LLM・生成系AIをDeep Learningの経緯から学ぶ
以下Udemyで学習したLLM/生成系AIの内容をまとめています。
興味がある方はぜひ受講してみてください。
NN(ニューラルネットワーク)について
LLM・生成系AIに入る前に簡単にニューラル・ネットワークについて触れています。
ニューラルネットワークとは、人間の脳に似た方法で意思決定を行う機械学習プログラムまたはモデルのこと。
すべてのニューラル・ネットワークは、1つの入力層、1つ以上の隠れ層、1つの出力層を含むノードの層、つまり人工ニューロンで構成されています。ニューラル・ネットワークはトレーニング・データによって徐々に学習し、時間の経過とともに精度を高め、これらは機械学習のサブセットで、ディープラーニング・モデルの中枢を成している。
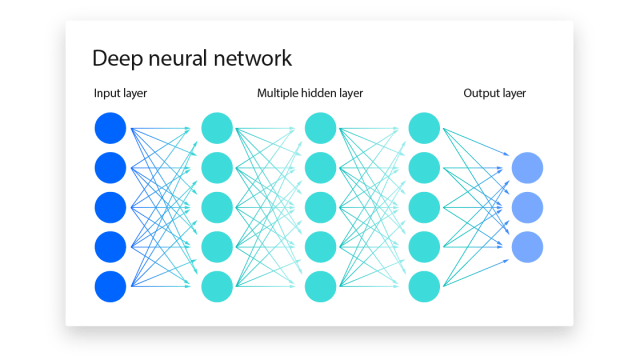
個々のノードは、入力データ、重み、バイアス(またはしきい値)、および出力で構成されている。
∑wixi + バイアス = w1x1 + w2x2 + w3x3 + バイアス
出力 = f(x) = 1 if ∑w1x1 + b>= 0; 0 if ∑w1x1 + b < 0
入力層が決定されると、重みが割り当てられる。これらの重みは、ある変数の重要度を判断するのに役立ち、重みが大きい入力ほど、出力に大きな影響を与える。
すべての入力が、それぞれの重みで乗算されたうえで合算。そこから、活性化関数を通じて、出力が決定する。
出力は損失関数にかけられ、正しい値と比較し、より学習を進めることで、成果に近づいていく。
損失関数
損失関数は、算出した出力と、実際に欲しい出力の誤差を評価する。これを最小にするよう学習を続け、正解に近づいていく。
- 二乗和誤差(MSE):誤差を二乗して、その総和をとったモノ
- 平均絶対誤差:平均二乗誤差に比べて外れ値に強い
- 交差エントロピー誤差:実際のカテゴリーに対する予測確率のみを評価す
活性化関数
- ステップ関数:閾値を超えると1、超えない場合0
- シグモイド関数:出力を0~1の範囲に抑えることができる
- ランプ関数:0より小さい場合は0、それ以上はその計算結果を出力(マイナスの値をノイズととらえたい場合は有用。画像生成などに使われる)
大規模言語モデル
Transformer
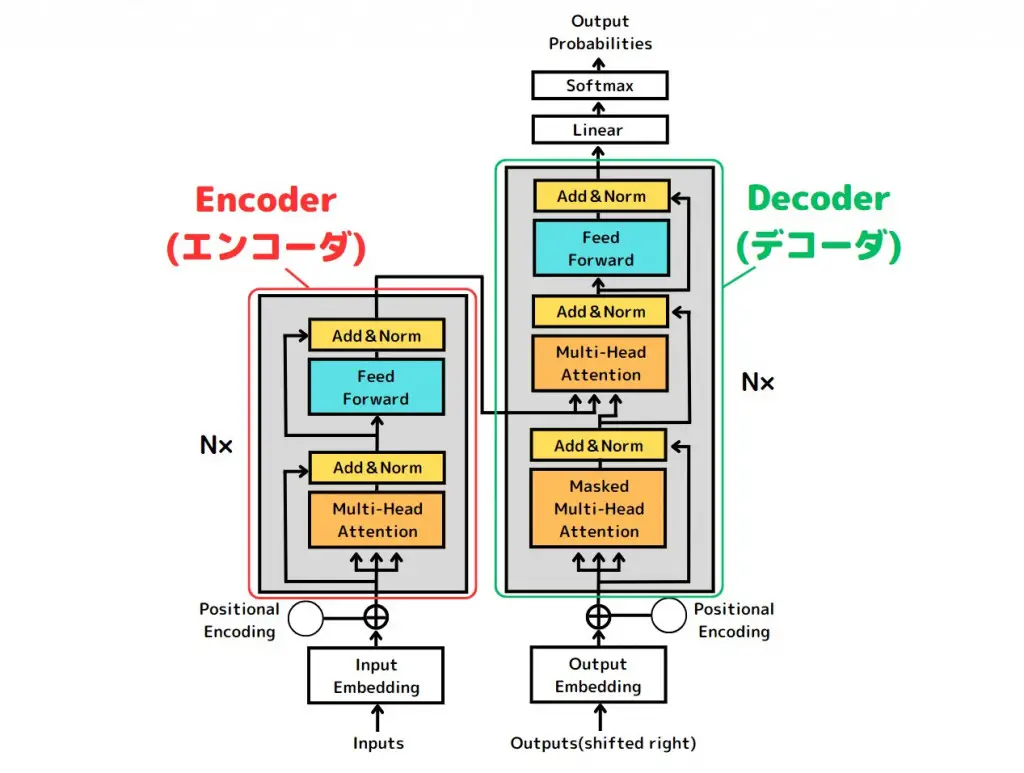
Transformerとは2007年に発表されたディープラーニングのモデル
Attention layer is All you need.
→従来のRecurrent層・畳み込み層を使わずに、Atention層だけを使うようにしたら精度がとても向上したみたい
この論文の発表が、昨今OpenAIが発表している現在のGPTシリーズやGoogleのBERTにつながっています。
Atention層
主に自然言語処理の分野で研究されてきたRNNに使われており、「文の中で重要な単語に重みづけをして渡す」層のコト。
Transformerは、従来のRNNではrecurrent(再帰)層+Atention層を組み合わせて使っていたところを、Atention層だけで学習させたモノ。
- エンコーダー・デコーダー
- エンコーダーで処理しやすいベクトル形式にしてからそれをデコーダーでアウトプットに変換する(和英翻訳では、エンコーダーで日本語をベクトル化、デコーダーで英語に出力)
- positional Encoding
- 単語の相対関係などをモデルに認識してもらうための処理(リカレント層がなくなったので、単語の位置を記憶していないため追加された)
- Attention層:単一の単語に注目
- Multi-Head Attention層:同時に複数の単語に注目して学習することが可能
- マスクしたAttention層:特定の単語をマスクして学習
エンコーダーで入力された重みづけ単語ベクトルに対して、デコーダーでは特定の単語が隠された状態でそれより前の文章の重みづけベクトルが入力され、これらの情報が隠された単語には何が入りそうか確率値を出力する。
GPT
GPT(Generative Pretrained Transformer):Transformerをベースにした事前学習生成モデル
→2017年に登場したTransformerモデル(Attention層だけを使うアプローチ)がベース
→1年後にイーロンマスク、サムアルトマンが設立したOpenAIによって「GPT-1」が登場
学習方法:エンコーダー+各タスクに合わせたファインチューニング
GPT-1

