CDN の仕組み
まず基本を復習
(2023.04)CDN 入門とエッジでのアプリケーション実行
CDN の役割は?
主に以下の 2 つ:
- 静的コンテンツ(HTML/CSS/JS/画像など)が入ったオリジンサーバへのアクセス集中を防ぐための負荷分散
- 地理的な制約によるコンテンツの配信遅延の軽減
本来はオリジンサーバーにアクセスするはずだったリクエストを、エッジロケーションが代理して担当することで、負荷分散と地理的な高速配信を実現できます。
エッジロケーションと AWS が持っているようなデータセンターは違う?
データセンターの一種だけど、データセンターよりも多いらしい(データセンターよりは規模が小さい?)。
エッジロケーションはデータセンターの一種ですが、世界中に配置され、クラウドの通常リージョンのデータセンターよりも多く設置されています。
CDN で配信されるデータ(コンテンツ)では整合性が一時的に取れなくなることがある
エッジロケーションはオリジンサーバーのコンテンツをキャッシュしているだけなので、当然データの整合性は一時的に取れなります。そのため、通常の CDN サービスでは、キャッシュを保持する期間(TTL, time to live)を設定できるようになっています。 整合性を高く保ちたい場合はキャッシュの保持期間を短くすればよいわけです。 もちろん短くしすぎると、CDN の負荷分散の利点は弱くなるので、要件に応じてバランスを判断する必要があります。
CDN を設定してある Web アプリケーションにユーザがリクエストしたとき、地理的に近いエッジロケーションはどうやって選択される?
AWS 公式が出してる CloudFront のエッジロケーションの仕組みの解説記事。Future の記事もわかりやすいけどこれもわかりやすかった記憶。
この 1 枚で良いね。

ユーザのリクエストをエッジロケーションの IP アドレスに向ける
- ユーザがブラウザからリクエスト(
example.com) - DNS にて、
example.com→ CDN 用ドメインcdn.example.comに名前解決- あらかじめ DNS に CNAME レコードの設定を行っておく(CNAME レコード:ドメインと別名ドメインを紐づける DNS レコード)
- CDN 用ドメインはベンダーによって異なる。Amazon CloudFront だと、CDN 用ドメインは
d3vam04na8c92l.cloudfront.netのようなドメインがディストリビューションごとに発行される。これを DNS の CNAME レコードに設定する。
- (ここが CDN の肝)CDN ベンダー DNS にて、CDN 用ドメインに対応する IP アドレスの動的な名前解決を行い、クライアント端末からの通信に最適な(多くの場合は地理的に最も近い)エッジロケーションの IP アドレスを返す
- CDN ベンダーの権威 DNS サーバは CDN 用ドメインに対応する IP アドレスを動的に変換して応答する
- 一般的には、送信元の IP アドレスや AS (Autonomous System)を読み取り利用することで最寄りのエッジロケーションを導出する
-
CDN を実現する肝となる仕組みがここです。 CDN 用ドメインは CDN ベンダーが管理しているため、権威 DNS サーバーの挙動は CDN ベンダーで決めることができます。
-
CDN を構成しない場合、権威 DNS サーバーは通常固定の IP アドレスを応答します。 しかしながら、CDN を構成する場合、固定の IP アドレスでは、地理的に近いエッジロケーションにアクセスさせるという要件を達成できません。
ここまでの流れをわかりやすく図解してくれてるのが先程の図(再掲):

インターネットとは?
インターネットの説明あるの good!
