VSCode の言語拡張を作る
Pandoc x Markdown の執筆環境だと、Markdown の frontmatter に LaTeX のプリアンブルを書ける。ここに LaTeX のシンタックスハイライトを当てたい。
要件
- Pandoc の公式マニュアルの "Variables" の節に定義されている変数にスコープ、ハイライトを当てる
- プリアンブルのコードに LaTeX のハイライトを当てる
TextMate は GUI エディタ。エディタの構文解析に使われるルールの定義が TextMate Language Grammar(tmLanguage)。
- TextMate Language Grammar, tmLanguage
- ソースコードを トークン化(トークナイズ) するためのルール定義。
- トークナイズのルールは正規表現で記述される。
- 行単位で処理される。1 つの正規表現では複数行は扱えない。TextMate のトークナイザーは 1 行ずつ解析する。
- ただし、begin / end / while のような仕組みを使うことで、複数行にまたがる構文(文字列やコメントなど)も表現できる。
- 内部で使われている正規表現エンジンの Oniguruma は複数行マッチをサポートしているが、TextMate の仕様上「1 つの正規表現で改行を跨いでマッチする」ことができない。
- TextMate のトークナイザーは基本的に「1行単位」で正規表現を適用するが、begin / end / while による状態スタックを利用することで複数行にまたがる構文も扱える。
- 正規表現エンジン自体(Oniguruma)は複数行マッチ可能だが、TextMate の仕様上「1つの正規表現で改行をまたいでマッチする」ことはできない。
「トークナイザー」も正しくはないのかな。
「正規表現にマッチしたパターンにスコープを割り当てる」だから、もちろんトークナイザーとしても使えるし、トークンよりも広い範囲を操作することもできる。
とりあえず独自のスコープの定義を当てることができた。

syntax の定義は syntaxes/xxx.tmLanguage.json に書ける。
以前作った Python の中の Markdown にハイライトを当てるやつ。今回の要件もこれに似てる。
とりあえず pandoc マニュアルに書いてあるキーワードにハイライト当てられるようになった。
あとは yaml のマルチラインスタイルの部分に LaTeX ハイライトを当てられれば勝ち。

VSCode 側のグローバルな設定でハイライトを当てる。

settings.json
{
...
"editor.tokenColorCustomizations": {
"textMateRules": [
{
"scope": "keyword.nukopy.nukopy",
"settings": { "foreground": "#0066ff", "fontStyle": "bold" }
},
{
"scope": [
"punctuation.definition.comment.begin.pandoc-latex-injection",
"punctuation.definition.comment.end.pandoc-latex-injection"
],
"settings": { "foreground": "#00f2ff", "fontStyle": "bold" }
},
{
"scope": [
"keyword.pandoc.variables.metadata-variables",
"keyword.pandoc.variables.language-variables",
"keyword.pandoc.variables.variables-for-html",
"keyword.pandoc.variables.variables-for-html-math",
"keyword.pandoc.variables.variables-for-html-slides",
"keyword.pandoc.variables.variables-for-beamer-slides",
"keyword.pandoc.variables.variables-for-powerpoint",
"keyword.pandoc.variables.variables-for-latex",
"keyword.pandoc.variables.variables-for-context",
"keyword.pandoc.variables.variables-for-wkhtmltopdf",
"keyword.pandoc.variables.variables-for-man-pages",
"keyword.pandoc.variables.variables-for-textinfo",
"keyword.pandoc.variables.variables-for-typst",
"keyword.pandoc.variables.variables-for-ms",
"keyword.pandoc.variables.variables-set-automatically"
],
"settings": { "foreground": "#00f2ff", "fontStyle": "bold" }
}
]
},
...
}


