SSGにclientサイド完結型の全文検索を実装した - minista v2.7
ReactのJSXで書けるスタティックサイトジェネレーター(以下SSG)ministaのv2.7にクライアントサイド完結型の全文検索を実装しました!
実物はドキュメントサイトで稼働中。...と言いますか、そもそも当のドキュメントサイトに全文検索がなくて困ったから作ったようなものですけど。
完成イメージはalgolia
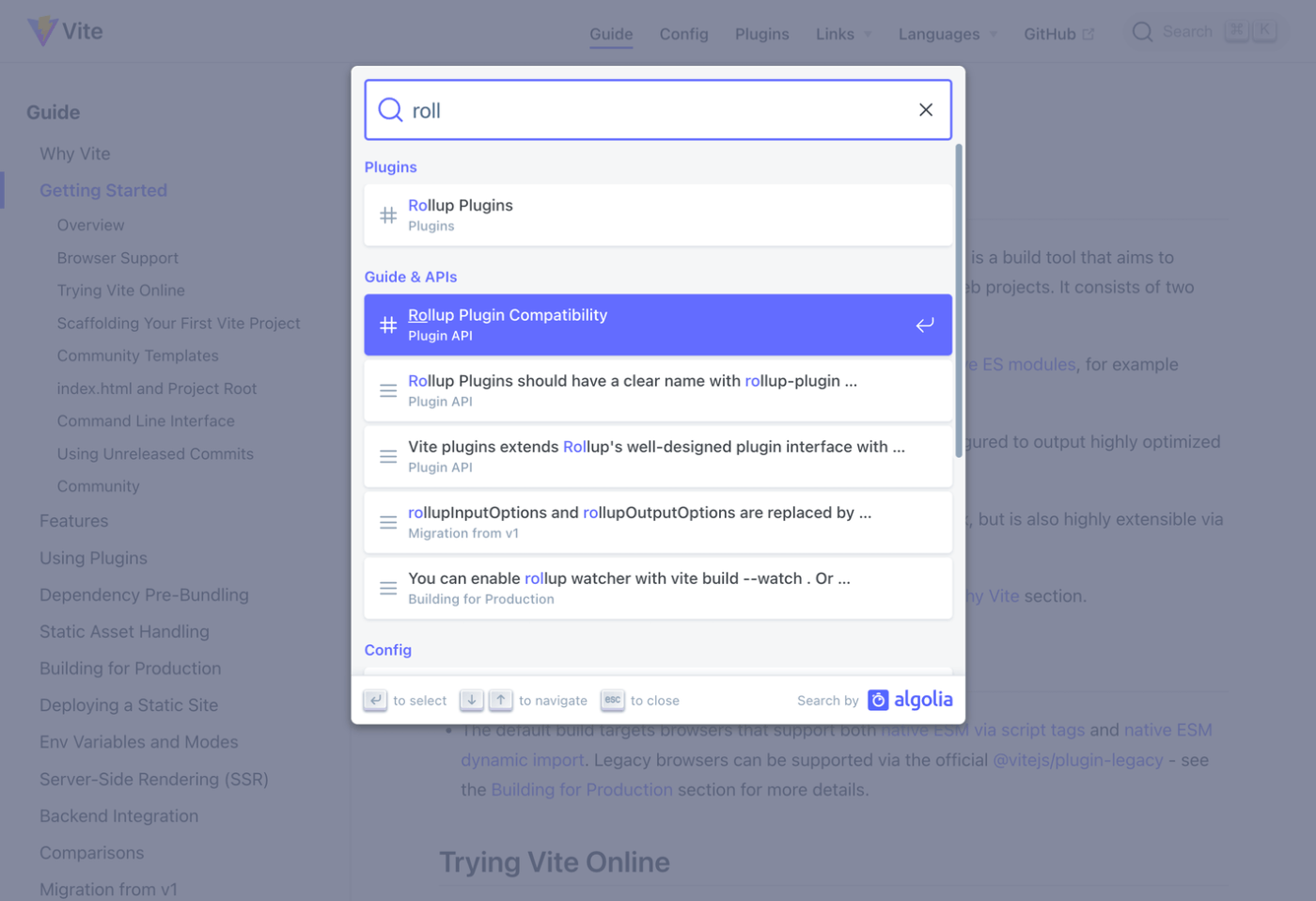
目標は「クライアントサイドのみでalgoliaみたいな検索を実現すること」でした。
- ページタイトルにヒット
- ページ本文にヒット
- ヒットした部分をハイライト
- ヒットする単語を絞り込む
- AND検索に対応
- リンクは見出しのIDまで飛ぶ
- 日本語に対応
まぁ、全ページのHTMLを解析してJSONを生成すればReactでなんとかできるでしょう。
JSONファイルの生成
実装コードはこちら。タイトル・本文の抽出をイメージしてみましょう。
<head>
<title>CSS</title>
</head>
<body>
<h1>CSS</h1>
<h2 id="css-modules">CSS Modules</h2>
