データベースの基本
基礎用語
-
データベース (Database)
- 関連するデータの集合。データは効率的にアクセスし、管理するために構造化される。
- ref: データベース、DBMS とは何か?
-
データベースファイル
- データの実体
- コンピュータ上で管理されるデータベースにおいては、そのデータベースのデータが書き込まれているファイル、データの実体のこと。
-
DBMS(Database Management System)
- データベースファイルに対して読み書きを行うソフトウェア。MySQL、PostgreSQL、MongoDB、TiDB など。
-
(IT の文脈での)データベース (Database)
- データベースファイル + DBMS で構成されるデータ管理を行うためのシステム。データベースファイルは DBMS の仕様で決まるため、使用する上では分けて考えることは少ない。
(以下、IT の文脈での「データベース」を使用する)
-
スキーマ (Schema)
- データベースで管理されるデータの構造の定義。
-
クエリ (Query)
- 特定の情報を取得するためにデータベースに送信する命令。
基礎用語 - RDBMS
-
RDBMS (Relational Database Management System)
- DBMS の内、データをテーブルとその関係として構造化し、それを管理するソフトウェア。MySQL、PostgreSQL、Oracle Database、MariaDB などがこれにあたる。
-
テーブル (Table)
- RDBMS において、。テーブルは行(レコード)と列(フィールド)から成るデータ構造。
- レコード (Record): テーブル内の各行のこと。一連の関連データを表現する。
- フィールド (Field): テーブル内の各列は、レコードの特定の属性を表現する。
-
SQL (Structured Query Language)
- RDBMS のデータベースの構造とデータの操作(CRUD, Create, Read, Update, Delete)を行うための標準的な言語
-
インデックス (Index)
- データの検索速度を高めるためのデータベース構造。インデックスは特定の列の値に基づいてテーブル内のデータの位置を参照する。BTree というデータ構造を仕様。
- テーブル間の関係を定義するための概念
-
主キー (Primary Key)
- 各テーブル内で各レコードを一意に識別するフィールド。
-
外部キー (Foreign Key)
- あるテーブルのレコードが別のテーブルの特定のレコードを参照するためのフィールド。RDBMS でデータ同士の関係性を表現するための概念、機能である。
-
主キー (Primary Key)
-
正規化 (Normalization)
- データの重複を避け、データの整合性を保つためにテーブル構造を変更すること。
-
トランザクション (Transaction)
- データベースに対する一連の操作をまとめたもの。トランザクションは原子性、一貫性、分離性、耐久性(ACID特性)を持つ。
References
- PostgreSQL チュートリアルでの PostgreSQL のアーキテクチャ(サーバ / クライアント型)の説明。「データベースファイル(database files)」への言及もある。
RDBMS - トランザクションと ACID 特性
トランザクション
-
トランザクション (transaction)
- データベースに対する一連の操作のこと。データベースや分散システムにおいて、データの整合性、安全性を保つために必要な概念。例えば、ある特定のトランザクションを実行した際、一連の操作が全て成功するか、あるいは失敗した場合は操作が一つも実行されなかったかのように扱わうことで、データの整合性が保たれる。トランザクションには、ACID 特性というデータの整合性、信頼性などデータベースが正しく動作するために必要な性質を満たす必要がある。
ACID 特性
以下の 4 つの特性を全て満たすことで、データベーストランザクションの信頼性と整合性が維持されます。
-
ACID 特性
-
原子性 (Atomicity)
- トランザクション実行後のデータベースの状態が、トランザクションに含まれる一連の操作が「全て実行される」か「一つも実行されない」のどちらかの状態になるという性質。
- ex) 銀行の送金処理において、送金元の残高、送金先の残高それぞれの更新はトランザクションとして実行される。
-
一貫性 / 整合性 (Consistency)
- トランザクションの実行前後でデータの整合性が保たれ、矛盾が無い状態が継続される性質。
- ex) 銀行の送金トランザクションによって口座の残高が負になることがないようにする。
-
隔離性 / 独立性 (Isolation)
- 各トランザクションは互いに独立して実行され、他のトランザクションの実行中に発生する中間状態を見ることができないという性質。
- (言い換え)トランザクション実行中の処理過程は外部から隠蔽され、他のトランザクションに影響を与えないようにする性質。
- 隔離性により、複数のトランザクションが同時に行われるときでも、それぞれが互いに干渉せずに安全に実行できるようになる。
- ex) 銀行の送金トランザクションにおいて、処理の途上である「出金は実施済みだが入金は未実施」といった状態を外部から読み出されないよう排他制御などを行う。
-
耐久性 (Durability)
- 成功したトランザクションの結果は永続的であることを保証する性質。つまり、一度トランザクションがコミット(確定)されれば、その結果はデータベースに永続的に保存され、システム障害が発生した場合でも失われることはないという性質を表す。
-
原子性 (Atomicity)
References
コネクションプール connection pool
意味
-
コネクション connection
- DBMS は一般にアプリケーションの背後でデータを管理するために存在する。アプリケーションはユーザが利用したい機能に合わせて DBMS へ問い合わせをし、必要なデータを取り出してユーザに返す。アプリケーションが DBMS へ問い合わせを行い、その問い合わせに対応するデータを受け取りたい場合、アプリケーションと DBMS の間にネットワーク的な接続が必要になる。一般にこの接続には TCP 接続が用いられる。このアプリケーションと DBMS の接続のことを「コネクション」と呼ぶ。
-
コネクションプーリング connection pooling
- コネクションプーリングとは、プログラムがデータベース管理システム(DBMS)へアクセスする際、アクセス要求のたびに接続や切断を繰り返すのではなく、一度形成した接続窓口(コネクション)を維持し続けて使い回す手法。
-
コネクションプール connection pool
- コネクションプーリングにおいて、使い回す複数の接続を保持しているもの。
- 実体はオンメモリに保持し続けられている、TCP 接続が継続しているプロセス?
