こんにちは!株式会社COMPASSのシステム開発部、SREチームのごーすと(@5st7)です!普段は、k8s周りの運用であったり、アプリケーションのパフォーマンスの監視、改善、インフラ周りの自動化などを積極的に進めています。三度の飯よりも好きなものがプリンで、美味しいプリンの店とかが流れてきたら1営業日以内に馳せ参じます。プリン好きな人はお店で会いましょう。
今日は負荷試験の取り組みについてご紹介できればと思います。COMPASSが提供するキュビナは現在100万人を超えるユーザーに利用していただいていますが、その分トラフィックも大きく、安定してサービスを提供できるようにするために、様々な工夫をしています。その中でも利用の集中する時間帯の負荷に耐えられるかの検証は非常に重要な取り組みの一つです。今回は、COMPASSが今まで負荷試験にどのように取り組んできたのか、その歴史と改善を行っていった結果現在どのように運用しているかについてご紹介させていただければと思います。
この記事はこんな方におすすめ
- これから負荷試験について勉強しようと思っている方
- Kubernetes環境で負荷試験を行いたいと考えている方
- 運用して行く上でのTipsなどを知りたい方
背景
COMPASSが開発、提供する公教育向けのデジタル教材キュビナは、現在では100万人を超える子どもたちにご利用いただいています。また、学校で授業が行われている時間帯に利用が集中するため、同時接続数自体は多く、実際の数値以上に負荷に対するケアが必要となってきます。サービスのローンチ当初はAkkaを用いたCluster Shardingなどを行うことで負荷軽減を試みていました。しかし、非常に強力な技術である反面、システムの複雑化を招いてしまうというデメリットもあり、2023年夏にCluster Shardingを除去するという試みを行いました。
技術スタック、開発環境に関する内容はこちらの記事をご覧ください。
