Amazon ECS / Amaozn Elastic Container Service 情報整理
入門資料
- (2020/04)【AWS Black Belt Online Seminar】Amazon Elastic Container Service (Amazon ECS)
- ちょっと古いけど根本は変わらんよね
アジェンダ


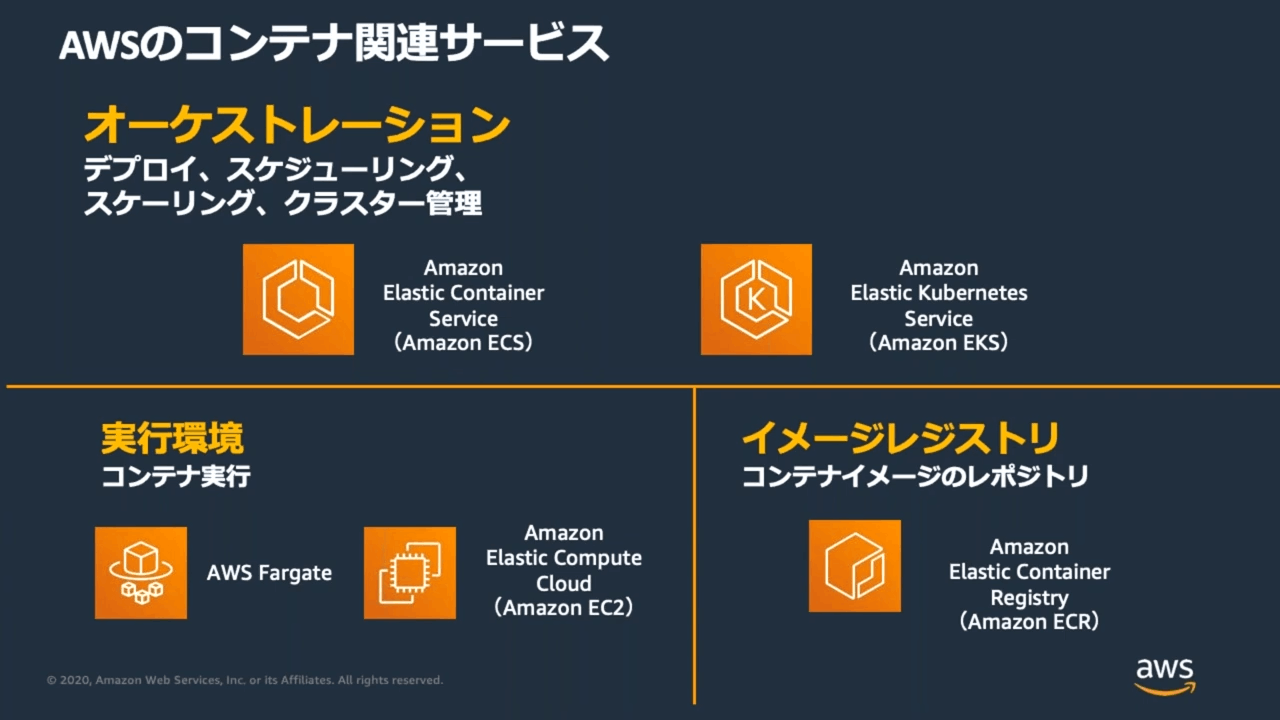

