オンプレ Ubuntu 24.04 マシンに AWS Systems Manager の設定をする
ハイブリッドおよびマルチクラウド環境での Systems Manager の利用
ドキュメント
IAM について
IAM はこれをみるとよく分かる
AWS CLI v2 の設定
インストール
- Linux x86 (64-bit)
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
aws --version
# aws-cli/2.17.20 Python/3.11.9 Linux/6.8.0-38-generic exe/x86_64.ubuntu.24
設定
aws configure
# AWS Access Key ID [None]: xxxx
# AWS Secret Access Key [None]: xxxx
# Default region name [None]: ap-north-east-1
# Default output format [None]:
マネージドノード
Systems Manager で使用するように設定されたマシンはすべて、マネージドノードと呼ばれます。
マネージドノードについて
Systems Manager 用の非 EC2 マシンの設定を完了したら、ハイブリッドアクティベーションマシンは AWS Management Console にリストされてマネージドノードとして表示される。コンソールでは、ハイブリッドアクティベーションマネージドノードの ID は、「mi-」のプレフィックスにより Amazon EC2 インスタンスと区別される。Amazon EC2 インスタンス ID は、プレフィックス「i-」を使用する。
マネージドノードとは、Systems Manager 用に設定されたあらゆるマシンのこと。以前は、マネージドノードはすべてマネージドインスタンスと呼ばれていた。現在、インスタンスとは EC2 インスタンスのみを指す。
マネージドノードは AWS Systems Manager 用に設定されたすべてのマシンを指します。AWS Systems Manager は、Amazon Elastic Compute Cloud (Amazon EC2) インスタンス、エッジデバイス、オンプレミスサーバー、または VM (他のクラウド環境にある VM を含む) をサポートしています。以前は、マネージドノードはすべてマネージドインスタンスと呼ばれていました。現在、インスタンスとは EC2 インスタンスのみを指します。deregister-managed-instance コマンドは、この用語変更の前に命名されました。
インスタンスの階層について
Systems Manager はハイブリッドおよびマルチクラウド環境内の非 EC2 マネージドノード用にスタンダードインスタンス層とアドバンストインスタンス層を提供する。
スタンダードインスタンス層により、AWS アカウント ごと、AWS リージョン ごとに最大 1,000 のハイブリッドアクティベーションマシンを登録できる。1 つのアカウントとリージョンに 1,000 を超える非 EC2 マシンを登録する必要がある場合は、アドバンストインスタンス層を使用する。
アドバンストインスタンスは、AWS Systems Manager Session Manager を使用して非 EC2 マシンに接続することも可能にする。Session Manager はマネージドノードにインタラクティブシェルアクセスを実現する。
ハイブリッドおよびマルチクラウド環境で Systems Manager に必要な IAM サービスロールを作成する
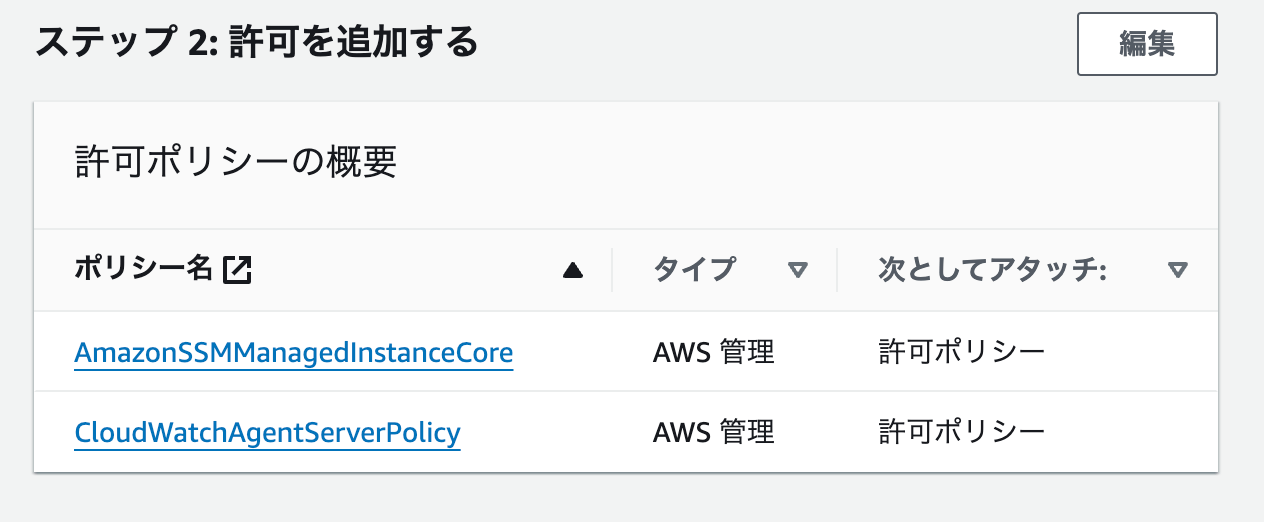
許可ポリシー
許可ポリシーは以下 2 つ
AmazonSSMManagedInstanceCore-
CloudWatchAgentServerPolicy- EventBridge または CloudWatch Logs を使用して、マネージドノードを管理またはモニタリングする場合はこのポリシーも追加
ハイブリッドアクティベーションを作成して、Systems Manager にノードを登録する
アクティベーションの作成
aws ssm create-activation \
--default-instance-name name \
--iam-role iam-service-role-name \
--registration-limit number-of-managed-instances \
--region region \
--expiration-date "timestamp" \\
--tags "Key=key-name-1,Value=key-value-1" "Key=key-name-2,Value=key-value-2"
ハイブリッド Linux ノードで SSM Agent をインストールする方法
Ubuntu Server
統合された CloudWatch Logs へのノードログの送信 (CloudWatch エージェント)
CloudWatch エージェントを入れる
ノードのメトリクスとログを収集するには、AWS Systems Manager エージェント (SSM Agent) を使用する代わりに、Amazon CloudWatch を設定して使用できます。SSM Agent よりも CloudWatch エージェント を使用したほうが、EC2 インスタンスのメトリクスを多く収集できます。また、CloudWatch エージェント を使用すると、オンプレミスのサーバーからもメトリクスを収集できます。
エージェントの構成設定を Systems Manager Parameter Store に保存し、CloudWatch エージェントで使用することもできます。Parameter Store は AWS Systems Manager の一機能です。
Run Command めちゃめちゃ楽
Parameter Store に CloudWatch エージェントの設定ファイルを入れる。デフォルトの設定ファイルを取得するため、サーバに入り、設定ファイルを作成するウィザードを実行する。