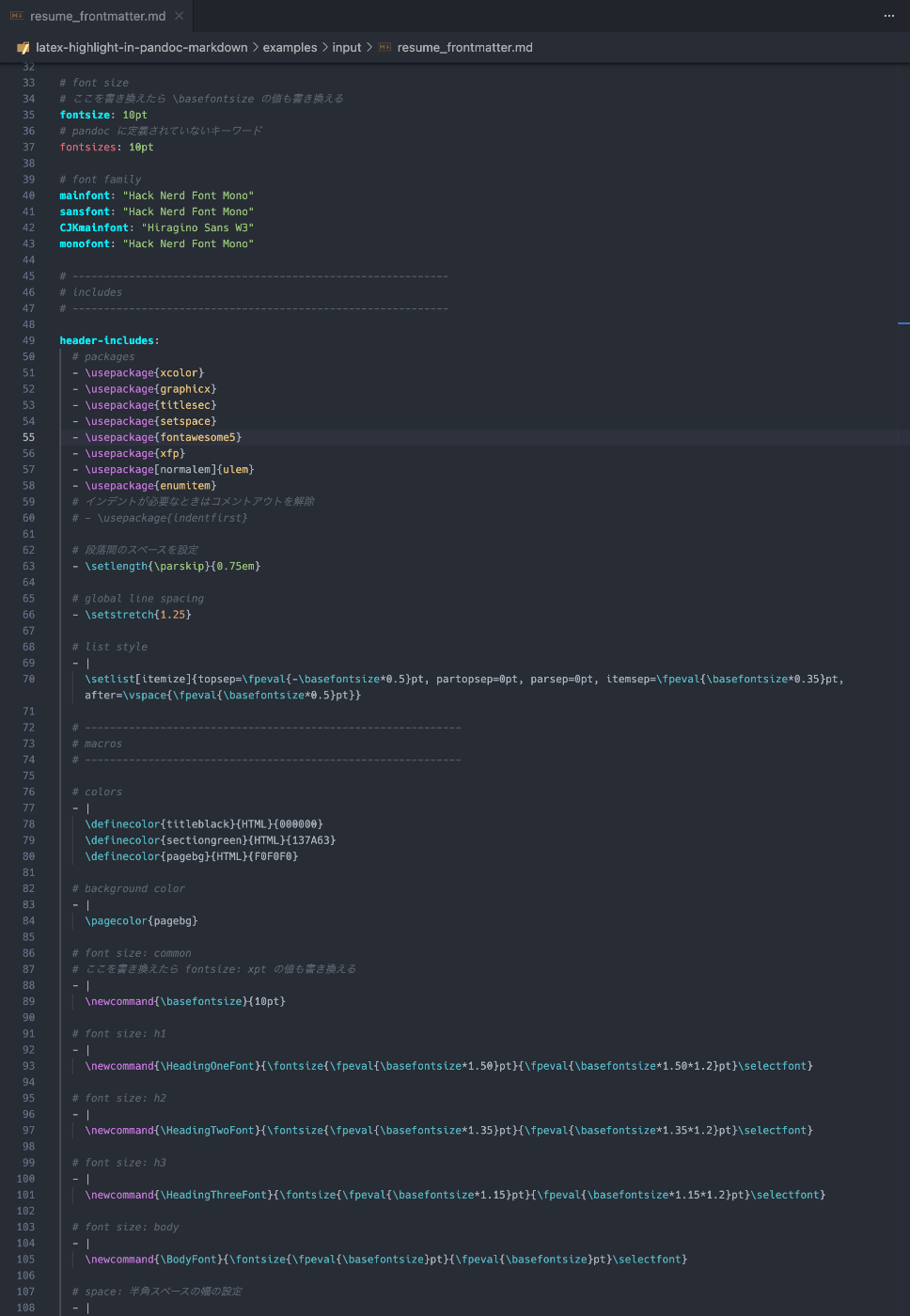
参考にしたやつ
VSCode 拡張のリリースフロー
とりあえず昔作ったやつを引っ張り出す。アカウントがある。
GitHub のアカウントで Azure にログイン。
Azure Organization とやらは作ってあった。

Create New Project

まずはローカル環境でインストールできるようにする。
ローカルで .vsix 形式のファイルからインストールできた。

手順は README に書いた。以下の手順で OK。
Development
Requirements
- Node.js v22.16.x
- Visual Studio Code v1.99.x or later
- (optional) Cursor 1.7.x or later
Setup
git clone git@github.com:nukopy/latex-in-markdown-for-pandoc.git
cd latex-in-markdown-for-pandoc
pnpm i
Build
pnpm run build
If successful, the extension package dist/latex-in-markdown-for-pandoc-<version>.vsix is created.
Install locally
Execute command Extensions: Install from VSIX... in VS Code (or Cursor) and select the file dist/latex-in-markdown-for-pandoc-<version>.vsix.
アクセストークンの発行
作成
Azure DevOps のユーザ設定 > Security > Personal access token

