🍀この記事はこんな方におすすめ
- テスト設計に膨大な時間を取られて、もっと価値の高い業務に時間を使いたいと思っている方
- AIを活用したいけど「何から始めればいいの?」と悩んでいるQAの方
- AI導入の成功事例だけでなく、リアルな失敗談や苦労話も知りたい方
- テスト設計を効率化させたいQAエンジニアの方
なぜAIでテスト設計を効率化しようと思ったのか
QAエンジニアの皆さん、日々のテスト設計業務お疲れ様です!
私たちの会社では、ここ最近AI活用の波が押し寄せています。
開発チームはコーディング効率化やAIでの自動化、資料の叩き台を自動化し効率化などなど...
「じゃあ、QAでは?」
そんな問いかけから、AI活用を真剣に検討し始めました。QA業務の中で「時間がかかっているプロセスは何か?」を考えた結果、浮かび上がってきたのがテスト設計でした。
仕様書を読み込んで、因子と水準を抽出して、組み合わせを考えて、テストケースを作成して...この一連の作業が1日ほどかかっていたのです。特に大規模なプロダクトだと、考慮すべき組み合わせが膨大になって、経験豊富なQAエンジニアでも丸2日かかることも。
「ここをAIで効率化できれば、もっと探索的テストや品質改善活動に時間を使える!」
そんな想いから、AIを活用したテスト設計効率化の推進がスタートしました。今回は、それを約2時間程度まで削減できた試行錯誤の過程と、ぶつかった壁、そして(まだ完全ではないですが)見えてきた光明について共有したいと思います。
Step1: 仕様書から因子と水準を自動抽出する挑戦
最初の壁:AIは「因子」と「水準」を理解してくれない!
まず最初に取り組んだのは、仕様書から因子と水準を自動で抽出する仕組みの構築でした。
「仕様書をAIに読ませれば、サクッと因子と水準を抽出してくれるでしょ」
...なんて甘い考えは速攻で打ち砕かれました😅
AIに「この仕様書から因子と水準を抽出して」と頼んでも、返ってくるのは的外れな結果ばかり。
そりゃそうですよね、AIにとって「因子」や「水準」って何?という状態なわけです。
解決策:自社のテスト設計に合わせた「言語化」
ここで重要だったのが、自社のテスト設計における「因子」と「水準」を明確に言語化することでした。
例えば:
- 因子とは:「テスト対象の機能や条件を表す変数のこと。ユーザーの操作や環境設定など、テスト結果に影響を与える要素」
