OpenTelemetry に入門する
この本めっちゃ良かった。本編も良い。コラムの現実的な内容や各概念に対する考え方とかめっちゃ良かった。Azure 関係なくシステム設計の基礎的な概念を一通りマッピングできる本。
参考:クラウドアプリケーション 10の設計原則 「Azureアプリケーションアーキテクチャガイド」から学ぶ普遍的な原理原則
用語
-
計装, instrumentation
- アプリケーションの運用に必要な情報を取得できるようにする行為や仕組みのこと
- 能動的なニュアンスの言葉。「取得可能な範囲のデータでなんとかやりくりする」という受動的な態度ではなく、「自分でデータを取得できるようにする」という能動的な態度が「計装」。
-
テレメトリ, telemetry
- システムの挙動を外から観測できるようにするための情報。ログ、メトリクス、トレース。
- tele-: 遠隔、metry-計測
-
ログ, log
- システム内で発生したイベントを記録したテキスト
-
メトリクス, metrics
- 特定の時点におけるシステムの状態を数値化したもの
-
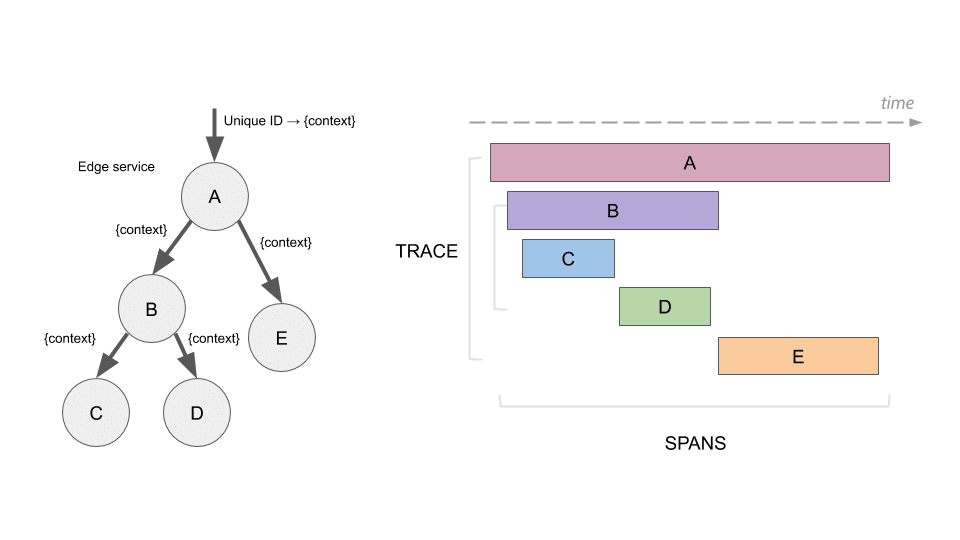
トレース, trace
- 複数の実行基盤や要素で構成される分散システムにおいて、同じリクエストを関連付け、性能やイベントを追跡する仕組み
可観測性と監視の解釈
制御工学における「可観測性(オブザーバビリティ、observability)」。
可観測性はシステムに対する評価尺度ってことか。
システムから外部へ出力される情報で、その内部状態をどの程度推測できるかを評価する尺度
監視 monitoring(行為)と可観測性 observability(能力)の違いについて。
監視は「既知の未知」、可観測性は「未知の未知」を扱う、という部分が要点
- 監視, monitoring
- 問題であると認識している状態であるかを、継続的に確認する行為
- オブザーバビリティ, observability
- 未知、予測できないことが起こったとしても、外部から内部状態を理解しやすいかを評価する尺度
(引用元:クラウドアプリケーション 10の設計原則 「Azureアプリケーションアーキテクチャガイド」から学ぶ普遍的な原理原則 p.149-p.150)
整理
監視は、システムを開発・運用する人が「何が問題かを理解、認識している状態」が前提。これが「既知」の部分。「何が問題か」を定義できるので、それを継続的に確認すればシステムが正常かどうかを判断できる。
可観測性は、システムを開発・運用する人が「何が問題かを理解している状態」は前提ではない。
(は言い過ぎ?問題の理解、認識は監視の範囲でやれば良い。監視と可観測性でベン図の共通部分はあると思うけど、分けることで何をすべきかが明確になるので定義は分かりやすくなるかも。)
可観測性の観点では「何が問題か」を定義していない状態で、未知、予測できないことが起きたときに何が起きているのかが把握できる状態になっていることが望ましい。
まとめ
自分の理解としては以下になる。
既知として認識できる部分は洗い出してメトリクスに落として、閾値設定、アラート設定を行って、アラート時の対応を整理しておく。問題を認識できない未知の部分はログ、メトリクス、トレースで掘りさげられる状態を作っておく、つまり可観測性を向上させておく。まずは既知で落とせる所は落として(ここももちろん大変)から可観測性の出番となる。
ChatGPT 5-thinking に生成してもらったやつ。Web サーバの「監視」の例。
既知(Known-known)の監視ターゲットと“鳴らし方”まとめ
レイヤ別:まず張るべき監視ポイント
Web / LB / API ゲートウェイ
- 5xx率、429率(レート制限発火)
- p95/p99 レイテンシ & タイムアウト率
- 受け口の飽和:
accept()キュー / リッスンバックログ溢れ(SYN/accept queue) - アクティブ接続数、ワーカー数上限近傍
アプリ(言語ランタイム / フレームワーク)
- スレッド / ワーカープール使用率、リクエスト待ち行列長