Amazon ECS の機能
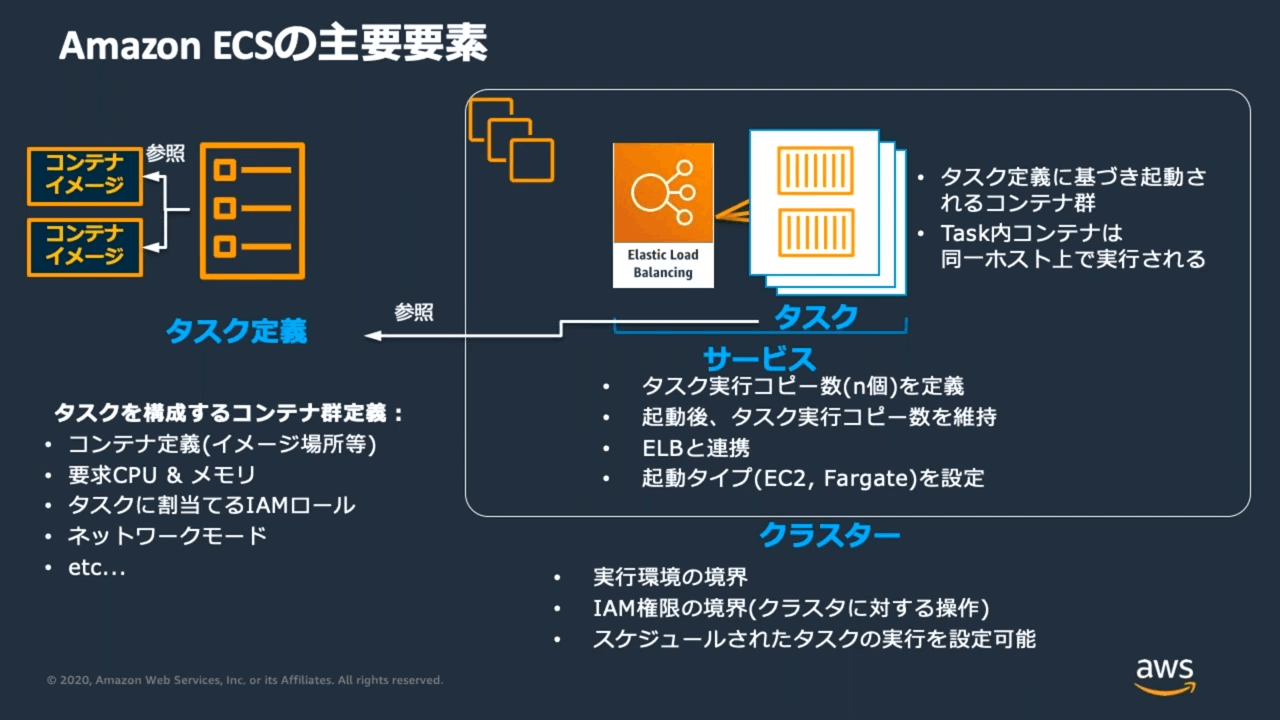
Amazon ECS の主要要素
- タスク定義
- クラスタ
- 実行環境の境界
- IAM 権限の境界
- タスク
- タスク定義に基づいて、クラスタ内でインスタンス化される
- サービス
- 決められた数のタスクを維持する
コンテナの実行環境

