nand2tetris 第 2 版をやる ハードウェア編 2025.06.01 ~
放置されて半年。開始する。
リポジトリ


進め方
Coursera の動画見た感じパートの全体像の把握に良さそう。
進め方は「Coursera の動画見る → 本読む → 実装 → Coursera 提出」でやってみようかな。
Coursera には「全体像の把握」と「homework 提出による進捗管理」をやってもらう。
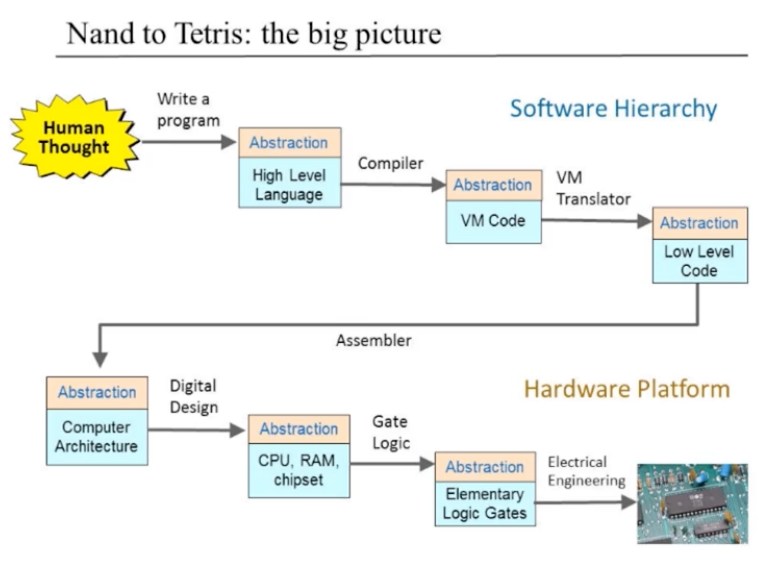
nand2tetris の全体像

作るもの(the Hack Computer)の全体像
Hack という名前のコンピュータを作る

階層:高レベル言語 → VM コード → 低レベル言語 → マシン語 → CPU, RAM, チップセット → 論理ゲート → ハードウェア
ハードウェア実装のための環境構築
ハードウェアパートをやるための環境構築。公式推奨の nand2tetris 用の Web の IDE(シミュレータ)もあるんだけど、古き良き Desktop アプリのシミュレータを触ってみたいので環境構築。Java 製らしい。開発環境には M3 チップ搭載の Macbook Pro を使用している。
- OS: macOS
- Chip: M3 Max
公式で推奨されている Web IDE
Java のインストール
ARM64 DMG Installer をダウンロード

-
.pkgをダブルクリック - インストールウィザードが起動
- ウィザードに従って進めるとインストール完了の旨が表示される
- ウィザードを閉じる
- ターミナルを起動
- Java のバージョン確認:
java -version - ✅️ バージョンが表示されたら Java のインストール完了!

java -version
# java version "24.0.1" 2025-04-15
# Java(TM) SE Runtime Environment (build 24.0.1+9-30)
# Java HotSpot(TM) 64-Bit Server VM (build 24.0.1+9-30, mixed mode, sharing)
Nand2Tetris Software Suite のインストール
- Nand2Tetris Software Suite の zip ファイルのダウンロード
- 解凍
- ハードウェアシミュレータの起動:
sh ./nand2tetris/tools/HardwareSimulator.sh- 起動コマンドは macOS 用の公式セットアップドキュメントの "Install the Nand2Tetris Software Suite" の節を参照
- ✅️ ハードウェアシミュレータが起動すれば Nand2Tetris Software Suite のインストール完了!

環境構築 DONE
✅️ Coursera モジュール 1 の課題 OK
- 環境構築
- 課題提出のテスト
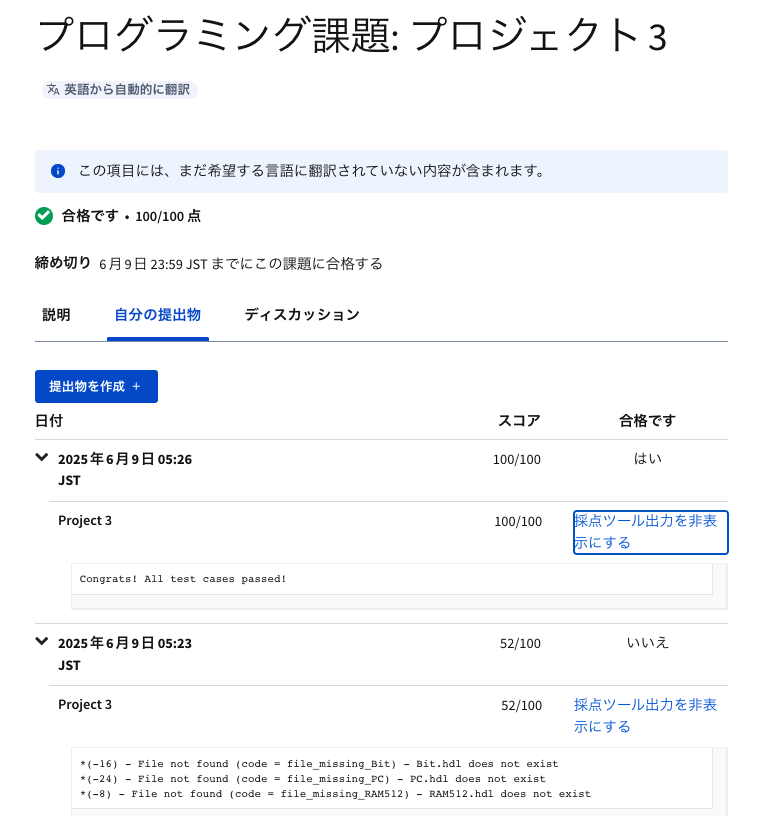
提出画面はこんな感じ。
スコアが表示されて、採点ツールの出力を見ることができる(採点には少し時間がかかる)。

✅️ 2025.06.01 DONE
明日は Coursera モジュール 2 から。
ここからが本題。

先述した進め方で進めてみる。
Coursera の動画見た感じパートの全体像の把握に良さそう。
進め方は「Coursera の動画見る → 本読む → 実装 → Coursera 提出」でやってみようかな。
Coursera には「全体像の把握」と「homework 提出による進捗管理」をやってもらう。
スケジュール
とりあえずの雑スケジュール。1 モジュールに 3 日かける計算。
どんなもんかわからんけど、難易度高いところは時間かかると思われる。
早く終われば巻けばよいし、めっちゃ時間かかったらそういうものだと思って受け入れてじっくり時間をかけて進める。
ただし深堀りのしすぎには注意。終わらせるのが優先。
でも、せっかく時間あるのに深堀りしないのももったいないので、あとで今深掘るのかあとで深堀るのかは選り分ける。
公式が言ってるスケジュールはこんな感じ:
このプロジェクト中心のコースでは、最新のコンピュータシステムを一から構築します。この魅力的な旅を6つの実践的なプロジェクトに分け、初歩的な論理ゲートの構築から完全に機能する汎用コンピュータの作成までを行います。
...
コース形式:
- コースは6つのモジュールで構成され、各モジュールは一連のビデオ講義とプロジェクトで構成されています。
- 各モジュールの講義を視聴するには約2~3時間、6つのプロジェクトを完成させるには約5~10時間が必要です。
- このコースは6週間で修了できますが、ご自分のペースで受講していただいても結構です。

2025.06.02 ~ Project 1:ブール論理
概要
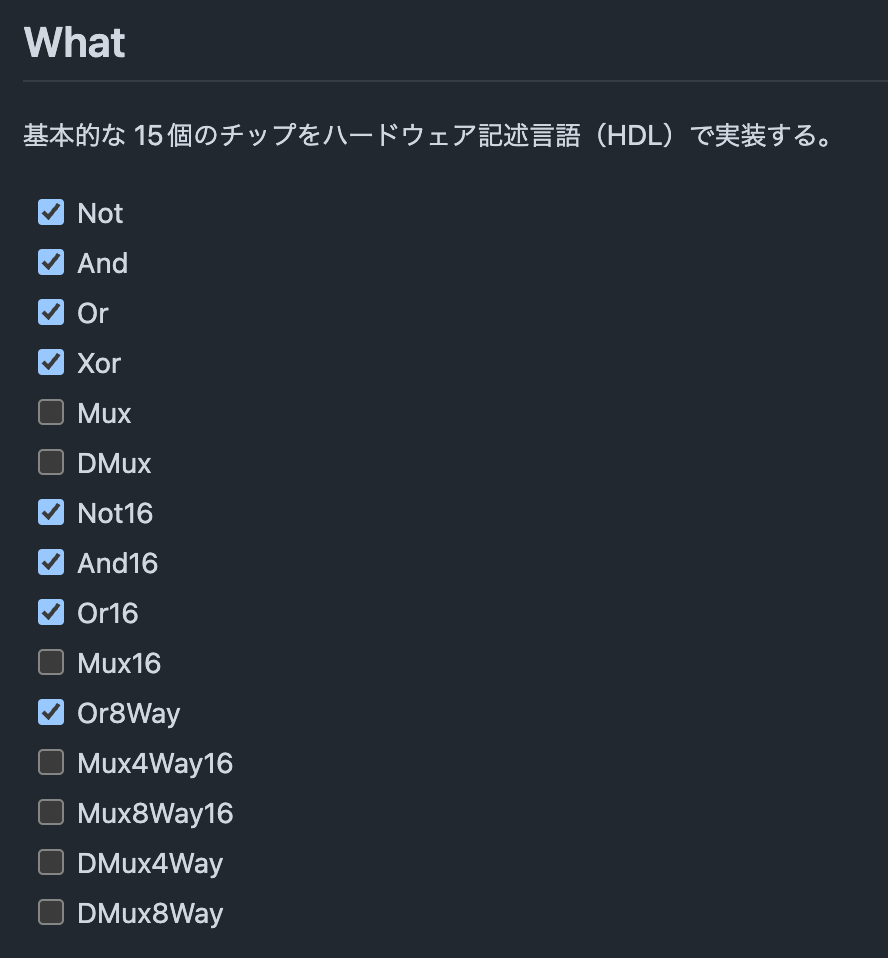
15 個の初等論理ゲートを HDL で実装し、ハードウェアシミュレータでテストする。
ブール代数の簡単な紹介から始め、論理ゲートを使ってブール関数を物理的に実装する方法を学びます。その後、ハードウェア記述言語(HDL)を使用してゲートとチップを指定する方法と、ハードウェア・シミュレータを使用して結果のチップ仕様の動作をシミュレートする方法を学びます。このような背景を踏まえて、15個の初等論理ゲートを構築し、シミュレートし、テストするプロジェクト1の段階を設定します。このモジュールで作成するチップセットは、後にコンピュータの算術論理演算ユニット(ALU)とメモリシステムを構築するために使用されます。これは、それぞれモジュール 2 と 3 で行います。
重要な概念
- ブール代数
- ブール関数
- ゲート論理
- 初等論理ゲート
- ハードウェア記述言語(HDL)
- ハードウェアシミュレーション
プロジェクト1を始める前に、この本の付録AとHDLサバイバルガイドを読んでください。
と Coursera に言われたので、書籍の付録 A、B を読んだ。
付録 A はブール関数の証明について。さらっと読んだ。
付録 B は Hack コンピュータ用の HDL(Hardware Description Language、ハードウェア記述言語)の解説。こっちが重くて 2 時間くらいでじっくり読んだ。
- 付録 A:ブール関数の合成
- 付録 B:ハードウェア記述言語
明日は p.11 ~
2025.06.03 Project 1:ブール論理
続き。書籍 p.11 ~
今日は Xor の実装まで。
明日でモジュール 1 終われそう。
2025.06.04 WED Project 1:ブール論理
続き。Mux / DMux の実装から。
セレクターの作り方が理解できると複数入力のマルチプレクサもさくさく進む。
DMux8Way まで実装完了!