Scopes

権限
$ vsce login -- nukopy
WARNING Failed to open credential store. Falling back to storing secrets clear-text in: /Users/nukopy/.vsce
https://marketplace.visualstudio.com/manage/publishers/
Personal Access Token for publisher 'nukopy': ****
The Personal Access Token verification succeeded for the publisher 'nukopy'.
とりあえずリリースまで漕ぎ着けた。まだ README 準備できてないけど。
vsce publish --pre-release みたいなコマンドあったけどプレリリースのステータスみたいなのなくて何も表示が変わらなかった。

Web 埋め込みも悪くないね。アイコンの余白調整は必要だけど。
↓スクショ
リリース前に重大なバグが見つかった。
テストしてて良かった。
早速直していく。再現はできてエラーログも取得できた。
TextMate の文法(xxx.tmLanguage.json)をテストするためのツールを issue で教えてもらった。v0.1.0 だとシンプルなことしかやってない。まず既存のやつのテストを書かねば。
既存のリポジトリのテスト方法を見てみる:
vscode-tmgrammar-test は使ってないけど、テストケースを TeX にして、各トークンにどのスコープが当たっているかのテストを書いてる。
テスト実行してみる
テストケース(1 行目がテストケースを表す)
# SYNTAX TEST "pandoc-latex-injection-body" "error test"
---
header-includes:
- \usepackage{amsmath}
---
# Reproduce
## Example: Scope is resolved successfully
\newpage
## Example: Scope is not resolved
In this document, we derive the expectation, variance, and standard deviation from the definition of the normal distribution.
First, let’s review the theorem for the expectation, variance, and standard deviation of a normal distribution.
\begin{thm*}
When a random variable $X$ follows a normal distribution $N(\mu, \sigma^2)$ (i.e., $X \sim N(\mu, \sigma^2)$), the expectation, variance, and standard deviation of $X$ are given as follows:
$$
E[X] = \mu, \qquad V(X) = \sigma^2, \qquad \sqrt{V(X)} = \sigma.
$$
\end{thm*}
コマンド
pnpm exec vscode-tmgrammar-test ./docs/notes/fix-issue-3/docs/test.md
grammar not found for "text.tex.latex"
✓ ./docs/notes/fix-issue-3/docs/test.md run successfuly.
ローカルの TextMate スコープ text.tex.latex を探す
これだね
rg -n --hidden --glob 'package.json' '"scopeName"\s*:\s*"text\.tex\.latex"' \
"/Applications/Cursor.app/Contents/Resources/app/extensions" ~/.cursor/extensions
zsh: command not found: #
/Applications/Cursor.app/Contents/Resources/app/extensions/latex/package.json
1:{"name":"latex","displayName":"%displayName%","description":"%description%","version":"1.0.0","publisher":"vscode","license":"MIT","engines":{"vscode":"*"},"scripts":{"update-grammar":"node ./build/update-grammars.js"},"categories":["Programming Languages"],"contributes":{"languages":[{"id":"tex","aliases":["TeX","tex"],"extensions":[".sty",".cls",".bbx",".cbx"],"configuration":"latex-language-configuration.json"},{"id":"latex","aliases":["LaTeX","latex"],"extensions":[".tex",".ltx",".ctx"],"configuration":"latex-language-configuration.json"},{"id":"bibtex","aliases":["BibTeX","bibtex"],"extensions":[".bib"]},{"id":"cpp_embedded_latex","configuration":"latex-cpp-embedded-language-configuration.json","aliases":[]},{"id":"markdown_latex_combined","configuration":"markdown-latex-combined-language-configuration.json","aliases":[]}],"grammars":[{"language":"tex","scopeName":"text.tex","path":"./syntaxes/TeX.tmLanguage.json"},{"language":"latex","scopeName":"text.tex.latex","path":"./syntaxes/LaTeX.tmLanguage.json","embeddedLanguages":{"source.cpp":"cpp_embedded_latex","source.css":"css","text.html":"html","source.java":"java","source.js":"javascript","source.julia":"julia","source.lua":"lua","source.python":"python","source.ruby":"ruby","source.ts":"typescript","text.xml":"xml","source.yaml":"yaml","meta.embedded.markdown_latex_combined":"markdown_latex_combined"}},{"language":"bibtex","scopeName":"text.bibtex","path":"./syntaxes/Bibtex.tmLanguage.json"},{"language":"markdown_latex_combined","scopeName":"text.tex.markdown_latex_combined","path":"./syntaxes/markdown-latex-combined.tmLanguage.json"},{"language":"cpp_embedded_latex","scopeName":"source.cpp.embedded.latex","path":"./syntaxes/cpp-grammar-bailout.tmLanguage.json"}]},"repository":{"type":"git","url":"https://github.com/microsoft/vscode.git"}}