- エンコーダー:Tranformer学習モデル(エンコーダー、デコーダー)教師ナシ学習
- ファインチューニング:教師アリ学習
学習させたデータ:書籍1,000冊(4.5GBテキスト、パラメーター数:1億1700万個)
GPT-2
パラメーター数:15億個(大量のWebページから取得された40GBテキスト)
GPT-3
パラメーター数:1750億個(様々なWebページから取得された570GBテキスト)
GPT-3.5
パラメーター数:3550億個
→人間による強化学習でより精度を向上。
PaLM(Google)

- パラメータ数:5400億個
- トークン数:7800億個(英語1単語=1トークン)
- 学習に使った機器:6144台のTPU v4(Tensor Processsing Unit: Googleが開発した深層学習のためのプロセッサー)
- Pathways学習アプローチ:2つのTPUポッドを使って並行学習をしていくような構成
PaLM2 (2023/5/11に発表)

- 現時点では論文未発表
- 多言語、推論、コーディング機能が発達
Bard

- Googleが開発している対話型AIサービス
- PaLM2が搭載されている
LLaMA(Large Language Model Meta AI)

-
圧倒的に少ないパラメーター数のモデル
-
パラメータ数を抑えながら高精度を実現
-
GitHubのリボ時取からコードを確認できる
-
パラメータ数:7B、13B、33B、650億個の4モデル
-
トークン数:1.4兆億個
アーキテクチャの3特長
- RMSNormalizationによる計算量の削減:入力層に入れる前に平均二乗誤差(Root Mean Square)で正規化して空入力するアプローチ
- 活性化関数Swigle関数の適用
- 相対位置埋め込み処理:Tranformerでは絶対位置埋め込み処理を実施していたものを早退位置に変更→長文に対する精度が上がることが分かったため
拡散モデル:DDPM(Denoising Diffusion Probabilistic Models)ノイズ除去拡散確率モデル
DALL、StableDiffision に使われているモデル
ランダムノイズを与える過程を逆に遡ったときに、元の画像と近い画像が得られるようにパラメータを最適化(ノイズは主に正規分布に従ったノイズが当てられる
- CLIP:大量の画像とテキストの組み合わせを学習し、画像とテキストの類似度を算出したうえで、特定の画像に対して適切なテキストを選択してくれるようになる
- 拡散モデル:ある画像に対してランダムノイズを徐々に当てていき、関z戦にノイズになったものを逆工程でノイズを除いていき、元の画像とノイズを除いた画像の差分を小さくなるようにする試み
まとめ
最近ではAIツールを使用することが当たり前になってきた。Transformerから一気に加速したAI技術の発展の先が気になると同時に不安になる。
とりあえずTransformerについて一度論文を見てみましょう。
Discussion