Microsoft Copilot Studioを使ってAPIGatewayを呼び出してみた
はじめに
本記事では Microsoft Copilot Studio(旧 Power Virtual Agents を内包した統合環境)を用いて、社内ドキュメント(SharePoint)と自前 API(Amazon API Gateway + AWS Lambda + Amazon S3, S3 Vectors)を連携し、Teams から利用できる社内向けナレッジ QA/業務自動化ボットを構築内容をまとめます。
HTTP要求と最近GAされたS3 Vectorsの内容にも触れていますので、参考になれば幸いです。
全体アーキテクチャ(テキスト図):
Teams Client
↓ (ユーザ質問)
Copilot Studio Agent
├─ 内蔵ナレッジ検索 (SharePoint インデックス)
├─ HTTP コール → API Gateway
│ └─ Lambda (Orchestrator)
│ ├─ S3 Vectors 近傍検索 (類似文書取得)
│ ├─ 必要に応じ外部 API (社内システム等)
│ └─ LLM 呼び出し (Azure OpenAI / Amazon Bedrock など選択)
└─ 応答整形/コンプライアンスフィルタ
↓
Teams へ回答
copilot studioとは
Copilot Studio は Microsoft のエンタープライズ向け生成 AI 拡張プラットフォームで、以下を統合的に提供します。
- GUI での会話フロー(トピック/プラグイン)設計
- ナレッジベース(SharePoint / ファイル / Web / データソース)接続
- 自然言語 → 意図推定(オーケストレーションレイヤ)
- REST / Graph API / Power Platform コネクタ連携
- セキュリティ(DLP, 監査ログ, RBAC)
- Teams / Web / Mobile / Power Apps など複数チャネル公開
本記事では「標準ナレッジ回答+外部 API オーケストレーション+S3 Vectors を用いた高精度ドキュメント検索」の複合利用を実装します。
copilot studioでエージェント作成
新規エージェント作成(言語: 日本語 / 地域: 運用要件準拠)
今回エージェントは**GPT5 Auto(実験段階)**を使用します。最近追加されたばかりでまだGAされていないので、あくまで検証モデル想定です。
ナリッジに社内ドキュメントを追加(シェアポイント)
SharePoint 取り込み時のポイント:
-** 情報アーキテクチャ**: 機密度 (Public / Internal / Restricted) 別サイト or ライブラリ分離
- メタデータ列: 分類タグ, 更新日, オーナー, バージョン, 機密フラグ
- インデックス対象: PDF/Word/Excel/M365 ページ。古いバイナリ(画像化スキャン)は OCR 前処理(Azure Computer Vision / Amazon Textract)
今回ナリッジにはSharePointを使用してM365系とPDFデータを主に使用しています。後述でこの取り込みファイルの正規化は必須だと感じました。(古いファイルとか読まれるとRAGとして制度がブレる)
