Pandas(基本)
初めに
pandasとはpythonのライブラリの1つでデータ分析に用います。pandasを用いるときはまず初めに以下のコードを実行してpandasをインポートする必要があります。
import padas as pd
DataFrameとSeries
pandasにはDataFrameとSeriesという2つの重要な型があります。
DataFrame
DataFrameは表のようなもので、横一列を行、縦一列を列といいます。例として以下のDataFrmeを考えます。(pd.DataFrame)
pd.DataFrame({'A': [3, 4], 'B': [5, 6]})
・出力
| A | B | |
|---|---|---|
| 0 | 3 | 5 |
| 1 | 4 | 6 |
この例では、行の値が0、列の値がBのとき、DataFrameの値は5、行の値が1、列の値がBのとき、DataFrameの値は6となっています。次の例のようにDataFrameの値は数字だけでなく、文字もokです。
pd.DataFrame({'果物': ['みかん', 'りんご'], '野菜': ['にんじん', 'レタス']})
・出力
| 果物 | 野菜 | |
|---|---|---|
| 0 | みかん | にんじん |
| 1 | りんご | レタス |
以上の例では辞書からDataFrameを作成しています。辞書のキーが列の名前となり、辞書の値が列の値となっていることが分かります。pd.DataFrameの引数indexの値を指定することで、列の名前も変更することができます。
pd.DataFrame({'果物': ['みかん', 'りんご'],
'野菜': ['にんじん', 'レタス']},
index=['一番好き', '次に好き'])
・出力
| 果物 | 野菜 | |
|---|---|---|
| 一番好き | みかん | にんじん |
| 次に好き | りんご | レタス |
Series
DataFrameは表ですが、Seriesは配列で、リストから作成することができます。(pd.Series)
pd.Series([1, 2, 3, 4, 5])
・出力
0 1
1 2
2 3
3 4
4 5
dtype: int64
Seriesは一列のDataFrameです。そのため、DataFrameと同じように引数indexを指定することで行の名前を指定することができます。しかし、Seriesには列ごとの名前がなく、代わりに全体としての名前があります。
pd.Series([48, 39, 59], index=['2020 売上', '2021 売上', '2022 売上'], name='製品X')
・出力
2020売上 48
2021売上 39
2022売上 59
Name: 製品X, dtype: int64
データの読み込み
DataFrameやSeriesを作ることができるようになりましたが、ほとんどの場合は既に存在しているデータを扱います。
データには様々な形式がありますが、基本的なものとしてcsvファイルがあります。csvファイルはComma-Separated Valuesの略で、コンマ区切りの値からなる表のようなデータです。
今回はkaggleのtitanicコンペのデータを用います。train.csvのみ用います。
csvファイルを読み込む場合は以下のようにpd.read_csvを用います。パスにはtrain.csvのダウンロード場所を指定します。
train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/datasets/train.csv')
shapeを用いてDataFrameの大きさを確認できます。
train.shape
・出力
(891, 12)
ここから、trainは891行12列のデータであることが分かります。pd.DataFrame.headを用いることで、DataFrameの先頭5行を確認できます。
train.head()
・出力

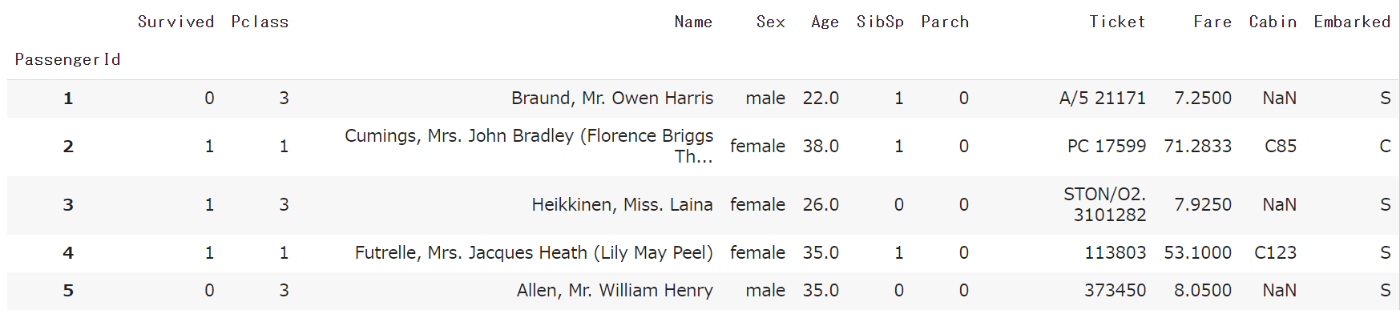
PassengerIdを行の名前として使いたい場合は以下のようにファイルを読み込みます。
train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/datasets/train.csv')
train.head()
・出力
Discussion