CSVの列レイアウトを読み取りParquetファイルに変換する処理をRustで実装する
初めに
Apache Parquet形式のファイル(以降、Parquetファイル)については詳細を省きますが、そもそもどんなときにCSVをParquetファイルに変換すると利点があるのか、私見では下記が思い当たります。
-
ParquetファイルはバイナリなのでCSVと比べるとデータサイズが圧縮される。
-
スキーマ情報をファイル内に保持するので、ファイルに対してSQLを実行するタイプのOSS(ex. DuckDB,Dremio,Apache Arrow DataFusion)を利用したSQL実行時の設定でスキーマ定義を省略できる。
Parquetファイルへの変換処理をPythonで実装するのは割と事例がありますが、Pythonをインストールしないと利用できないので、駆動環境に影響を与えずに変換処理だけ転用したい場合にやりづらい場合があるかもしれません。
そういったことを踏まえると、Rust等のクロスコンパイル対応のネイティブコンパイル言語で実装してバイナリを持ち運びしやすくすることで転用しやすくなるという利点はあると思います。あと、単純にネイティブコンパイル言語なので処理が速くなることもあるかもしれません。
試すこと
CSVファイルをParquetファイルへ変換する処理をRustで実装した事例[link]がありましたが、今回はこの手法を参考に下記の変換仕様で実装してみました。
- CSVレイアウトに基づいたスキーマを自動生成し、スキーマの事前定義なしでPaquetファイルに変換する。
- 出力されるParquetファイルのスキーマのデータ型は全て文字列型とする。
開発環境
- Windows10
- Visual Studio Code
- WSL2
- Docker
- Rust : 1.73.0
やったこと
Rustのビルド環境の構築
WSL2にDockerをセットアップし、コンテナでRustのビルド環境を構築しました。
</> Dockerfile
FROM debian:bullseye
RUN apt-get update \
&& apt-get install -y build-essential \
&& apt-get install -y curl \
&& apt-get install -y sudo \
&& apt-get -y install libpq-dev \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# user追加
ARG USERNAME=user
ARG GROUPNAME=general
ARG UID=1000
ARG GID=1000
ARG PASSWORD=user
RUN groupadd -g $GID $GROUPNAME && \
useradd -m -s /bin/bash -u $UID -g $GID -G sudo $USERNAME && \
echo $USERNAME:$PASSWORD | chpasswd && \
echo "$USERNAME ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
USER $USERNAME
WORKDIR /home/$USERNAME/
# フォルダ作成
RUN mkdir -p $HOME/project \
&& chmod +wrx $HOME/project \
&& mkdir -p $HOME/data \
&& chmod +wrx $HOME/data
# rust
RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs > $HOME/rustup.sh \
&& chmod +x $HOME/rustup.sh \
&& $HOME/rustup.sh -y
CMD ["bash"]
プロジェクトの作成
下記のコマンドでプロジェクトを作成しました。
cargo new csv-to-parquet
Cargo.tomlファイルに依存クレートを設定しました。
</> Cargo.toml
[package]
name = "csv-to-parquet"
version = "0.1.0"
edition = "2021"
[dependencies]
arrow = "42.0.0"
parquet = "42.0.0"
anyhow = "1.0.71"
csv = "1.2.2"
実装
スキーマの生成処理
CSVのヘッダー情報を読み込み、Parquetのスキーマを生成する処理です。
fn get_schema(input_file_path: &str) -> Result<Vec<Field>>{
let input = File::open(input_file_path)?;
let mut reader = ReaderBuilder::new().has_headers(true).from_reader(input);
let mut schema_vec: Vec<Field> = vec![];
let headers = reader.headers()?.clone();
for (index, header) in headers.iter().enumerate() {
let _col = Field::new(header, DataType::Utf8, true);
schema_vec.push(_col);
}
Ok(schema_vec)
}
CSVファイルの読み込みとParquetファイルへの変換処理
CSVファイルをParquetファイルに変換する処理です。
コマンドライン引数で入力ファイルパス(input_file_path)としてCSVのパスを指定し、出力ファイルパス(output_file_path)として出力先のParquetファイルのパスを指定します。
fn main() -> Result<()> {