/Users/nukopy/.cursor/extensions/james-yu.latex-workshop-10.10.2-universal/package.json
217: "scopeName": "text.tex.latex",
241: "scopeName": "text.tex.latex",
246: "scopeName": "text.tex.latex",
251: "scopeName": "text.tex.latex",
275: "scopeName": "text.tex.latex",
304: "scopeName": "text.tex.latex",
319: "scopeName": "text.tex.latex",
/Users/nukopy/.cursor/extensions/torn4dom4n.latex-support-3.10.0/package.json
70: "scopeName": "text.tex.latex",
nukopy latex-highlight-in-pandoc-markdown on issues/3-fix-maximum-call-stack-error-when-highlighting-latex-in-markdown-body [MU⇡] is 📦 v0.1.0 via v22.16.0 via 🐏 52% (67GiB/128GiB) on AWS Region: (ap-northeast-1) at 🗓 2025/10/08 00:10:20
➜ ls /Applications/Cursor.app/Contents/Resources/app/extensions/latex/syntaxes
Bibtex.tmLanguage.json LaTeX.tmLanguage.json TeX.tmLanguage.json
cpp-grammar-bailout.tmLanguage.json markdown-latex-combined.tmLanguage.json
nukopy latex-highlight-in-pandoc-markdown on issues/3-fix-maximum-call-stack-error-when-highlighting-latex-in-markdown-body [MU⇡] is 📦 v0.1.0 via v22.16.0 via 🐏 52% (67GiB/128GiB) on AWS Region: (ap-northeast-1) at 🗓 2025/10/08 00:11:42
➜ ls /Applications/Cursor.app/Contents/Resources/app/extensions/latex/syntaxes/LaTeX.tmLanguage.json
/Applications/Cursor.app/Contents/Resources/app/extensions/latex/syntaxes/LaTeX.tmLanguage.json
VSCode 拡張機能のテスト
Q. TextMate の文法のテストを書こうと思うんだけど、 vscode-tmgrammar-test と vscode/test-electron どちらを使うのが良さそう? それぞれの立ち位置が分かっていない。
| 目的 | 向いてるツール | 何ができる? | 使いどころ |
|---|---|---|---|
| TextMate 文法そのもののトークナイズ/スコープをサクッと検証 | vscode-tmgrammar-test | VS Code の TextMate エンジンで、プレーンテキストのフィクスチャを使って期待スコープを検証(Sublime の syntax test 風) | ルール追加・正規表現修正の回帰テスト、スコープ崩れの再現と検証に最適。(npm) |
| VS Code 拡張全体の統合/E2E(起動~有効化、UI 振る舞い、API 連携) | @vscode/test-electron(=VS Code Test CLI が内部で利用) | 実際の VS Code(Electron) を起動して 拡張の統合テストを Mocha で実行。CLI からデバッグもしやすい | 文法以外:アクティベーション、コマンド、設定、他拡張との相性チェックに。(npm) |
結論(短刀直入)
-
文法の正しさ・スコープ崩れの検証がメイン →
vscode-tmgrammar-test一択。
フィクスチャ書いて CI で回すのが一番速い。 -
拡張としての挙動まで含めた総合テスト →
@vscode/test-electron(or VS Code Test CLI)。
起動~有効化~設定変更~コマンド実行みたいなシナリオを検証。
実務フローのおすすめ(併用)
-
ユニット層(速い):
vscode-tmgrammar-testで grammar の回帰テストをがっちり。 -
統合層(網羅): 重要シナリオだけ
@vscode/test-electronでスモーク。VS Code 本体が使う TextMate ベースである点は公式ガイドにも明記。(code.visualstudio.com)
参考になる実例
- VS Code の Markdown TM grammar リポジトリは、フィクスチャ+自動生成の結果で色分けテストを回してる。自分のリポでも同パターンを真似できる。(GitHub)
TextMate 周辺の概念、用語の整理
全体像が良くわからなくなってきたので「TextMate とはなんぞや」から周辺の概念、用語を整理する。
まとめ
- TextMate:macOS テキストエディタ
- TextMate Grammar:TextMate で使われていた構文仕様。正規表現によるトークン化ルールを外部ファイルとして宣言的に記述し、テキストをスコープ付きトークン列に変換する仕様。
TextMate とは
- TextMate は macOS 用のテキストエディタ(開発元: MacroMates)。
- 2000年代に登場し、「構文解析ロジックをソフトウェア本体に埋め込むのではなく、外部定義ファイル(データ)として読み込む設計」を作ったことで有名。
- その構文定義フォーマット(TextMate Grammar)は、VSCode、Sublime Text、Atom など多くのエディタが採用している。
TextMate Grammar とは
TextMate Grammar は、「テキストエディタ TextMate がプログラムのソースコードをトークン化(tokenize, tokenization)するためのルールセット」のこと。ソースコードのトークン化のためのルールセットは外部ファイル(tmLanguage / JSON / plist)で宣言的に定義できる仕組みとなっている。
