のされ方によって著しく文字認識の精度が落ちてしまう傾向が見られ、こちらもOCRに軍配が上がりました。
以前と比べてかなり精度は向上したと考えていますが、OCRと比較するとやはり期待したアウトプットには届きませんでした。したがって、問題文の抽出は現状通りVertex Document AIを用いて進めていく方針となりました。しかし、LLM技術は非常に速いスピードで進化しており、今後も新しい技術が発表された際には積極的に様々な検証を行っていきたいと思いますので、その際はまた記事にできればと思っています。

学習eポータル+AI型教材「Qubena(キュビナ)」を開発している株式会社COMPASSです! 弊社に興味をお持ちいただいた方はキャリア登録をお願いします!最新情報や求人情報をお届けします! →app.crm.i-myrefer.jp/entry/qubena/14pXH9t0sDocJgU7TD1q
Discussion
こんにちは
正しく同じ問題に取り組んでいるものです。
Google Document AIを使用しております。
記事内の画像のようにDocument AIが返してきた結果を可視化するツールを教えていただけませんか?
Google Cloudを使うのは初めてで探してもなかなか出てこなくて本当に困っています。
記事内のものはgoogleの公式ツールでしょうか?それともサードパーティのものでしょうか?
コメントありがとうございます。
返信が遅くなり申し訳ありません。
以下の画面のことでしょうか?
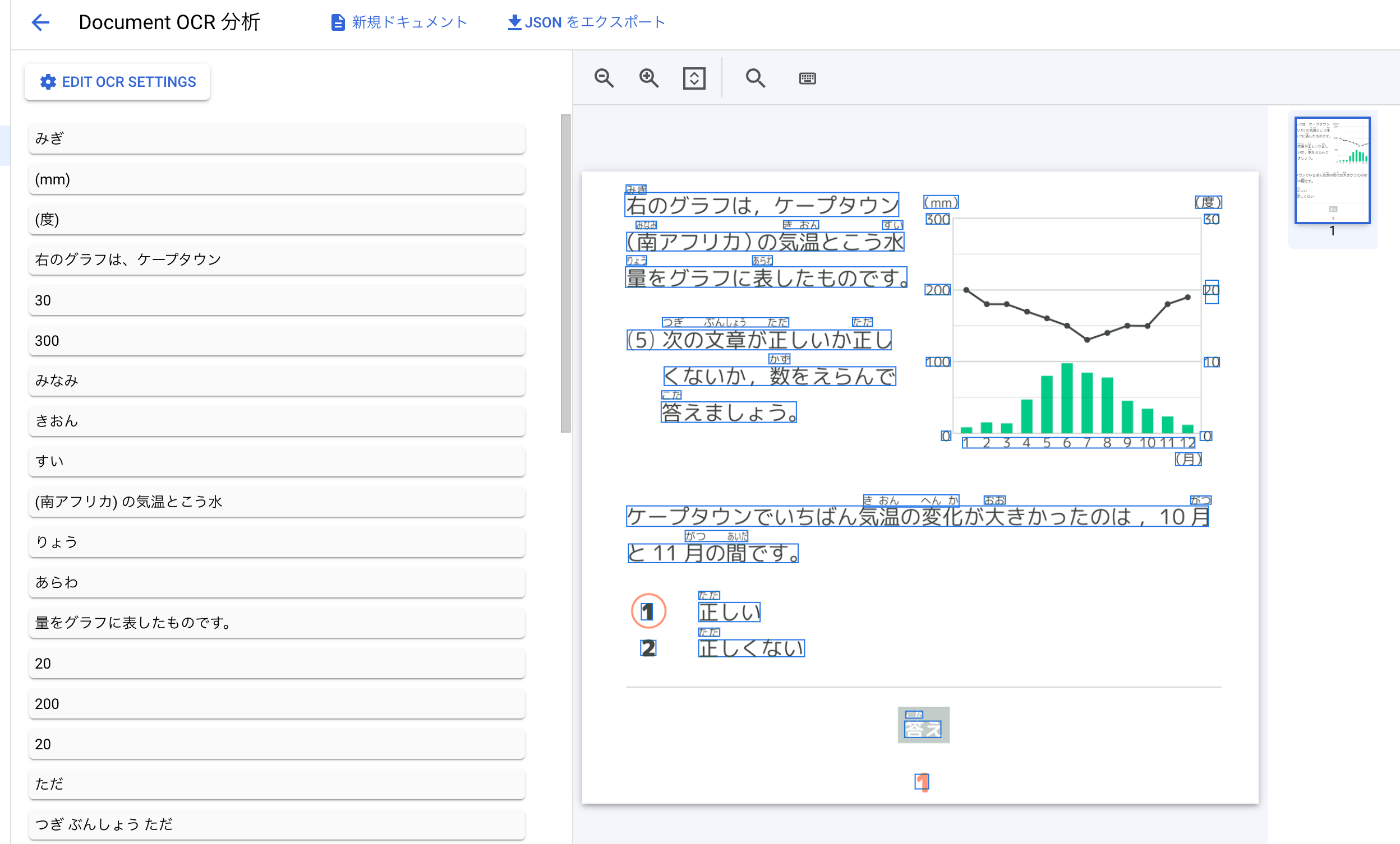

こちらは Document AI で何らかのプロセッサを作成し、プロセッサのテストでテストドキュメントをアップロードした際のものです。
返信ありがとうございます。助かりました!