これから 2-3 章で使用する処理チップとメモリチップを作るための基本的な論理ゲートの実装をした。
さらに処理チップとメモリチップは Hack コンピュータの CPU とメモリデバイスの構築に使われる。
✅️ Coursera の Project 1 にも提出完了!

✅️ 2025.06.04 WED Project 1:ブール論理 DONE
実装、Coursera への提出 DONE!!
2025.06.04 WED モジュール 3:コース概要
Project 2 の前のコース概要の説明。30 分程度の Coursera 講義。
開始
コースの宿題は6つのプロジェクトで構成されています:
- プロジェクト1:And、Or、Not、マルチプレクサなどの初歩的な論理ゲートの構築
- プロジェクト2:算術論理演算ユニット(ALU)の構築に至る、加算器チップファミリーの構築
- プロジェクト3:レジスタとメモリ・ユニットの構築、最終的にはランダム・アクセス・メモリ(RAM)の構築
- プロジェクト4:機械語を学び、それを使って低レベルのプログラムを作成します。
- プロジェクト 5: プロジェクト 1~3 で構築したチップセットを使用して、中央処理装置 (CPU) と、プロジェクト 4 で導入した機械語で記述したプログラムを実行できるハードウェア・プラットフォームを構築します。
- プロジェクト 6: アセンブラの開発、つまり記号的な機械語で書かれたプログラムをバイナリ実行可能コードに変換する機能の開発。
この Hack を作る訳ね

✅️ 2025.06.04 WED モジュール 3:コース概要 DONE
2025.06.04 WED Project 2:ブール算術
概要
算術論理演算ユニット ALU を作る
簡単に説明しよう: 前のモジュールで作ったチップセットを使って、次は加算器ファミリーを作る。次に、大きな一歩を踏み出し、算術論理演算ユニット(ALU)を作ります。ALUは算術演算と論理演算の一式を実行するように設計されており、コンピュータの計算頭脳である。コースの後半では、このALUを中心的なチップとして使用し、そこからコンピュータのCentral Processing Unit(CPU)を構築します。これらのチップはすべて2進数(0と1)で動作するため、このモジュールではまず2進数演算の概要を説明し、その後ALUの構築に入ります。
重要な概念
- 2 進数
- 2 進加算
- 2 の補数法
- 半加算器
- 全加算器
- n ビット加算器
- カウンタ
- 算術論理演算装置(ALU)
- 組合せ論理
とりあえずコースの概要を見たので、次は書籍「第 2 章 ブール算術」p.39 から入る。
書籍→実装→ハードウェアシミュレータでテスト→OK なら Coursera に提出。
2 の補数表現理解!
4o に何回か聞いてまとめた。
-
Q. 「2 の補数」とはなんなのか?
「2 の補数」とは「2 進数における負の整数の表現方法」の 1 つ。
-
他にどんな表現方法があるのか?
表現法 特徴 符号付き絶対値 最上位ビットを符号(0:正, 1:負)にする(加減算が面倒) 1 の補数 負数 = ビット反転(1111 = -0 問題がある) 2 の補数 負数 = ビット反転して +1(加減算がシンプル!)← 主流 -
「2 の補数」の定義
nビットの 2 進数で
-xを表すには:2ⁿ - xつまり、nビット中で
xの反転 + 1。「ビット反転して + 1」を覚えよう!!
例えば 8ビットで
-5を表すには:+5 = 00000101 → ビット反転 = 11111010 → +1 = 11111011 ← これが -5(2の補数表現) -
要点
- ✔️ 数の表現方法の一つ
- ✔️ 2進数の世界限定の話
- ❌ 10進数には「2の補数」という考え方は使わない。2 進数の世界限定の話なので。
-
名前の由来
✅ なぜ「2の補数」なの?
この名前の由来は、
2ⁿ - xという数式そのもの。- 通常の減算
A - BはA + (2ⁿ - B)に置き換えられる - この
2ⁿ - Bが「B の 2 の補数」
だから「2の補数」という。
- 通常の減算
-
2 の補数表現をコンピュータの加算、減算に使うのは便利なのは理解できたけど、「内部の数値を 2 の補数表現を使っています」というのは誰が定義しているものなの?
→ CPU(命令セットアーキテクチャ、ISA)を設計する人たちが決めています
たとえば:
- x86 や ARM のようなアーキテクチャでは、「整数の符号付き表現としては 2 の補数を使う」と仕様で明示されている。
- つまり、「命令
ADD,SUBなどは、オペランドを 2 の補数とみなして演算します」とあらかじめ CPU が決め打ちしている。
だから、プログラマやOS、コンパイラはそれに合わせて設計する必要がある。
-
次は加算器の仕様を見る。
- 半加算器(Half Adder):2 つのビットの和を求める
- 全加算器(Full Adder):3 つのビットの和を求める
- 加算器(Half Adder):2 つの n ビットの和を求める
今日は Inc16 の実装まで。
明日 p.48 ~ ALU の仕様を確認して実装。

Inc16 のシミュレーション

2025.06.04 WED Project 2:ブール算術(続き)
続きから。ALU 実装やる。
とりあえず概要把握のため動画見てみる
フォン・ノイマンアーキテクチャ
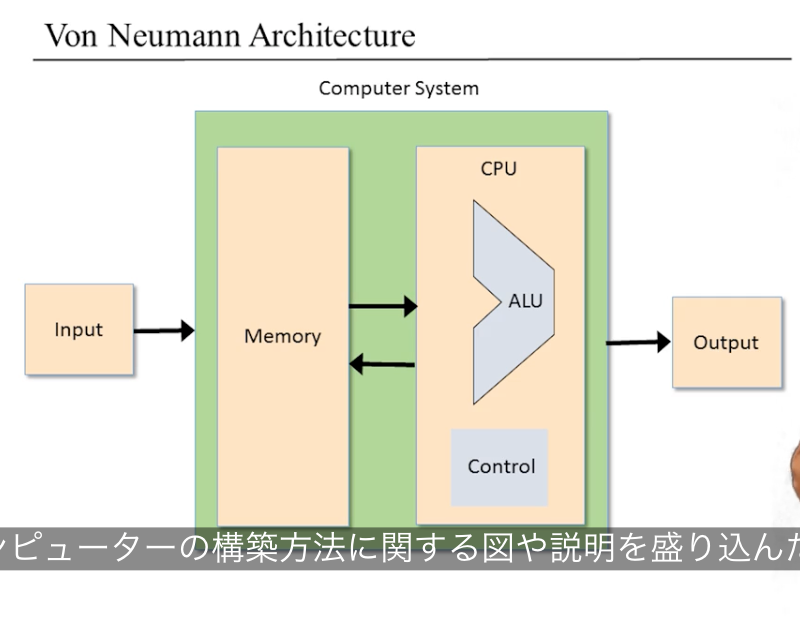
[一般論] ALU とは?
算術論理演算機 Arithmetic Logic Unit (ALU) は算術演算と論理演算を計算するように設計された論理ゲート(nand2tetris では「チップ」)、チップである。2 つの入力を受け取って結果を出力する関数を計算する。
ALU に実装された関数は「あらかじめ定義された(pre-defined)算術関数、論理関数群」である。
f: one out of a family of pre-defined arithmetic and logical function
- 算術演算:整数の加算、乗算、除算
- 論理演算:And, Or, Xor, ...
ALU を実装するとき、どの演算までをハードウェア(ALU)に実装するかの判断をする。
ハードウェアで実装しなくても、ソフトウェアレイヤ(OS レイヤーやその上のアプリケーションレイヤー)で実装することができる。
どのレイヤーで実装するかを考えるときトレードオフを考慮に入れる。ハードに実装すると高速だがチップの設計・製造にコストがかかる。ソフトウェアだと後から実装できるため拡張性に優れるが計算速度がハードの実装に劣る、というトレードオフがある。