ApiGateway + lambda でAPI作成
目的: Copilot Studio から呼び出される単一エンドポイント (/query など) を設け、RAG + 外部システム照会 + 回答生成を統合。
エンドポイント設計(例):
POST /dev/query
Request: { "prompt": string }
Response: {
"answer": string,
"usage": { "inputTokens": number, "outputTokens": number }
}
リクエストで受け取ったプロンプトを加工してlambdaからbedrockを呼び出す。
// コンテキストの無いプロンプトテンプレート
// Knowledge BaseをLambda実行時に利用しない場合に使用(useKnowledgeBaseInPrompt: false)
const PROMPT_TEMPLATE_WITHOUT_CONTEXT = (userPrompt: string) =>
`以下の問い合わせに対して解決策を提案してください。\n問い合わせ:${userPrompt}`
// コンテキストのあるプロンプトテンプレート
// Knowledge BaseをLambda実行時に利用する場合に使用(useKnowledgeBaseInPrompt: true)
const PROMPT_TEMPLATE_WITH_CONTEXT = (context: string, userPrompt: string) =>
`①同様の問い合わせの参照結果:
\n${context}\n
------------
②問い合わせ:
\n${userPrompt}
------------
①の参照結果をもとに、回答は日本語で行い、②の問い合わせに対して解決策を以下のフォーマットで提案してください。
## <タイトル>
<解決策の内容>
### 参考:(順番は関連性の高いものを上にする)
1. [タイトル](URL)
2. [タイトル](URL)
`
export function generateFinalPrompt(userPrompt: string, context?: string): string {
if (!context || context.trim().length === 0) {
return PROMPT_TEMPLATE_WITHOUT_CONTEXT(userPrompt)
}
return PROMPT_TEMPLATE_WITH_CONTEXT(context, userPrompt)
}
呼び出した時のレスポンスとトークン数を返却する。
/**
* Private method to handle the actual Bedrock API call
*/
private async callBedrockApi(prompt: string, request: InvokeModelRequest): Promise<InvokeModelResponse> {
const payload = {
anthropic_version: "bedrock-2023-05-31",
max_tokens: request.maxTokens || this.config.defaultMaxTokens,