ポイントは以下の通り。
- サーバーレスでは hogehoge
- コネクションを新たに張るときに DBMS を動かしているインスタンス側は負荷がかかる
- プロセスを作成し、メモリ、CPU などのリソースの確保を行う
コネクションの作成手順
データベースとのコネクション作成は通常、以下のような手順で行われる。ここではTCP/IPを通じての接続を例にとる。
- ソケットの作成
- アプリケーションは、データベースサーバーへの通信路を作るために、ソケットを作成する。ソケットとは、ネットワーク上の 2 つのエンドポイント間の双方向通信リンクを提供するプログラムインターフェースである。
- サーバーへの接続
- アプリケーションは、データベースサーバーの IP アドレス(またはホスト名)とポート番号を指定して、ソケットを通じてサーバーに接続する。一般にここでの接続のプロトコルとしては TCP(Transmission Control Protocol)が利用される。TCPは、信頼性が高く順序付けされたバイトストリームを提供するプロトコルで、通信が正確に行われることを保証する。
- TCP 3 way handshake
- TCP 接続は、いわゆる 3 way handshake というプロセスを通じて確立される。まず、クライアント(ここではアプリケーション)は、接続要求とともに SYN パケットをサーバーに送信する。次に、サーバーは接続を認識し、SYN パケットに対する応答として SYN-ACK パケットをクライアントに送り返す。最後に、クライアントはこの SYN-ACK パケットに対する応答として ACK パケットをサーバーに送信する。これにより、TCP 接続が確立される。
- データベースへのログイン
- TCP 接続が確立したら、アプリケーションはデータベースへのログイン要求を送信する。これには通常、ユーザー名とパスワード(または他の認証情報)が含まれる。データベースサーバーは、これらの認証情報を検証し、正しい場合はアクセスを許可する。
- コネクションプール
- コネクションが確立され、使われなくなったとき、アプリケーションはこのコネクションを切断する代わりに、コネクションプールに戻すことができる。次にデータベース接続が必要になったとき、アプリケーションは新しい接続を作成するのではなく、コネクションプールから既存の接続を再利用することができる。これによりパフォーマンスが向上する。