// コマンドライン引数を取得
let args: Vec<String> = env::args().collect();
let input_file_path = &args[1];
let output_file_path = &args[2];
let schema_vec = get_schema(&input_file_path)?;
let schema = Arc::new(Schema::new(schema_vec));
let input = File::open(&input_file_path)?;
let mut csv_input = csv_arrow::ReaderBuilder::new(schema.clone())
.has_header(true)
.with_quote(b'"')
.build(input)?;
let output = File::create(&output_file_path)?;
let mut writer = ArrowWriter::try_new(output, schema,None)?;
while let Some(batch) = csv_input.next() {
let batch = batch?;
writer.write(&batch)?;
}
writer.close()?;
Ok(())
}
コードの全体像
コードの全体像は下記となります。
</> src/main.rs
use std::fs::File;
use std::sync::Arc;
use std::env;
use anyhow::{Context,Result};
use arrow::csv as csv_arrow;
use arrow::datatypes::{DataType, Field, Schema};
use parquet::arrow::ArrowWriter;
use csv::ReaderBuilder;
fn get_schema(input_file_path: &str) -> Result<Vec<Field>>{
let input = File::open(input_file_path)?;
let mut reader = ReaderBuilder::new().has_headers(true).from_reader(input);
let mut schema_vec: Vec<Field> = vec![];
let headers = reader.headers()?.clone();
for (index, header) in headers.iter().enumerate() {
let _col = Field::new(header, DataType::Utf8, true);
schema_vec.push(_col);
}
println!("{:?}", &schema_vec);
Ok(schema_vec)
}
fn main() -> Result<()> {
// コマンドライン引数を取得
let args: Vec<String> = env::args().collect();
let input_file_path = &args[1];
let output_file_path = &args[2];
let schema_vec = get_schema(&input_file_path)?;
let schema = Arc::new(Schema::new(schema_vec));
let input = File::open(&input_file_path)?;
let mut csv_input = csv_arrow::ReaderBuilder::new(schema.clone())
.has_header(true)
.with_quote(b'"')
.build(input)?;
let output = File::create(&output_file_path)?;
let mut writer = ArrowWriter::try_new(output, schema,None)?;
while let Some(batch) = csv_input.next() {
let batch = batch?;
writer.write(&batch)?;
}
writer.close()?;
Ok(())
}
ビルド
下記のコマンドでバイナリを作成しました。Release用のビルドを実施。
cargo build --release
動作確認
test.csvをtest.parquetに変換しました。
</> test.csv
カラム1,カラム2,カラム3
データ1,データ2,データ3
データ4,データ5,データ6
データ7,データ8,データ9
データ10,データ11,データ12
下記のコマンドを実行しました。
./csv-to-parquet test.csv test.parquet
下記の通り結果を確認しました。
Parquet Viewer - Microsoft Store アプリをインストールし、test.parquetの中身を表示。
</> test.parquet
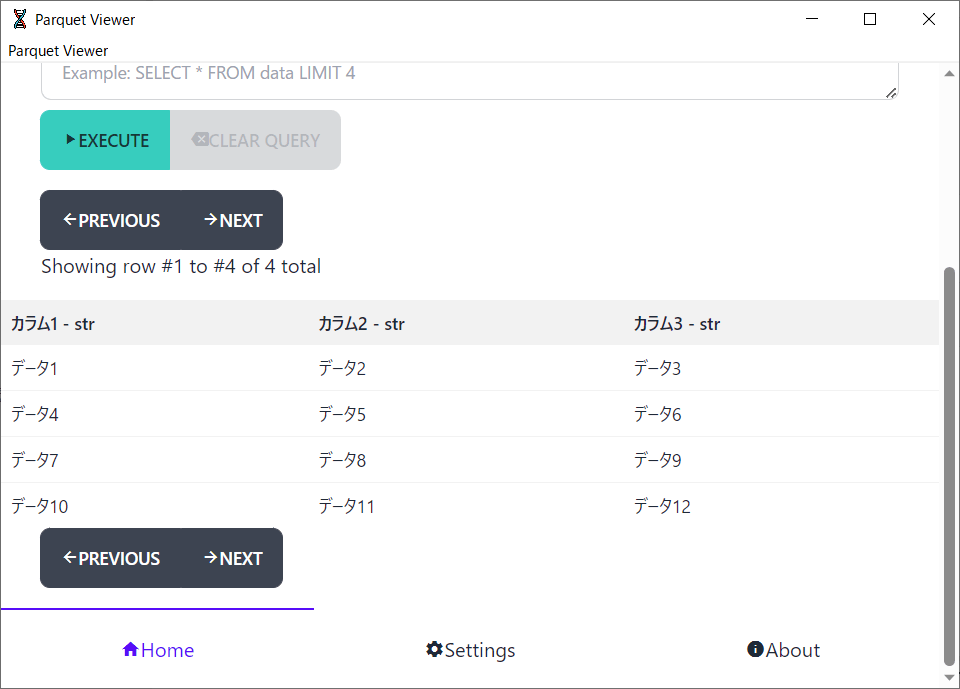
無事、変換できたことを確認できました。
終わりに
Paquetファイルに変換することでOSS(ex. DuckDB,Dremio,Apache Arrow DataFusion)を介したファイルに対するSQLの実行において事前のスキーマ定義が不要になります。
前職では、データ量がビッグデータほどは無く、SQLによるデータ加工はしたいがテーブルを作成してテーブルにデータを投入する手間を省きたいというニーズがありましたのでParquetファイルに変換しておいて、SQLによるデータ抽出、データ加工をしていました。抽出したデータに基づいてユーザー向けにアラートメールを送信する、等のシステム構築での利用でした。
Discussion