- 水準とは:「各因子が取りうる具体的な値や状態のこと。例えば、ブラウザという因子に対して、Chrome、Firefox、Safariなどが水準となる」
このような定義をプロンプトに組み込むことで、AIの抽出精度が劇的に向上しました。
Step2: 組み合わせ生成ツールの開発
Webツールを作成した理由
因子と水準の抽出ができるようになったら、次は組み合わせの生成です。抽出した因子と水準から、2因子間網羅や3因子間網羅のテストマップを自動生成できるWebツールを作成しました。
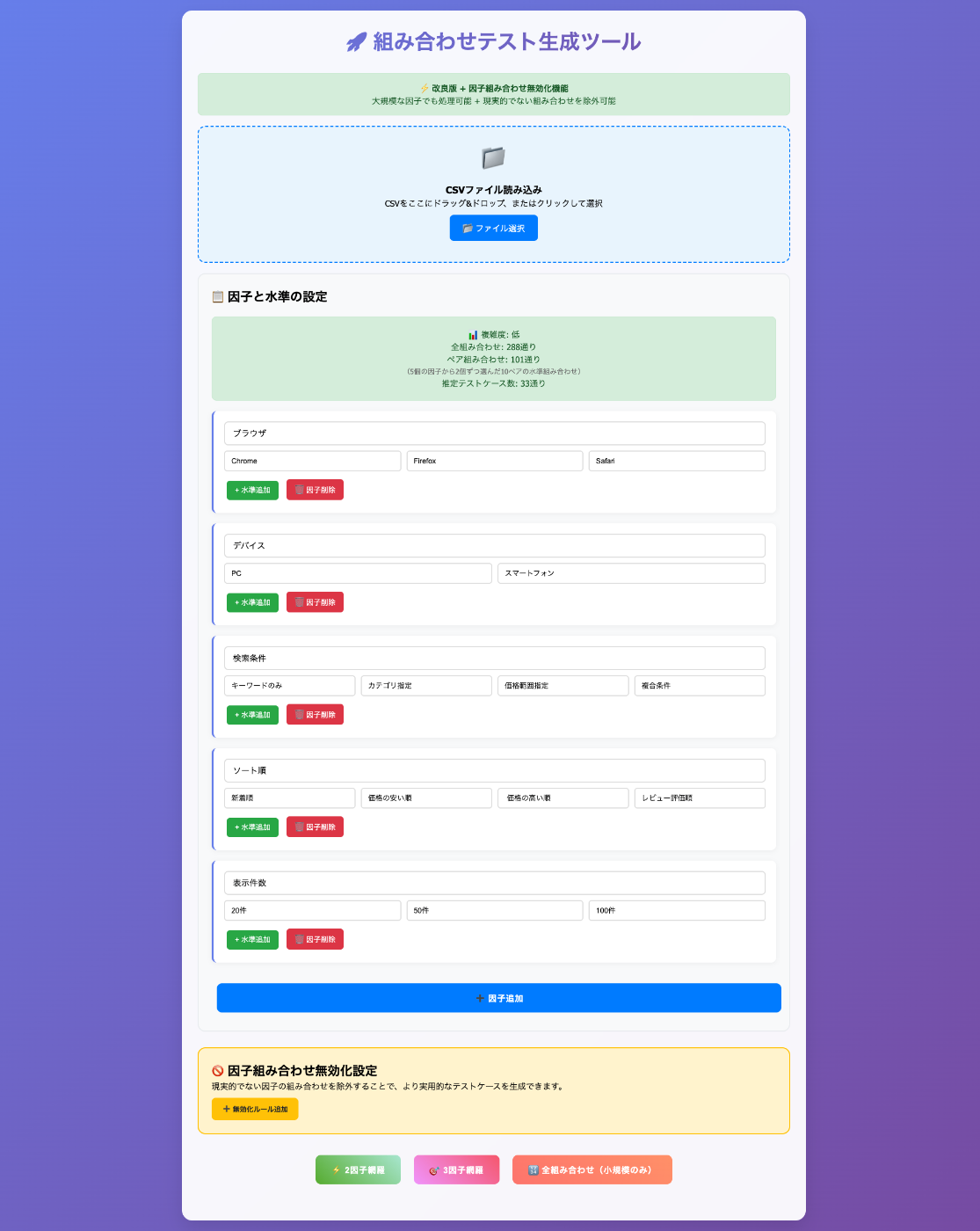
なぜWebツール?と思われるかもしれませんが、理由は単純です:
- チーム全員が使いやすい
- インストール不要でブラウザがあればOK
- 結果の確認が視覚的にできる
え、でもWebツール作成のスキルは...?
「HTMLとかJavaScriptとか、そんなに詳しくないんだけど...」
大丈夫です!ここでもAIの出番です🤖
実は、このWebツール自体もAIに作ってもらいました。私がやったのは:
要件を整理してAIに伝える
- 「CSVファイルから因子と水準を読み込めるようにして」
- 「2因子間網羅と3因子間網羅のアルゴリズムを実装して」
- 「結果をCSVでダウンロードできるようにして」
- 「全網羅のデータもCSVでダウンロードできるようにして」
生成されたコードを実行してフィードバック
- 「組み合わせ不要な因子・水準をUIから削除できるようにして」
- 「エラーハンドリングを追加して」
- 「日本語の文字化けを直して」
AIも完璧じゃない!生成コードの落とし穴
ただし、AIとの共同作業も一筋縄ではいきませんでした。
例えば、「組み合わせ不要な因子・水準をUIから削除できるようにして」と依頼したときの話です。
AIが生成したコード:
- ✅ UIから削除ボタンで消すことができる
- ❌ 読み込ませたデータには残ったままになる
- ❌ 組み合わせ実行時に削除したはずの水準が使われる!
「えっ、削除したのになんで結果のCSVには削除した因子・水準が出てくるの!?」
よく考えてみれば、私の指示は「UIから削除できるようにして」だけでした。まさか表示を消すだけで、実際のデータロジックからは削除してもらえないとは...