これに加えてピアリング戦記を読むともっと楽しい。エッジロケーションの選択のところで出てきた Automonous System, AS や ISP などインターネットがどのように構築されているか、またその構築の過程がまとまっている。
- インターネットの特徴
- 「インターネット」とは、複数のインターネットサービスプロバイダで構成されたネットワーク
- 通信に使用する経路が常に同一であることや、性能、可用性は全体では保証されていない
- そもそもインターネットに限らず、ネットワークは通信する距離が長くなるほど通信にかかる時間も増加する。それに加えて経由するネットワークが増えることで、この不規則さの影響を受けやすくなる。つまり、ユーザの通信でインターネットを使用する距離が長くなるほど、速度や安定性の懸念が大きくなりやすい。
よくある構成なので当たり前のように感じるかもしれませんが、通信経路に使用している「インターネット」の特徴を確認しておきましょう。
インターネットとは 複数のインターネットサービスプロバイダで構成されたネットワーク です。通信に使用する経路が常に同一であることや、性能、可用性は全体では保証されていません。そもそもネットワークは通信する距離が長くなるほど通信にかかる時間も増加します。それに加えて経由するネットワークが増えることで、この不規則さの影響を受けやすくなるということです。つまりユーザーの通信でインターネットを使用する距離が長くなるほど、速度や安定性の懸念が大きくなりやすいのです。
もしこれが世界中のユーザーに提供するような Web サービスだとどうでしょうか ? 通信速度や安定性に不満を持つユーザーが増えてしまうかもしれません。多くのユーザーから画像や動画取得リクエストが Web サービスに送られることで、サーバーの処理能力や負荷も気にすることが増えていきます。
そんな時にあると嬉しいのが Amazon CloudFront です !
CDN(CloudFront)を使うと...
以下の図の構成の特徴:
- エッジロケーションから AWS リージョンまでの通信は「AWS ネットワークバックボーン」を使用する
- ユーザーから近くのエッジロケーションまでの通信はインターネットを使用した経路
- エッジロケーションに画像や動画などの静的コンテンツをキャッシュすることで、オリジンの負荷軽減や多くのユーザーへ効率の良い配信ができる

AWS ネットワークバックボーンとは?
上に示した構成図に記載されている「AWS ネットワークバックボーン」は、完全冗長の複数の 100 GbE 並列ファイバーで構成されているため、高いパフォーマンスの通信を実現しやすくなる。
例えるならインターネットが「一般道を使って渋滞や工事中の道を考慮しながら目的地まで到達する」のに対して、AWS ネットワークバックボーンは「道幅も広く複数の車線があり、AWS 利用者のみに用意された高速道路で目的地まで到達する」といったところでしょうか ٩(๑・∀・)۶
エッジロケーションと AWS リージョン間の通信は AWS ネットワークバックボーンを経由することで、ユーザーがインターネットを使用する距離は「世界中に多く存在する中から近くのエッジロケーションまで」で済む。
ユーザーとサーバの距離が遠くても、通信の性能が不安定な部分を減らせるのが CDN の重要な役割の 1 つ。
以下の図もわかりやすい。
- 通信経路
- ユーザ ↔ 近くのエッジロケーション:インターネット
- 近くのエッジロケーション ↔ オリジンサーバ:AWS ネットワークバックボーン

CDN によるキャッシュ
図がすばら
エッジロケーションには画像や動画などの静的ファイルをキャッシュとして保存できる設定があります。ショッピングサイトの商品画像や動画配信サイトの動画など、ユーザーがアクセスしたエッジロケーションにコンテンツのキャッシュがあれば、オリジンにアクセスすることなくコンテンツの取得をより高速にできます !

キャッシュを活用できればユーザーが嬉しいだけではなく、オリジンの負荷削減につながるのでサービス提供者にも嬉しさがあります !