このプロセス全体は、アプリケーションとデータベース間のコミュニケーションを可能にし、これによりデータの送受信を行うことができる。
コネクションプールはどのレイヤーの話?
コネクションプールは、アプリケーションレイヤーとデータベースレイヤーの間のリソース管理の概念である。
コネクションプールは、アプリケーションがデータベースへの接続を効率的に再利用するためのキャッシュまたはプールのことを指す。
ユーザからアプリケーションへのリクエスト → アプリケーションによるデータベース操作(ドライバー経由でクエリを送信しようとする操作)という処理を起点に、アプリケーションとデータベースのコネクションが新規作成される。このコネクションの新規作成処理には一定のオーバーヘッドが伴う。
大規模になると、リクエストのたびにデータベースへの接続を作成するため、サーバーのメモリ使用量が枯渇し、接続の最大許容数に達する可能性がある。解決策の 1 つは、より多くのメモリを購入することであり、もう 1 つはコネクションプールを使用すること。
このオーバーヘッドを避けるため、すでに開かれた(そして閉じられていない)接続をプール内に保持し、必要なときにそれを再利用する。これによりパフォーマンスが向上し、リソース利用が最適化される。
コネクションプールは、RDBMS 特有の概念ではなく、他の多くのネットワークサービスやプロトコルでも見られる。ただし、データベースアクセスにおいては特に重要となる。多くのアプリケーションが頻繁に小さなクエリを発行するため、コネクションの open / close のオーバーヘッドがパフォーマンスに大きな影響を与える可能性がある。
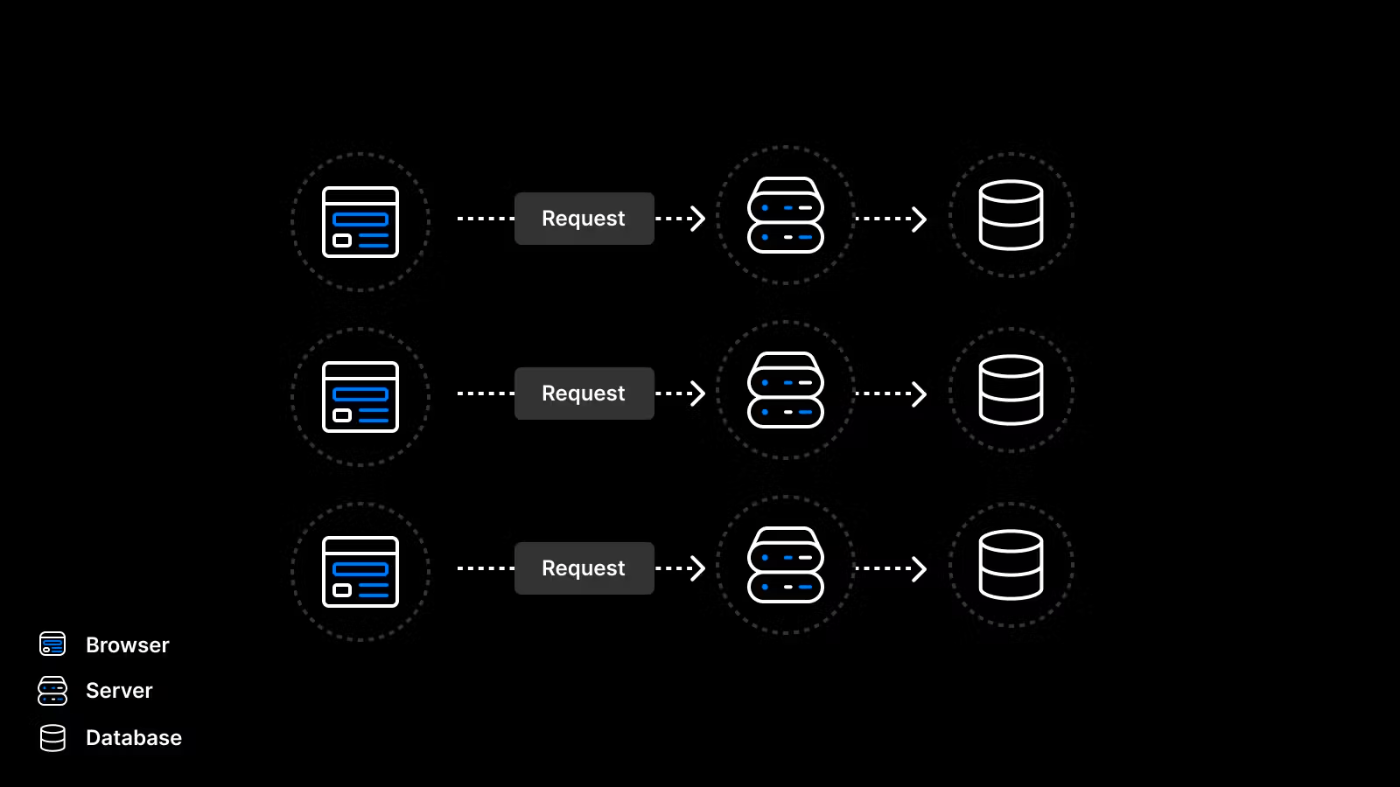
- コネクションプーリング以前
- コネクションプーリング以後
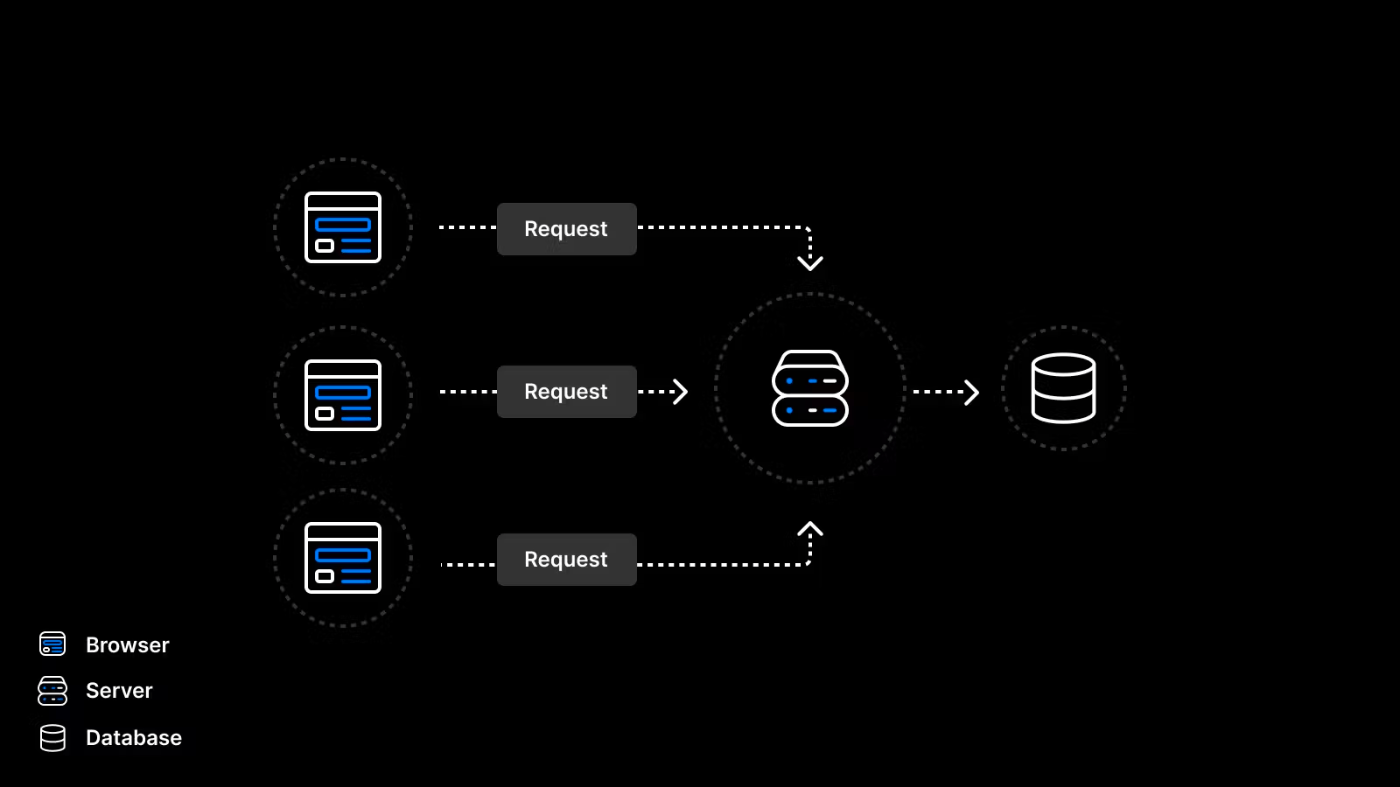
各種プログラミング言語やフレームワークでは、このコネクションプールを管理するためのライブラリやツールが提供されている。これにより開発者はデータベース接続の再利用やリソース管理を簡単に行うことができる。
コネクションプールの実例
Supabase PgBouncer
PgBouncer は PostgreSQL のためのオープンソースのコネクションプーラ(connection pooler)
pgpool。元祖コネクションプーラ?