以前はCluster Shardingを用いることで負荷対策を行っていたということもあって、不定期に負荷試験を行っていましたが、上記のCluster Shardingの除去であったり、今以上にリリースの信頼性と耐久性を向上していこうということで、定期的な負荷試験の実施を行うこととしました。今回は定期的に負荷試験を行うにあたって、どのように取り組んできたかの変遷についてお話ししますが、取り組みを行った結果として、前年度と比較して安定してサービスを提供することができるようになりました。(品質保証プロセスなどのその他の要因も大きくありますが)それでは今までの取り組みについて、現在のCOMPASSの環境などを交えながら紹介していこうと思います。
COMPASSの環境について
それでは、まずはCOMPASSの環境について記載していきます。
インフラ構成
COMPASSのインフラ構成は図のようになっています。
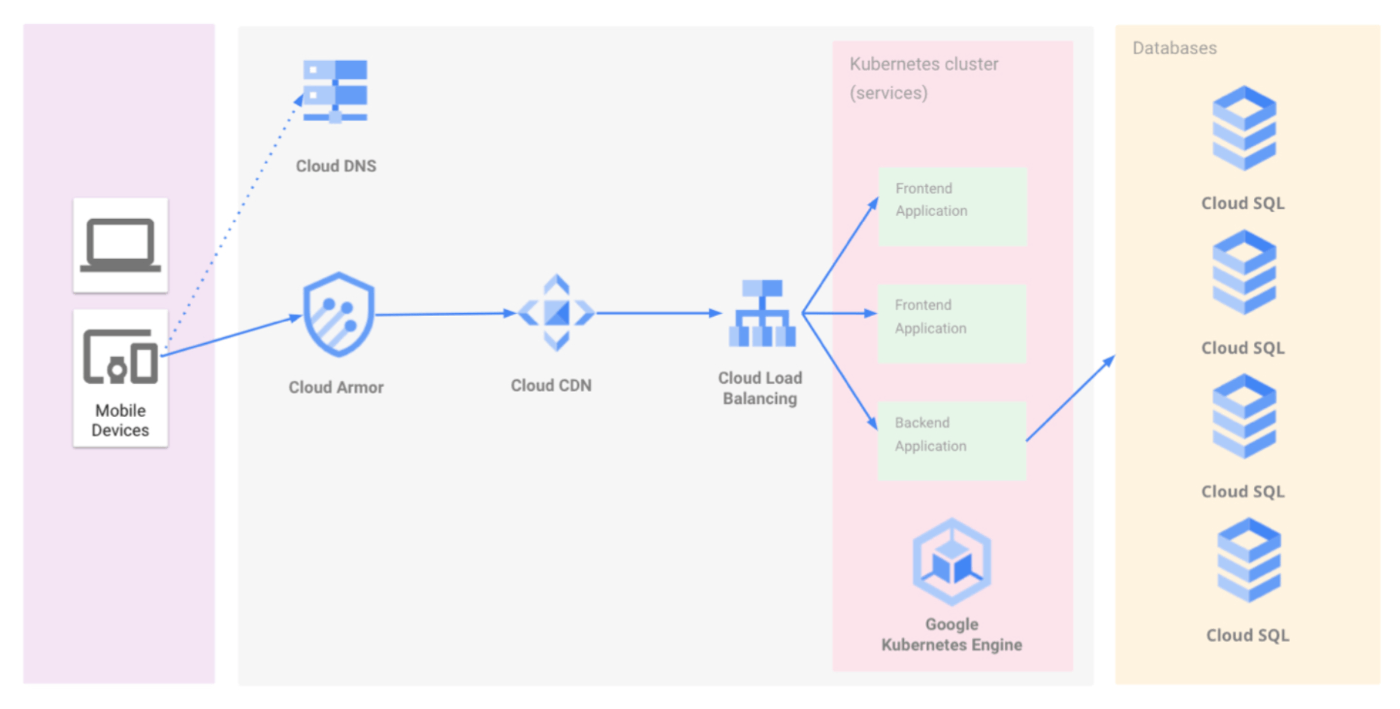
COMPASSのインフラ構成
GCPを採用していますので、基本的には全てGCPのサービスで完結するような構成になっていますが、かなりシンプルになっていると考えています。構成としてはDNS(Cloud DNS)、WAF(Cloud Armor)、CDN(Cloud CDN)、ロードバランサー(Cloud Load Balancing)、コンテナオーケストレーション(Google Kubernetes Engine)DBMS(Cloud SQL)で構成されています。
Kubernetes(k8s)について
COMPASSではコンテナの運用にKubernetes(以下k8s)を用いています。Kubernetes(クバネティス、K8s)は、コンテナ化されたアプリケーションのデプロイ、スケーリング、および運用を自動化するためのオープンソースのコンテナオーケストレーションプラットフォームです。Googleによって開発され、現在はCNCF(Cloud Native Computing Foundation)によって管理されています。