- GCポーズ時間(JVM/Go)、イベントループ遅延(Node.js)
- メモリ RSS / ヒープ上限接近、FD(ファイルディスクリプタ)使用率
ジョブ / キュー / ストリーム
- キュー深さ・滞留時間(age)・DLQ件数
- コンシューマラグ(Kafka/SQS)・再配信 / 再試行回数
- 処理スループットの急落(入力は来てるのに処理が減速)
DB / ストレージ
- 接続プール枯渇、ロック待ち / デッドロック、スロークエリ件数
- レプリケーションラグ、チェックポイント時間
- ディスク枯渇(容量 / iNode)・
iowait高止まり・EBSバースト残量
キャッシュ / CDN
- ヒット率低下、エビクション急増
- キャッシュ → オリジンのフェイル / レイテンシ悪化
ネットワーク / OS
- CPU(特に
iowait)、ランキュー長 > 論理コア数 - TCP再送・ドロップ増、
ListenOverflows(= バックログ溢れ) - OOM kill 検出、コンテナ / Pod の再起動スパイク
外部依存(SaaS / サードパーティ API)
- 4xx(429含む)/ 5xx率、レートリミット残量
- 呼び出し p95/p99、バックオフ / リトライ比率
ビジネス KPI(表層症状を掴む)
- 成功トランザクション変動、カゴ落ち率、決済失敗率
- サインイン失敗率、重要ファネルのドロップ
“鳴らし方”の目安(ページ or チケット)
-
ページ(起こす)
ユーザー影響が即時 / 広範。例:- 5xx率 > 1% が 5 分継続
- p99 > 2s が 10 分継続
- 受け口溢れ(バックログ溢れ)検知
-
チケット(後追い対応)
劣化の前兆や容量系。例:- FD 使用率 80% 超
- ディスク使用率 70% 超
- キャッシュヒット率のジリ下げ
ChatGPT 5-thinking に生成してもらったやつの Web サーバの「可観測性」を向上する例。
オブザーバビリティ(未知に強くする設計)まとめ
“アラートは既知を鳴らす。オブザーバビリティは未知に答える。”
つまり 掘れるデータ と 掘る導線 を用意しておくのが仕事。
目的(ゴール)
- 未知・予測不能な事象が起きたときに、原因候補へ最短でピボットできる状態をつくる。
- “平均”ではなく分布と相関で見る。属性で切り、トレースで確証を取る。
三本柱(Metrics / Logs / Traces の役割)
- Metrics:変化検知・傾向把握(SLO/バーン、p95/p99、レート、エラー率)。
- Logs:コンテキスト(意思決定・パラメータ・分岐)。構造化JSONで属性を付ける。
- Traces:因果の地図。どのスパンで詰まっているか/下流か上流かを確定。
カギは 相互リンク:ダッシュボード ⇒(Exemplars)⇒ 代表トレース ⇒ ログ。
設計原則(Unknown に強くするコツ)
-
高カーディナリティを恐れない“設計”
- 属性例:
trace_id / request_id / tenant_id(h) / user_id(h) / region / build_sha / feature_flags[] / experiment_bucket / shard / plan_tier / os_version / carrier - ハッシュ化で個人特定を回避しつつピボット可能に。
- 属性例:
-
メトリクス ⇒ トレースの橋(Exemplars)
- p99が跳ねたそのバケツの代表トレースに飛べる導線を用意。
-
サンプリングは“痛いもの濃く”
- Tail-based / 動的サンプリング:エラー・高レイテンシ・レア属性は100%保存、通常は薄く。
-
コンテキスト伝搬の厳守
- W3C Trace Context(
traceparent)+ジョブ/キュー間の手動伝搬(ヘッダ/メッセージ属性)。
- W3C Trace Context(
-
スキーマと命名の規律
- 単位(ms/秒/bytes)固定、
http.server.duration等の標準名を踏襲。 - ステータスは数値+語(
