テスト駆動開発 Test Driven Development, TDD
TDD やるならこれだけ見とけなソース
まず読んでね
まずこれを聞くと全体像と温度感が分かって良い
TDD Boot Camp 2020 twada さんの基調講演
TDD のサイクル:「動作するきれいなコード」を書く
動作するきれいなコードはあらゆる意味で価値がある
- どのテストから始めるか?
- テストリストから重要度(大事そうなやつ)、テスト容易性(テスト書きやすそうなやつ)の 2 軸で選択する
- 「リファクタリング」の定義
- Martin Fowler の定義:ソフトウェアの外部から見た振る舞いを変えないまま、理解や保守が簡単になるようにソフトウェアの内部をきれいにしていくこと
- Kent Beck の定義:成功しているテストが成功しているまま、コード(プロダクトコード、テストコード両方を含む)をきれいにしていくこと(TDD にて、意図的に Fowler のリファクタリングの定義を狭めた)
- → リファクタリングの終了の定義が明確になり、サイクルを回せる
- TDD のゴールは「動作するきれいなコード」
- 「動作するコード」:テストが通る(汚い)コード
- 「きれないコード」:動作するままでリファクタリングされたコード

「重要度が高いものはテスト容易性が低い」というのは思い込み。
テストリストを書きながら、仕様を整理して、「重要度が高く、テスト容易性も高い」、「重要度が低く、テスト容易性も低い」という 2 つの極みにテストリストの要素を寄せていく
テスト容易性の 3 つの要素
- 観測が簡単であること
- 制御が簡単であること
- 対象が十分小さいこと
観測が簡単でない例、簡単な例
- 観測が簡単でない例
- 3 の倍数のときは数の代わりに「Fizz」をプリントする
- → 「プリントする」の観測が簡単でない(言語によって異なる。標準入出力のキャプチャの仕組みのあるなしに左右される。かつ、標準入出力のテスト自体はドメインロジックに比べれば重要でない。)
- 観測が簡単な例
- 3 の倍数のときは数の代わりに「Fizz」に変換する
- → 「変換」であれば出力の観測が容易にできるので、ドメインロジックのテストが書きやすくなる
テスト関数の中身
4 phase test って名前が付いているらしい。検証(assert)から書くと良い。
手が動かなくなったらテストリストに戻って具体を考えてみる。抽象と具体を行き来する。
テスト駆動開発で早めに検証を書くと、「手が動かない」という状態が早めに来る。この状態に出会うのはプロジェクトの早期であればあるほどよい。

自分が普段使っているスニペットはこれ:
#[test]
fn test_() {
// テスト項目:
// given (前提条件):
// when (操作):
// then (期待する結果):
}
「作る前に使う」ことでインタフェースの設計をしながら実装を行う
使いやすいコードと作りやすいコードは違う。
優先度としては「使いやすい、読みやすい > 作りやすい」。
テストファーストでは、まず使う目線に立って実行、when を書いて使う目線になれる。
作る前に使う
TDD 一周目はテスト容易性の高いものを選択する。
一、二周目は設計があるので重くなりがち。なので書きやすいものを選択して仮実装でスタートダッシュを切る。
設計重視でひどい実装で OK。
mutation test
テストコードのテストをしたい
defect insert
仮実装によりテストコードのテストを行う。
テストコードのアンチパターン:Assertion Roulette
テストフレームワークは基本的に fail first で、一つのテスト関数内に assert 関数をたくさん並べると、「そのテストが何をテストしたいのか分かりづらい」、「デバッグが大変」という状況になってしまう。

そのため原則テスト関数には assert が 1 つと考えておくと良い(1 assertion per test)
(もちろん場合による。例えば、integration test、E2E test は時間がかかるので 1 assertion per test は明らかに適していない。)

テスト容易性のキーファクター
入出力から遠い
(大常識)テスト間の依存関係は百害あって一利なし。
テストが増えてきたときに並列分散実行を行う必要がある。このときテスト間の依存関係があると並列分散実行できずテストの高速化ができない。
TDD のスキル

テストコードは「動作するドキュメント」
テストの構造化とリファクタリングでテストコードが「動作するドキュメント」になった!