コネクションプールはデータベースへの新規接続を減らすために接続を保持して使いまわす仕組みです。新規接続の受け付けはデータベースサーバにとってコストが高い処理です。再利用を行うことで接続によるオーバーヘッドを低減できます。
PostgreSQL のクライアントが Tomcat のようなアプリケーションサーバであれば、アプリケーションサーバ側でコネクションプールを用意することができます。しかし、Webサーバ上の PHP や Perl では、各 HTTP セッションを処理するプロセスの間で共通に使用できるコネクションプールを作ることは簡単ではありません。例えば PHP 言語で「永続的」な pconnect の機能がありますが、あくまで、Webサーバの単一プロセス内で接続を保持するだけです。pgpool-II は独立したサーバプロセスとして提供されるため、このようなケースでも複数のセッションで共用できるコネクションプールを実現できます。
PostgreSQL では同時接続数を増やしていくと、あるところからトータル処理性能が低下していきます。各接続を処理するプロセスの使用メモリ量の合計が大きなものになり、また、処理の競合による待ちも増えていくためです。したがって、同時接続数を一定レベルに抑える必要があります。ところが PostgreSQL は設定した最大接続数を超えた接続要求に対してエラーを返す振る舞いをします。これではアプリケーションの配置に制約が生じます。Webサーバであれば、Web側で受け付ける同時接続数を PostgreSQL の同時接続数を下回るようにしなければいけません。
pgpool-II では、pgpool-II に設定した最大同時接続数を超えた接続要求に対して、エラーではなく待たせる動作をします。PostgreSQL とアプリケーションの間に pgpool-II を挟むことで、データベースサーバの同時接続数をエラーを出さずに一定数に抑えることができるようになります。
References
Vercel 公式:コネクションプーリングとは?
Supabase 公式:コネクションプーリングとは?
Apache vs Nginx の話もしてくれていて、コネクションプールの理解に良さそう。
- Database Connections: Less is More
コネクションプールの実装には軽量プロセス(軽量スレッド)が大変良いのはなぜ?
Go でのコネクションプールの実装
pgpool について
Rust のテスト書くときにコネクションプールを使い回せない
事例
この Lambda のコネクションプールの問題は解決してた気がするけど、コネクションプールって何を理解するのに良さそう。→ Amazon RDS Proxy の登場により問題は解決してる。
- Amazon RDS Proxy あり / なしで負荷テストをやってる例
- エッジ環境におけるコネクションプーリングの問題とその解決方法。サーバーレス環境とコネクションプーリングの問題は共通。この記事の「サーバーレス環境とコネクションプーリング」の部分。2023/05 時点の記事。
- これも一緒に読むとはかどる。同じ筆者。2023/01 時点の記事。この時点では Amazon RDS Proxy や Cloud SQL Proxy のようなプラットフォームが提示する解決策がまだない状態だった。
コネクションプーリングの理解に Vercel のガイドが良さげ
- Connection Pooling with Serverless Functions
- コネクションプーリングとはについては分かりやすく書いてある。
Neon との Partnership についてちょこっと書いてある
- Cloudflare Workers とかのエッジ環境についてのイントロ
- Supabase PgBouncer: connection pooler
この記事良さそう
データベースドライバ
とりあえず ChatGPT で雑に。
データベースドライバーは、アプリケーションとデータベース管理システム(DBMS)間の通信を担当するソフトウェアコンポーネントです。これは、アプリケーションがデータベースに対して操作(クエリの実行、データの取得等)を行うためのインターフェースを提供します。
具体的には、アプリケーションがデータベースに対する操作を行う際、その操作をデータベースが理解できる形式(多くの場合はSQL)に変換し、結果をアプリケーションが扱える形式に変換する役割を果たします。
データベースドライバーはデータベースの種類(MySQL、PostgreSQL、Oracleなど)や使用しているプログラミング言語(Java、Python、Goなど)によって異なります。これは各データベースが独自の通信プロトコルやデータ形式を持つため、それぞれに対応したドライバーが必要となるためです。
データベースドライバーは、JDBC(Java Database Connectivity)やODBC(Open Database Connectivity)のような標準化されたAPIを通じてアクセスされることが多く、これによりアプリケーション開発者はデータベースの種類に関わらず一貫したコードでデータベース操作を行うことが可能になります。
分散システムにおける概念
シャーディング
意味
データベースのシャーディング(Sharding)は、大量のデータを効果的に管理するための手法で、データベースを複数のパーツ(シャードと呼ばれます)に分割し、各シャードを異なるサーバーに配置する方法を指す。これにより、データベースのパフォーマンスを向上させ、大量のデータを処理できる能力を維持できる。
シャーディングは、それぞれのシャードが独立して動作するため、各シャードでの読み取り / 書き込みのパフォーマンスが向上する。これは、すべてのデータを単一のデータベースに保持して処理するよりも高速でスケーラブルです。そのため、大規模なデータセットや高負荷の状況を扱う必要があるアプリケーションにとっては非常に役立つ手法である。
シャーディングは、主に大規模な分散データベースシステムで使われる。特に、データ量が大きく、単一のデータベースサーバーで処理することが難しい場合や、読み書きのパフォーマンスを向上させる必要がある場合などに利用される。
シャーディングを行うことで、データを異なる物理サーバーに分散させることができる。これにより、負荷を複数のノードに分散させることが可能となり、システム全体のパフォーマンスを向上させることができる。また、特定のデータを特定のシャードに配置することで、データの取得を高速化することも可能。