Hack コンピュータで実装する Hack のインタフェース
- Chip Name: ALU
- In:
- データ:x[16], y[16]
- 制御ビット:zx, nx, zy, ny, f, no
- 2 つの入力 x, y に対してどの演算(算術演算、論理演算)を行うかを決定するための 6 つビット
- Hack コンピュータで実装する ALU では、この 6 つのビットの組み合わせで 18 個の演算の内の 1 つを選択し、計算する。
- 制御ビットが 6 ビット分あるので、18 個よりも多くの演算を実装することはできるが、ここでは Hack コンピュータの実装に必要な 18 個の演算に絞っている。(原理的には 6 ビットあるので
2^6
- Out:
- データ:out[16]
- 制御ビット:zr, ng

Hack コンピュータで実装する Hack の仕様

演習

出力の制御ビットについて
- Out:
- out[16]
- zr: 出力 out が 0 ならフラグを立てる。そうでなければ 0。
- ng: 出力 out が負の値ならフラグを立てる。そうでなければ 0。
なぜこの 2 つの出力の制御ビットが必要かは、Hack のコンピュータアーキテクチャ全体を構築すると明らかになる。

Hack コンピュータの ALU はシンプルで、エレガントで、実装が簡単!
シンプルさが究極の洗練
Simplicity is the ultimate sophistication.

ALU の実装はわからないときは真理値表書くとこれまでの実装で出てきたパターンを適用できる。
入力の制御ビット f の適用はマルチプレクサ(セレクタ)の考え方でいける。f をセレクタに見立てて、f が 0 のときは x & y を通して、f が 1 のときは x + y を通す、というマルチプレクサの実装パターンで実装できる。
→ というかマルチプレクサ Mux16 使えば良いじゃん()
ALU の 2 つのテストが通った!時間測ってないけど 30 分くらいテストに時間かかった気がする。多分ヘルパーチップによるもの。ビルトインだけだとテスト早い。
-
ALU-basic.tst(出力の制御ビットを含めたテスト) -
ALU.tst(出力の制御ビットを含めたテスト)
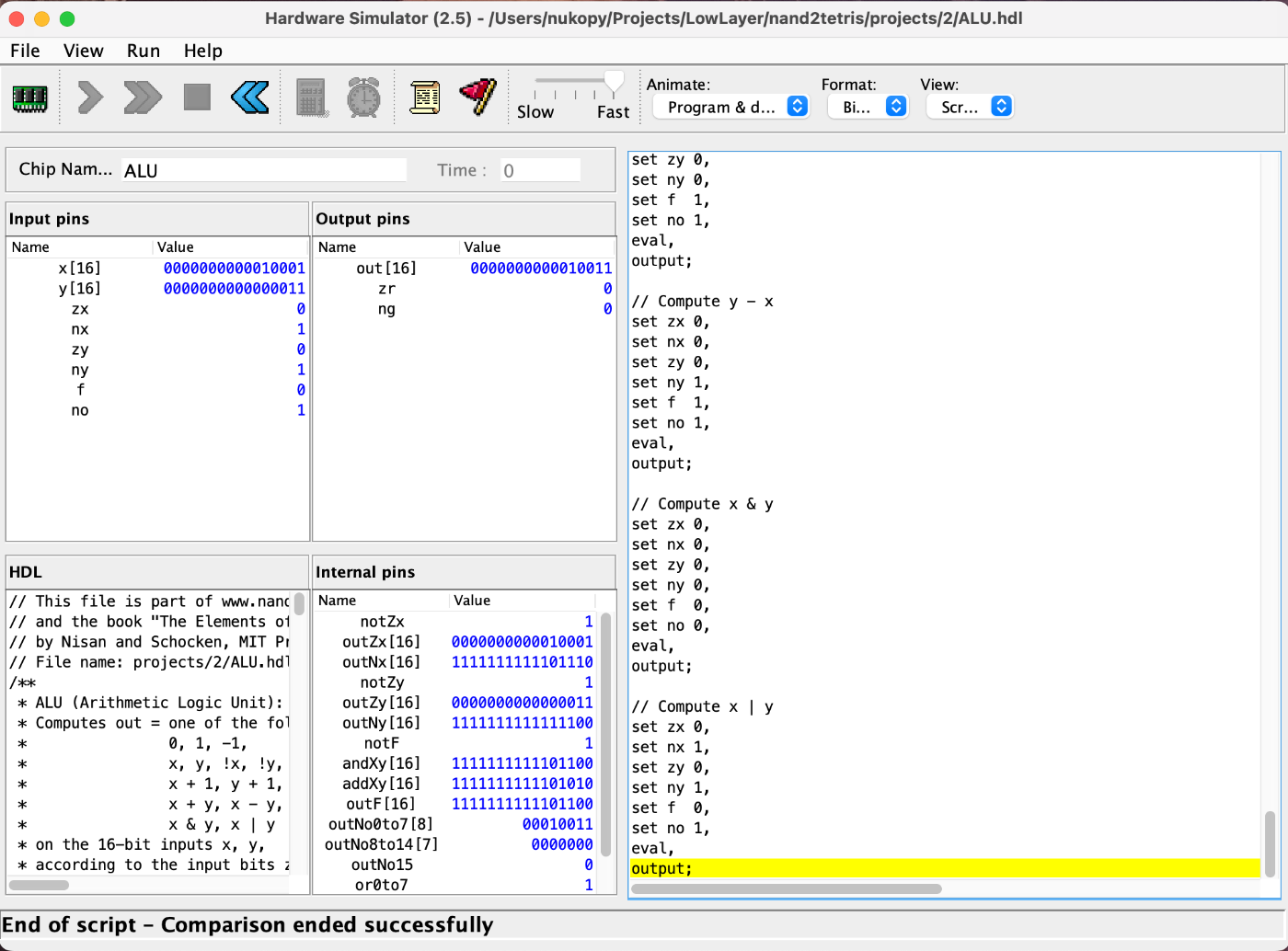
コーディングエージェント縛ってたけど、ヘルパーチップのテスト(*.tst, *.cmp)だけ書かせた。
✅️ Coursera の Project 2 に提出完了!合格!

✅️ 2025.06.05 THU Project 2:ブール算術 DONE
2025.06.06 THU Project 3:メモリー
概要
RAM を実装する。
フリップフロップゲート → 1 bit レジスタ → RAM チップとボトムアップに作っていく。
コンピュータのALUを構築した後、このモジュールでは、ランダムアクセスメモリー( RAM)としても知られるコンピュータのメインメモリーユニットを構築します。初歩的なフリップフロップ・ゲートから1ビット・レジスタ、nビット・レジスタ、RAMチップ・ファミリーへとボトムアップしていきます。組合せ論理に基づくコンピュータの処理チップとは異なり、コンピュータのメモリ・ロジックはクロック・ベースの逐次論理を必要とする。この理論的背景の概要から始め、メモリ・チップセットの構築に移ります。
主要概念
- 組合せ論理と逐次論理
- クロックとサイクル
- フリップフロップ
- レジスタ
- RAM ユニット
- カウンタ
いまのところ悪くないペース
時間の概念をこれまで作ってきた回路(論理ゲート)に導入したい。
- これまで作ってきた組み合わせ回路は入力と出力が同時に起こる。出力 out(t) は入力 in(t) に依存する関数 f(t)。
- 組み合わせ回路:
out(t) = f(in(t))
- 組み合わせ回路:
- 順序回路は出力が 1 単位時間前の入力に依存する。出力 out(t) は入力 in(t-1) に依存する関数 f(t)。
- 順序回路:
out(t) = f(in(t-1))
- 順序回路:

順序回路では 1 単位時間前の入力に依存するので、入力を次の出力に使用できる。
これにより、+1 単位時間後に前の時間の出力を保持できるようになるる。つまり回路が時間依存の状態を持てるようになる。

コンピュータが時間と記憶をどのように扱うようになるのか、特に逐次論理に焦点を当てている。
まず、時間要素を無視していた組み合わせ論理 combinatorial logic とは異なり、実際にはハードウェアの再利用や過去の情報の記憶のために時間が必要である。
コンピュータで時間を扱うために、物理的な連続時間をクロックによって離散的な整数時間単位に分割する。これにより遅延の問題を無視し、各時間単位で状態が変化することを論理的に捉えられるようにしている。
現在の出力が現在の入力のみに依存する組み合わせ論理に対し、逐次論理 sequential logic では過去の入力や状態に基づいて現在の出力が決定されるという違いがある。
これにより、コンピュータに時間の概念を導入することができる。
なぜコンピュータに時間の概念が必要か?
- データを保持したい(演算結果を保持したい)
2025.06.08 SUN Project 3:メモリー(続き)
一日お休みした(というか Claude Code ひたすら触ってた)ので再開
連続的な時間をサイクルという一定の長さの区間で区切り、時間を離散的に扱えるようにする。
サイクルの実装には 2 つのフェーズを連続的に交互に動く発振器を使うのが一般的。
2 つのフェーズは 0/1, low / high, tick / tock のようにラベル付けされる。tick の開始から次の tock の終了までの経過時間をサイクルと呼ぶ。1 サイクルが離散時間の単位である。
現在のクロック位相(tick or tock)はバイナリ信号(電圧の高低?)で表される。
ハードウェアの回路を使用し、同じクロック信号がシステム内の全てのメモリチップに同時に送信される。
全てのチップに接続されたクロックはマスタークロックと呼ばれる。
マスタークロックにつながる全てのチップにおいて、クロックの入力は下位レベル(≒構成要素)の DFF 回路に流される。
クロックサイクル (t) の終わりにのみ、チップが新しい状態に移行し、次のサイクル (t+1)でその新しい状態がチップから出力される。
ハードウェア:クロック用発振器、水晶振動子
クロック信号とは?
規則正しく刻まれる周期的な電気信号です。これによって、複数の電子回路間で作動のタイミングを合わせることができます。
- (2023/02) MEMS発振器と振動子の比較
- 振動子は、圧電現象をもつセラミックや水晶の振動片を利用した受動部品です。振動させるためには、発振回路(IC)を用いる必要があります。
- 発振器は、振動子と発振回路をパッケージングし、ワンチップとなったものを指します。