ルールセットは正規表現ベースのパターンマッチングルールの集合であり、正規表現のパターンマッチングを行う処理は Oniguruma という正規表現エンジンで行っている。
正規表現ベースのルールでソースコード(=テキスト)をトークン化し、スコープ名(例: keyword.operator や string.quoted.double) を割り当てる、というのが TextMate Grammar の動作の基本。つまり、ルールセットとは「正規表現とスコープ名のペアの集合」といえる。
スコープは「ソースコードのどの部分がキーワードか、どの部分がコメントか」など「パターンマッチした各トークンがソースコードにおいてどういう役割か」を表す概念で、スコープ名はその役割ににつける名前のこと。
TextMate Grammar 詳細
TextMate Grammar は、
- 入力:生のテキスト(例:
if (x > 0) print("ok")) - 出力:トークン列(例:
keyword.control.if,variable, punctuation, …)
を生成する、正規表現ベースのパターンマッチングルールの集合。
- ルールは正規表現(Oniguruma 構文)で記述される
- Oniguruma 構文:正規表現エンジン Oniguruma が採用している正規表現の構文ルール
- 構文木(AST)を構築するわけではない。 ← ポイント後述
- パターンマッチしたトークンには スコープ名(
scope name) が付与される。- 例:
{ "match": "\\bif\\b", "name": "keyword.control.flow.python" }
- 例:
- この「スコープ名」は後でテーマ(配色定義)が参照し、色やスタイルを決める。
- 我々が VSCode などで使えるシンタックスハイライトは「TextMate Grammar のスコープ名と色のペアの集合」である。
補足:LSP と TextMate Grammar の役割の違い
TextMate Grammar によるトークン化は Language Server Protocol(LSP)の動作とは独立している。
TextMate Grammar は LSP のように抽象構文木(AST)を構築するわけではない。つまり、セマンティクスの解析は提供しない。TextMate Grammar はあくまでシンタックスハイライトのためのトークン化であり、いわゆる定義へのジャンプや検索、補完などの LSP が提供してくれる機能とは完全に独立している。役割が明確に別れている。
LSP と TextMate Grammar の役割の整理
役割を整理すると以下のようになる(ChatGPT 5 thinking に書いてもらった):
| 項目 | TextMate Grammar | LSP |
|---|---|---|
| 目的 | 見た目の構文ハイライト | コードの意味理解・操作 |
| ベース | 正規表現 | AST / 型解析など |
| 動作層 | クライアント内(VS Code 内部) | クライアント ⇄ サーバ通信 |
| 入力 | 生テキスト | パース済み構文木、型情報 |
| 代表例 |
*.tmLanguage.json, Oniguruma
|
tsserver, pyright, rust-analyzer
|
| 連携 | 無くても動く | 無くても動く |
| 相互依存 | なし(完全独立) | なし(ただし共存は可能) |
VSCode での動作イメージ
- TextMate:トークンを色分け(keyword, string, …)
- LSP:コードの意味を理解し、操作可能にする
この2つは完全に独立して動作し、同時に存在できる。
LSP が無くても色はつくし、TextMate が無くても補完は出る(色はつかないけど)。
┌──────────────────────────────────────────┐
│ VS Code Editor │
│ │
│ ┌────────────────┬──────────────────┐ │
│ │ TextMate │ LSP Client │ │
│ │ (Syntax) │ (Semantic) │ │
│ └────────────────┴──────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ Oniguruma Regex JSON-RPC │
│ │ │ │
│ ▼ ▼ │
│ Text Tokens Language Server │
│ (解析・補完) │
└──────────────────────────────────────────┘
セマンティクスとハイライトで構文解析をわざわざ 2 回走らせる意味はある?tree-sitter の導入
時間かかりそうなのでまた今度。
tmLanguage(または tmLanguage.json / tmLanguage.plist)
- TextMate Grammar の実体ファイル形式
- 拡張子
.tmLanguageが元祖で、XML の Property List (plist) 形式。
→ 例:<dict><key>patterns</key><array>…</array></dict> - VSCode や Atom(さよなら)ではこれを JSON に変換した
.tmLanguage.jsonを扱うことが多い。
tmLanguage.json の構造
{
"scopeName": "source.python",
"patterns": [
{ "include": "#my-strings-patterns" },
{ "match": "\\b(def|class)\\b", "name": "keyword.declaration.python" }
],
"repository": {
"my-strings-patterns": {
"patterns": [
{ "begin": "\"", "end": "\"", "name": "string.quoted.double.python" }
]
}
}
}
-
scopeName:文法のトップレベル名。 -
patterns:実際のマッチルール。 -
repository:再利用可能なルール群。マッチルールをモジュール化できる。 -
include:他ルール(repository)や他言語を取り込む- 例:(今回のケースのような)Markdown 内で LaTeX をハイライトする、など
.plist と .json の違い
-
.plist:エディタ TextMate で使われていた TextMate Grammar の定義ファイルの形式。XML 形式。 -
.tmLanguage.json: VSCode 向けに TextMate Grammar のパターンマッチルールの定義を JSON 化したもの。内容は等価。- VSCode は JSON 形式を推奨している。
.plist形式も利用可能。
- VSCode は JSON 形式を推奨している。
Oniguruma(鬼車)
- 正規表現エンジン(C 言語製)。
- Ruby、Atom、VSCode など多くのエディタや言語が採用している。
- TextMate Grammar はこの Oniguruma の構文、機能に依存している。
- 例:
(?<=...)(後読み)や(?>...)(原子的グループ)など、POSIX より強力な拡張構文が使える。
- 例:
VS Code との関係
- VS Code の TextMate Grammar によるソースコードの解析処理に Oniguruma の WebAssembly 版(
onig.wasm) を使用している。 - これにより、ブラウザ環境でも正規表現を同じように動作させることができる。