キャッシュの仕組みをもっと知りたい方は Amazon CloudFront ユーザーガイドの キャッシュの最適化と可用性 を読んでみてください。
1 つの CloudFront ディストリビューションには複数のオリジン紐付けができるので、パスによって静的コンテンツと動的コンテンツのオリジンを振り分け、それぞれに異なるキャッシュポリシーを設定する構成も取れます。
- AWS 公式:キャッシュと可用性
CloudFront:エッジロケーションのキャッシュとリージョナルエッジキャッシュによる多段キャッシュ
厳密に言うと、Amazon CloudFront でキャッシュを利用する場合、エッジロケーションとオリジンの間にはリージョナルエッジキャッシュ (リージョン別エッジキャッシュ) という、より多くの容量を確保できるロケーションが連携される。
個別のエッジロケーションではしばらくアクセスがないコンテンツは、キャッシュ保持期限内でも容量の問題で削除されてしまうことがある。しかしリージョナルエッジキャッシュにより、より多くのコンテンツをキャッシュで保持できるため全体的なパフォーマンスが向上する。
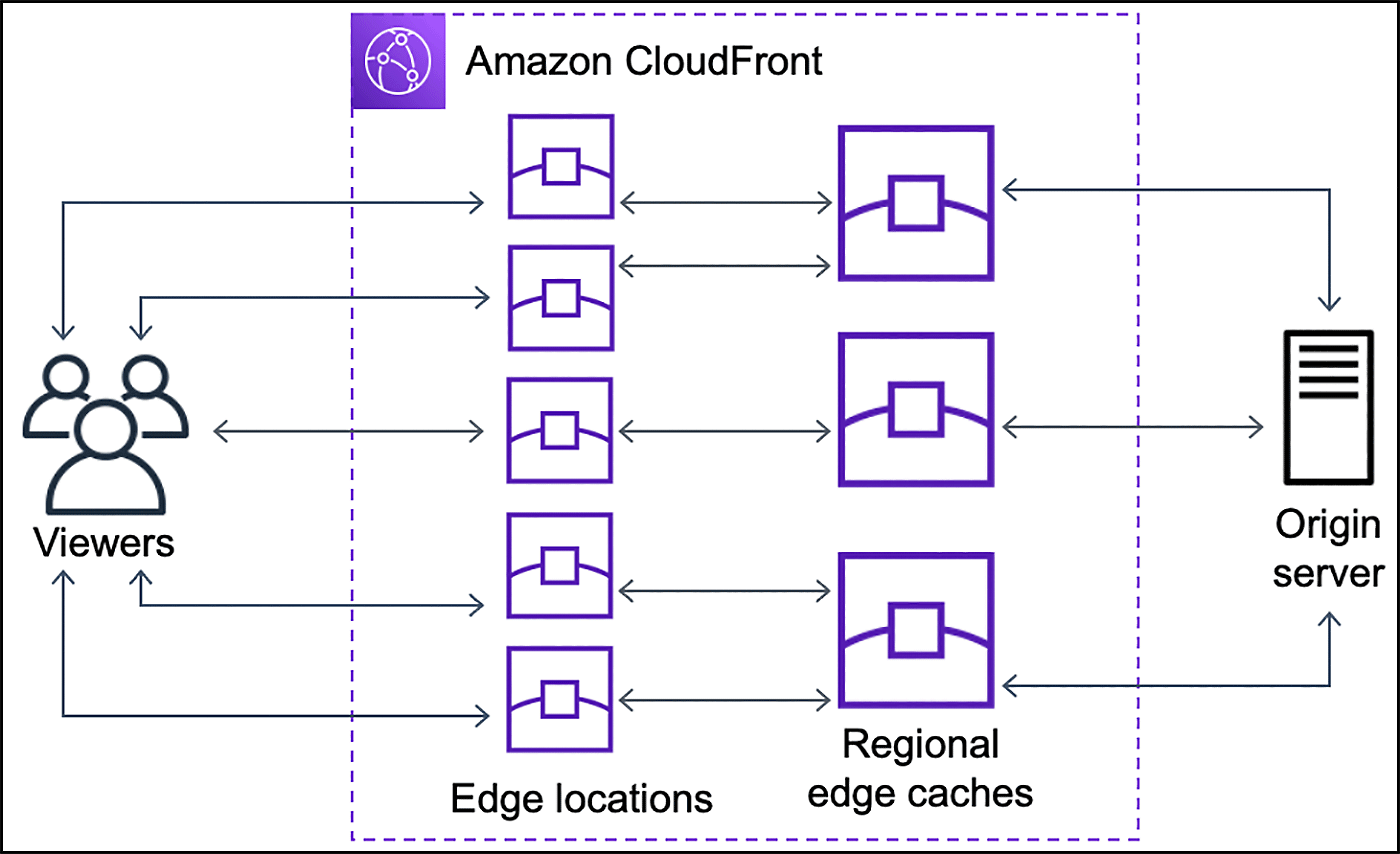
- AWS 公式:CloudFront とリージョン別エッジキャッシュとの連携
Future の記事と AWS の CloudFront 解説記事を見ると、一番最初に書いた CDN の 2 つに加えて、インターネットを経由することによる通信の不安定な部分を減らす、という役割もある。
主要な役割に比べて間接的な役割かもしれないけど。
CDN の役割
- 静的コンテンツ(HTML/CSS/JS/画像など)が入ったオリジンサーバへのアクセス集中を防ぐための負荷分散
- 地理的な制約によるコンテンツの配信遅延の軽減
- インターネットを経由することによるユーザとオリジンサーバ間の通信の不安定な部分を減らす
- CDN なし:ユーザ---インターネット---→オリジンサーバ