クロック用発振器
クロック用発振器は、水晶デバイスメーカーが「発振回路」と「水晶振動子」をパッケージに詰め、最良の発振状態をお客様に提供するものです。
電圧を加えるだけで、必要な周波数のクロック信号が得られます。

雰囲気だけ
- 033 百円マイコンを使った水晶発振器と分周回路
今回は、CPUクロックに使う水晶発振子の周波数精度を確認するため
テスト的に、百円マイコンで、水晶を発振させ 1/10に分周して
ユニバーサルカウンタで周波数を読み取る事が、今回の目的です
何もわからんが、MIL 記法部分だけかろうじて認識できる

水晶振動子って実物こんな感じなのか
秋月とかで買えるのかな

クロックの立ち上がりエッジを "イベント" としている

位相とは?



話は逸れたが実装に移る。
理解がまだ浅いので Bit.tst にコメント書きながら Bit.cmp でゲートの値の変化を眺める。
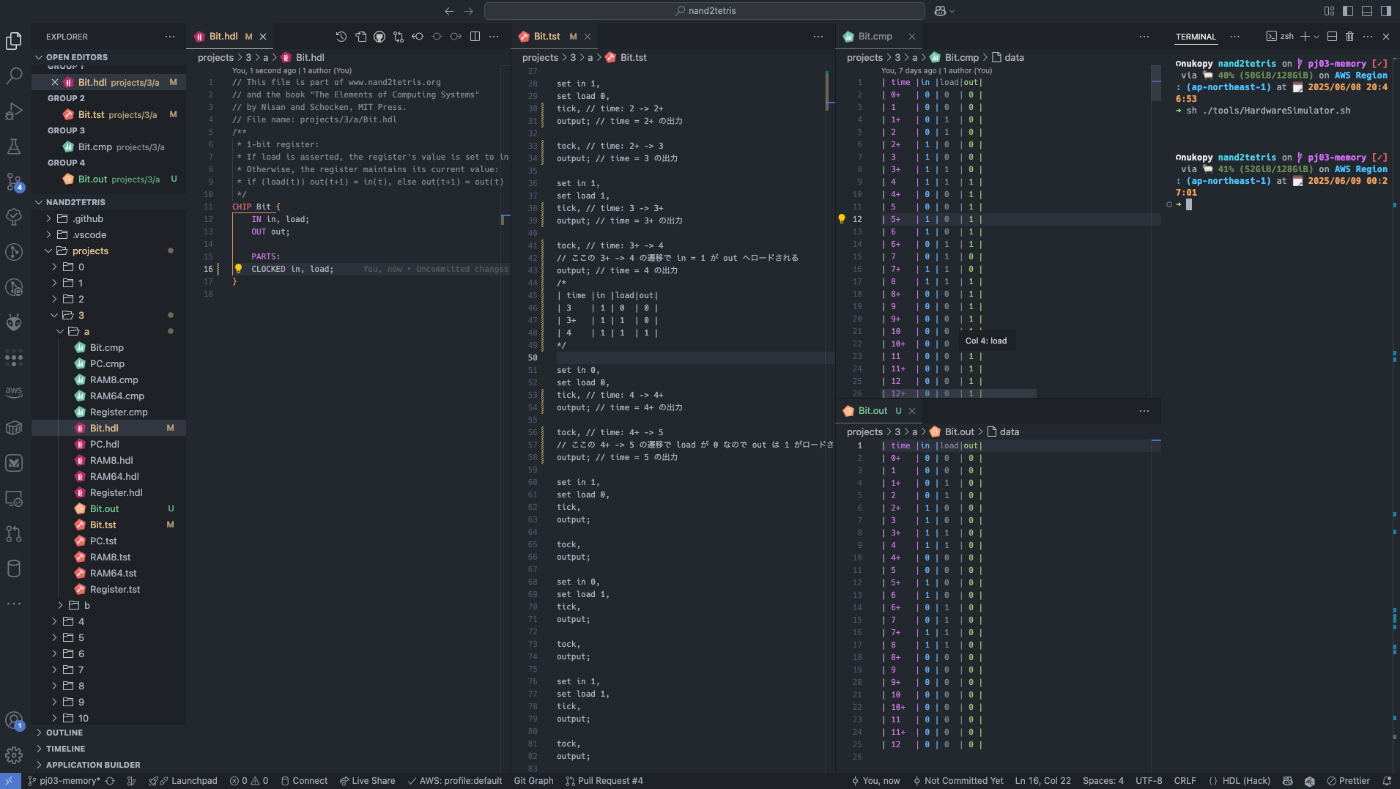
RAM8(レジスタを 8 個並べた RAM)の実装できた!
あとはこれを組み合わせて RAM16K まで走る。
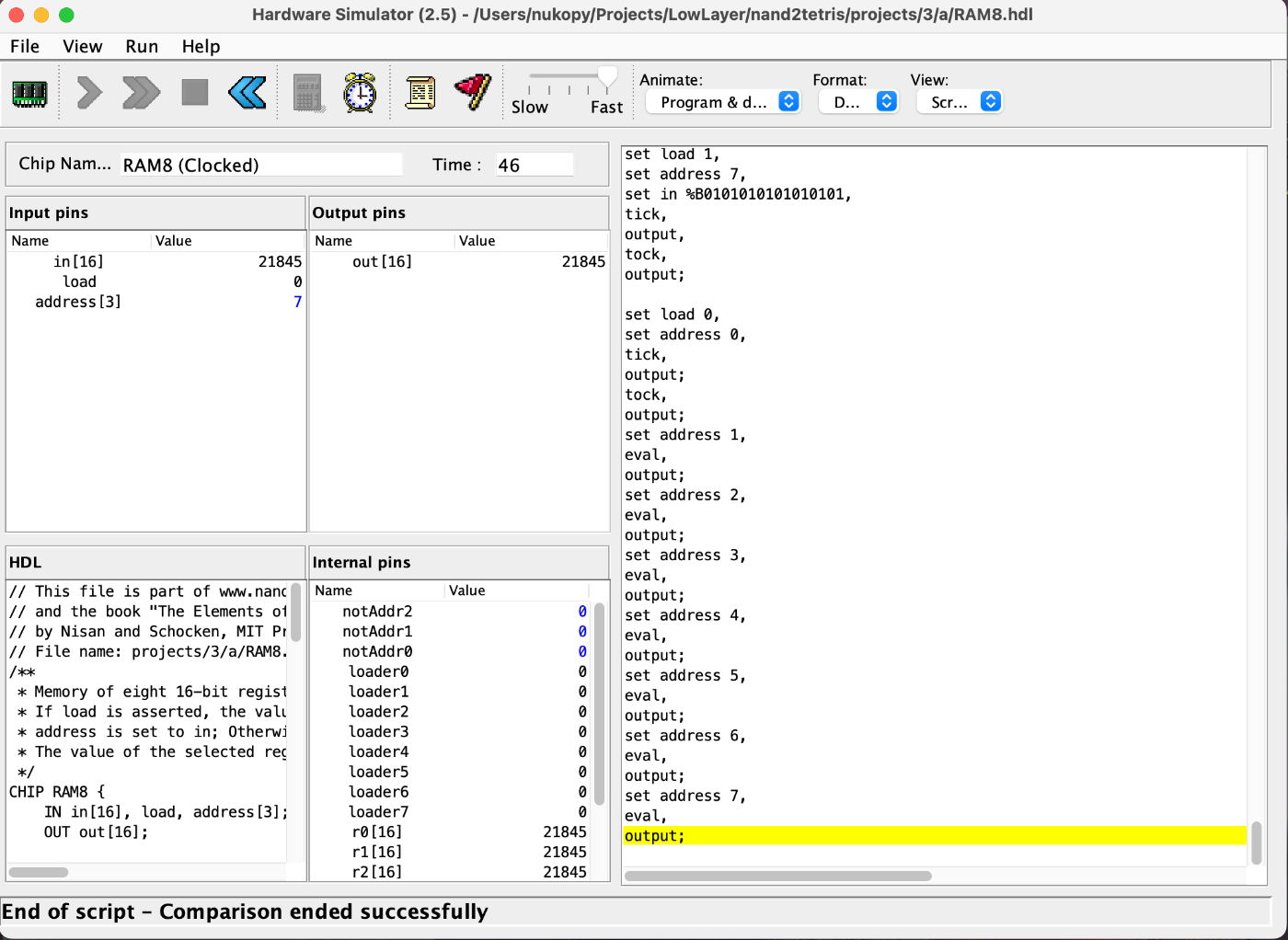
RAM64 DONE
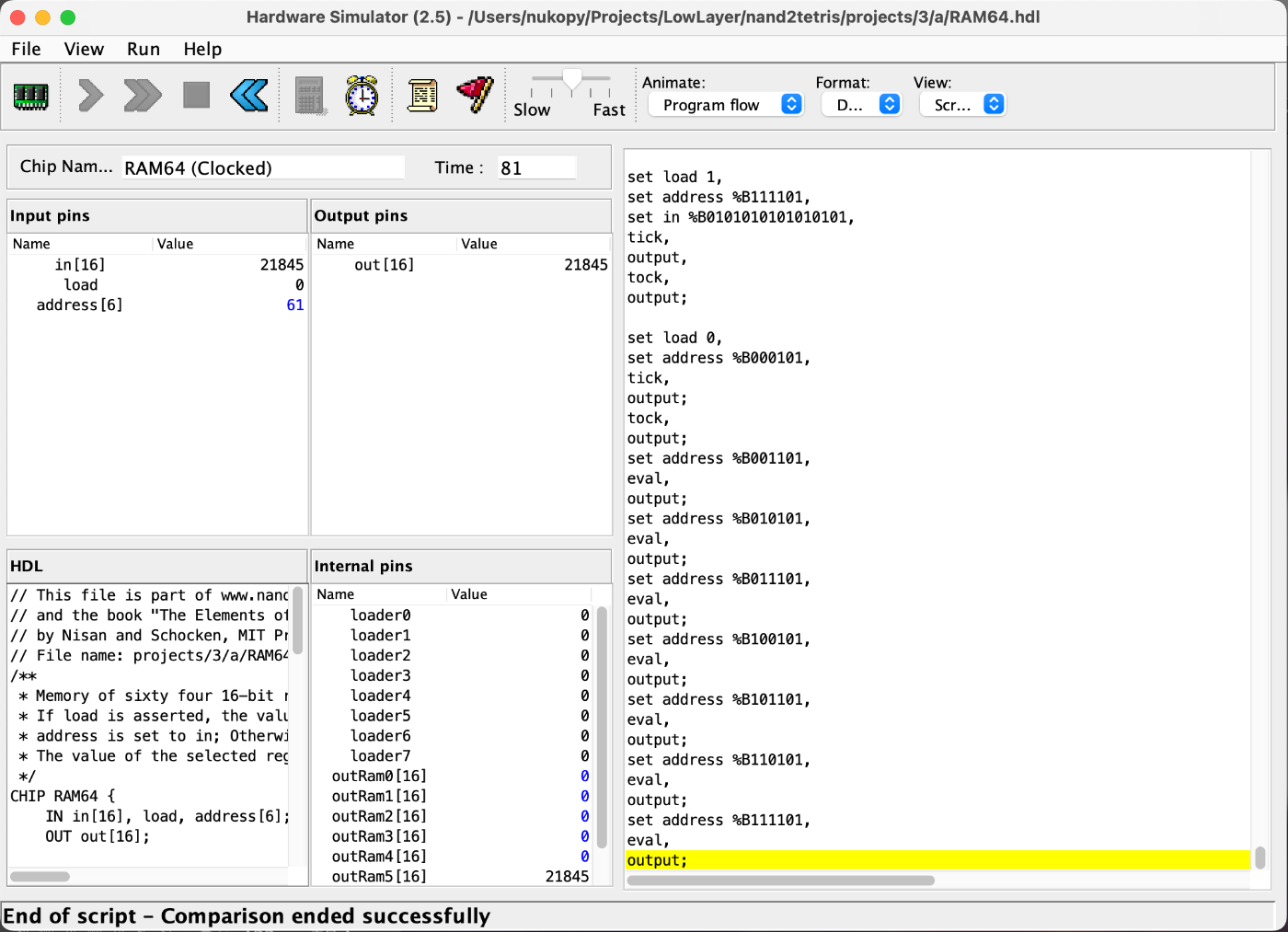
RAM512、RAM4K、RAM16K DONE!!