CloudWatch エージェント設定ウィザードを実行する
設定ウィザードのログ
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard
[sudo] password for nukopy:
================================================================
= Welcome to the Amazon CloudWatch Agent Configuration Manager =
= =
= CloudWatch Agent allows you to collect metrics and logs from =
= your host and send them to CloudWatch. Additional CloudWatch =
= charges may apply. =
================================================================
On which OS are you planning to use the agent?
1. linux
2. windows
3. darwin
default choice: [1]:
1
Trying to fetch the default region based on ec2 metadata...
I! imds retry client will retry 1 timesD! should retry true for imds error : RequestError: send request failed
caused by: Put "http://169.254.169.254/latest/api/token": context deadline exceeded (Client.Timeout exceeded while awaiting headers)D! should retry true for imds error : RequestError: send request failed
caused by: Put "http://169.254.169.254/latest/api/token": context deadline exceeded (Client.Timeout exceeded while awaiting headers)2024/08/02 03:37:45 D! could not get region from imds v2 thus enable fallback
W! could not get region from ec2 metadata... EC2MetadataRequestError: failed to get EC2 instance identity document
caused by: RequestError: send request failed
caused by: Get "http://169.254.169.254/latest/dynamic/instance-identity/document": context deadline exceeded (Client.Timeout exceeded while awaiting headers)Are you using EC2 or On-Premises hosts?
1. EC2
2. On-Premises
default choice: [2]:
2
Please make sure the credentials and region set correctly on your hosts.
Refer to http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html
Which user are you planning to run the agent?
1. cwagent
2. root
3. others
default choice: [1]:
1
Do you want to turn on StatsD daemon?
1. yes
2. no
default choice: [1]:
1
Which port do you want StatsD daemon to listen to?
default choice: [8125]
What is the collect interval for StatsD daemon?
1. 10s
2. 30s
3. 60s
default choice: [1]:
3
What is the aggregation interval for metrics collected by StatsD daemon?
1. Do not aggregate
2. 10s
3. 30s
4. 60s
default choice: [4]:
4
Do you want to monitor metrics from CollectD? WARNING: CollectD must be installed or the Agent will fail to start
1. yes
2. no
default choice: [1]:
1
Do you want to monitor any host metrics? e.g. CPU, memory, etc.
1. yes
2. no
default choice: [1]:
1
Do you want to monitor cpu metrics per core?
1. yes
2. no
default choice: [1]:
1
Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file.
1. 1s
2. 10s
3. 30s
4. 60s
default choice: [4]:
4
Which default metrics config do you want?