EC2 インスタンスがクラスタに登録されるまで
登録の流れ

Amazon ECS-optimized AMI と ECS コンテナエージェント

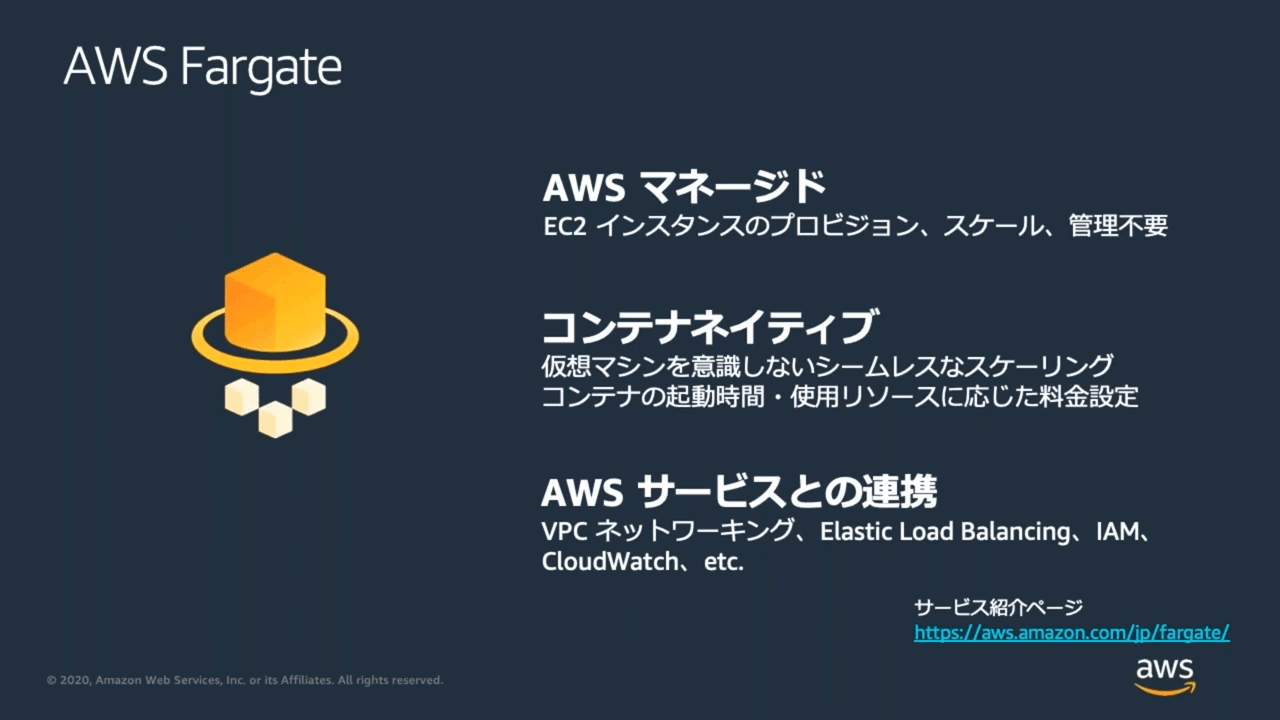
AWS Fargate
概要と EC2 クラスタと何が異なるか
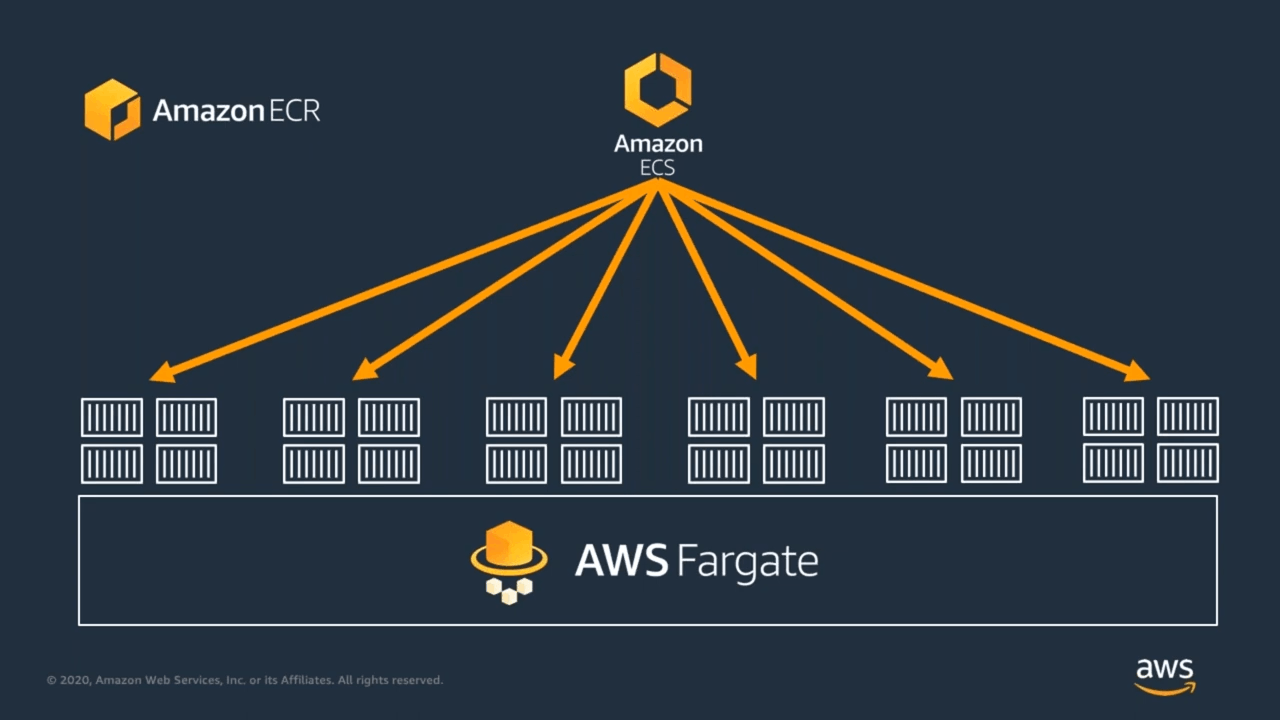
before: ECS with Amazon EC2 仮想マシン上でコンテナが実行されている