RAM8 から階層構造で RAM16K までできるのおもしろい
あとアドレスの解釈の仕方がおもしろくて、チップの内部で入力のアドレスをどう解釈しようがその番号に対して同じ出力を保証できれば良いって仕組みがおもしろい。
例えば、x5x4x3x2x1x0 の 6 bit のアドレスがあって、3 bit ずつ「RAM の内部でどの RAM チップを選択するか」、「選択した RAM の中でどのアドレスのレジスタを選択するか」に使うんだけど、
お行儀良く x2x1x0、x5x4x3 と上位下位 3 bit ずつに分けて使っても良いし、x5x2x0、x4x3x1 みたいなぐちゃぐちゃに使っても良い。
結局特定のアドレスに対してどのメモリレジスタへ読み書きするかが一意に定まれば良いのでアドレスの解釈何でも良い(可読性が悪いので結局お行儀良く使うけど)。
プログラムカウンタの実装 DONE!

✅️ Coursera の Project 3 に提出完了!合格!
(本当にテストされているのか試した。いくつかの HDL ファイルを抜いて zip 化したら本当に採点で減点された)
✅️ 2025.06.08 SUN Project 3:メモリー DONE
最初に立てたスケジュールよりは 5 日間くらい巻けている。なんだかんだでペースが良い時と悪い時があるから、1 つのモジュールに 3 日取っているのはちょうど良い。
ソフトウェアの方はモジュール 8:アセンブラが終わってからスケジュール引く。

順序回路のクロックの概念に苦戦したけど、ハードウェアシミュレータを動かしながら出力を見ると理解できてきた。
コンピュータシステムで状態を保持するには時間の概念が必要。
時刻 t-1 のときの状態を t になったときでも保持させ続けたい。
それを実現するための仕組みが(クロック)サイクル。連続的な時間をサイクルに分割して離散的に扱えるようにする。
2025.06.09 MON Project 4:機械語
今日もやっていき
概要
新しいコンピューター・システムを構築する上で決定的に重要なのは、低レベルの機械語(命令セット)を設計することである。結局のところ、これはコンピューターそのものが実際に構築される前に行うことができる。
例えば、まだ出来上がっていないコンピュータをエミュレートするJavaプログラムを書き、それを使って新しい機械語で書かれたプログラムの実行をエミュレートすることができる。このような実験によって、新しいコンピュータの骨太の「ルック&フィール」をよく理解することができ、ハードウェアと言語の設計の両方を変更・改善する決定につながる可能性がある。
同じようなアプローチで、このモジュールではHackコンピュータと機械言語が作られたと仮定し、Hack機械言語を使っていくつかの低レベルプログラムを書きます。その後、付属のCPUエミュレータ(コンピュータ・プログラム)を使ってプログラムをテストし、実行します。この体験は、低レベル・プログラミングを体験するだけでなく、ハック・コンピュータ・プラットフォームの概要を実際に体験することができます。
主要概念
- オペコード
- ニーモニック
- バイナリ機械語
- 記号機械語
- アセンブリ
- 低レベル算術
- 論理
- アドレッシング
- 分岐
- I/O コマンド
- CPU エミュレータ
- 低レベルプログラミング
- どの操作を行えるようにするか?
- 算術演算
- 論理演算
- フロー制御
- コンピュータ上で動くデータ型をどのように決めるか?
メモリー階層

急にプログラムの書き方の基本が出てきた

ひとまず本の 4 章 機械語を読み終わった。
これから Mult.asm と Fill.asm の実装に入る。
アセンブリ言語のプログラムの実行は nand2tetris 公式の CPU エミュレータを使用する:

Mult.asm の実装
疑似コード

Mult.asm のテスト通った!

プログラム実行時、ROM にプログラムのラベル宣言が読み込まれないのが良く分からない。
ラベル宣言は、
(symbol)という形式のテキスト行で表される。
アセンブラはsymbolをプログラムの次の命令のアドレスにバインドすることで、ラベル宣言を処理する。
アセンブラがラベル宣言を処理するときに取る動作は以上であり、バイナリコードは何も生成されない。
ラベル宣言が疑似命令とと呼ばれる理由はこのためだ。
ラベル宣言はシンボルを操作するために存在し、コードは何も生成しない。
(コンピュータシステムの理論と実装 第 2 版 p.96 より引用)
つまり、ROM にラベル宣言は読み込まれない。実際に上記の Mult.asm の CPU エミュレータでの実行結果を見ても、たしかにラベル宣言は ROM 上に存在しない。
あーー完全理解。ありがとう 4o。
-
LOOPというシンボルが現在の ROM のアドレスにバインドされる- ラベル宣言
(LOOP)が書かれている行。上の実装例だと、0-origin の 6 行目)にバインドされ、LOOPというシンボルがシンボルテーブルに載る。ここではバイナリコードは吐かれない。 
- ラベル宣言
- アセンブリが A 命令
@LOOPのシンボルをシンボルテーブルを使って解決し、@6に変換(.asm)→バイナリコードに変換(.hack)
(以下 4o の出力)
わからないこと
-
(LOOP)のようなラベル宣言は、なぜ ROM 上に存在しないのか? -
@LOOPのようなジャンプ先は、どうやって数値アドレスに変換されるのか? - 「ラベルは ROM アドレスにバインドされる」とあるが、誰が・いつ・どのようにそのバインドを管理しているのか?
実際の仕組みと処理の流れ
Hack アセンブリ処理の全体像(2パス方式)
Hack アセンブリは、アセンブラ(Assembler)というプログラムが .asm ファイルを .hack に変換することで実行可能なバイナリを生成します。
🥇 パス1:ラベルの登録(ラベル宣言の処理)
- アセンブラは、アセンブリファイルを上から順に1行ずつ読んでいく。
-
(LOOP)のようなラベル宣言を見つけたとき、そのラベルを「現在の ROM 命令数(=現在の命令アドレス)」にバインド。 -
@XxxやD=D+Aなど実際に ROM に書き込まれる命令だけをカウント。 - この処理の結果、シンボルテーブル(symbol table)が次のように出来上がる:
LOOP → 2
END → 10
🥈 パス2:命令の変換(シンボルの解決と機械語生成)
- アセンブラは再びファイルの先頭から読む。
-
@LOOPのようにシンボルを含む A 命令があった場合、シンボルテーブルからアドレスを引いて@2に置き換える。 - すべての命令を16ビットのバイナリに変換して
.hackファイルに出力。
✅ 結果として…
-
(LOOP)自体は機械語に変換されない(ROM に書かれない) -
@LOOPは@2となってバイナリ命令0000000000000010になる
用語の整理
| 用語 | 意味 |
|---|---|
ラベル宣言 (LOOP)
|
プログラム内の特定の行に名前を付ける疑似命令。ROM に入らない。 |
A 命令 @Xxx
|
レジスタ A に定数やアドレスを格納する命令。シンボルならアセンブラがアドレスに変換する。 |
| ROM アドレス | 命令が格納される場所。命令ごとに連番。 |
| シンボルテーブル | シンボル(変数名やラベル名)とその値(アドレスなど)を保持する辞書。 |
| 疑似命令 | バイナリを生成しないが、アセンブラの処理に使われる命令(ラベル宣言など)。 |
今日はここまで。
明日 Fill.asm を終わらせて 4 章 機械語を終わらせる。
2025.06.10 TUE Project 4:機械語(続き)
Fill.asm の実装やる。
疑似コード書いて実装。
Fill.asm のテスト通った!
✅️ Coursera の Project 4 に提出完了!合格!