テストの構造化とリファクタリングは本人がやりきらないと負債になる。
テストコードを資産にするためにもテストコードを書いた本人が構造化とリファクタリングを行わなければならない。
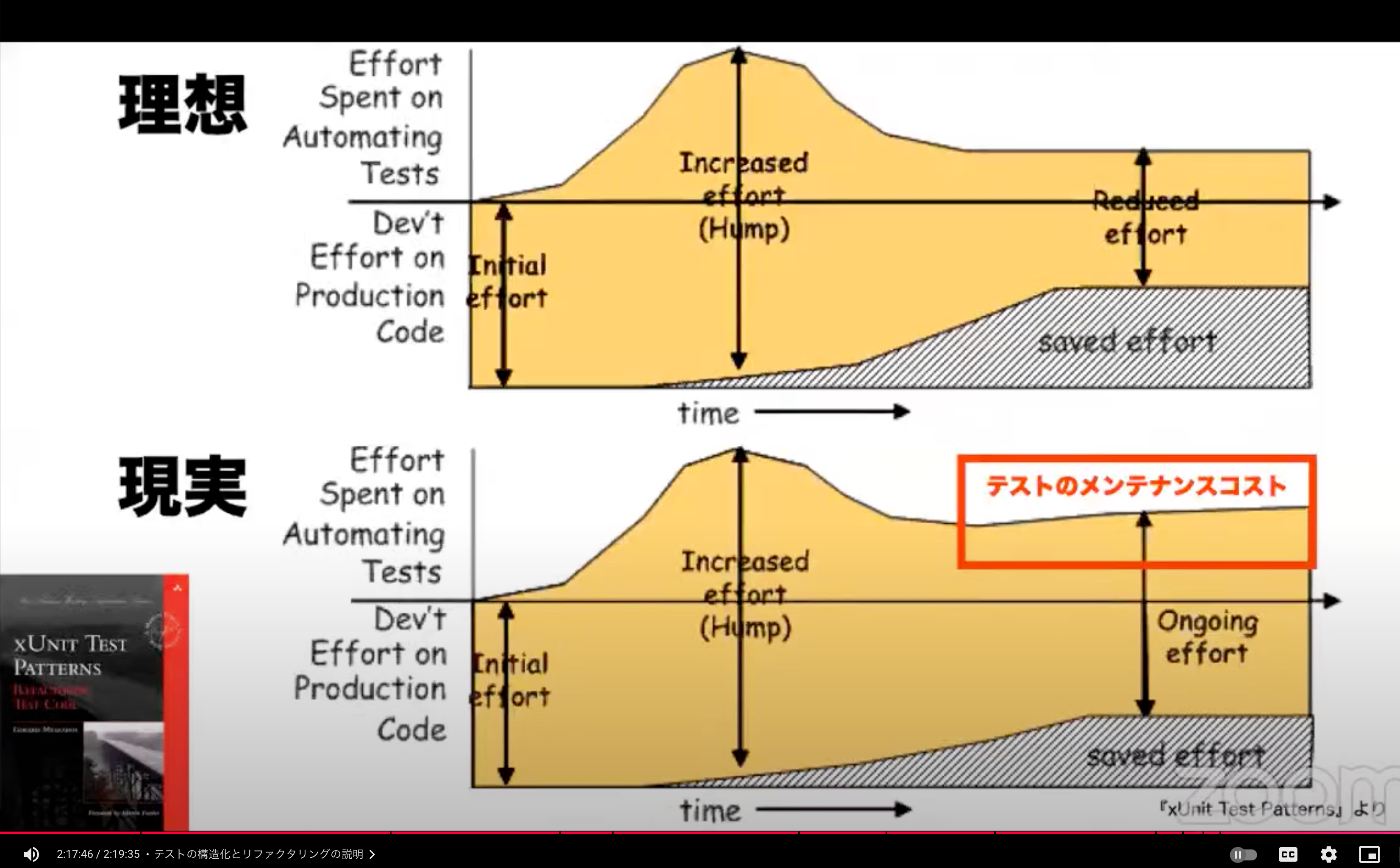
TDD のスキル
テストコードを資産にするためにもテストコードを書いた本人が構造化とリファクタリングを行わなければならない。これによりテストコードが「動作するドキュメント」になり、チームの資産となる。