ただし、シャーディングは適切な戦略と計画をもとに行わなければならず、一度にすべてのデータを探索する必要があるクエリ(例えば、シャードを跨いだデータの集約やジョインなど)のパフォーマンスが下がる可能性がある。また、データを分散させることでデータの整合性を保つのが難しくなるという課題もある。
References
Rust での簡易的なシャーディングの実装例 in Tokio Tutorial
「EXPLAIN / ANALYZE の基本」、「PostgreSQL の内部構造」についての整理。
実行計画(Execution Plan)とはなにか、なぜ必要か
-
定義
- SQL をどう実行するかの設計図。
- 例)テーブルフルスキャンか、インデックススキャンか、結合順序や結合方式(Nested Loop / Hash / Merge)、並べ替えや集約の手段など。
-
必要性
- SQL は「何をしたいか」だけを書く言語(SQL は宣言的なプログラミング言語)。最短経路を選ぶのはオプティマイザ(クエリプランナ)の役割。
- オプティマイザは統計情報(行数、分布、選択性等)を用いて最小コストの計画を選択する。
統計情報が古いと、誤ったコスト推定 → インデックスを使わない、結合順序を誤る、過剰 I/O などの性能劣化を引き起こす。
EXPLAIN / EXPLAIN ANALYZE / ANALYZE の違い
| コマンド | 目的 | 何が出るか | 実クエリ実行 | 性能への影響 |
|---|---|---|---|---|
EXPLAIN |
計画の予測を見る | 推定行数・コスト・実行手順 | しない | ほぼなし |
EXPLAIN ANALYZE |
実測で計画と実行時間を確認 | 実行計画+実測時間・実行行数(推定 vs 実際) | する | 当該クエリ分はかかる(計測のオーバーヘッドも少し加算) |
ANALYZE |
統計情報の更新 | 統計テーブルの刷新(出力は簡易) | しない(サンプリングはする) | テーブル規模に応じて軽負荷 |
代表的な使い方(PostgreSQL)
-- 予測だけ確認
EXPLAIN SELECT * FROM users WHERE email = 'a@example.com';
-- 実測も確認(バッファ情報込み)
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM users WHERE email = 'a@example.com';
-- 統計情報更新(テーブル単位 / 全体)
ANALYZE users;
ANALYZE;
「ANALYZE だけで統計更新」 vs 「毎クエリで統計更新しない理由」
- 統計情報
- テーブルの行数、各列の分布(ヒストグラム・最小/最大・NULL 率・Ndistint)、インデックス選択性など。
- 毎クエリ更新しない理由
- 統計の再計算は自体は重い処理(全データをなめたりサンプリングが必要)→ クエリ毎にやるとオーバーヘッドが大きくて負荷増大。
- PostgreSQL の統計情報の更新タイミング
- バックグラウンドの
autovacuum/analyzeが、行の変更割合などの閾値を超えたときに自動実行。 - すぐに精度を上げたい時は手動で
ANALYZEを実行。
- バックグラウンドの
- 効果
- 最新統計に刷新 → オプティマイザの判断精度が上がり、
EXPLAIN/ 実行の品質向上。
- 最新統計に刷新 → オプティマイザの判断精度が上がり、
EXPLAIN / ANALYZE は DB にどのくらいの負荷を与えるのか?
-
EXPLAIN(計画のみ)- 実行しないので遅くならない(計画生成コストのみ。比較的軽量。)
-
EXPLAIN ANALYZE(計画 & 実測)- 実際にクエリを実行して計測するため、その実行時間分はかかる(計測のオーバーヘッドも微小に追加)。
EXPLAIN ANALYZEは常時使うものではなく、診断時に一時的に使うコマンド
-
ANALYZE- 統計更新のための軽~中程度負荷。大規模テーブルでは時間がかかることもあるが、通常はバックグラウンド実行または手動で適宜実行。
インデックスの基本と効果確認
-
例
CREATE INDEX idx_email ON users (email); -- 重複禁止なら CREATE UNIQUE INDEX idx_email_unique ON users (email); -
効果の確認
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM users WHERE email = 'a@example.com';- 期待:
Index Scan using idx_emailと表示される、Buffers: shared hit=...が増えるほどメモリヒット(キャッシュヒット)。
- 期待:
-
注意
- 先頭
%を含む LIKE(LIKE '%example.com')は B-tree では効きにくい。 - インデックスが増えるほど書き込み遅延(更新時に全インデックス更新)とメモリ圧迫(後述)が発生。
- 先頭
なぜインデックスはメモリを消費するのか(PostgreSQL 内部)
インデックス自体はディスク(ストレージ)に保存されるが、高速化のためにメモリ(shared_buffers)へキャッシュされるため。
物理配置
- テーブル本体:
base/<db_oid>/<relfilenode> - インデックス:テーブルとは別ファイルで B-tree などのページ(8KB)として保存。
キャッシュ階層
-
shared_buffers(PostgreSQL のバッファプール)- テーブル・インデックスのページを 8KB 単位でキャッシュ。
- LRU 近似方式で管理。サイズは
SHOW shared_buffers;で確認。
- OS ページキャッシュ
-
shared_buffersから溢れた場合でも、OS キャッシュに乗ることがある。
-
実行時の流れ(概念)
- クエリ実行 → 必要なインデックスページを探す
-
shared_buffersにヒット(キャッシュヒット)すればディスク I/O 無し。メモリ I/O のみで高速。 - ヒットしなければディスクからインデックスページをロードして
shared_buffersへ配置 - 更新系はメモリ上でページを更新 → WAL 記録 → 遅延書き戻し(非同期でストレージに書き込み?カーネルのライトバック処理みたいな感じ?)