- CDN あり:ユーザ---インターネット---→エッジロケーション---ベンダーのネットワークバックボーン→オリジンサーバ
- ※「地理的な制約による云々」にこの性質が含まれるかもしれないけどキャッシュとは別の性質なのであえて分けて書いてある
CloudFront のユーザとエッジロケーションの通信の仕組み
これまで見てきたユーザのリクエストをどのようにエッジロケーションに向けるかの CloudFront 版。
CloudFront ディストリビューションのドメイン名に仕掛けがあります。このドメイン名を DNS で名前解決すると、ネームサーバーはクライアント端末から通信に最適な (通常はレイテンシーを考慮した最寄りの) エッジロケーションの IP アドレスを返してくれます。なのでユーザーには最寄りのエッジロケーションを意識させる必要がないのです !

ようやく登場する Cloudflare Workers。
CloudFront Functions はちょうど業務で使ったばっか。
CDN のエッジサーバでアプリケーションを実行するサービスたち
- Vercel Edge Functions
- Cloudflare Workers
- AWS CloudFront Functions
- → エッジロケーション
- AWS Lambda@Edge
- → リージョンエッジ
- CloudFront Functions の方がユーザに近い場所で実行される
上記のサービスの強み:
自分が CloudFront Functions で使ったことあるのは、「ヘッダの書き換え」と「リダイレクト」。
これらのサービスは、例えば次のようなユースケースをエッジサーバー上で利用できる(すなわち、通常のクラウドより低遅延である)ことが強みとされています:
- ヘッダの書き換え
- トークンの検証と認可
- デバイス判定
- A/B テスト
- IP ブロック
- リダイレクト
Cloudflare Workers とは?