この経験から、AIに指示を出すときは「何をしたいか」だけでなく、「その結果どうなってほしいか」まで含めて伝える必要があることを学びました。
結局、以下のような修正指示を追加で出しました:
- 「削除時は表示だけじゃなくてデータ配列からも削除して」
- 「削除前に確認ダイアログを出して」
- 「元に戻すボタンも追加して」
こんな感じで、プログラミングの専門知識がなくても、AIとの対話を通じて実用的なツールが作れました。ただし、生成されたコードは必ずテストして、期待通りに動くか確認することが重要です。QAエンジニアならではの品質チェック意識が、ここでも活きてきますね!
苦労ポイント①:ランダム要素の罠
組み合わせ生成ロジックで各水準を均等に使用するため、最初はランダム要素を含むアルゴリズムで実装されていました。しかし、これが思わぬ落とし穴に...
実行するたびにテストケース数が変わってしまう!
「さっきは50ケースだったのに、今度は52ケース...えっ、今度は48?」
品質保証の観点からすると、これは致命的です。同じ条件なら同じ結果が得られるべきですよね。
解決策:ランダムを完全排除!
この問題を解決するため、ロジックからランダム要素を完全に排除しました。新しいアルゴリズムでは:
- 全ての水準を必ず同じ回数使用する
- 割り切れない場合は±1回までの差を許容
例えば、3つの水準で10個のテストケースを作る場合:
- 水準A:3回
- 水準B:3回
- 水準C:4回(±1の範囲内)
このアプローチにより、実行結果が安定し、再現性のあるテスト設計が可能になりました!
苦労ポイント②:CSV連携での文字化け地獄
抽出した因子と水準をCSV形式で保存し、それを読み込む仕組みを実装しました。CSVなら確認も編集も簡単!と思ったのですが...
文字コードの統一ができず、日本語が文字化けする問題が発生
「テスト」が「繝��繧ケ繝�」みたいになって、「あー、文字コードか...」という感じでした。
CSVの文字化け問題は定番ですよね。UTF-8 with BOMに変更することで解決しました。ただ、この手の細かい調整が必要になるのは、CSVを扱う上での「あるある」だなと改めて実感しました。
Step3: AIによるテストケース自動生成
理想:テストマップのCSVを読み込ませて仕様書からの情報でテストケースが作れる!
というのが理想だったのですが、そんなわけはないですよね...
仕様書からの情報でテストケースの生成をしてみたところ、こんな結果に:
テストケース:ユーザー登録機能の確認
手順:
1. ユーザー登録画面を開く
2. 必要事項を入力する
3. 登録を実行する
一見問題なさそうですが、実際にテストする人からすると:
- 「事前準備は何が必要?DBは初期化する?」
- 「テスト用のメールアドレスは準備済み?」
- 「ユーザー登録画面ってどこから開くの?」
- 「必要事項って具体的に何?」
- 「登録を実行するボタンの名前は?」
- 「テスト環境の設定は?権限は必要?」
実行不可能なテストケースの完成です😱
前提条件の作成や正しい画面遷移の情報が必要でした。
そこで思いついたのが...フロントのコードも連動することにより正しい情報が取れるのでは...!ということでした。
改善策:フロントエンドコードの活用
この問題を解決するため、プロダクトのフロントエンドコードも読み込ませることにしました。
// 例:ボタンのコンポーネント定義から
<Button id="submit-registration" label="新規登録" />
UIの情報を活用することで、必要な要素が取得できるため、より具体的なテストケースが生成できるようになりました:
またどのような条件の場合に表示させるかなどの情報も取得できるようになったため、事前準備もある程度まで記載できるようになりました。
テストケース:ユーザー登録機能の確認
事前準備:
- テスト環境のDBをクリーンな状態にする
- メール送信のモックを有効化
- テスト用メールアドレス "test@example.com" が未登録であることを確認
手順:
1. ヘッダーメニューの「新規登録」リンクをクリック
2. メールアドレス欄に"test@example.com"を入力
3. パスワード欄に"Test123!"を入力
4. 「新規登録」ボタンをクリック
まだ残る課題:トークン数の限界
ただし、複数のチームが開発している機能については、まだ完全な自動化には至っていません。
問題の本質は、AIのトークン数(処理できる文字数)の限界でした。
技術的には複数チームのUI情報を読み込ませることは可能です。
しかし...