after: ECS with AWS Fargate
仮想マシンの運用(OS パッチ当てなど)がなくなる
料金体系
割り当て CPU、メモリ設定で料金体系が決まり、稼働時間によって従量課金される。
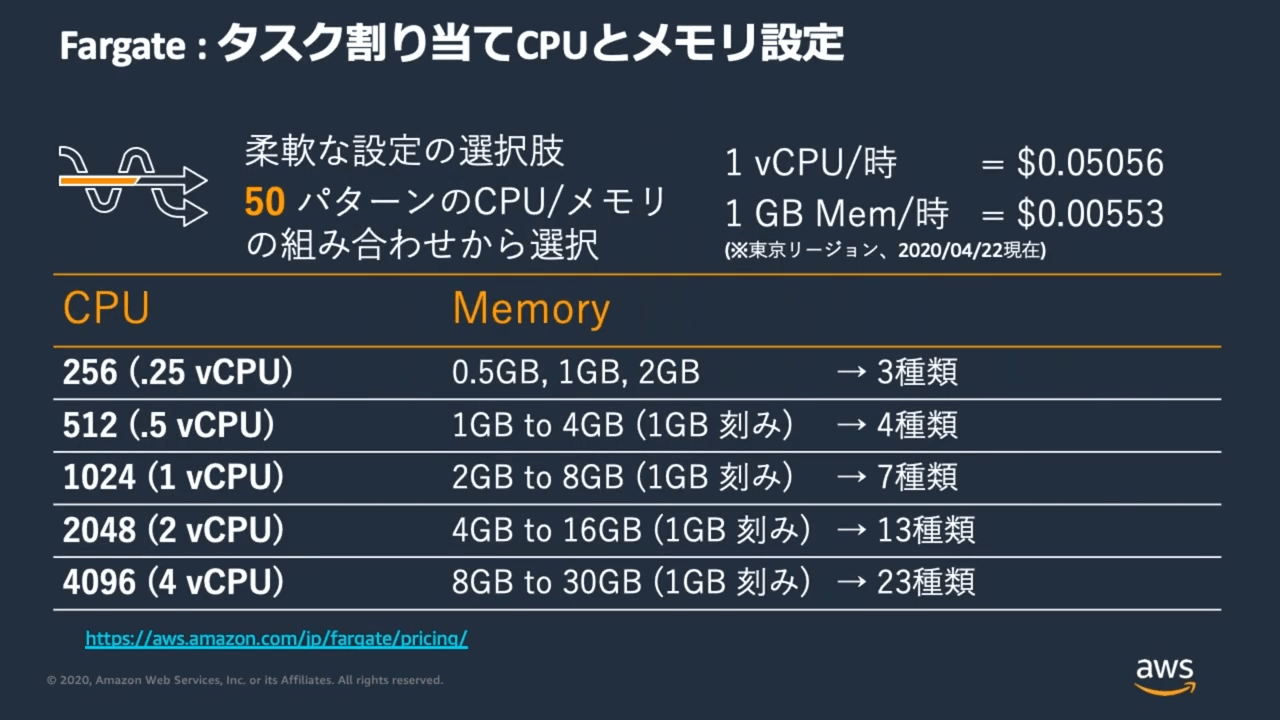