status_code=500, error=true, error.type=...)で曖昧さ排除。
- 単位(ms/秒/bytes)固定、
最小インストルメンテーション(まず埋める属性)
-
HTTP(サーバ/クライアント)
http.method, http.route, http.status_code, peer.service, net.host, net.peer.ip, region, tenant_id(h), user_id(h), build_sha, feature_flags[]
-
DB
-
db.system, db.operation, db.statement.digest, db.rows_read/affected, db.sql.table(※PII/値は落とさない)
-
-
キュー/ストリーム
messaging.system, queue.name, message.id(h), enqueue_age_ms, retry_count
-
外部API
rpc.system, vendor, quota_bucket, retry_count, backoff_ms
-
リソース属性(全スパンに乗る)
service.name, service.version, deployment.environment, cloud.region
ダッシュボード/ビュー(未知を掴むための画面)
-
レイテンシ分布ヒートマップ:
service × endpointを region/tenant/flag で絞れる。 - エラー俯瞰:エラーフィンガープリント上位、新規発生/再発を分離。
- サービスマップ:RPS・エラー率・p95 を矢印に重畳。どこで詰まるかが一目で分かる。
-
リリース比較:
build_sha切替前後の KPI 差分。 - SLO & エラーバーン:バーン検知から該当時間帯のトレースへ一発ジャンプ。
調査ワークフロー(“未知”に遭遇したら)
- SLOバーン/メトリクス異常をトリガに時間窓を決める。
- 相関ビューで属性重要度(region/tenant/flag/endpoint)をランキング。
- 代表トレース(Exemplar)を開く → self_time(自身の実行時間)が大きいスパンを特定。
- 隣接スパン(上流/下流)の遅延・エラー有無で因果を切る。
- 該当スパンのログ(構造化)で入力/条件/分岐を確認 → 再現 or ロールバック判断。
サンプリング&保持の指針
-
Tail-based(推奨):
error=true/duration>p99/rare_endpoint/tenant=VIPは keep 100%。 - Head-based:全体 0.1–5% 程度の薄取り(正常時の傾向把握用)。
- 保持:Traces 3–7日、Logs 7–30日、Metrics(集約)90–400日。
- コスト制御:スパン数削減(冗長スパンを抑制)、ログはイベント選別+サマリ計測へ。
実用スニペット
OpenTelemetry Collector(Tail サンプリング例・YAML)
processors:
tail_sampling:
policies:
- name: errors
type: status_code
status_code:
status_codes: [ERROR]
- name: high-latency
type: latency
latency:
threshold_ms: 1000
- name: vip-tenant
type: string_attribute
string_attribute:
key: tenant.tier
values: ["enterprise"]
- name: default-prob
type: probabilistic
probabilistic:
hash_seed: 1
sampling_percentage: 5
Node.js(OTel 自動+手動属性)
import { diag, trace, context, propagation, baggage } from "@opentelemetry/api";