Fill.asm はこんな感じ。
キーボード入力があると画面(メモリマップ)が黒く塗りつぶされ(1111....)、ないと白く塗りつぶされる(0000....)。
- キーボード入力あり:黒

- キーボード入力なし:白
動画は以下を参照:
✅️ 2025.06.10 TUE Project 4:機械語 DONE
06.10 ~ 06.11 体調死んでた。再開。
2025.06.12 TUE Project 5:コンピュータアーキテクチャ
講義資料を眺めるだけでも楽しい
概要
この4つのモジュールを振り返ってみよう。
- 初歩的な論理ゲートをいくつか作り(モジュール1)、
- それを使ってALU(モジュール2)、
- RAM(モジュール3)を作った。
- そして、コンピュータ全体が実際に利用可能であると仮定して、低レベル・プログラミング(モジュール4)で遊びました。
このモジュールでは、これらすべてのビルディングブロックを組み立てて、Hackと呼ばれる汎用16ビットコンピュータを作ります。Hackの中央処理ユニット(CPU)を作ることから始め、CPUとRAMを統合し、Hackの機械語で書かれたプログラムを実行できる本格的なコンピュータシステムを作ります。
主要概念
- フォン・ノイマンアーキテクチャ、ハーバード・アーキテクチャ
- ストアドプログラムの概念
- フェッチ-エキュートサイクル
- データバス
- 命令バス
- CPU
- コンピュータ設計
このプロジェクトでやること
機械語を実現するコンピュータを構築する

CPU <-> Memory 間のデータのやり取り
3 つのデータの通り道=バスを使用する:
- Data Bus データバス
- Address Bus アドレスバス
- Controll Bus 制御バス
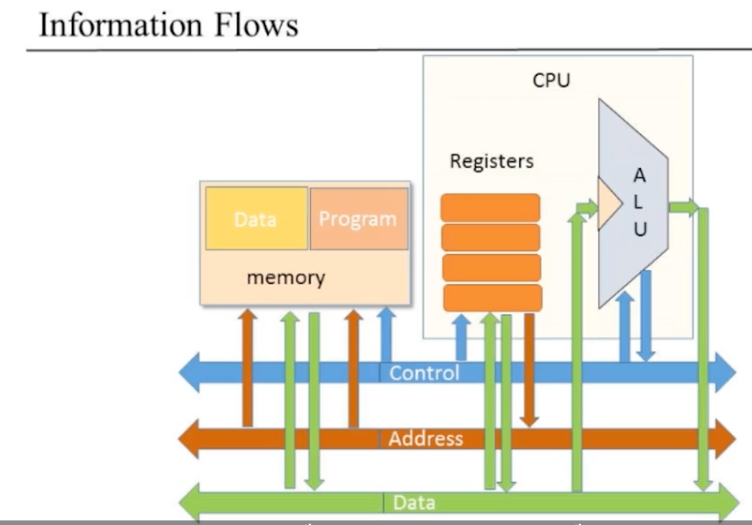
Memory

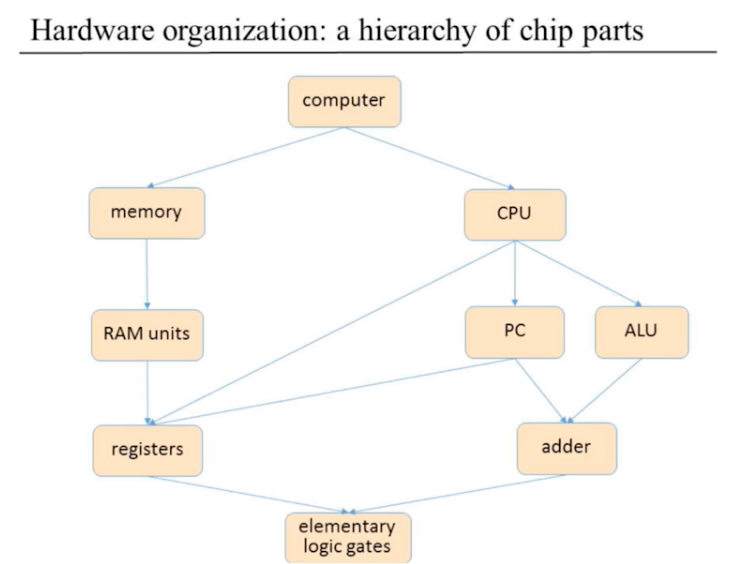
これまで作ってきた & これから作るハードウェアの階層構造
Project 5 では、CPU、memory を作り、これらを組み合わせて computer (= Hack computer) を作る。
全てのチップは初歩的な論理ゲートから構成されていることを改めて認識する。
Hack Computer の I/F

Hack CPU の実装
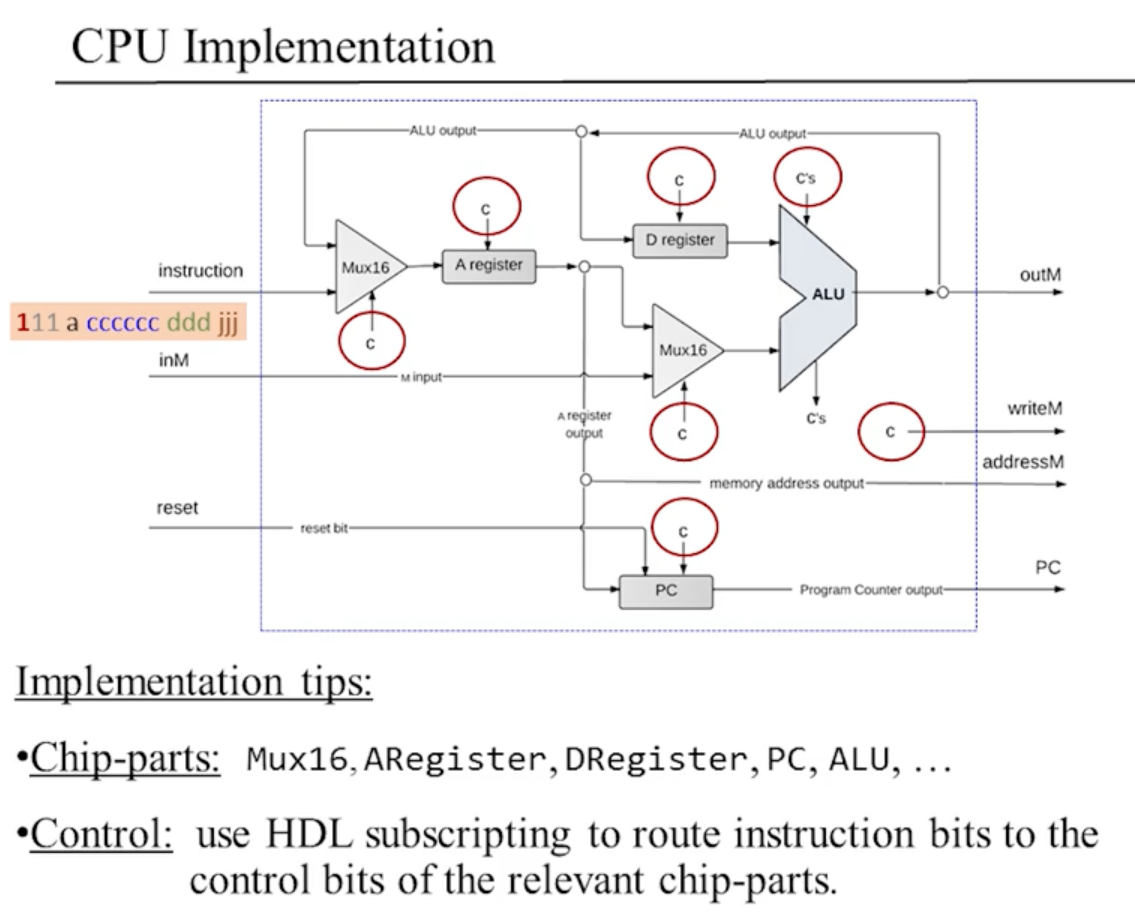
RAM (Data Memory) の実装
Screen、Keyboard のメモリマップは Project 4 で使ったやつ。

ROM (命令メモリ) の実装
RAM のシンプル版。
ビルトインチップとして提供される。
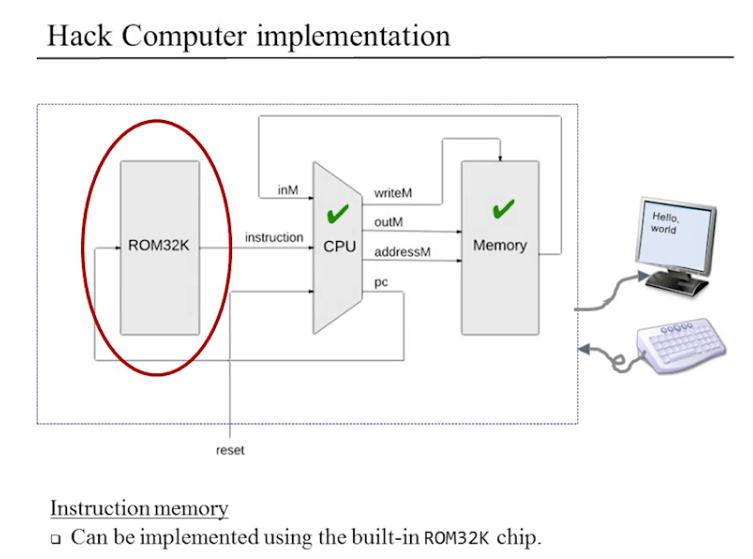
Memory.hdl 実装中。
バグあり。起きたら続き。
2025.06.13 TUE Project 5:コンピュータアーキテクチャ(続き)
Memory.hdl の実装
バグの原因はアドレス範囲の判定の実装がぐちゃぐちゃだったこと。
整理してから実装したらシンプルだった。
Memory.hdl の実装 DONE!