ミニマムは CPU 256、Memory 512 GB
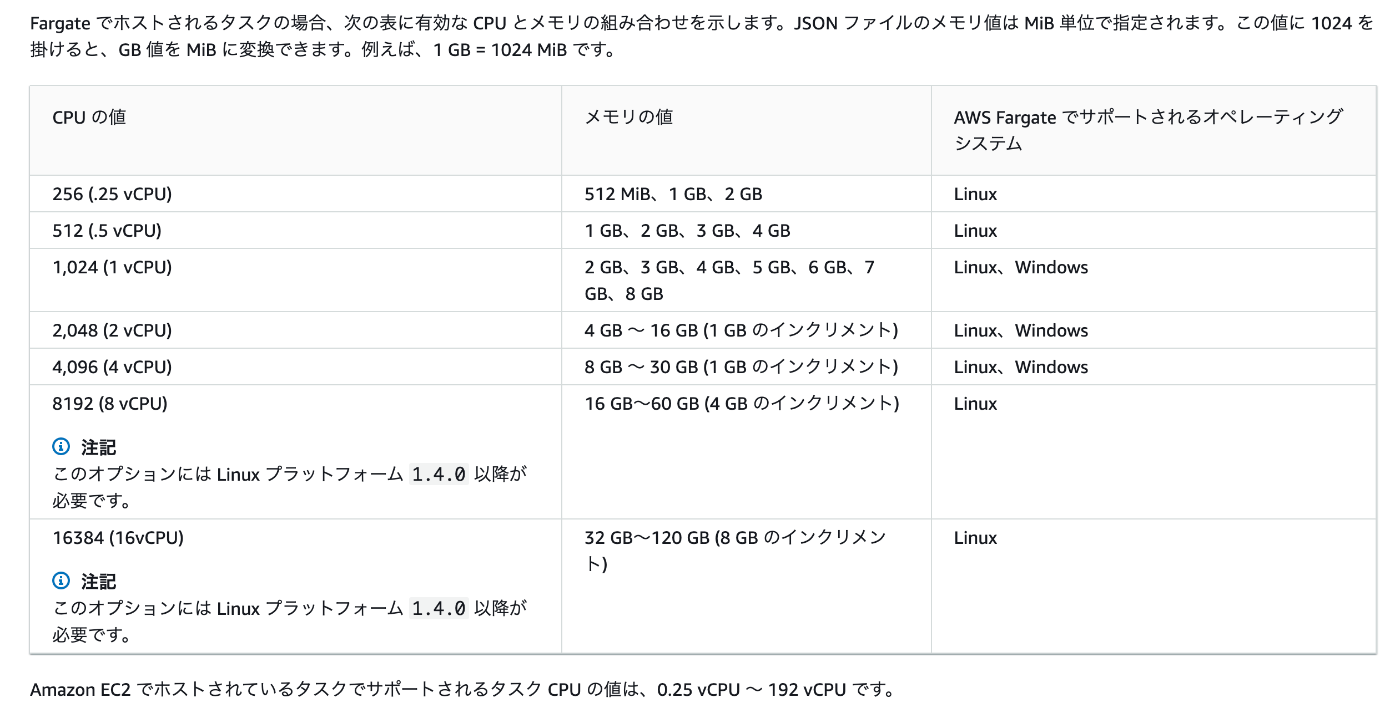
この値をめちゃくちゃ小さくしたら、ecspresso deploy を実行したときにエラーになった。タスク定義が間違っており、Fargate にはそんな組み合わせの設定ないでって怒られた。