const bag = baggage.setBaggage(context.active(), baggage.create({
"tenant.id": { value: hash(tenantId) },
"build.sha": { value: process.env.BUILD_SHA ?? "dev" },
}));
const span = trace.getTracer("web").startSpan("checkout", undefined, bag);
span.setAttribute("feature.flags", ["new-pricing", "ab-test-42"]);
span.setAttribute("region", process.env.REGION ?? "ap-northeast-1");
// ... do work
span.end();
構造化ログ(トレース相関)
{
"timestamp": "2025-09-07T07:12:34.567Z",
"level": "error",
"msg": "payment failed: signature expired",
"trace_id": "8f1c...a2",
"span_id": "3b4e...91",
"tenant_id_h": "t:ab13f",
"user_id_h": "u:9c22e",
"endpoint": "POST /v1/checkout",
"region": "ap-northeast-1",
"build_sha": "b7e1c2",
"error.type": "SignatureExpired",
"clock.skew_ms": 4500
}
配管(参考:最小構成図)
ガードレール(やり過ぎ注意)
- PII禁止:生のメール/電話/住所/トークンは落とさない。必要ならハッシュ化。
- カーディナリティ予算:属性は必要最小限+上限監視(爆発時はドロップ/サンプル)。
- プライバシー:ユーザー追跡は同意の範囲内で。データ最小化&保持期限の設定。
チェックリスト(導入時に見るやつ)
- 主要エンドポイントの トレース100%(まずは短期間で)
-
tenant_id(h), region, build_sha, feature_flags[]を全スパン/ログに - SLO/バーンから代表トレースへ飛べる導線(Exemplar連携)
- Tailサンプリングの閾値(エラー/高遅延/レア属性)
-
リリース比較ダッシュボード(
build_sha切替) - コスト監視(スパン数・ログ量・保存期間)
ひと言で
- 未知は“平均”に隠れる。
- 属性で切って、代表トレースで確証。
- 痛いものは絶対落とさない(Tail Sampling)。
計装の種類
計装は「アプリケーションの運用に必要な情報を取得できるようにすること」と書いたが、具体的には「アプリケーションの運用に必要なテレメトリデータ(ログ、メトリクス、トレース)を取得できるようにすること」となる。
もっと具体的には、監視・オブザーバビリティプラットフォームにテレメトリデータを送信してダッシュボードで確認できるようにすること、となる。
※「計装」という言葉自体にはデータの集計やダッシュボードの実装は含まれない。
計装には 3 つのパターン。
- 自動計装
- サービスの有効化やリソースの作成に合わせ、標準で計装される
- e.g. Amazon EC2 で VM を作成すると、基本的なメトリクス(メモリ使用量、CPU 使用率など)が取得できる
- e.g. Amazon ECS でコンテナを起動すると、基本的なメトリクス(メモリ使用量、CPU 使用率など)が取得できる
- 運用を支援するツールやサービスを導入すると計装される
- e.g. New Relic、Datadog、Sentry などのオブザーバビリティプラットフォームのクライアントをアプリケーションを構成するサービスに導入する
- サービスの有効化やリソースの作成に合わせ、標準で計装される