<p>ministaで使えるスコープCSS。</p>
</body>
{
"pages": [
{
"path": "/docs/css",
"title": "CSS",
"content": "CSS Modules ministaで使えるスコープCSS。"
}
]
}
このままでも実装できますが、ヒットする単語をクライアントサイドで絞るのが大変ですし、見出しIDの検出もできていないですね。もう少し使いやすいJSONを用意したい。
まず、テキストを文字の種類で分割しましょう。そのためのライブラリを作りました!
よく検索するのは3文字以上の英単語・カタカナ・漢字なので hits に集めておきます。見出しIDは、分割した content の何番目に該当するか調べて toc に登録します。
{
"hits": ["CSS", "Modules", "minista", "スコープ"]
"pages": [
{
"path": "/docs/css",
"title": "CSS",
"toc": [[0, "css-modules"]],
"content": ["CSS", " ", "Modules", " ", "minista", "で", "使", "える", "スコープ", "CSS", "。"]
}
]
}
JSON内に同じ単語が何度も登場しているので、単語帳 words を作りインデックス化します。
{
"words": [" ", "minista", "CSS", "Modules", "。", "える", "で", "スコープ", "使"]
"hits": [2, 3, 1, 7]
"pages": [
{
"path": "/docs/css",
"title": [2],
"toc": [[0, "css-modules"]],
"content": [2, 0, 3, 0, 1, 6, 8, 5, 7, 2, 4]
}
]
}
Reactコンポーネント
検索のロジックを1から書くのは大変かと思いますので、ビルトインのReactコンポーネントを用意しました!実装コードはこちら。
ministaは静的サイトの一部をReact App化するPartial Hydrationがあり、その内で使えます。
※JSONが分離されているので独自に検索コンポーネントを作ることも可能
import { Search } from "minista"
export default () => {
return <Search jsonPath="/assets/search.json" />