- AWS 公式ドキュメント:Amazon ECS タスク定義の無効な CPU またはメモリエラーをトラブルシューティングする
コンテナのログの扱い
- 一般的にコンテナで動かすアプリケーションのログは stdout / stderr に吐くのが良いとされている
- 理由
- ローカルの開発環境でもデバッグが容易
- ログの出力ストリームの送り先は実行環境側でコントロールすべき
- 理由

コンテナでの機密情報の扱い
コンテナから機密情報にどうアクセスするか

タスク定義
Amazon ECS と IAM の連携:タスクロール、タスク実行ロール

ネットワークモード:コンテナネットワークの動作を設定する




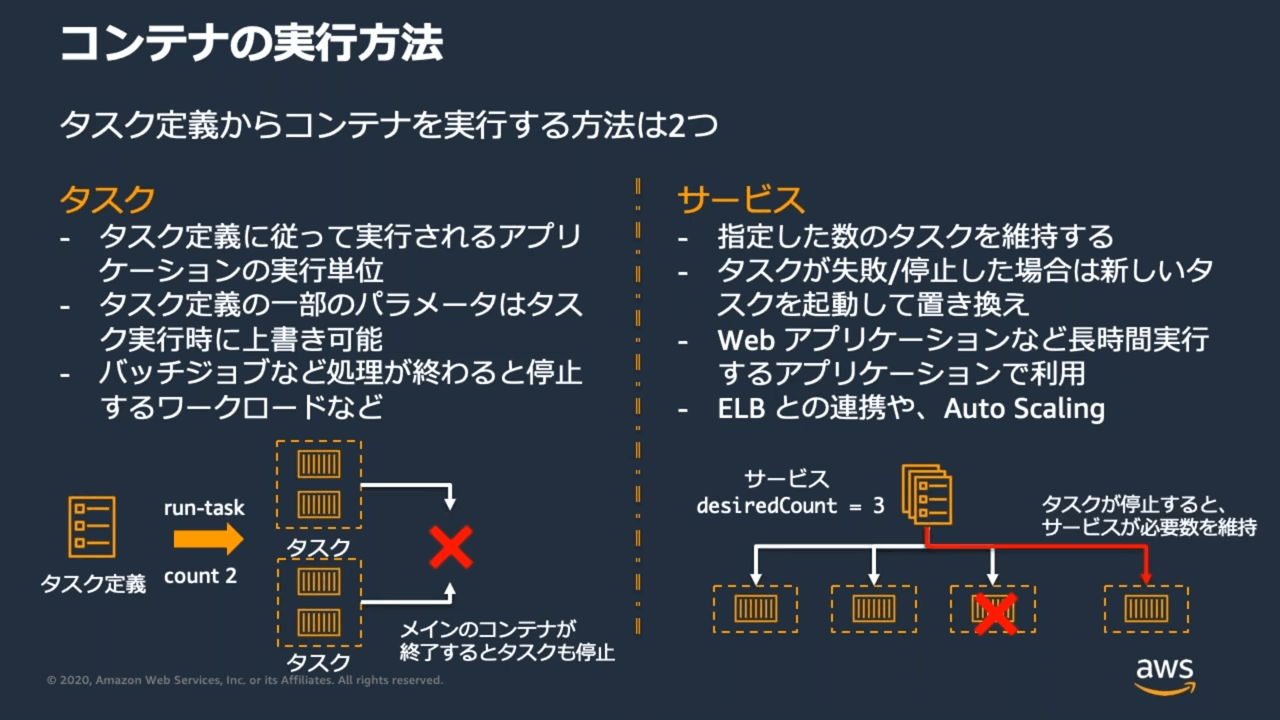
コンテナの実行:タスク定義からコンテナを実行する
タスク定義からコンテナを実行する方法は 2 つ:
- タスク
- タスク定義に従って実行されるアプリケーションの実行単位
- バッチジョブなど、処理が終わると停止するワークロードなどに適する
- サービス
- 指定した数のタスクを維持する
- タスクが失敗、停止した場合(エラーでコンテナが停止するなど)、新しいタスクを起動して置き換えを行い、設定した必要数のサービスを維持するように動く
- Web アプリケーションなど長時間実行するアプリケーションで利用
- ELB との連携や、Auto Scaling
タスクのライフサイクル