現在COMPASSではクラウドサービスとしてはGoogle Cloud Platform(以下GCP)を用いていますが、キュビナをローンチする前の技術選定段階で、今後のクラウドサービスの動向を踏まえて、できる限りそれぞれのクラウドサービスへの依存度を減らそうという動きがありました。その中で、k8sはOSSというところで各種クラウドサービスへの依存が少ないという点は非常に魅力的でした。また、キュビナの利用者はローンチ当初から急激に増えていた状況であり、スケールがしやすいというところも採用するにあたって大きなメリットだと考え、採用に至りました。
私自身はCOMPASSに参画する前もk8sを運用していましたが、COMPASSに参画してからGoogle Kubernetes Engine(以下GKE)を初めて触りました。使い心地としては、なんだかんだ言ってGoogleが使いやすいように作ってくれているので使いやすいかなという印象です。また、スケールする際に「いい感じ」にやってくれるところが気に入っています。しっかり使いこなそうと思うと本当に色んなことができる仕組みではありますが、実際の現場ではまだまだ触れていない機能なども多いと思います。私はk8sがものすごく好きなので、常に改善を繰り返してよりよい環境を作るチャレンジができているところが非常に楽しいです。
本記事では、基本的にはk8sを用いた環境での負荷試験を前提としてお話をしていきます。
負荷試験のツールについて
メインの負荷試験のツールとしては、K6-Operatorを用いています。K6-Operatorは、オープンソース負荷テストツールであるK6をKubernetes環境で実行および管理するためのオペレーターです。負荷試験を行うためのツールは他にも色々存在していますが、下記のメリットを考慮してK6-Operatorを採用しました。
- シナリオベースで負荷試験ができる点
- テストスクリプトをJavaScriptで記述できる点
- GKEとClusterAutoScalerを組み合わせることで大きな負荷をかけることができる点