Cloudflare Workers の特徴:
- 0ms cold starts のサポート
- 通常のサーバーレス環境で発生するコールドスタートが発生しない
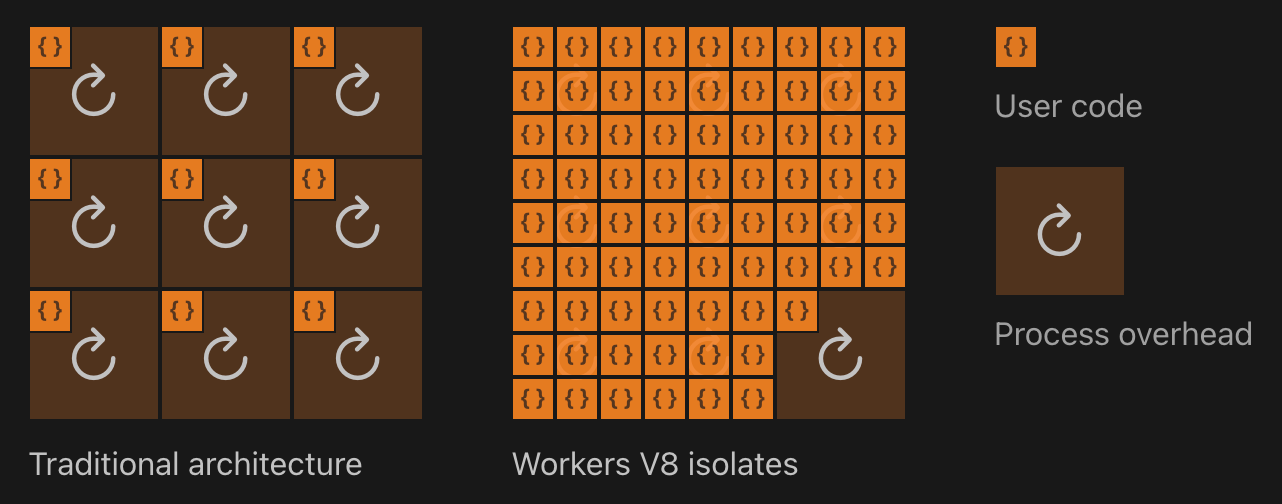
- Cloudflare workers では内部的にコンテナではなく、JavaScript エンジン V8 の isolate という機能を使用している。これにより
- 詳しくは How Workers works を参照
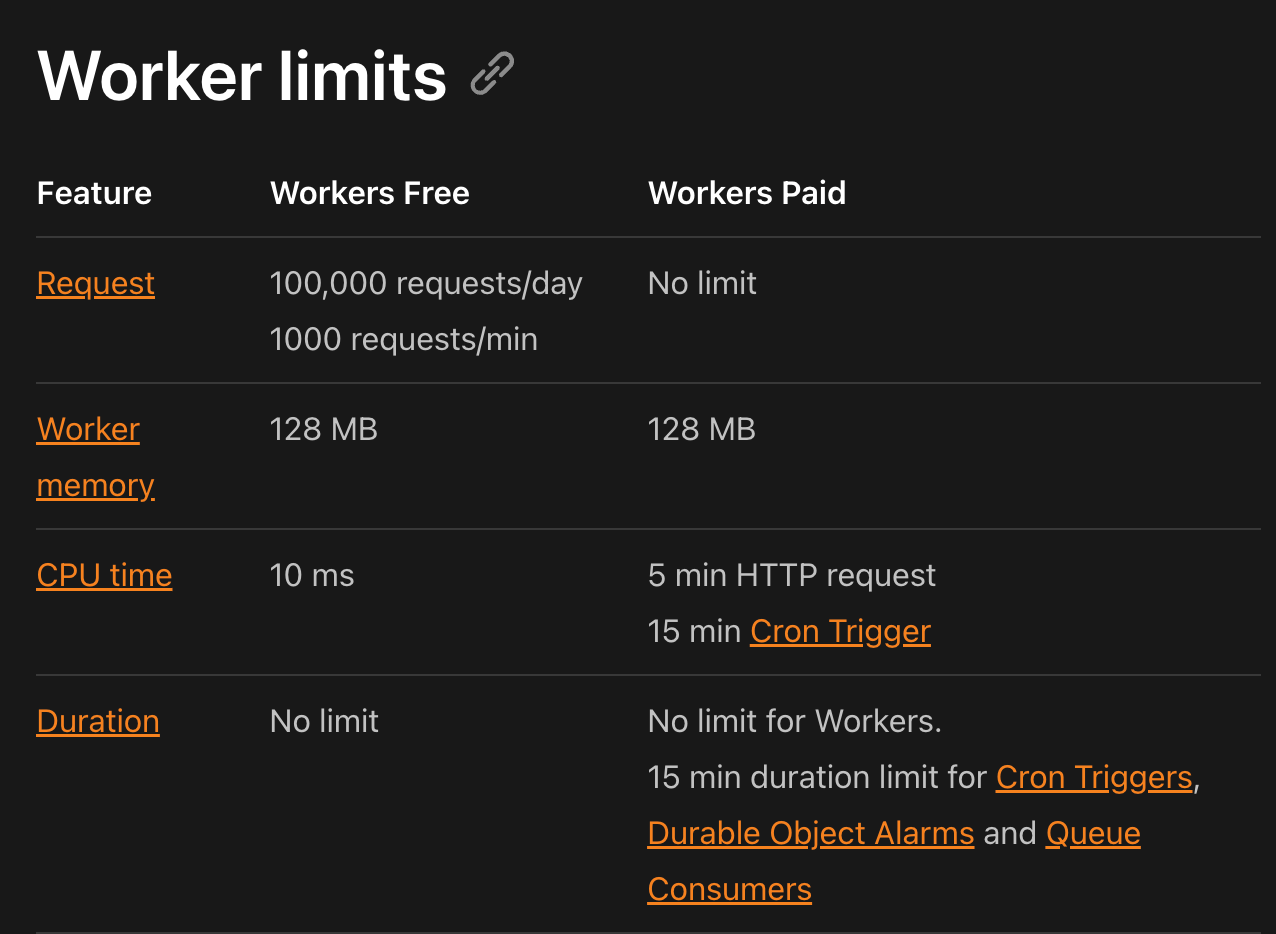
- CPU runtime の 10ms 制限(2025.06.08 現在。フリープラン。)
- そのため、重い処理は実行できない
- Workers limits を参照
JavaScript エンジン V8 の isolates 機能
V8 orchestrates isolates: lightweight contexts that provide your code with variables it can access and a safe environment to be executed within. You could even consider an isolate a sandbox for your function to run in.
A single instance of the runtime can run hundreds or thousands of isolates, seamlessly switching between them. Each isolate's memory is completely isolated, so each piece of code is protected from other untrusted or user-written code on the runtime. Isolates are also designed to start very quickly. Instead of creating a virtual machine for each function, an isolate is created within an existing environment. This model eliminates the cold starts of the virtual machine model.
Unlike other serverless providers which use containerized processes ↗ each running an instance of a language runtime, Workers pays the overhead of a JavaScript runtime once on the start of a container. Workers processes are able to run essentially limitless scripts with almost no individual overhead. Any given isolate can start around a hundred times faster than a Node process on a container or virtual machine. Notably, on startup isolates consume an order of magnitude less memory.
A given isolate has its own scope, but isolates are not necessarily long-lived. An isolate may be spun down and evicted for a number of reasons:
- Resource limitations on the machine.
A suspicious script - anything seen as trying to break out of the isolate sandbox.- Individual resource limits.
Because of this, it is generally advised that you not store mutable state in your global scope unless you have accounted for this contingency.
If you are interested in how Cloudflare handles security with the Workers runtime, you can read more about how Isolates relate to Security and Spectre Threat Mitigation.