1. Basic
2. Standard
3. Advanced
4. None
default choice: [1]:
1
Current config as follows:
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "cwagent"
},
"metrics": {
"metrics_collected": {
"collectd": {
"metrics_aggregation_interval": 60
},
"cpu": {
"measurement": [
"cpu_usage_idle"
],
"metrics_collection_interval": 60,
"resources": [
"*"
],
"totalcpu": true
},
"disk": {
"measurement": [
"used_percent"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"diskio": {
"measurement": [
"write_bytes",
"read_bytes",
"writes",
"reads"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"net": {
"measurement": [
"bytes_sent",
"bytes_recv",
"packets_sent",
"packets_recv"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"statsd": {
"metrics_aggregation_interval": 60,
"metrics_collection_interval": 60,
"service_address": ":8125"
},
"swap": {
"measurement": [
"swap_used_percent"
],
"metrics_collection_interval": 60
}
}
}
}
Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items.
1. yes
2. no
default choice: [1]:
1
Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration?
1. yes
2. no
default choice: [2]:
2
ウィザードで作成した config.json。これをベースにする。logs フィールドを作成して設定ファイルを作る。
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "cwagent",
"region": "ap-northeast-1"
},
"metrics": {
"metrics_collected": {
"collectd": {
"metrics_aggregation_interval": 60
},
"cpu": {
"measurement": [
"cpu_usage_idle"
],
"metrics_collection_interval": 60,
"resources": [
"*"
],
"totalcpu": true
},
"disk": {
"measurement": [
"used_percent"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"diskio": {
"measurement": [
"write_bytes",
"read_bytes",
"writes",
"reads"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"net": {
"measurement": [
"bytes_sent",
"bytes_recv",
"packets_sent",
"packets_recv"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"statsd": {
"metrics_aggregation_interval": 60,
"metrics_collection_interval": 60,
"service_address": ":8125"
},
"swap": {
"measurement": [
"swap_used_percent"
],
"metrics_collection_interval": 60
}
}
}
}
collectd と statsd
- collectd:
- システムレベルのメトリクス収集に特化したデーモン
- 主にハードウェアやOSのメトリクス(CPU、メモリ、ディスクI/O、ネットワークなど)を収集
- プラグイン方式で拡張可能
- 設定ファイルベースで動作
- データの保存や転送に様々な形式をサポート
- statsd:
- アプリケーションレベルのメトリクス収集に適したシンプルなプロトコルとデーモン
- カウンター、ゲージ、タイマーなどのカスタムメトリクスを扱う
- UDPベースの軽量プロトコル
- アプリケーションコードからの直接的な統合が容易
- 集約機能を持つ
主な違い
- 焦点:
- collectd: システムレベルのメトリクス
- statsd: アプリケーションレベルのメトリクス
- 設定と使用:
- collectd: より詳細な設定が可能、システム管理者向け
- statsd: シンプルなプロトコル、開発者が使いやすい
- データ収集方法:
- collectd: 主にポーリングベース
- statsd: プッシュベース(アプリケーションが能動的にメトリクスを送信)
- 拡張性:
- collectd: プラグインシステムで拡張
- statsd: シンプルなプロトコルを基に、様々な言語でクライアントライブラリが提供されている
実際の使用では、これらのツールは相互排他的ではありません。多くの場合、以下のように組み合わせて使用される:
- collectd でシステムレベルのメトリクスを収集
- statsd でアプリケーションレベルのカスタムメトリクスを収集
- 両者のデータを統合して、包括的な監視システムを構築
CloudWatch Agentの文脈では、システムメトリクスの収集に collectd ライクな機能を使用し、アプリケーションメトリクスの収集に statsd プロトコルを使用することで、両方のアプローチの利点を活かしている。
StatsD
CloudWatch エージェントには StatsD サーバが内包されている。設定で有効化できる。8125 ポートに StatsD プロトコルのリクエストを投げれば CloudWatch Metrics にアプリケーションのメトリクスを飛ばせる。
...
"metrics": {
"metrics_collected": {
"collectd": {
"metrics_aggregation_interval": 60
},
"cpu": {
"measurement": [
"cpu_usage_idle"
],
"metrics_collection_interval": 60,
"resources": [
"*"
],
"totalcpu": true
},
"disk": {
"measurement": [
"used_percent"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"diskio": {
"measurement": [
"write_bytes",
"read_bytes",
"writes",
"reads"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"net": {
"measurement": [
"bytes_sent",
"bytes_recv",
"packets_sent",
"packets_recv"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"statsd": {
"metrics_aggregation_interval": 60,
"metrics_collection_interval": 60,
"service_address": ":8125"
},
"swap": {
"measurement": [
"swap_used_percent"
],
"metrics_collection_interval": 60
}
}
}
...
開発が活発じゃない(master ブランチの最終コミットが last year)ってのは Prometheus とかのメトリクスの便利な exporter がデファクトになっていてそっちのが便利だから今はあまり使われないとかなのかな。過去の基盤だったツールの互換性のために残してあるみたいな。