まず1点目のシナリオベースで負荷試験ができる点については、K6に限らず多くの負荷試験ツールでサポートされていますが、テストシナリオをコードで記述できるという点、そして2点目に記載したJavaScriptで記述できるという点はメリットが大きいと考えました。特に、JavaScriptでの記述であれば、フロントエンドエンジニアでも負荷テストのシナリオを作れるので、そういった取り回しの良さというところが魅力でした。また、K6-OperatorはそもそもGCPと相性が良いため、大きな負荷をかけられるというところをはじめ、GCP上の各種サービスとの連携がしやすいというところも良い点だと考えました。一方で負荷試験ツールの選定について、上記のメリットから現在ではK6-Operatorを採用していますが、より効率の良い負荷試験を行っていくにあたって、今後もより良いツールなどがあれば検討した上でメリットが大きければそちらを採用するなど、現状に満足せず、日々改善を繰り返していきたいと考えています。
負荷試験改善までの道のり
それでは、いよいよ負荷試験の改善についてのお話をしていきたいと思いますが、大枠のストーリーとしては、手動で負荷試験を実行していたところを、自動で実行できるように改善した結果、負荷試験の効率が上がり、システムの安定性にも寄与した、という内容になります。使用ツールは手動でも自動でもK6-Operatorを用いていますので、試験の手法自体は同じではありますが、その中でどのような工夫をして効率をよくしていったかという所に注目してご紹介できればと思います。
手動実行時代
負荷試験については、負荷試験の実行、試験結果の分析という流れで行っていました。実際にシステムに大きな負荷がかかった際に問題がないかを確認するという点については満たせていたと考えていますが、今振り返ってもかなり大変な作業を行っていたと考えています。
負荷試験の実行
手動で実行をしていた時は、ストリームアラインドチームの1つのチームが主導で負荷試験を行っていました。負荷試験の実行自体はK6のマニフェストをK6用のクラスタに手動で適用することで行えるのですが、負荷試験の準備(各種環境立ち上げなど)等を含めると作業に半日ほどかかるような状況でした。難しい作業ではないのですが、一つ一つに時間がかかるので、実行するだけでも運用としては結構重い運用になっていたと思います。
COMPASSのチーム構成についてはこちらの記事をご覧ください。