和訳 by o3
アイソレート(Isolates)
V8 では アイソレート と呼ばれる軽量コンテキストを管理します。アイソレートは、コードがアクセスできる変数と安全に実行できる環境を提供するため、関数のサンドボックスと考えることもできます。
高速で分離された実行環境
- 1 つの V8 ランタイムインスタンス(エッジサーバではコンテナとして動かしている)で数百〜数千のアイソレートを同時に実行でき、必要に応じてシームレスに切り替わります。
- 各アイソレートのメモリは完全に隔離されているため、他の信頼できないコードやユーザ作成コードから保護されます。
- (コンテナとは仕組みはことなるけど、「アプリケーションごとにリソースが隔離された実行環境を用意する」を実現できる)
- アイソレートは起動が非常に速く、関数ごとに仮想マシンを新規作成する方式で発生する コールドスタート がありません(e.g. AWS Lambda のコールドスタート)。
Workers と従来型サーバーレスの違い
| 実行モデル | 起動オーバーヘッド | |
|---|---|---|
| 従来型 | コンテナごとに言語ランタイムを起動 | 大きい |
| Workers | 1 度だけ JavaScript ランタイムを起動し、 その上で多数のアイソレートを生成 |
ほぼゼロ |
- Workers では、コンテナ起動時に JavaScript ランタイムのコストを 1 回 支払うだけで済みます。
- その後は無制限にスクリプトを実行でき、個々のスクリプトに追加でかかるオーバーヘッドはほとんどありません。
- isolate はコンテナや VM 上で Node プロセスを立ち上げる場合に比べ、約 100 倍速く起動 し、起動時メモリも 1 桁以上少なく 済みます。
なるほど、V8 を動かすコンテナ(プロセス)を起動すればあとはその上で隔離された JavaScript 実行環境を作れるのか。
AWS Lambda とかは関数実行時に都度コンテナ(プロセス)の起動が必要だから実行ごとにプロセス起動のオーバーヘッドがあるが、V8 の isolate には V8 のコンテナ起動時のオーバーヘッドのみで、スクリプト(関数)実行時の起動オーバーヘッドが小さいので立ち上がりが高速。
アイソレートが終了する主な理由
- マシン上のリソース制限に達したとき
- サンドボックスを抜け出そうとする不審なスクリプトが検出されたとき
- 個別の CPU/メモリ制限を超えたとき
このため、グローバルスコープに書き換え可能な状態を持たせる設計は推奨されません。どうしても必要な場合は、アイソレートの終了を想定したフォールバックを用意してください。
→ isolate で動かす処理はステートレスにしてってことね。この点においてはコンテナを前提としたシステム設計でも同じ。
Cloudflare Workers の利用例
Cloudflare Workers の利用例は公式ドキュメントに記載されている。
- JSON の取得
- リダイレクト
- A/B テスト
- CORS ヘッダープロキシ
- トークンの検証と認可
- Basic 認証
- ストレージや DB へのアクセス
Cloudflare Workers x React Router の処理の流れの理解
ひとまず Cloudflare Workers の処理の流れの理解が必要。
エントリーポイント
Cloudflare Workers のエントリーポイントは wrangler の設定ファイル(ここでは wrangler.jsonc)の main フィールドで決まる。
公式ドキュメントの React Router (formerly Remix) のプロジェクト作成方法でプロジェクトを初期化した場合、デフォルトは ./workers/app.ts がエントリーポイントになっている。
{
"$schema": "node_modules/wrangler/config-schema.json",
"name": "chatai",
"compatibility_date": "2025-04-04",
"main": "./workers/app.ts",
"vars": {
"VALUE_FROM_CLOUDFLARE": "Hello from Cloudflare"
},
"observability": {
"enabled": true
}
}
workers/app.ts
workers/app.ts の初期状態は以下の通り:
import { createRequestHandler } from "react-router";
declare module "react-router" {
export interface AppLoadContext {
cloudflare: {
env: Env;
ctx: ExecutionContext;
};
}
}
const requestHandler = createRequestHandler(
() => import("virtual:react-router/server-build"),
import.meta.env.MODE,
);
export default {
async fetch(request, env, ctx) {
return requestHandler(request, {
cloudflare: { env, ctx },