- Aチームのフロントエンドコード:20,000トークン
- Bチームのフロントエンドコード:25,000トークン
- Cチームの共通コンポーネント:18,000トークン
- 仕様書とその他の情報:5,000トークン
合計すると68,000トークン...もうこれだけでだいぶ使い込んでしまってますよね。さらにマトリクス表などを読み込んだ場合には、AIのトークン上限に到達してしまいました。
単一チームのコードでもそこそこのトークンを使用するのに、複数チームのコードを統合しようとすると、この上限に引っかかってしまうことが多いです。
現在は以下のような対策を検討中です:
- 必要最小限のコードのみを抽出する前処理の実装
- チームごとに分割して処理し、後から統合する方式
- より大きなトークン数を扱えるAIモデルへの移行
トークン数の制約は、AIを実務で活用する際の重要な考慮事項だと改めて実感しました。
細かいけど重要な改善点:期待結果の分割
もう一つ気づいた課題が、AIが生成したテストケースは1つのケースに複数の期待結果を詰め込んでしまっていたこと。
改善前:
テストケース1:ユーザー登録機能の確認
期待結果:
登録完了画面が表示される
確認メールが送信される
DBにユーザー情報が登録される
1つのテストケースに複数の期待結果があると、NGになった時に問題箇所を後から特定しづらくなります。だから私は期待結果ごとにケースを分けるようにしていました。でも、この「私にとっての当たり前」をAIは知らない。そりゃそうですよね、伝えてないんですから。
改善後:
テストケース1-1:ユーザー登録後の画面遷移確認
期待結果:登録完了画面が表示される
テストケース1-2:ユーザー登録後のメール送信確認
期待結果:登録したメールアドレスに確認メールが送信される
テストケース1-3:ユーザー登録後のDB登録確認
期待結果:DBにユーザー情報が正しく登録される
AIに「期待結果ごとにテストケースを分割して」という指示を追加することで、ようやく実務で使えるレベルのテストケースが生成されるようになりました。
Step4: 再現性の確保 - プロンプト手順書の作成
属人化を防ぐための仕組みづくり
ここまでの試行錯誤で、AIを使ったテスト設計がある程度形になってきました。でも、新たな課題が浮上しました。
「これ、他のメンバーにも使ってもらうには?」
各ステップでAIへの指示を工夫したり、細かい調整を重ねてきましたが、それらのノウハウが私の頭の中にしかない状態でした。これでは、せっかくの効率化も属人化してしまいます。
AIにプロンプト手順書を作らせる
そこで考えたのが、AIに自身への指示方法をまとめた手順書を作成してもらうということでした。
「今までのやり取りを踏まえて、他の人でも同じようにテスト設計ができるプロンプトの手順書を作成して」
AIは今までの対話内容を分析し、以下のような構成の手順書を生成してくれました:
- 因子・水準抽出フェーズの詳細な指示方法
因子・水準抽出プロンプト(一部抜粋)
1. 指定された画面仕様書およびそのサブページの情報を取得してください
2. 仕様書の内容を分析し、以下のような観点から因子と水準を抽出してください
- ユーザー入力要素(検索、選択、入力フィールドなど)
- 画面表示要素と条件(表示項目、表示形式など)
- システム状態と条件(データ状態、処理状態など)
- 処理機能(ソート、フィルタリング、ページネーションなど)
- 画面遷移と導線(リンク、ボタン、メニューなど)
- 機能制限と条件(有効/無効、表示/非表示など)
- データ間の依存関係(必須/任意、連動するフィールドなど)
- その他仕様書から読み取れるテスト観点
など「仕様書に記載された全ての状態・動作・表示・遷移・初期値」を因子として抽出してください。
3. 仕様書に明示的に記載されている情報のみを使用し、推測は含めないでください
---
(中略)
---
6. 結果をCSVファイルとして以下の形式で出力してください
- ファイル名: [日付]_[機能名]_test_design.csv
- 形式: 因子,水準1,水準2,...