CPU.hdl の実装


計算機の歴史
かの有名なパンチカードシステムは 1884 年。
19世紀の終わりごろには小形電気モータが登場し,電気を動力とする計算機を開発できるようになった.米国では統計処理を効率化するため,ハーマン・ホレリスはパンチカードを用いた統計処理機械を1884年に開発した.これはパンチカードシステム(PCS)
フォン・ノイマンによってプログラム内蔵方式が提唱されたのが 1945 年。
1945年06月
【世界】J.v.Neumann:EDVACに関する報告書初稿(プログラム内蔵方式の概念を示す)
電子コンピュータの誕生
- 1946 年:NIAC(世界発の電子コンピュータ)
問題ごとに配線しなおす方式
フォン・ノイマン型コンピュータの提案
(プログラム内蔵型)- 1949 年:EDSAC
(世界発のフォン・ノイマン型コンピュータ)
ソフトウェアの原点

EDSAC の構成

うおーー CPU のテスト通った!
1 章からの実装でここが一番時間かかった気がする
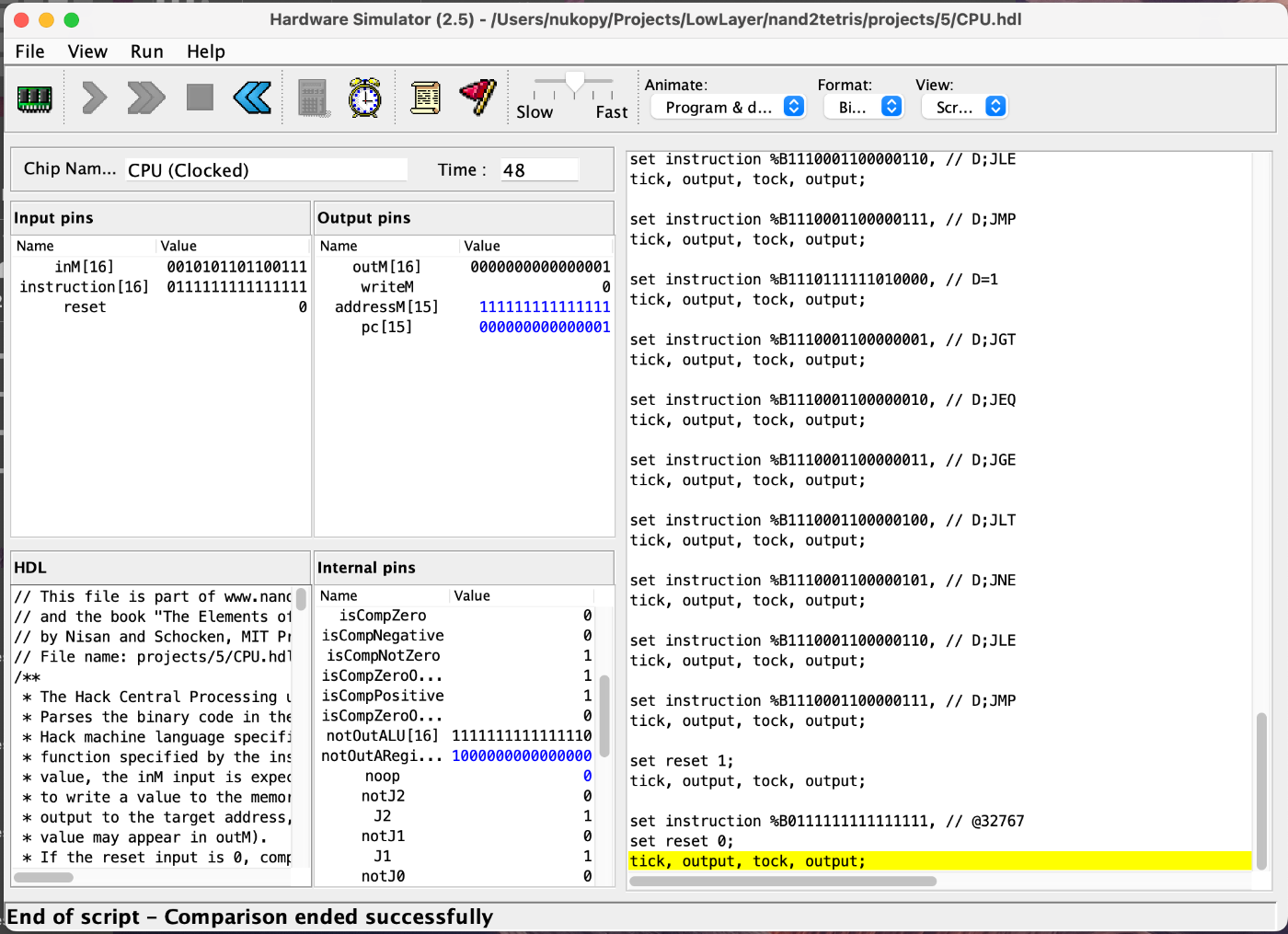
ラスト残すは Hack コンピュータ(Computer.hdl)のみ
Hack コンピュータ(Computer.hdl)の 3 つのテスト全て通った
ComputerAdd.tst