- 仮実装(ひどいけどテストが通るコード)によって「テストコードのテスト」を行う
- 仮実装に対して別の数を与えることによって実装をまともな方向に戻していくテクニックを「三角測量」という
- テストコードは他人は消せない。三角測量によって余計に 1 つ書いたテストコードは残すべきではない。
- テストコードのメンテナンスコストに目を向ける。読みにくい、動くけど仕様が伝わらないテストは意味がない。ドキュメントとして価値のあるテストをコードとして残す。
Test Doubles Cheat Sheet (with Rust examples)
Test Double は「本物の依存の代わりに使うテスト用の代替物」の総称。
依存を差し替えることでテストを 速く・安定して・狙ったシナリオで 行えるようにする。
📌 使い分けまとめ(再掲)
- 戻り値を固定したい → Stub
- 呼び出しの仕方を検証したい → Mock
- 処理も動かしつつ記録したい → Spy
- 軽量で現実的な代替実装が欲しい → Fake
- ただの穴埋め → Dummy
1) Dummy(ダミー)
- 定義: 型を埋めるためだけに存在する代替物。呼ばれる想定はない。
- 意図: コンパイルや関数シグネチャを満たすためだけに置く。
- 用途: テストで依存を全く使わないのに、引数やフィールドで必須なとき。
pub struct DummyRepo;
impl UserRepo for DummyRepo {
fn find_by_id(&self, _id: &str) -> Option<User> { unreachable!() }
fn save(&self, _user: User) { unreachable!() }
}
2) Stub(スタブ)
- 定義: 呼ばれたら「決められた結果」を返すだけの代替物。
- 意図: 依存の出力を固定して、上流のロジックをテストしやすくする。
- 用途: 「成功ならこう振る舞う」「失敗ならこう返る」といった分岐を確実に試したいとき。
pub struct StubRepo { pub result: Option<User> }
impl UserRepo for StubRepo {
fn find_by_id(&self, _id: &str) -> Option<User> { self.result.clone() }
fn save(&self, _user: User) {}
}
3) Mock(モック)
- 定義: 呼び出し方(回数や引数)が正しいかを検証する代替物。
- 意図: 「こう呼ばれるべきだ」という契約をテストする。
- 用途: データ保存、通知送信、外部 API 呼び出しなど「呼び出しの有無や内容」が重要なとき。
use std::cell::RefCell;
pub struct MockRepo {
pub saved: RefCell<Vec<User>>,
}
impl UserRepo for MockRepo {
fn find_by_id(&self, _id: &str) -> Option<User> { None }
fn save(&self, user: User) { self.saved.borrow_mut().push(user); }
}
4) Spy(スパイ)
- 定義: 本物の処理を実行しながら、呼び出し状況を記録する代替物。
- 意図: 実際の挙動を保ちながら「何回呼ばれたか」を観測する。
- 用途: 「呼ばれたかどうか」だけでなく「処理も動かしたい」場面。キャッシュ、ラッパー、メトリクス収集など。
use std::cell::Cell;
pub struct SpyRepo<R: UserRepo> {
inner: R,
pub save_calls: Cell<usize>,
}
impl<R: UserRepo> UserRepo for SpyRepo<R> {
fn find_by_id(&self, id: &str) -> Option<User> { self.inner.find_by_id(id) }
fn save(&self, user: User) {
self.save_calls.set(self.save_calls.get() + 1);
self.inner.save(user)
}
}
5) Fake(フェイク)
- 定義: 本物に近いけど簡易化された実装。ちゃんと動くが軽量。
- 意図: 複雑な依存(DBや外部API)の代わりに、テスト用の「動く代替品」を用意する。
- 用途: インメモリDBや簡易キャッシュなど。I/O を避けつつ現実的な動作を確認したいとき。
use std::collections::HashMap;
use std::cell::RefCell;
pub struct InMemoryRepo {
store: RefCell<HashMap<String, User>>,
}
impl UserRepo for InMemoryRepo {
fn find_by_id(&self, id: &str) -> Option<User> {
self.store.borrow().get(id).cloned()
}
fn save(&self, user: User) {
self.store.borrow_mut().insert(user.id.clone(), user);
}
}
6) Test Double(総称)
- 定義: Dummy / Stub / Mock / Spy / Fake をひっくるめた総称。
- 意図: 本物の依存を差し替えることで、テストを速くし、制御しやすくし、失敗箇所を明確にする。
-
用途:
- DB に繋がずにテストしたい
- ネットワークや外部 API を呼びたくない
- 振る舞い(呼び出し方や順序)を確認したい
- 再現が難しいケース(エラーやタイムアウト)を意図的に起こしたい
📌 使い分けまとめ(再掲)
- 戻り値を固定したい → Stub
- 呼び出しの仕方を検証したい → Mock
- 処理も動かしつつ記録したい → Spy
- 軽量で現実的な代替実装が欲しい → Fake
- ただの穴埋め → Dummy