試験結果の分析
負荷試験の実行も大変ではありますが、最も重要なプロセスが試験結果の分析になります。負荷試験を行った際に各種メトリクスがきちんとモニタリングできるように、負荷試験用のダッシュボードを作成し、実際に負荷試験を行った際にどのような変化が見られるかというところを分析していました。
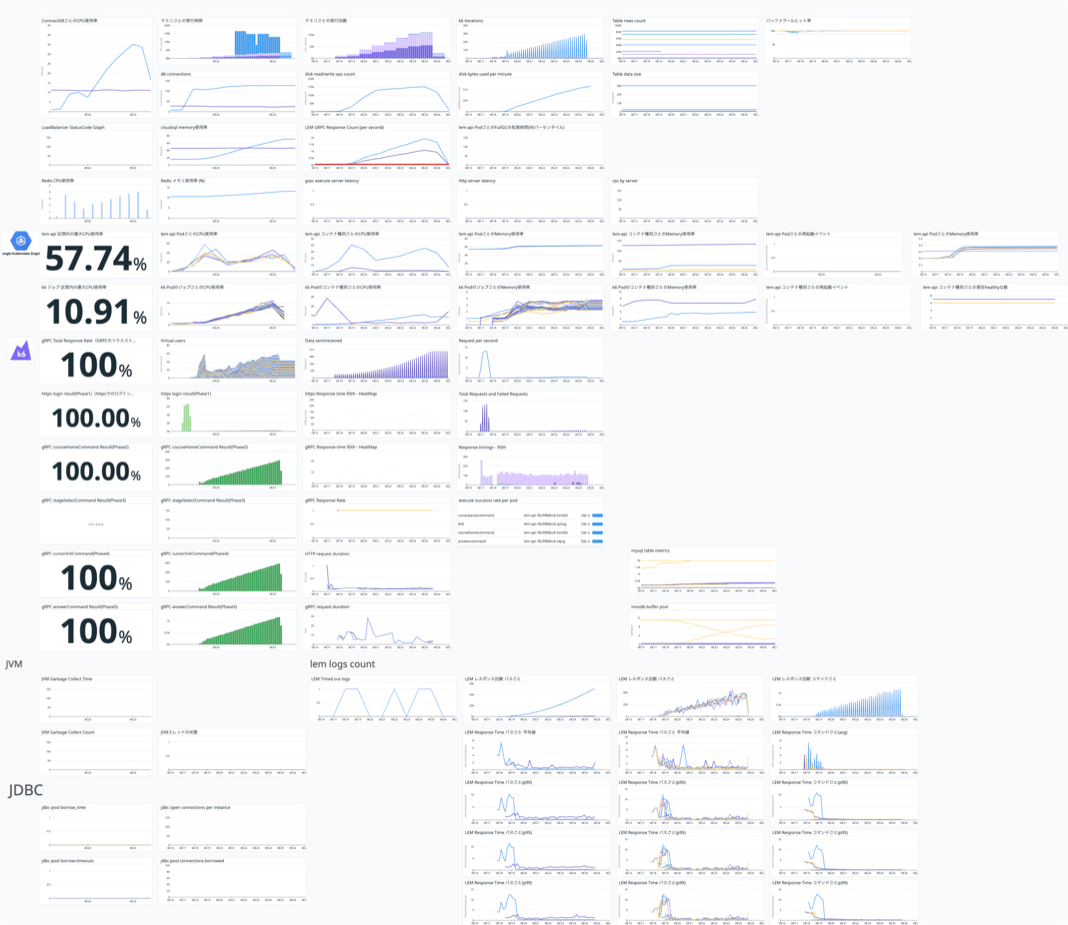
負荷試験用ダッシュボード
この時パフォーマンスの基準として、エンドポイントのレイテンシーを確認し、前回の負荷試験実行時よりも遅くなっていないか、想定外の挙動をしていないかというところを主に確認していました。ダッシュボードとしては様々なメトリクスを取り扱ってはいたので、分析を行うという意味では十分な情報が得られていたと思います。
手動実行時代の課題
前述の通り、負荷試験の目的そのものはこの運用でも果たせていましたが、実際の運用負荷がかなり高いというところが課題だと感じていました。まず、負荷試験の実行にあたる運用負荷が高いという点についてですが、実際に問題が発生して原因を分析する際に、何を更新したことに起因するかを特定するために、コミットハッシュごとに負荷試験を行うというアプローチをとっていました。ただでさえ実行に時間がかかる負荷試験をたくさん回さなければならないというところが、運用としてはかなり厳しいポイントだったと考えています。
また、負荷試験用のダッシュボードについても、確かに情報がたくさんあることは悪いことではないのですが、多くなりすぎた際に認知負荷が高まり、直感的にどこに問題があるかがわかりにくいという問題点がありました。さらに、ダッシュボードの情報と負荷試験の実行が密に連携されていたわけではなかったので、実行結果をConfluenceなどの別の媒体に都度記録しながら分析を行うなど、情報の整理という面でもかなり運用負荷が高い状況でした。
自動実行への改善
負荷試験がシステムの安定性のために不可欠であり有意義であることは実際に手動で実行をしていた時に明らかではあったので、シンプルにもっと楽に負荷試験を実行できるようにしたい...!ということで、自動実行の構成を考えていくことにしました。