ComputerMax.tst

ComputerRect.tst

✅️ Coursera の Project 5 に提出完了!合格!
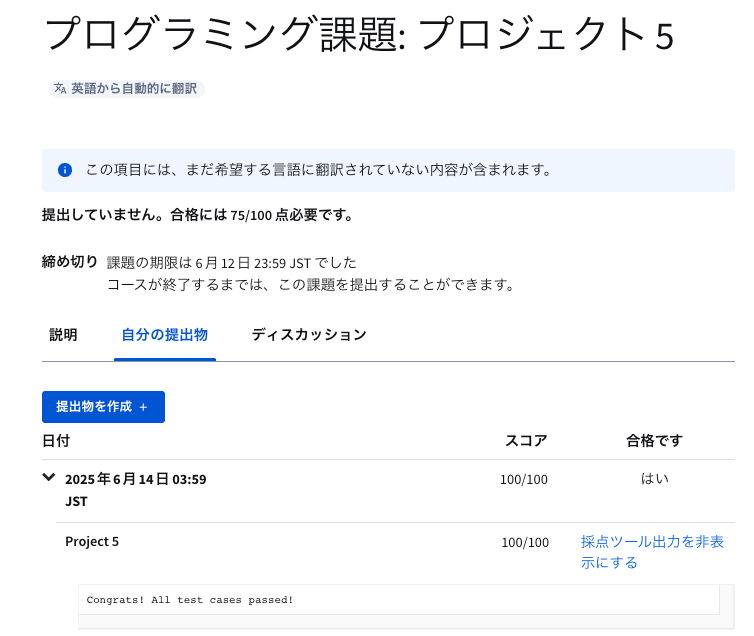
✅️ 2025.06.13 FRI Project 5:コンピュータアーキテクチャ DONE
(正確には 2025.06.14 SAT 午前 4:40)
Q. ノイマン型コンピュータ、フォン・ノイマンアーキテクチャとはなにか?
- そもそもどういう概念なのか?
- この中心となる概念はなにか?
- なぜ当時このアーキテクチャが革新的だったか。
Answer by o3
ざっくりまとめ
- フォン・ノイマン型コンピュータ=「プログラムもデータも同じメモリに置き、CPU が逐次的にそれを読み書きしながら処理する」方式。
- 中心コンセプトは stored-program(プログラム内蔵方式)。
- なにが革新的だったか:ハードをいじらずにメモリを書き換えるだけで別の処理ができる“汎用・再プログラム可能”な計算機を実現した点。
1. そもそも何が「ノイマン型」なのか
1945 年、ジョン・フォン・ノイマンが EDVAC 計画のメモ(通称 First Draft Report on EDVAC)で提唱したアーキテクチャを指す。典型的には次の5ブロックを一本のバスでつなぐ形で説明される。
| ブロック | 役割 |
|---|---|
| メモリ | データ と プログラム命令を格納 |
| 演算装置(ALU) | 四則演算や論理演算などを実行 |
| 制御装置(CU) | メモリから命令を取り出し、解読し、各装置へ制御信号を出す |
| 入力装置 | 外界→メモリ(例:カードリーダ、キーボード) |
| 出力装置 | メモリ→外界(例:プリンタ、ディスプレイ) |
ここで大事なのが「メモリの中身は純粋なビット列であり、CPU は 命令 も データ も区別せず読み書きできる」という点。これこそが stored-program idea で、今日の CPU がバイナリを RAM にロードして実行するやり方の原型だ。
2. 当時のコンピュータとの違い
| 1940 年代前半 (ENIAC ほか) | 1945 以降 (EDVAC, EDSAC…) |
|---|---|
| 配線やスイッチの差し替え=プログラミング | メモリ内容を書き換え=プログラミング |
| 演算定数/命令はプラグボードやダイヤルで物理的に指定 | 命令列も数値として RAM に格納 |
| 専用機的(砲弾弾道、統計など目的別) | 汎用機的(タスクに応じてソフトを変えるだけ) |
要するに 「プログラム=ハードウェア配線」 だった世界から、「プログラム=メモリ上のデータ」 に移行したのが革命ポイント。
3. 何が革新的だったか
-
再利用性・汎用性
新しい問題を解かせたいときはコードを書き換えるだけ。ハード改造が不要になり開発サイクルが激短になった。 -
自己改変コードが可能
命令をデータとして扱える=実行中に自分の命令列を書き換えるメタプログラミングも理論上 OK(実際の利用は限定的だが当時は衝撃)。 -
周辺機器を問わず同じ論理
I/O デバイスが変わっても、CPU-メモリ-I/O の三層モデルで抽象化できる。今日の OS がドライバで抽象化する発想の源流。 -
資源の共有
演算装置とメモリをタイムシェアできるため、部品点数が抑えられコストダウン。 -
理論と実装のブレークスルー
チューリングマシン理論(プログラムもデータもテープ上の記号)を電子計算機のレベルで具体化。理論が実用マシンに一気に降りてきた瞬間だった。
4. 典型例と影響
- EDVAC(設計:1945–)
- EDSAC(ケンブリッジ大, 1949)
-
IAS machine(プリンストン, 1951)
これらのクローンが世界中に波及し、“ノイマン型”がデファクトに。さらに - IBM 701 → メインフレーム
- DEC PDP-8 → ミニコン
- Intel 4004 → マイクロプロセッサ
とスケールダウンしつつも同じ枠組みで進化した。
5. その後見えてきた制約(おまけ)
-
メモリ帯域がネック
命令もデータも同じバスを奪い合うためスループットが頭打ち(いわゆる von Neumann bottleneck)。 - ハーバード型(命令メモリとデータメモリを分離)やキャッシュ階層の導入は、このボトルネック緩和策として登場。
まとめ一言
「プログラムはハードではなくデータである」
たったこれだけのアイデアが、計算機を“作業内容を書き換えられる万能ツール”へと進化させ、現代のソフトウェア産業の土台になった。
Answer by o3
フォン・ノイマン型コンピュータ(von Neumann architecture)の丁寧な定義
1. 歴史的背景と命名
-
出典
1945 年6月、プリンストン高等研究所に在籍していた数学者 John von Neumann がまとめた覚書
First Draft of a Report on the EDVAC(EDVAC 計画草案)が原典。 - 「ノイマン型」 は厳密には本人単独の発明ではなく、EDVAC 共同開発陣(Eckert, Mauchly ほか)の合意事項を von Neumann が数学者らしい整理で文章化したものが広く読まれたため、その名が冠された。
2. 核心概念 ― stored-program (= プログラム内蔵方式)
命令列(プログラム)も計算対象(データ)も、同一の読み書き可能メモリに格納し、
CPU がそこから逐次的に取り出して解釈・実行する
という方式そのものが「ノイマン型」の必須条件である。
これにより
- メモリ上の内容を書き換えるだけで異なる仕事をさせられる(“汎用性”)
- 命令をデータとして扱えるので、理論的には自己書換えプログラムが可能
- ハードウェアの再配線なしに再プログラムできる
3. 構成要素(5ブロックモデル)
以下の 5つの論理ブロック が単一のバス(または同等の通信路)で結ばれている構造を指すのが一般的な形式的定義。
| ブロック | 役割の定義 |
|---|---|
| 主記憶装置(Memory) | 連続アドレス空間を持ち、 命令語・データ語を区別せず読み書き可能 |
| 演算装置(Arithmetic Logic Unit, ALU) | 四則演算・論理演算をビット列に対して実行 |
| 制御装置(Control Unit, CU) | ✔ 命令カウンタ(PC)で次のアドレス指定 ✔ 命令をデコードし ALU や I/O に制御信号を出す |
| 入力装置(Input) | 外部媒体 → 主記憶へのデータ流入経路 |
| 出力装置(Output) | 主記憶 → 外部媒体へのデータ流出経路 |
補足
- ALU と CU をあわせて 中央処理装置 (CPU) と総称する。
- 先行機 ENIAC では「プログラム」はプラグボード配線だったため、この主記憶ブロックの中には存在し得なかった。
4. 動作モデル(フェッチ–デコード–実行サイクル)
-
Fetch
制御装置がプログラムカウンタ (PC) で示す主記憶番地から命令語を取得。 -
Decode
命令語のビット列を解析し、演算種別とオペランド番地を決定。 -
Execute
- ALU に演算を依頼
- I/O へデータ転送
- PC を更新(分岐命令なら改変)
-
次サイクルへ — 停止命令や例外がない限り永久に繰り返す。
逐次処理 (sequential execution) が本モデルの前提であり、並列演算は構造上オプションにすぎない(後年のスーパースカラーやパイプラインは、逐次的な抽象モデルを高速化する実装技法であって定義変更ではない)。
5. 形式的要件を箇条書きで
-
単一・読み書き可能なランダムアクセス記憶を命令とデータが共有
-
単一のアドレス空間(命令番地とデータ番地が同じ数直線上に乗る)
-
逐次的フェッチ–デコード–実行制御を行う CPU
-
命令語は固定もしくは可変長のビット列で、
-
opcode(操作コード) -
operand(直値またはメモリアドレス)
を含むフォーマットを持つ
-
-
入出力はメモリ転送で抽象化され、装置固有動作は CPU から見て「命令あるいは割込み」で表現される
これら5要件を満たす限り、実装が真空管・トランジスタ・LSI・FPGA であっても「ノイマン型」と呼べる。
6. 他アーキテクチャとの対比で見る境界線
| 分類 | メモリ構成 | 代表例 | ノイマン型との違い |
|---|---|---|---|
| ハーバード型 (Harvard) | 命令メモリとデータメモリを物理分離 | AVR マイコン,初期 PDP-11 | 共有メモリ≠単一、したがって定義上ノイマン「でない」 |
| マイクロプログラム制御 | 制御語は別 ROM, ただし命令は RAM | IBM System/360 | 外面的にはノイマン型 CPU をさらにマイクロコードで実装した階層 |
| データフロー / 宣言型マシン | 実行トリガをデータ依存で決定 | MIT TAG, Monsoon | 「逐次フェッチ–デコード」前提を採らない |
| 再構成配線型(ENIAC 等) | 配線が“命令” | ENIAC, Zuse Z3 | メモリ内プログラムを持たず “pre-stored” でない |
7. 「ノイマン型」定義の意義
- 学術的には チューリング機械の計算モデルを物理実装に落とす最低条件を言語化したもの
- 産業的には ソフトウェアという独立した知的資産を成立させた前提
- 教育的には 計算機構成論・OS 論の最初の抽象階層(CPU と主記憶)を規定
まとめ
フォン・ノイマン型コンピュータとは
「プログラムとデータを同一の読み書き可能メモリに置き、そこから逐次的に命令を取り出して解釈・実行する中央処理装置を核とする5ブロック構成の計算機体系」
— この要件を満たす限り、その実装技法や規模にかかわらず “ノイマン型” と呼ばれる。
Wikipedia: von Neumann architecture

ノイマン型コンピュータの定義
メインメモリ (読み書き可能な一つのアドレス空間) に 命令(プログラム)とデータが同じ形式で格納され, プロセッサがそのメモリから命令を 順番に取り出し (フェッチ) → 解読 (デコード) → 実行 する仕組みをもつコンピュータのモデル。
中心となる概念
ストアドプログラム方式 (stored-program concept)
プログラムを「配線」ではなく「データ」としてメモリに置き、必要に応じて書き換えたり入れ替えたりできる――この一点がノイマン型の肝。
なぜ革新的だったか
-
再プログラムが瞬時に
ハードを組み替える手間が消え、メモリ内容を書き換えるだけで新しい計算が可能になった。 -
汎用性の飛躍
目的別の“計算装置”から、タスクごとにソフトを載せ替える“万能機”へ。ソフトウェア産業の土台をつくった。 -
理論と実装の接合
チューリング機械の「命令もデータも同じテープ上」というアイデアを、電子計算機で現実化した最初の設計だった。
Q. あくまでもモデルだよね
うん、あれは「実装」じゃなくて抽象的な枠組み=モデル。
日本語で言うなら、状況に合わせて次の表現がしっくり来るよ。
| 英語 | よく使う日本語訳 | ニュアンス |
|---|---|---|
| model | モデル | そのままカタカナで OK。IT・数学分野では普通に使う。 |
| computational model | 計算モデル | 「計算の抽象的な仕組み」を強調したいとき。 |
| architecture | アーキテクチャ/構成/方式 | ハード・ソフトの“仕組み”という意味を出したいとき。 |
| conceptual framework | 概念枠組み/概念モデル | 理論寄りの説明で使う硬めの訳語。 |
フォン・ノイマンの場合は
「フォン・ノイマン型計算モデル」
「フォン・ノイマン・アーキテクチャ」
のどちらでも通じる。日常の技術文書だとカタカナそのまま「モデル」「アーキテクチャ」を使うことが多い。
Q. 計算機のモデルという理解であっている?この場合「計算機」とはなにかという定義が必要だけど。どのレイヤーの概念なのかがまだ理解できていない。少なくとも物理的な設計ではないし、具体的な命令セットアーキテクチャの話もしていない。論理的な設計のレイヤーになるのかな。具体的にレイヤーを図示しながら整理・丁寧に説明して。