めも:Rust の練習帳
リポジトリ
環境
macOS 組み込みの Bash(/bin/bash)、ではなくミラーリポジトリのマイナーバージョンまで合致している Bash をインストールした。
$ /bin/bash --version
GNU bash, version 3.2.57(1)-release (arm64-apple-darwin23)
Copyright (C) 2007 Free Software Foundation, Inc.
$ /opt/homebrew/bin/bash --version
GNU bash, version 5.2.26(1)-release (aarch64-apple-darwin23.2.0)
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
参考
- bash リポジトリのミラー
- https://github.com/bminor/bash
- C 製なんだね
後で調べる
-
#[derive(Debug)]などの属性ってどういう仕組み? - Rust のテストランナーの挙動
-
#[test]ってどういう仕組みだっけ?テスト対象の関数をどうやって見つけて(テストディスカバリ)どうやって実行してるんだっけ? - テストの並列化はどうやってやるの?
-
-
whichコマンドで、ビルトインコマンドと外部コマンドを引数に与えた時の挙動の違いはどうな
ビルトインコマンドと外部コマンド
by ChatGPT
ビルトインコマンド以外の、brew(macOSのHomebrew)などの外部コマンドのことは一般的に「外部コマンド」または「ユーティリティ」と呼びます。
ビルトインコマンドと外部コマンドの違い
-
ビルトインコマンド:
- シェル(例:Bash、Zsh、Fishなど)自体に組み込まれているコマンドです。
- 例:
cd,echo,alias,export,historyなど。
-
外部コマンド:
- シェルに組み込まれていない、外部のプログラムやスクリプトとして実行されるコマンドです。
- シェルが実行ファイルを検索して見つけ、子プロセスとして実行します。
- 例:
brew,git,curl,ls,grepなど。
例
-
brewは Homebrew のパッケージマネージャとして外部コマンドの例です。Homebrew自体はシェルの一部ではなく、独立したプログラムです。 -
lsはファイルリストを表示するUnix系のコマンドで、これも外部コマンドです。
使用例
シェルを使用する際には、ビルトインコマンドと外部コマンドの区別が重要です。例えば、ビルトインのechoコマンドはシェルが直接処理しますが、brewコマンドはシェルがbrewという実行ファイルを検索し、それを実行します。
まとめ
Homebrewのbrewなど、シェルに組み込まれていないコマンドを指す場合は「外部コマンド」と呼びます。外部コマンドはシェルがファイルシステム上で実行ファイルを検索し、それを子プロセスとして実行するものです。
which コマンドの挙動
- ビルトインコマンド
- シェルに組み込まれているため、特定のディレクトリには配置されない。シェルの内部で直接利用される。
- 外部コマンド
- システムの基本的なユーティリティとして提供されるため、通常は
/bin,/usr/bin,/usr/local/binなどのディレクトリに配置される。
- システムの基本的なユーティリティとして提供されるため、通常は
bash-5.2$ which echo
/bin/echo
bash-5.2$ which ls
/bin/ls
bash-5.2$ which brew
/opt/homebrew/bin/brew
bash-5.2$ type echo
echo is a shell builtin
bash-5.2$ type ls
ls is /bin/ls
bash-5.2$ type brew
brew is /opt/homebrew/bin/brew
type コマンドとは
type コマンドは、指定したコマンドがビルトインコマンド、外部コマンド、エイリアス、シェル関数など、引数で与えられたコマンドがどのような種類のコマンドであるかを表示するために使用されるコマンド**。type コマンドは、シェルが指定されたコマンドをどのように解釈するかを確認するのに役立つ。
- ビルトインコマンドの場合
bash-5.2$ type echo
echo is a shell builtin
- 外部コマンドの場合
bash-5.2$ type ls
ls is /bin/ls
bash-5.2$ type brew
brew is /opt/homebrew/bin/brew
-a オプションを使用すると、システム内の同じ名前のコマンドを全て表示する。このとき、ビルトインと外部コマンドの両方を含む。
例えば、echo コマンドは、Bash などのシェルではビルトインコマンドとしても存在するが、システムの基本的なユーティリティとして外部コマンド(例えば /bin/echo)としても存在するため、2 つ表示される。一方、ls コマンドは、システムの基本的なユーティリティとしての外部コマンドのみ存在し、Bash には組み込まれていないため、外部コマンドの表示のみになる。
bash-5.2$ type -a echo
echo is a shell builtin
echo is /bin/echo
bash-5.2$ type -a ls
ls is /bin/ls
ちなみにシステム内にコマンドが見つけられないと not found を返す。
bash-5.2$ type lss
bash: type: lss: not found
echo コマンドについて、which echo の結果と type echo の結果が矛盾してない?which コマンドの結果は外部コマンドだけど、type コマンドの結果はビルトインコマンドだと示しているよ。
なるほど、自分の理解が足りなかった。which コマンドはそもそも PATH を見て外部コマンドを検索するためのコマンドだったのか。PATH がそもそも外部コマンドを検索するための環境変数だったのか。ただ「コマンド」としてしか理解できてなかった。
- コマンド
- ビルトインコマンド
- 外部コマンド
- シェル関数
- alias
ご指摘の通り、echo コマンドについて which echo と type echo の結果が異なることがあります。これは which コマンドと type コマンドがコマンドの検索方法や表示方法が異なるためです。
which コマンド
which コマンドは、指定されたコマンドがシステムのどこにあるかを表示します。具体的には、環境変数 PATH に設定されたディレクトリを順に検索し、最初に見つかった実行可能ファイルのパスを表示します。which コマンドは外部コマンドの検索に特化しています。
$ which echo