典型的な EXPLAIN 出力と読み方
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM users WHERE email = 'a@example.com';
計測結果の例:
Index Scan using idx_email on users (cost=0.29..8.31 rows=1)
(actual time=0.02..0.03 rows=1 loops=1)
Buffers: shared hit=3
-
Index Scan using idx_email:B-tree インデックス利用 -
Buffers: shared hit=3:3 ページが shared_buffers にヒット(メモリ経由) - 初回などで
read=3と出ればディスクから読んだことを示す
まとめ:インデックスによりメモリ消費が増える理由
-
キャッシュ対象の増加
- インデックス数が増える=保持すべきページが増える
-
更新時の作業領域
- 各インデックスのページ更新・WAL 記録で一時的にメモリを要する
-
メタ情報(統計・メンテ構造)の増加
- 監視/内部管理のための付帯コスト
-
影響
-
shared_buffersがメモリを圧迫 → キャッシュヒット率低下 → ディスク I/O 増 → 遅くなる可能性
-
PostgreSQL 特有の実務のポイント
-
統計の自動更新
- autovacuum/analyze が行う(閾値超過時)。遅延があるため、データ分布が急変した直後は手動
ANALYZEが有効。
- autovacuum/analyze が行う(閾値超過時)。遅延があるため、データ分布が急変した直後は手動
-
統計の格納先
-
pg_statistic(DB が参照) - 定義は
pg_statsビューで確認しやすい
-
-
キャッシュ状態の把握
SHOW shared_buffers; SELECT blks_hit, blks_read, blks_hit * 100.0 / NULLIF(blks_hit + blks_read, 0) AS hit_ratio FROM pg_stat_database WHERE datname = current_database(); -
実行計画の妥当性をチェックする(想定通りに計画されているかをチェックする)
-
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)を活用し、推定行数 vs 実行行数、shared hit/read、結合順序、フィルタ条件の選択性を確認。
-
-
インデックス設計の原則:
- 頻出な検索条件の先頭に置く(複合インデックスは左端から効く)
- 過剰作成は禁物(書き込み負荷・メモリ圧迫)
- 部分・式インデックスの活用(条件が限定的/計算列が多い場合)
- 文字列の前方一致は B-tree が効きやすいが、先頭ワイルドカードは効かない(pg_trgm等の検討)
実務での典型的なワークフロー
- 統計の更新(スロークエリを探索するときは先に
EXPLAIN。そのあとANALYZE。)ANALYZE users; - 現状計画の把握
EXPLAIN SELECT ...; - 実測 + I/O の可視化
EXPLAIN (ANALYZE, BUFFERS) SELECT ...; - インデックス設計・追加
CREATE INDEX idx_email ON users (email); - 効果検証
EXPLAIN (ANALYZE, BUFFERS) SELECT ...; - モニタリング
SHOW shared_buffers; SELECT ...hit_ratio... FROM pg_stat_database; - 見直し
- ヒット率低下・I/O 増大時は不要インデックスの削減や統計の再更新を検討。
まとめ
- 実行計画
- DB が選ぶ実行手順の設計図。現在の統計情報を参照して計画。
-
EXPLAIN- 計画(予測)のみ。高速。
-
EXPLAIN ANALYZE- 計画 + 実測値。当該クエリ分は遅くなる。
-
ANALYZE- 統計の更新。毎クエリではやらない(重い)
- 自動 / 手動のタイミングで実施。
- PostgreSQL 内部
- インデックスはディスクに保存、利用時に
shared_buffersへキャッシュされる。 - 8KB ページ単位、
Buffers: shared hit/readで可視化。 - インデックス増は書き込み負荷とメモリ圧迫を招く。
- インデックスはディスクに保存、利用時に
- 設計原則
- 必要十分なインデックス、統計の鮮度、計画の観測と再設計のループが性能の要。
スロークエリの検知から修正までの流れの整理。以下を参考。
恒常的なモニタリングにより、まず「スロークエリ」を見つける
基本:サーバログで検知
postgresql.conf を設定して、一定時間以上かかったSQLを自動でログ出力させる。
# 代表的設定
logging_collector = on
log_min_duration_statement = 500ms # 例: 500ms超をスローとして記録
log_statement = 'none' # 逐次ログは無効のままが無難
log_line_prefix = '%m [%p] %u@%d %r %a ' # 時刻/プロセス/DB/ユーザ/アプリ 等
log_lock_waits = on # ロック待ちも記録
deadlock_timeout = 10s # デッドロック兆候の検知を早める
track_io_timing = on # I/O時間の計測(負荷少)
- 実行時間が長い SQL があれば、そ「SQL 全文」と「実行時間」がログに残る。
- ログは
pgBadgerなどで可視化すると、遅い SQL ランキング・時間帯の傾向が一目で把握できる。
本番環境:pg_stat_statements で集計
拡張を入れて SQL ごとの統計情報を集計する(平均/最大/呼出回数/標準偏差など)。
-- 1回限り: postgresql.conf
shared_preload_libraries = 'pg_stat_statements'
-- DBで
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- 使い方(遅い順にTOP表示)
SELECT query, calls, mean_exec_time, max_exec_time, rows
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 20;
- どのクエリが平均的に遅いか / たまに極端に遅いか / 回数が多いかが分かる。
- アプリ側のバインドパラメータは正規化された形で集計されるため分析しやすい。
オンコール対応:実行中の遅延を即時に見る
-
長時間実行中のクエリを今すぐ確認:
SELECT pid, now()-query_start AS dur, state, wait_event_type, wait_event, query FROM pg_stat_activity WHERE state <> 'idle' ORDER BY dur DESC; -
ロック待ちの把握:
SELECT a.pid, a.query, l.locktype, l.mode, l.granted FROM pg_locks l JOIN pg_stat_activity a ON l.pid=a.pid ORDER BY a.query_start;
APM / 外部監視の活用(併用推奨)
Datadog / New Relic / AppSignal などはトレースと SQL を紐付け、遅いエンドポイントや N+1 も発見しやすくなる。