messages: [
{
role: "user",
content: [{ type: "text", text: prompt }],
},
],
...(request.temperature && { temperature: request.temperature }),
...(request.topP && { top_p: request.topP }),
}
const command = new InvokeModelCommand({
modelId: request.modelId || this.config.defaultModelId,
body: JSON.stringify(payload),
contentType: "application/json",
accept: "application/json",
})
const response = await this.bedrockClient.send(command)
const responseBody = JSON.parse(new TextDecoder().decode(response.body)) as BedrockResponse
LOG.trace("Bedrock response:", JSON.stringify(responseBody, null, 2))
const generatedText = responseBody.content?.[0]?.text || ""
if (!generatedText) {
throw new Error("No response generated from model")
}
return {
response: generatedText,
usage: {
inputTokens: responseBody.usage?.input_tokens || 0,
outputTokens: responseBody.usage?.output_tokens || 0,
},
}
}
ワークフロー:
- 入力バリデーション & レート制御 (API Key + WAF / throttling)
- 監査ログ (CloudWatch Logs)
- リクエストから受け取ったメッセージからプロンプト構築
- LLM 呼出 (s3 vectorsから内容を取得)
- 応答整形
- レスポンス返却
S3 Vectors
Amazon S3 Vectors 概要:
- 従来の「オブジェクトストレージ + 別途ベクトル DB」構成を単純化し、S3 バケット内でベクトル埋め込みをネイティブ管理・近傍検索を提供
- 大規模データセット(数十億ベクトルスケール)に対しコスト最適化とスループット向上
- 標準 S3 の耐久性 / 可用性モデルを継承しつつ、一貫したセキュリティ (IAM / KMS 暗号化 / Access Logs)
- 追加の複製やデータ移動不要 → ETL コスト削減 & データ主権 (Data Residency) 管理容易
copilot studioでhttp接続(HTTP要求の送信の呼び出し)
copilot studioに戻り、新しいトピックを作成します。**「HTTP要求の送信」**をクリックし、先ほど作ったAPIと紐づけていきます。