結論から言うと、GitHubActionsを用いて負荷試験の実行準備から実行までを自動化し、負荷試験の実行結果サマリををSlackに投稿するという構成にしました。
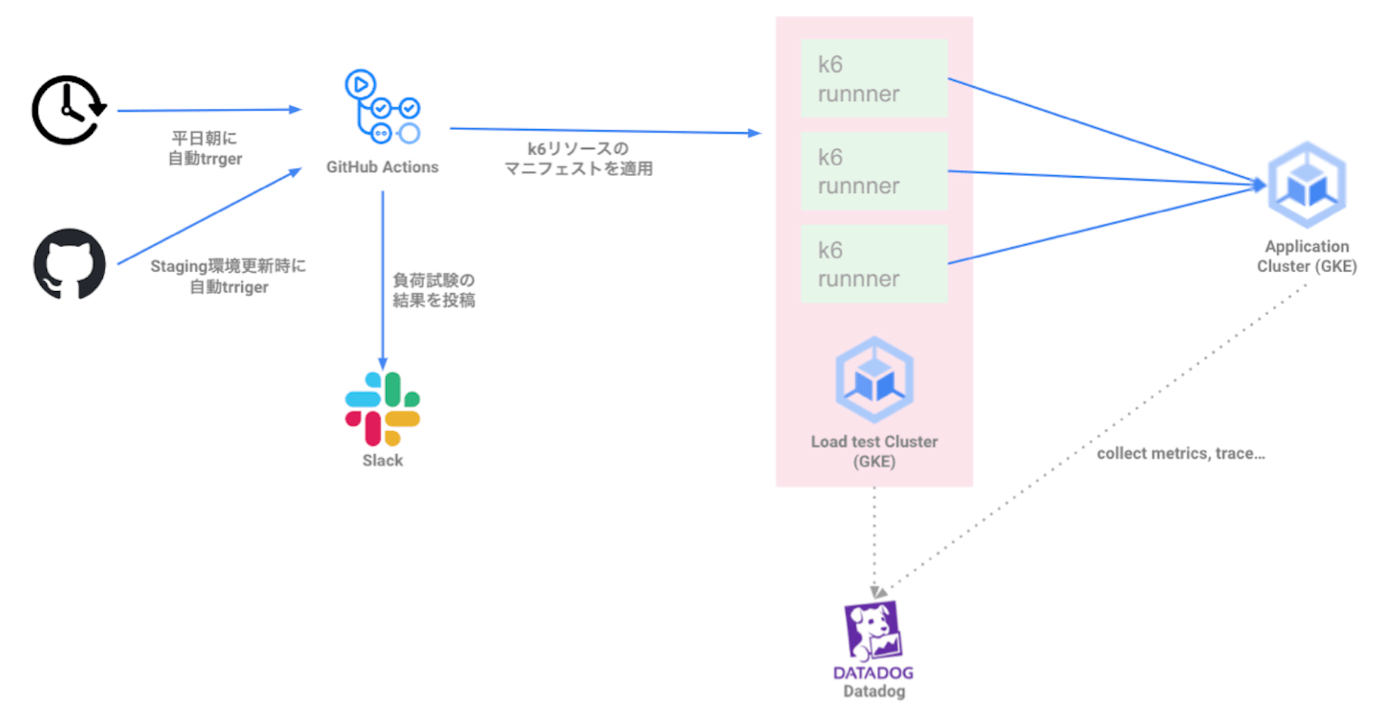
負荷試験自動化の構成
まずは負荷試験の実行に関してですが、準備から実行までをGitHubActionsから行えるようにしたので、実行に関しては全く人の手がかからなくなりました。特に大変だった準備に関しても、CloudSQLや対象のアプリケーションのPodの準備などを自動で行うようにしました。そして、自動化自体の手間もそこまで大きくかかったわけではなく、今までの実行手順をGitHubActionsのyamlに落としていき、実行してもらうだけで実現ができました。なので、実際に現在負荷試験を手動で行っているが自動化したいという方々がいらっしゃいましたらお試しいただければと思います。
次に、試験結果の分析についてですが、今までは非常に多くのメトリクスを用意したダッシュボードを用いていましたが、負荷試験の負荷量、負荷をかけた対象のイメージなどと共に、問題があるかどうかの判断に必要な情報だけをまとめたサマリーのダッシュボードを用意しました。また、負荷試験が終わったタイミングでレポートをSlackに投稿するようなワークフローを組みました。これにより、分析の際に苦労していた情報の整理の手間も省け、非常に効率の良い分析が行えるようになりました。
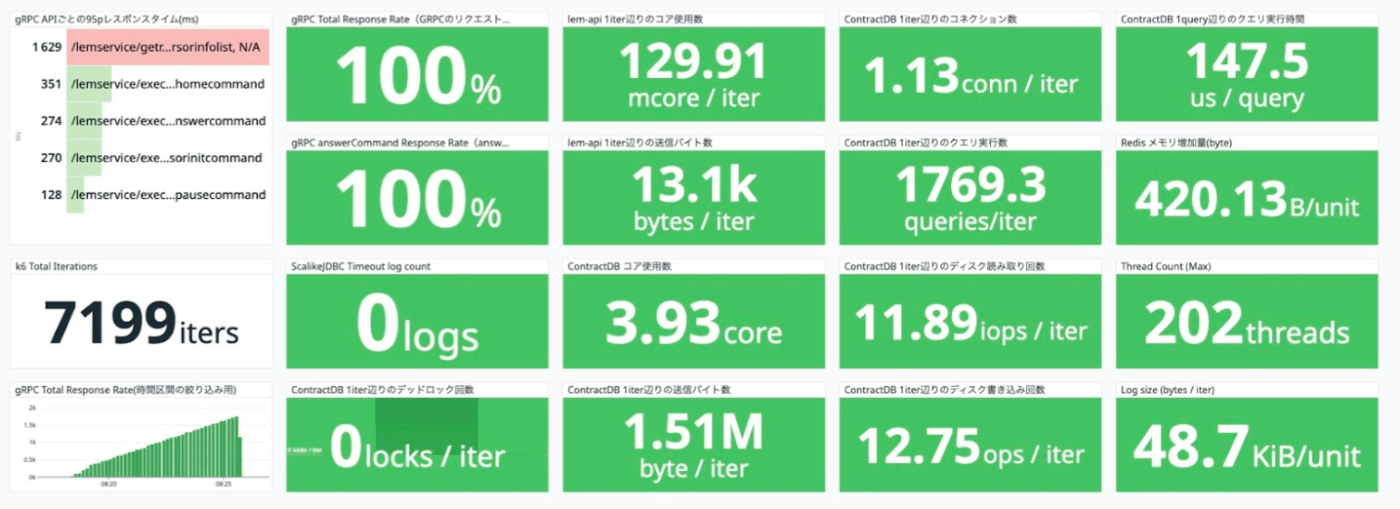
サマリーのダッシュボード。問題がない時はオールグリーン。

メトリクスの中で問題がある箇所がわかりやすいように表現。複数指標に警告が出ている例。
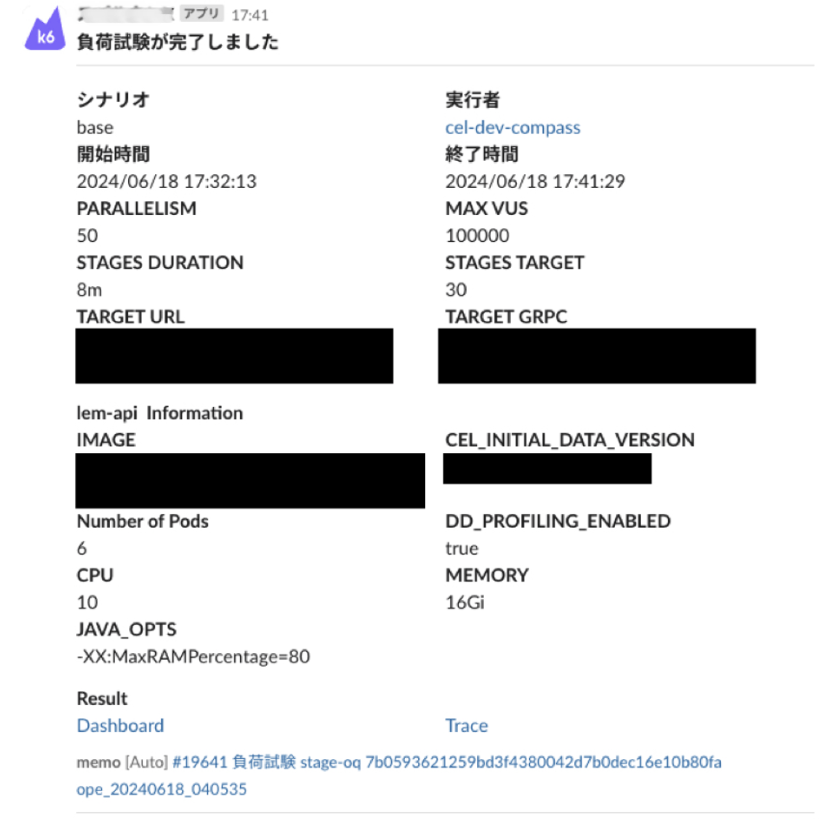
負荷試験結果のSlackへの投稿
負荷試験の実行、試験結果の分析(情報の整理)が自動で行えるようになったので、頻度についても手動実行時代よりも高く行えるようになり、開発環境のイメージに対して1日1回、ステージング環境が更新されたタイミングでステージング環境のイメージに対して1回実行するというような運用ができるようになりました。