スロークエリ候補が見つかった後:EXPLAIN / ANALYZE の実行
以下が基本的な流れ:
- スロークエリの検知
- スロークエリの候補を特定
- その SQL に対して
EXPLAIN/ANALYZEを当てて原因を掘る
まず EXPLAIN で実行計画を見る
EXPLAIN SELECT ...;
使われるインデックス、結合方式、推定行数・コストをざっと確認し、明らかなミスマッチ(全件スキャン(Seq Scan)、巨大 Hash 作成等)を洗い出す。
EXPLAIN (ANALYZE, BUFFERS) で実測値を確かめる。I/O も見る。
EXPLAIN (ANALYZE, BUFFERS) SELECT ...;
-
actual rowsが推定と大きく乖離- → 統計不整合の疑い
- →
ANALYZE(必要ならALTER TABLE ... ALTER COLUMN ... SET STATISTICSで精度を上げる)
-
Buffers: shared read=...が大きい- → キャッシュミスやディスク I/O が多くなっている
- インデックス設計、JOIN 順、取り過ぎ列の見直し
書き込み系クエリ(INSERT / UPDATE / DELETE)は検証用のコピーで行うか、BEGIN; ... ROLLBACK; の中で実行する(シーケンス / 外部副作用は残る可能性に注意)。
診断の効率化:自動で「遅いクエリの実行計画をログ」に残す
auto_explain 拡張で、一定時間を超えたクエリの計画 & 実測を自動でログに残すことができる。
shared_preload_libraries = 'auto_explain'
# 例: 200ms超のクエリに対して実行計画を自動出力
auto_explain.log_min_duration = '200ms'
auto_explain.log_analyze = on
auto_explain.log_buffers = on
auto_explain.log_timing = on
auto_explain.log_nested_statements = on
- 「たまにだけ遅い」タイプの再現困難な問題に強い。
- ログ量は増えるので閾値は慎重に。
典型トリアージ手順
- スロークエリの検知
- ログ(
log_min_duration_statement)、pg_stat_statements、APMでスロークエリを特定。
- ログ(
- 状況把握
-
pg_stat_activity/pg_locksでロック待ちを確認。 - 直近の設定変更、デプロイ、統計更新の有無も確認。
-
- 仮説を立てる
- 統計古い?インデックス不適切?結合順や型不一致?フィルタが後置き?
- ネットワーク、ストレージI/O、チェックポイント、メモリ逼迫?
- 計画 / 実測の取得
-
EXPLAIN、EXPLAIN (ANALYZE, BUFFERS)で推定vs実測を行う。 - I/O、スキャン方式、結合順を確認。
-
- 対策(参考:(2023.04) Vol.01 Bill Oneで実施したSQLパフォーマンスチューニングの事例紹介)
-
ANALYZE/ 統計ターゲット調整 - インデックス新設/再編(部分/式/複合)
- SQL書き換え(不要列削減、JOIN順誘導、CTE / サブクエリ再構成)
- パラメータ調整(
work_mem,effective_cache_size,random_page_costなど)
-
- デプロイ
- 再計測
- 同じ条件で
EXPLAIN (ANALYZE, BUFFERS)を再取得し改善度を数値で確認。
- 同じ条件で
- 継続監視
-
pg_stat_statements上位に再浮上しないか、ログ、ダッシュボードでウォッチ。
-
どの設定・ビューを見ればよいか
-
現行しきい値(スロー閾値):
SHOW log_min_duration_statement; -
統計の鮮度に懸念 → 即時更新:
ANALYZE 目立つテーブル名; -
遅いクエリランキング:
SELECT query, calls, total_exec_time, mean_exec_time, rows FROM pg_stat_statements ORDER BY total_exec_time DESC LIMIT 20; -
実行中で長いもの/待ちがあるもの:
SELECT pid, now()-query_start AS dur, wait_event_type, wait_event, state, query FROM pg_stat_activity WHERE state <> 'idle' ORDER BY dur DESC;
EXPLAIN / ANALYZE を「いつ使うか」の具体イメージ
- ログや
pg_stat_statementsで遅い SQL が判明した瞬間- → そのSQLをそのまま
EXPLAIN、必要に応じてEXPLAIN (ANALYZE, BUFFERS)。
- → そのSQLをそのまま
- インデックスを新設 / 削除する前後
- → 効果検証として
EXPLAIN (ANALYZE, BUFFERS)を前後比較。
- → 効果検証として
- データ分布が急変した(大量 INSERT / UPDATE 後)
- →
ANALYZE実行 →EXPLAINでプラン変化を確認。
- →
- たまにだけ遅い
- →
auto_explainで当該瞬間の計画を自動採取して原因特定。
- →
- 本番での直接
ANALYZEが重い / 副作用が不安- 直近の本番データをステージングに複製し、
EXPLAIN (ANALYZE, BUFFERS)を安全に実行。
- 直近の本番データをステージングに複製し、
補足Tips(ハマりどころ回避)
-
EXPLAIN ANALYZEはクエリを実行する。副作用のある書き込み系クエリ(UPDATE/DELETE/INSERT)は検証環境やROLLBACKを活用する。 - パラメータによってプランが変わる(選択性が変動)ため、本番の代表的パラメータで再現する。
-
work_memが小さいとソート / ハッシュがディスク落ちしやすく、急に遅く見えることがある。 -
track_io_timing=onで I/O 主体か CPU 主体かの切り分けが楽になる。 - PG 15+ では
EXPLAIN ... WALなどの追加情報、PG 16 以降は I/O 統計系ビュー(バージョンに応じて活用)を活用。
まとめ
- 検知(ログ /
pg_stat_statements/ APM) - 観測(
pg_stat_activity/locks) - 仮説(統計 / 索引 / 結合順 / メモリ / I/O)
-
EXPLAIN→EXPLAIN(ANALYZE, BUFFERS)で裏取り - 対策実装(INDEX 追加 / SQL 改善 / 設定見直し / 統計)→ 再計測
- デプロイ
- 継続監視(再発防止&自動採取)
PostgreSQL におけるインデックスの基本
インデックスの基本
まず前提として:
- PostgreSQL のインデックスはディスク上に格納されるデータ構造
通常は B-tree がデフォルト。インデックスはテーブルのカラムやカラムを用いた式に対して作成でき、以下のように作成できる。
CREATE INDEX idx_email ON users (email);
すると PostgreSQL は次のような構造を作る:
-
usersテーブルのデータファイル(base/.../users) -
idx_emailインデックス専用のファイル(base/.../idx_email)
つまり、テーブルとインデックスは物理的に別ファイルとして存在する。
どこにインデックスを貼るのが良いか?