- 組み合わせ生成フェーズでの注意点とパラメータ設定
- テストケース作成フェーズで必要な情報と出力形式
テストケース作成プロンプト(一部抜粋)
### 作業内容
1. マトリクスファイルの各テストケース(列)を分析
2. リポジトリ内の対象機能のソースコードを詳細に調査
3. 実装に基づいた具体的なテスト手順を作成
4. **マトリクス表の全テストケースを漏れなく詳細化**
5. **各テストケースを単一期待結果のサブテストケースに分割**
6. CSV形式で詳細テストケースを出力
### 注意事項
---
(中略)
---
## 調査対象
フロントエンドリポジトリから以下の情報を抽出してください:
### 1. UIコンポーネント情報
- コンポーネントファイルの場所と構造
- 入力フィールドのID、name、placeholder等の属性
- ボタン、リンク等の操作要素のセレクタ情報
- フォームバリデーションの実装詳細
### 2. 状態管理・制御ロジック
- 各UI要素の有効/無効切り替え条件
- エラーメッセージの表示条件と正確な文言
- 画面遷移や表示状態の変化条件
---
(中略)
---
## 作業手順
### 1. マトリクス表の分析
1. マトリクス表の因子と水準の組み合わせを理解
2. 各テストケース(列)でどの因子が「●」になっているかを確認
3. テストケースの意図や狙いを把握
### 2. リポジトリの調査
1. 対象機能に関連するコンポーネントファイルを特定
2. 各ファイルの詳細な実装内容を確認
3. セレクタ情報、バリデーション条件、状態制御ロジックを抽出
### 3. テストケース詳細化
1. マトリクス表の各列について詳細テストケースを作成
2. 実装に基づいた具体的な操作手順を記載
3. 確認観点と期待結果を明確に定義
### 4. 品質確認
1. 全テストケースが実行可能な手順になっているか確認
2. セレクタや入力値が実装と一致しているか確認
3. 境界値テストや異常系テストが適切に含まれているか確認
---
(省略)
---
各フェーズごとに、これまでの試行錯誤で得られた「こう指示すればうまくいく」というノウハウが整理され、誰でも同じ品質のテスト設計ができるような内容になりました。
手順書の効果
この手順書を作成したことで:
- チームメンバーも同じ品質でテスト設計ができるようになった
- 新しいプロジェクトでも同じアプローチが使える
- プロンプトの改善点が明文化され、継続的な改善が可能に
まとめ:AIによるテスト設計効率化の現在地
できるようになったこと
- 仕様書からの因子・水準の半自動抽出 - 言語化により精度向上
- 安定した組み合わせテストケースの生成 - ランダム要素を排除し再現性を確保
- 基本的なテストケース作成 - フロントコードとの連携で実用レベルに
まだ課題として残っていること
- トークン数の制約への対応 - 複数チームのコードを同時に処理する方法の検討
- 完全自動化への道のり - 人間のレビューはまだ必須
最後に:失敗を恐れずチャレンジしよう!
正直、最初は「AIに任せれば楽勝でしょ」という甘い考えでスタートしました。実際にやってみると、予想以上の壁にぶつかり、試行錯誤の連続でした。
でも、その過程で得られた知見は非常に価値があるものでした。特に、自分たちの業務を言語化するという作業は、AIを使う使わないに関わらず、チームの共通理解を深める良い機会になりました。
QAエンジニアの皆さんも、ぜひAIを活用した効率化にチャレンジしてみてください。最初はうまくいかなくても、必ず何かしらの学びがあるはずです。
そして、もし同じような取り組みをされている方がいれば、ぜひ情報交換させてください!一緒にQA業務の未来を作っていきましょう🚀
最後に、、、
株式会社COMPASSでは一緒に教育をより良くしていく仲間を募集しています。
少しでも興味を持っていただけた方は、以下よりお気軽にご応募ください。
とりあえず話をきいてみたい!という方はぜひカジュアル面談に来ていただけると幸いです。

学習eポータル+AI型教材「Qubena(キュビナ)」を開発している株式会社COMPASSです! 弊社に興味をお持ちいただいた方はキャリア登録をお願いします!最新情報や求人情報をお届けします! →app.crm.i-myrefer.jp/entry/qubena/14pXH9t0sDocJgU7TD1q
Discussion