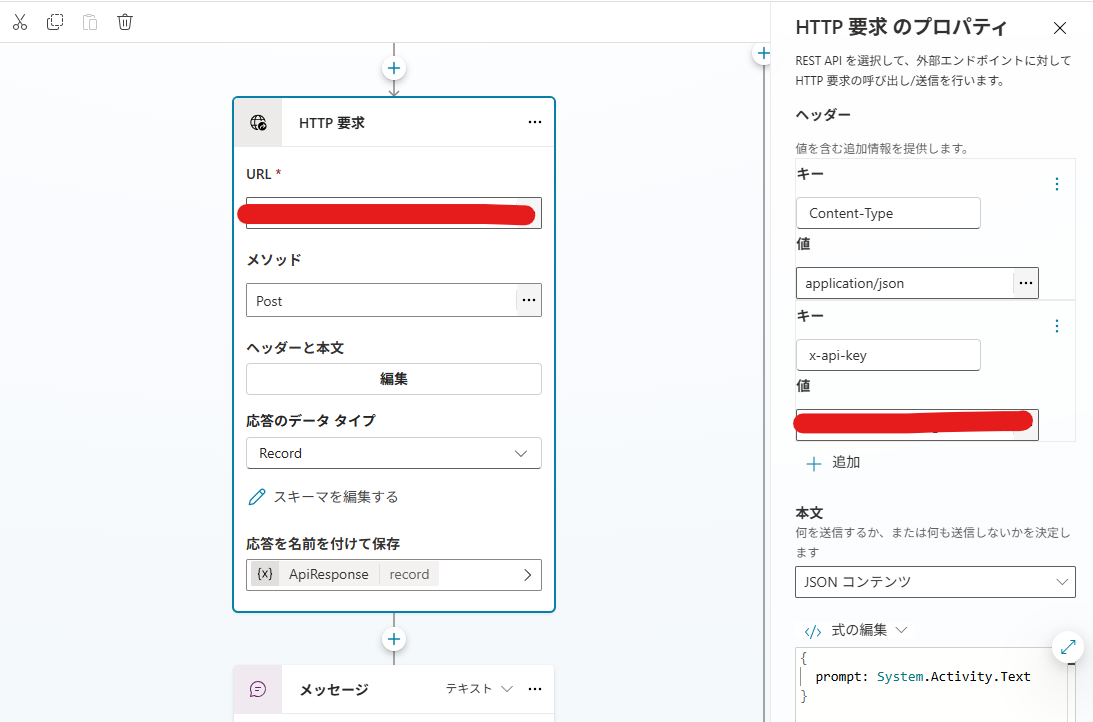
- URL:https://*****
- メソッド:POST
- ヘッダーと本文:
- Authorization:*************************** <- APIキーを設定
- Content-Type:Application/json
- 応答のデータタイプ:
- スキーマ:
kind: Record
properties:
response: String
usage:
type:
kind: Record
properties:
inputTokens: Number
outputTokens: Number
System.Activity.Textでメッセージを取得し、リクエストボディに含める。
apiとナリッジをトリガーフレーズで条件分岐
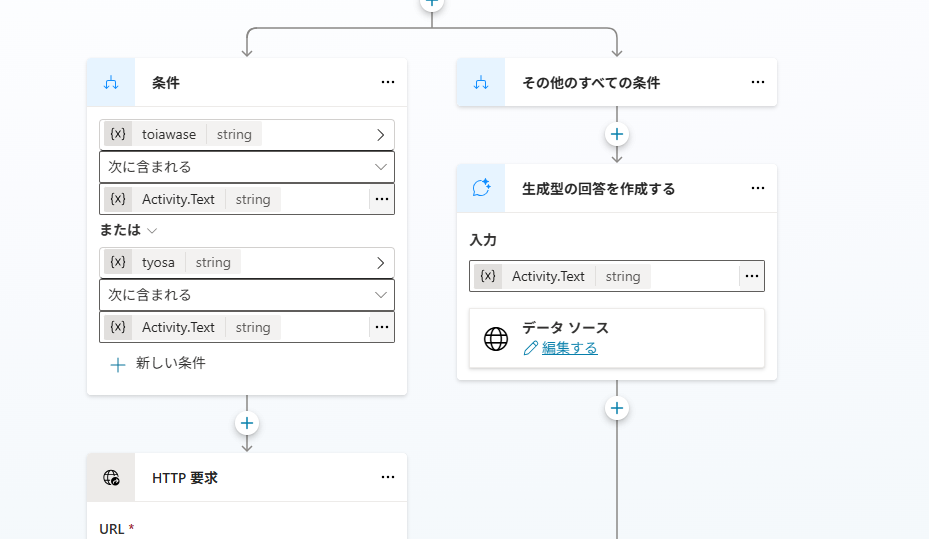
メッセージにトリガーワードが含まれる場合APIを呼び出すようにトピックを修正。
トリガーフレーズ:「調査」・「問い合わせ」
当初は先頭のトリガーフェーズで分岐しようとしたが、条件分岐がうまく設定できなかったので、変数を先に設定してから後で条件分岐を起こしている。
global変数を使うと先頭で分岐が可能ぽい(未検証)。
上記が完了したら、保存をして動かしてみましょう。
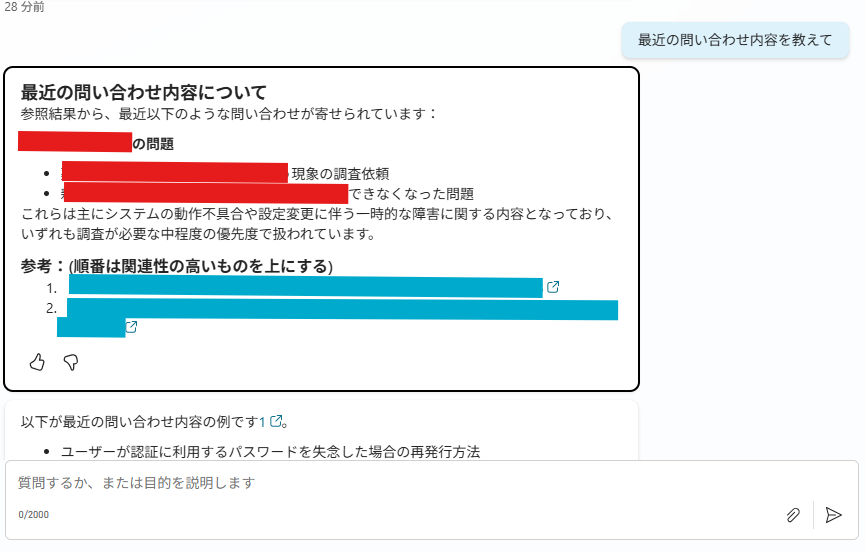
トリガーワード「問い合わせ」を入れると、正しく分岐できているのが確認できました。API側のs3vectorsの回答結果もいい感じです。
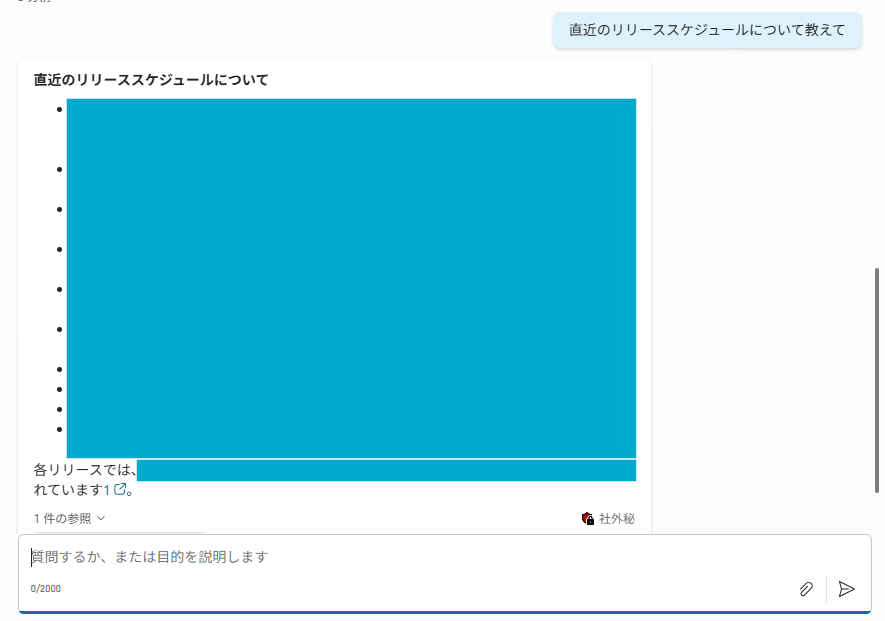
直近のリリーススケジュールについても、制度に問題があるものの、APIではなくナリッジからの呼び出しがうまく機能していることが分かりました。
※ほんとはトピックごとに内容を分ける必要があるのですが、現状エージェントがうまくトリガーを拾ってくれない(APIにリクエストしてくれない)のでこういう作りになっています…
teamsからチャットボットを呼ぶ

「Copilot Studio でチャネル → Microsoft Teams を有効化」これでteamsからでも呼び出しが可能になます。チャットボットはアプリケーションやボットとしても追加可能なので、特定のチャンネルで呼び出すことができます。
簡単ですが以上で、Copilot Studio と API (S3 Vectors) を組み合わせたQAボットの基本実装フレームを構築できます。
まとめ
copilot studioを初めて触ったのですが、想像以上に使いづらい印象があります。が、簡単にteamsボットやエージェントを作成できるのはとてもよおかったです。
トリガーをエージェントに任せると、なかなかAPI側に振り切ってくれないので、(ナリッジのインデックス問題があるかも)分岐が少々煩雑な作りになってしまいました。
copilot studioは機能が多い分、できることがほかにもありそうなのですが、まだまだ深ぼれていないのが現状です(ほかの参考文献が少ない&ドキュメント読みずらい定期)。
社内ナリッジを活用したい方は良かったら参考にしてみてください。
Discussion