以下を参照。
基本的な内容と思われるかもしれませんが、インデックスを貼ることは大事です。以下のようなカラムにはインデックスを貼ります。
- 外部キーとして指定され、結合に使われるカラム
- PostgreSQLでは、外部キー制約を付与しても参照する側の列には自動的にインデックスが付与されない。こちら の以下の記述の通り。
インデックスの方法には多くの選択肢がありますので、外部キー制約の宣言では参照列のインデックスが自動的に作られるということはありません。
- 検索で使われるカラム
- ソートで使われるカラム
インデックスはなぜメモリを消費するのか?
PostgreSQL には shared_buffers というメモリ領域があり、ここに「最近使われたテーブルページ」や「インデックスページ」がキャッシュされる。
動作イメージ:
- クエリ実行
-
shared_buffersにインデックスページがある?
→ あればディスクアクセスなし
→ なければディスクから読み込み、shared_buffers にコピー
つまり、インデックスはストレージにあるが、利用のたびにメモリ上に展開されるため、DB は実際にはメモリをインデックスのために消費することになる。
インデックスの実装(内部構造)のイメージ(B-tree)
PostgreSQL の B-tree インデックスは、概ね次のような階層構造を持つ:
[Root Page]
/ \
[Branch Page] [Branch Page]
/ \ / \
[Leaf Page][Leaf Page][Leaf Page][Leaf Page]
- これらの Page(約 8 KB 単位)がディスク上に保存される。
- クエリ実行時に、必要な Page をメモリ上(
shared_buffers)にロードして利用する。
shared_buffers によるキャッシュ動作
| 項目 | 内容 |
|---|---|
| 領域名 | shared_buffers |
| 役割 | データ・インデックスのキャッシュ |
| デフォルトサイズ | 約 25 % の RAM(PostgreSQL 設定次第) |
| 仕組み | LRU(最近最も使われた順)でページを保持 |
| フォールバック | 足りない場合は OS のページキャッシュを利用 |
つまり、インデックスを多く作ると:
- キャッシュ対象ページが増える
- → 結果的に
shared_buffersが圧迫される - → 古いキャッシュが追い出され、ディスク I/O が増える
具体的な動作例
例 1:インデックス利用時
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM users WHERE email = 'a@example.com';
出力例:
Index Scan using idx_email on users (cost=0.29..8.31 rows=1 width=64)
(actual time=0.020..0.022 rows=1 loops=1)
Buffers: shared hit=3
→ Buffers: shared hit=3 は「3 ページが shared_buffers にヒット(ディスクアクセスなし)」を表す。
→ メモリキャッシュを使っている証拠。
例2:キャッシュがない場合
キャッシュが切れていたり、初回アクセス時には:
Buffers: shared hit=0 read=3
→ 3ページ分をディスクから読み込んだ(=メモリ消費が増えた)という意味になる。
まとめ:メモリ消費が増える理由
| 原因 | 説明 |
|---|---|
| インデックスページをキャッシュするため | 頻繁に使われるページをメモリ上に保持 |
| 複数インデックスがあると総ページ数が増える | LRUキャッシュが逼迫する |
| 更新時に複数インデックスを同時に更新 | メモリ内でバッファを確保し、後で書き戻す必要あり |
| WAL(Write-Ahead Log)との併用 | インデックス更新は WAL にも記録するため、追加のメモリを利用 |
補足:確認コマンド例
現在のメモリ設定を確認するには:
SHOW shared_buffers;
キャッシュヒット率を確認するには:
SELECT blks_hit, blks_read, blks_hit * 100.0 / (blks_hit + blks_read) AS hit_ratio
FROM pg_stat_database
WHERE datname = current_database();
hit_ratio が高いほど、キャッシュが効いている(ディスクアクセスが少ない)ことを意味する。
まとめ
| 項目 | PostgreSQLでの動作 |
|---|---|
| インデックスの格納場所 | ディスク(base/.../indexファイル) |
| メモリを使う理由 |
shared_buffers という PostgreSQL が確保するメモリ領域にキャッシュされるため |
| キャッシュ単位 | 8 KB ページ単位(インデックスもテーブルも同じ) |
| インデックスが多い場合の影響 | メモリ圧迫 → キャッシュヒット率低下 → I/O 増大 |
| 対策 | 必要最小限のインデックス設計 + 適切な shared_buffers 設定 |