サービスの Auto Scaling

タスクの起動に失敗したときの動作:サーキットブレイカーとロールバック
Q. タスクが起動に一定回数以上失敗したら再起動を止めることはできる?
(Claude 3.5 Sonnet の回答めっちゃ分かりやすかった)
はい、ECS サービスで一定回数以上タスクの起動に失敗した場合に再起動を停止する方法があります。これは「サービス自動スケーリング」の設定を使用して実現できます。具体的には、deployment circuit breaker と rollback の機能を組み合わせて使用します。
現在のサービス定義には既に deploymentCircuitBreaker が含まれていますが、これをより詳細に設定することで、望む動作を実現できます。
サービス定義を以下のように修正することで、タスクの起動失敗に対応できます:
{
"deploymentConfiguration": {
"deploymentCircuitBreaker": {
"enable": true,
"rollback": true
},
"maximumPercent": 100,
"minimumHealthyPercent": 0
},
"deploymentController": {
"type": "ECS"
},
"desiredCount": 1,
"enableECSManagedTags": true,
"enableExecuteCommand": false,
"launchType": "FARGATE",
"networkConfiguration": {
"awsvpcConfiguration": {
"assignPublicIp": "ENABLED",
"securityGroups": null,
"subnets": [
"{{ must_env `SUBNETS` }}"
]
}
},
"platformFamily": "Linux",
"platformVersion": "LATEST",
"propagateTags": "NONE",
"schedulingStrategy": "REPLICA",
"serviceRegistries": [],
"healthCheckGracePeriodSeconds": 60
}
主な変更点と説明:
-
deploymentCircuitBreaker:-
enable: true: Circuit Breaker を有効にします。 -
rollback: true: 失敗時に前のバージョンに戻します。
-
-
healthCheckGracePeriodSeconds:- これを追加することで、タスクの起動後、指定された秒数の間はヘルスチェックの失敗を無視します。これにより、アプリケーションの起動に時間がかかる場合でも、過早に失敗と判断されることを防ぎます。
-
maximumPercentとminimumHealthyPercent:- これらの値により、デプロイメント中のタスクの動作を制御します。現在の設定では、すべてのタスクを一度に更新することができます。
この設定により、以下のような動作が期待できます:
- タスクの起動に失敗すると、ECS は自動的に再試行します。
- 一定回数(デフォルトでは 10 分間で 10 回)失敗すると、Circuit Breaker が発動します。
- Circuit Breaker が発動すると、
rollback: trueの設定により、前のバージョンのタスク定義に戻ります。 - もし前のバージョンも失敗する場合、サービスは最終的にタスクの起動を停止します。
注意点:
- 完全な停止を避けるため、少なくとも 1 つの健全なタスクを維持することを検討してください。
- ログとモニタリングを適切に設定し、失敗の原因を迅速に特定できるようにしてください。
-
healthCheckGracePeriodSecondsの値は、アプリケーションの起動時間に応じて適切に調整してください。
これらの設定により、タスクの起動に繰り返し失敗した場合でも、サービスが無限にリソースを消費し続けることを防ぎ、前の安定したバージョンにロールバックすることができます。
healthCheckGracePeriodSeconds はロードバランサの設定をしているときのみ使用できるパラメータ
Error: /06 22:08:40 [ERROR] FAILED. failed to update service attributes: operation error ECS: UpdateService, https response error StatusCode: 400, RequestID: 1776c504-4f0a-45f4-b02a-a26b0927bd47, InvalidParameterException: Health check grace period is only valid for services configured to use load balancers
ecs-service-def.json
{
"deploymentConfiguration": {
"deploymentCircuitBreaker": {
"enable": true,
"rollback": true
},
"maximumPercent": 100,
"minimumHealthyPercent": 0
},
"deploymentController": {
"type": "ECS"
},
"desiredCount": 1,
"enableECSManagedTags": true,
"enableExecuteCommand": false,
"launchType": "FARGATE",
"networkConfiguration": {
"awsvpcConfiguration": {
"assignPublicIp": "ENABLED",
"securityGroups": null,
"subnets": [
"{{ must_env `SUBNETS` }}"
]
}
},
"pendingCount": 0,
"platformFamily": "Linux",
"platformVersion": "LATEST",
"propagateTags": "NONE",
"runningCount": 0,
"schedulingStrategy": "REPLICA",
"healthCheckGracePeriodSeconds": 30
}
コンテナアプリケーションの監視
Black Belt
- (2019/11) [AWS Black Belt Online Seminar] Amazon CloudWatch Container Insights で始めるコンテナモニタリング入門
- Q&A もよく見て
- (2021/09) [AWS Black Belt Online Seminar] CON247 メトリクス入門 Container Insights
-
今回扱うのは、Amazon CloudWatch Container Insights を使ったECSおよびEKSにおけるコンテナ単位のメトリクス取得です。セットアップの方法と、チューニングのユースケースも紹介します。
- Q&A もよく見て
-
公式ドキュメント
- Amazon CloudWatch Container Insights
- Amazon ECS 公式ドキュメント:Amazon ECS のモニタリング
- Amazon ECS 公式ドキュメント:Container Insights を使用して Amazon ECS コンテナをモニタリングする
まとめ