}
このコンポーネントは負荷軽減のため入力を始めるまでJSONを読み込みません。静的サイトの場合、遷移する度にJSを再実行するのでfetchを制限しています。
入力が始まったら hits の単語に部分一致しているかチェック。
部分一致している単語を持っているページを探す流れですね。該当の単語が見出しIDの持つインデックスを超えていたらURLにIDを付与します。
使ってみた所感
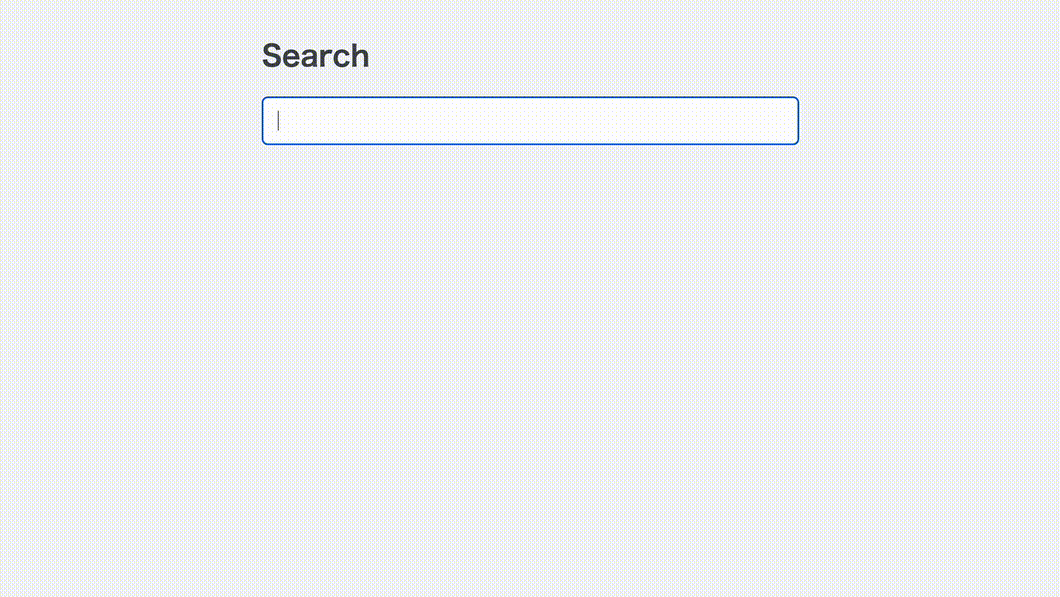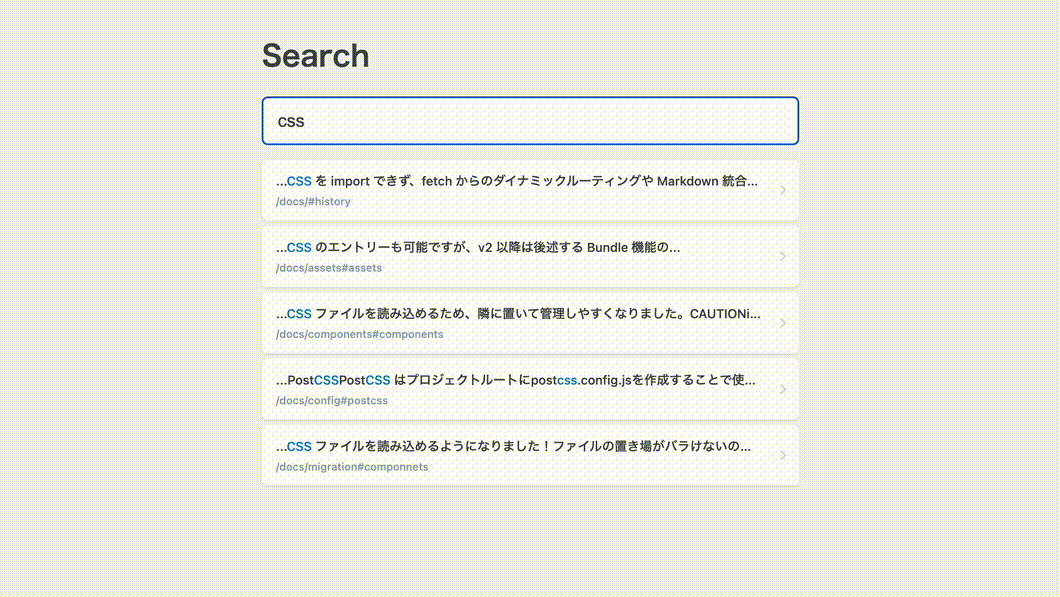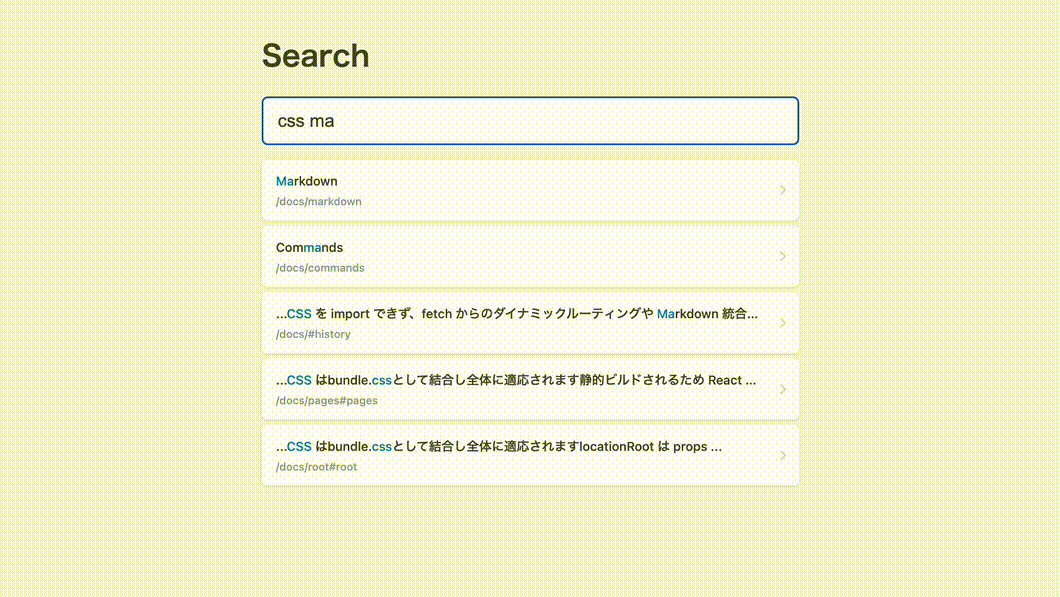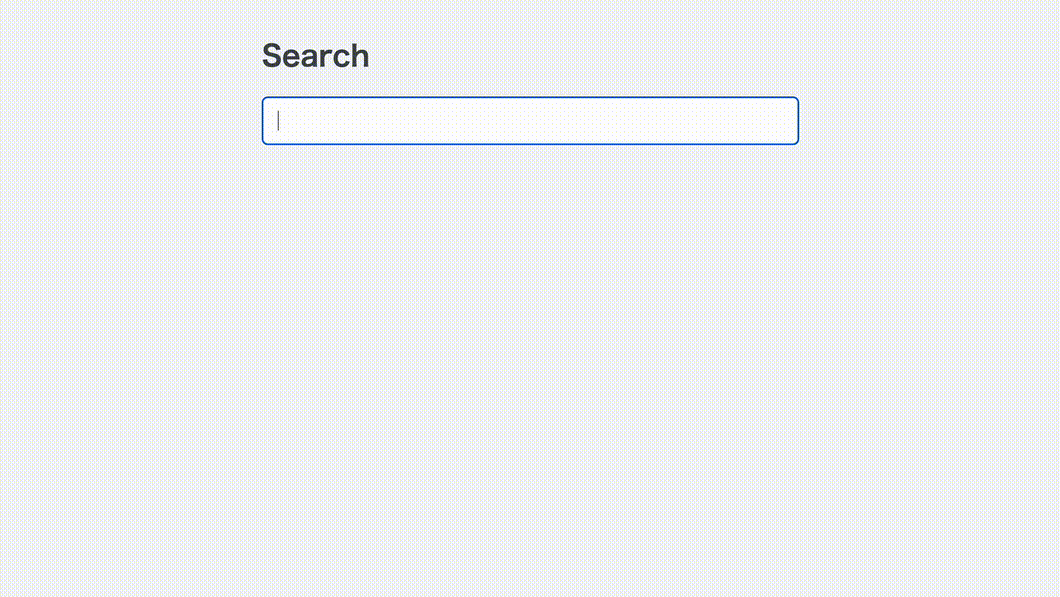
おおむね実現したい機能が作れました!検証環境の計測値は以下の通り。
- ページ数:13
- コードブロック以外の文字数:7512
- JSON容量:21KB
- JS容量(preact使用):24KB
- JS非実装時のメモリ:4.4MB
- JS実装時のメモリ:4.8MB
- JS実装+検索時のメモリ:5.0MB
なかなか軽量に作れたかもしれません。小規模サイトであればこれで済みそうです。
Discussion