結果的に、これらの取り組みを続けた結果、昨対比でサーバーが不安定になる事象の件数を95%減らすことに成功しました。(嘘みたいな数値ですが本当の数値です)もちろん、負荷試験以外にもQAチームの品質検証プロセスなども日々ブラッシュアップしているので、一概に負荷試験だけがこの数値に寄与しているとは言えません。ですが、こういった取り組みの一つ一つが大規模サービスの品質向上に確実に貢献できているという実感を持ちながら現在も日々改善を行っています。
まとめ
今回は負荷試験の実行から分析までのプロセスを改善し、効率化した件についてご紹介させていただきました。現状でも初期と比べるとかなり効率的になりましたが、一方で、改善ポイントはまだまだあると考えています。例えば一例として、現在はダッシュボードベースで負荷試験終了時に人が確認するというワークフローとなっていますが、確認から問題点の発見までも自動化することで、より効率的な運用ができます。このように、現状に満足せず、より良い品質でサービスを提供できるように、今後も改善を繰り返していきたいと考えています。
また、今回のような自動化の推進を行ったことで、社内のあらゆる業務に対する自動化へのモチベーションが生まれたというところも、副次的な効果として良かったことだと考えています。今回の自動化で確実に効率化に貢献できた自信はありますが、仲間からこういった声をかけてもらうことで、今回の取り組みの意義をより一層実感できました。

開発メンバーからの連絡。これに限らず日々感謝の言葉が飛び交っている。
最後に、ここまでお読みいただいてありがとうございました。本記事が皆様の課題解決の一助になれば幸いです。

学習eポータル+AI型教材「Qubena(キュビナ)」を開発している株式会社COMPASSです! 弊社に興味をお持ちいただいた方はキャリア登録をお願いします!最新情報や求人情報をお届けします! →app.crm.i-myrefer.jp/entry/qubena/14pXH9t0sDocJgU7TD1q
Discussion