補足
Cloud Functions と Cloud Run の使い分け

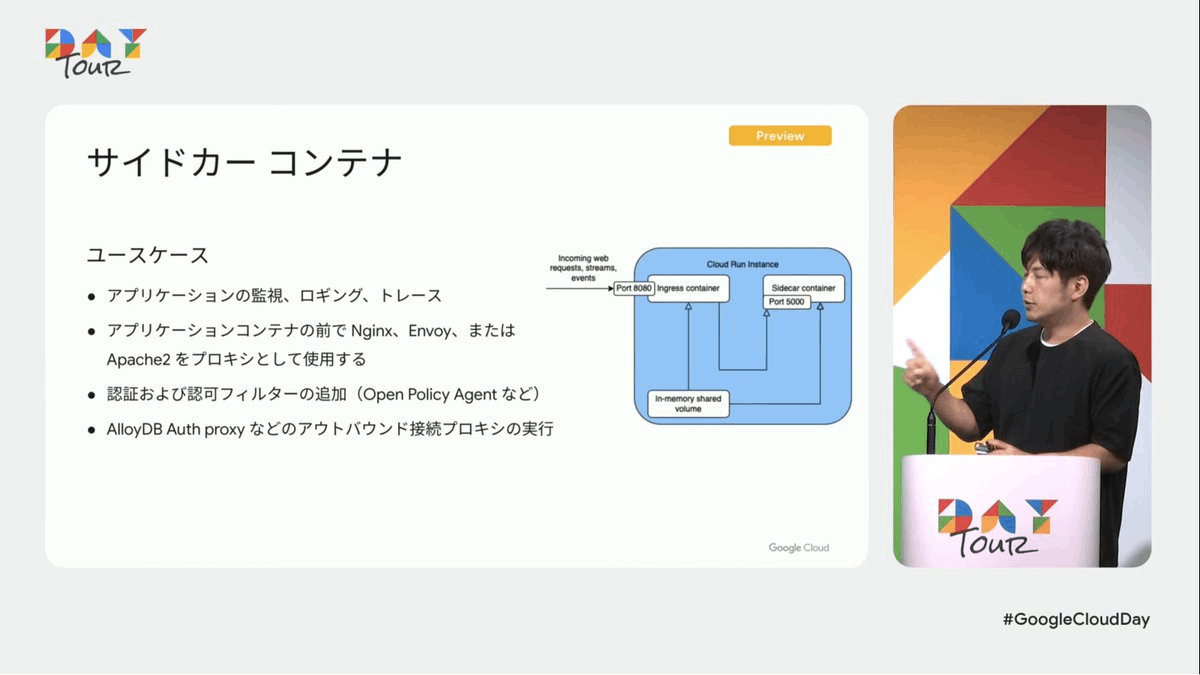
サイドカーコンテナ
ヘルスチェック