});
},
} satisfies ExportedHandler<Env>;
cloudflare workers の実行の仕組みは理解できてきたけど、実際にリクエストを受けたときにエントリーポイントの fetch が動作する仕組みがわからない by o3
ざっくり結論
Cloudflare Edge の workerd ランタイムが「イベント駆動サーバー」になっていて、HTTP リクエストを受けるたびに fetch(request, env, ctx) をコールバックとして呼び出す──ただそれだけ、という仕組み。
アプリ側はソケットを開かず待ち受けもしない。Edge が “イベント” をプッシュしてくるイメージだよ。(blog.cloudflare.com)
フローを一枚で
┌─① DNS anycast──┐
│ Browser │
└────────┬────────┘
▼
Cloudflare POP
(FL/Reverse-proxy)
▼ ② ルート照合
workerd プロセス
▼ ③ アイソレート取得 or 作成
┌──────────────────────┐
│ JavaScript isolate │
│ ───────────────── │
│ ▲ global scope │
│ │ import … │
│ │ export default { │
│ │ async fetch… } │
│ └──────────────────│
└────────┬────────────┘
▼ ④ fetch(req,env,ctx)
▼ ⑤ Response を Edge へ返却
Browser ◀─⑥ HTTP 応答──┘
ステップ別解説
| # | 何が起きる? | 主要ソース |
|---|---|---|
| ① DNS & ルーティング Anycast DNS で最寄り PoP に到達。 |
||
② ルートマッチwrangler.toml で設定した Routes / Custom Domain のパターンに合致するか判定。合致したらその Worker サービス名を特定。(developers.cloudflare.com) |
||
| ③ アイソレート取得 workerd プロセスはすでに各 Worker の JavaScript/Wasm バイトコードをメモリに持っている。 * アイソレートがアイドル中なら再利用 * 無ければ新規に V8 Isolate を作成(数百 µs 程度) |
||
| ④ イベントをプッシュ workerd が new Request() / ExecutionContext を組み立て、ESM モジュールの export default { fetch }(または addEventListener('fetch', …))を直接呼び出す。ここが “エントリーポイント” と言われる部分。(developers.cloudflare.com, developers.cloudflare.com) |
||
⑤ レスポンス受領fetch() が Response を返す or await 完了 → workerd が HTTP ヘッダー/ボディをシリアライズ。 |
||
| ⑥ ブラウザへ送信 TCP コネクションはすでに Edge-client 間で張られているので、そのまま返却。 |
ちょっと深掘り Q&A
Q1. fetch が呼ばれるタイミングはどう決まる?
→ ルートマッチした瞬間に “Fetch Handler” が起動する、と Cloudflare Docs でも明言されている。(developers.cloudflare.com)
Q2. Service-worker 文法 vs ESM モジュール
| 旧 (Service Worker) | 新 (ESM) |
|---|---|
addEventListener('fetch', evt ⇒ evt.respondWith(handle(evt.request))) |
export default { async fetch(request, env, ctx) { … } } |
| ESM の方がツリーシェイク効くし型付けも楽。どちらも内部では同じ dispatch ルーチンが呼ばれる。 |
Q3. どうしてソケットを開かなくていいの?
workerd は “サーバーファースト” 設計。アプリが listen() する代わりに Edge がイベントを注入 する方式だから。(blog.cloudflare.com)
Q4. アイソレートはいつ終わる?
- メモリ圧迫・CPU リミットオーバー
- セキュリティ的に怪しい挙動
- Edge 内部のリバランス
このどれかで “冷凍・廃棄” されることがある。なので mutable なグローバル状態は基本 NG。
Q5. コンテナ型サーバーレスとの違いは?
コンテナだと “VM / コンテナ起動 → ランタイム起動 → ユーザコード” の 3 段ステップ。
Workers は “ランタイム常駐 → アイソレートだけ差し替え” の 1 ステップなので、起動が 10² 倍速くメモリも 1 桁小さい。(blog.cloudflare.com)
これで 「リクエスト → fetch() までの裏側」 が見えたはず!
もっと奥の workerd C++ 実装や RPC パイプラインが気になったら、open-source リポジトリを覗くと楽しいよ。