- 手動での計装
- アプリケーション開発者が計装する
- スパン、トレースを仕込む

参考
分散トレーシングのためツール Jaeger (イェーガーって読むらしい。ジャガーって読んでた。)
アプリケーションの高速化
- 処理の流れを丁寧に整理する
- 仮説を立てる
- (なければ)該当箇所に計装:アプリケーションにスパン、トレースを仕込む
- 計測
- 高速化の目標を決める
- 高速化の実装
「根拠なしにハックするな、計測せよ」ってのが良いですね。
そうだね。このサイクルを回す。
そもそも、「適切な計測」は「適切な推測」なしに成り立たせるのが難しい。ある程度ボトルネックを推測し実験(計測)を繰り返しながら仮説を少しずつ強化し、改善策を入れるという作業が実際のパフォーマンス改善のワークロードに近い。
目的である「パフォーマンスの改善」を見失ってはいけない。
推測 -> 計測を繰り返して「限りなく正しいと思われる推測」を導き出して改善する。
また、ボトルネックの原因を理論的に「証明」することは現代の複雑すぎる計算機では実質的に不可能に近い(もしくは非常に煩雑である)場合がある。多くの自然科学が実験によってブラックボックスを解きほぐしていくように、推測を行ってはそれを棄却ないし強化するために実験を繰り返し、最終的にある仮定が正しいと信じられるだけだ。「証明」するというより、推測を積み上げた先に「限りなく正しいと思われる推測」が作られる。
Optimized C++でKurt Guntherothが言うように、必ずしもソフトウェアエンジニアは「証明」に取り組む必要はない。結局のところ、パフォーマンスが十分に改善されてしまえばそれでよく、「証明」自体は労力に対して得られるものが少ないことがあるからだ。必ずしもボトルネックの仮説を十分に強化してから改善に取り組まなければならないわけでもない。ある程度の整合性のある仮説があり、その仮説に則った改善策によって十分改善されるのであれば、その改善自体が仮説を強化出来る。
うっ
そういった事件があったのかという指摘はギクっとして、何も仮定を立てずにそれっぽいツールが出してくるそれっぽい数値を参考にパフォーマンス最適化をして沼った経験がある。ベンチマークやワークロードをブラックボックスにしてしまうのって結構やってしまうと思っているんだけど、この正当化に「推測するな、計測せよ」が使われているシーンは何度も見た。つまり計測しているので正しいと主張してしまうケース。
心当たりが無い?本当に?
カーディナリティ
cardinality(カーディナリティ)」とは、文脈によって意味が異なりますが、数学では**集合の「元の個数」を指し、IT分野では主にデータベースのテーブルカラムに含まれる一意な値の数(バリエーション)**を指します。IT分野では、この一意な値の数が多ければ「高カーディナリティ」、少なければ「低カーディナリティ」と表現されます。
ざっくり言うと、カーディナリティ=「値の種類の多さ」(=ユニーク数)。文脈で意味が少し変わるけど、基本的な意味は同じ。
代表的な文脈
-
集合論
集合の要素数のこと(|A|)。有限/無限(可算/非可算)とかの話。 -
データベース(列のカーディナリティ)
その列に「異なる値がいくつあるか」。
例:genderは低(数個)、zip_codeは中、uuidは激高。
インデックスの効きや選択性に関わる。SELECT COUNT(DISTINCT user_id) FROM events; -- 列のカーディナリティ -
データベース(リレーションのカーディナリティ)
エンティティ間の関係の多重度。1:1 / 1:N / N:M。
N:M は中間テーブルで切る、が基本。 -
メトリクス/ログ(観測基盤)
ラベル(タグ)の組み合わせ数。高すぎると“爆発”(メモリ/コスト地獄)。
例:
http_requests_total{path,method,status}はまだ良いが、path="/users/12345"みたいに IDを直入れすると実質無限に増える。
対策:IDは入れない/正規化(/users/:id)、サンプリング、集約。
いつ気にすべき?