VSCode での構成要素の関係
ここまでの整理:
| コンポーネント | 役割 |
|---|---|
| TextMate Grammar (.tmLanguage) | 文法ルールそのもの。どのテキスト範囲にどのスコープを割り当てるかを定義。 |
| Oniguruma | TextMate Grammar 内の構文(正規表現、Oniguruma 独自構文)をベースにトークン化を実行するエンジン。 |
| VS Code TextMate Tokenizer | TextMate 文法を読み込み、テキストをトークン化してスコープ情報を生成。Oniguruma を呼び出す。 |
| VS Code Theme | スコープ名に対応する色やフォントスタイルを定義。 |
まとめ:立ち位置の整理
| 名称 | 種別 | 主な役割 | VS Code における位置づけ |
|---|---|---|---|
| TextMate | エディタ / 仕様の起源 | 構文ハイライトの設計思想を提供 | 構文エンジンの元祖 |
| tmLanguage (.plist / .json) | データファイル | 正規表現ルールとスコープ定義を格納 | 拡張で提供する文法ファイル |
| Oniguruma | 正規表現エンジン | TextMate Grammar のマッチングを実行 | wasm 版が内部で利用されている |
| VS Code TextMate Tokenizer | 実装(Node.js / wasm) | Grammar を読み込んでスコープ付け | 実際の解析処理担当 |
| Theme | 設定ファイル | スコープ名ごとに色を割り当て | トークンに色を付ける層 |
整理すると、VSCode において、
- 文法を「定義」するのが
.tmLanguage - それを「動かす」のが Oniguruma、
- そして「表示に反映する」のが Theme(シンタックスハイライト)
という三層構造によりシンタックスハイライトが動いている。