- クエリが遅い → 列のユニーク数とインデックス設計を見直す
- TSDB/ログ費用が膨らむ → ラベル設計を見直す(“ユーザーIDをラベルに入れるな”は鉄則)
高カーディナリティとは
カーディナリティは「一意の値がどれだけ存在するか」の尺度。
例えば、以下のような話はカーディナリティの視点で考えることができる。
- DB の特定のテーブルのカラムに一意の値がどれだけ存在するか
- タグのラベルの種類がどれだけあるか
DB の例において、DB の特定のテーブルのカラムが ID 系のカラムであり、UUIDv4 や連番を使用している場合、基本的には全ての値が異なるので「高カーディナリティ」である。
OpenTelemetry においてなぜ「高カーディナリティ」が良くないのか
OpenTelemetry、というか分散トレースの文脈で言うと、スパン名の設定においてカーディナリティが重要となる。
基本的に、スパン名は SDK でスパンを作成するときに指定するが、RPC メソッド名、関数名など処理を簡潔に表す名前を指定することが望ましい。また、汎用的・一般的であるべき。get_user はふさわしい名称だが、get_user/12345 はカーディナリティが高いため(一般的ではなくなるため)避けるべき。

なぜかというと、スパン名は“集計キー”だから、動的値を混ぜると地獄(=指数的な系列増・検索劣化・コスト爆増)になる。
OTel 公式も「低カーディナリティで名付けろ」と言及している。(OpenTelemetry)
何が困るの?
-
メトリクスが爆発
多くの基盤はトレース→メトリクス変換でspan_nameをラベルに使う(例: Tempo の span metrics)。get_user/12345みたいに毎回違う名前だと、タイムシリーズが雪崩る=メモリ/保存量/料金が跳ね上がる。(Grafana Labs, Coralogix) -
検索性と可視化が死ぬ
高カーディナリティはクエリ時の走査量を増やし、UI でのグルーピング(「この操作ごとのレイテンシ」)が崩壊する。運用者は“同じ操作”で固めて見たいのに、毎回別名だと比較不能。(Grafana Labs) -
パイプライン・サンプリングが組みにくい
Collector 側の集計やポリシーは span.name で束ねることが多い。名前が毎回ユニークだと、ルールが効かない/読みにくい設定になる。公式 Issue でも「高カーディナリティなスパン名はパイプラインで問題」と明言。(GitHub)
どう名付けるべき?
-
HTTP:
{method} {http.route}(テンプレート化したルート)。
例:GET /users/:id(※実 ID は属性 attributeに入れる)。GET /users/123は NG。(OpenTelemetry) -
DB:
INSERT mydb.usersや{db.operation} {db.name}.{table}のように操作×対象で固定化。値は入れない。(OpenTelemetry)
ルール:スパン名=操作の“型”、個別の“値”は**属性(tags)**へ。
すでに名前がバラけてる場合の手当
-
アプリ側で直す:フレームワークのルートテンプレート(
/users/:id)を使ってスパン名を固定化し、user.idやhttp.targetに実値を載せる。(OpenTelemetry) -
Collector で後処理:
transformプロセッサでnameをhttp.routeから再構成、あるいはパス中の数値/UUIDをテンプレ化(:id)する。公式が「スパン名を属性から組み立ててよし」と明記。(OpenTelemetry) -
Span→Metrics の次元を絞る:
spanmetrics連携時は、維持するディメンションを厳選(service/span_name/status_codeなど)し、ベンダー実装のカーディナリティ制御や置換機能があれば活用。(Grafana Labs)
チェックリスト(自動レビュー用)
- そのスパン名は1万回呼ばれても同じか?→NO なら設計ミス。(OpenTelemetry)
- その名前で**「操作ごとのレイテンシ」**を素直に集計できるか?→できないなら、値を外して属性へ。(Grafana Labs)
――まとめ:“GET /users/:id” は OK、“GET /users/12345” は財布にクリティカルヒット。
名前は汎用・低カーディナリティ、値は属性。これがトレーシングの作法。(OpenTelemetry, Grafana Labs)
高カーディナリティによって請求が高額になった例