/bin/echo
この結果は、/bin/echo という外部コマンドが存在することを示しています。
type コマンド
type コマンドは、指定されたコマンドがビルトインコマンド、外部コマンド、エイリアス、シェル関数のいずれであるかを表示します。type コマンドは、シェルが実際にどのようにそのコマンドを解釈するかを示します。
$ type echo
echo is a shell builtin
この結果は、シェルが echo をビルトインコマンドとして扱っていることを示しています。
なぜ結果が異なるのか
-
whichコマンド:- 外部コマンドを探してそのパスを表示します。
-
echoのようなコマンドは、外部コマンドとして存在する場合、そのパスを表示します。
-
typeコマンド:- コマンドがビルトインコマンド、エイリアス、シェル関数、または外部コマンドのどれであるかを表示します。
- ビルトインコマンドが存在する場合、シェルはそれを優先的に使用するため、
type echoはecho is a shell builtinと表示します。
具体的な例
$ which echo
/bin/echo
$ type echo
echo is a shell builtin
この例では、シェルの echo コマンドはビルトインコマンドとして定義されていますが、/bin/echo という外部コマンドも存在します。シェルはビルトインコマンドを優先するため、実際にはビルトインの echo が使用されます。
まとめ
which と type の結果が異なる理由は、which が外部コマンドのみを検索するのに対し、type がシェルの内部でどのようにコマンドが定義されているかを示すためです。シェルがビルトインコマンドを持つ場合、type はそれを示しますが、which は外部コマンドのパスを表示します。この違いを理解することで、シェルの動作を正確に把握することができます。
では、名前解決はどのように行われる?
名前解決の順序としては、ビルトインコマンドが優先される。
- ビルトインコマンドを探す。見つかれば実行する。
- ビルトインコマンドが存在しなければ、環境変数
PATHを参照し、一番はじめに見つかった外部コマンドを実行する。
せっかくなので Bash のソースコードからコマンドの名前解決するところを見てみる
おそらく以下のような感じになってるはず。
- 入力を受け取る
- 入力をパースする
- コマンドを実行する
- ビルトインコマンドを探す。見つかれば実行する。
- ビルトインコマンドが存在しなければ、環境変数 PATH を参照し、一番はじめに見つかった外部コマンドを実行する。
ソースコードのビルド
gh repo clone ...
cd ./bash
./configure
#...
# configure: creating ./config.status
# config.status: creating Makefile
# config.status: creating builtins/Makefile
# config.status: creating lib/readline/Makefile
# config.status: creating lib/glob/Makefile
# config.status: creating lib/intl/Makefile
# config.status: creating lib/malloc/Makefile
# config.status: creating lib/sh/Makefile
# config.status: creating lib/termcap/Makefile
# config.status: creating lib/tilde/Makefile
# config.status: creating doc/Makefile
# config.status: creating support/Makefile
# config.status: creating po/Makefile.in
# config.status: creating examples/loadables/Makefile
# config.status: creating examples/loadables/Makefile.inc
# config.status: creating examples/loadables/Makefile.sample
# config.status: creating examples/loadables/perl/Makefile
# config.status: creating support/bash.pc
# config.status: creating support/bashbug.sh
# config.status: creating config.h
# config.status: executing po-directories commands
# config.status: creating po/POTFILES
# config.status: creating po/Makefile
# config.status: executing stamp-h commands
とりあえず Makefile が生成された。あとは make するだけ。その前に Makefile の構造をざっと眺める。
- エントリーポイント:
all: .made
# Make sure the first target in the makefile is the right one
all: .made
.made
.made: $(Program) bashbug $(SDIR)/man2html$(EXEEXT)
@echo "$(Program) last made for a $(Machine) running $(OS)" >.made
$(Program): $(OBJECTS) $(BUILTINS_DEP) $(LIBDEP) .build
$(RM) $@
$(PURIFY) $(CC) $(BUILTINS_LDFLAGS) $(LIBRARY_LDFLAGS) $(LDFLAGS) -o $(Program) $(OBJECTS) $(LIBS)
ls -l $(Program)
-$(SIZE) $(Program)
make コマンドを実行すると、all ターゲットから .made ターゲットが呼び出され、$(Program) ターゲットがビルドされる。$(Program) ターゲットのビルドが完了すると、.made ファイルが生成される。
make を実行してみる。
make &> log.txt
ログを見ると、最後の方に bash をビルドし、man ページを生成しているのがわかる。
gcc -L./builtins -L./lib/readline -L./lib/readline -L./lib/glob -L./lib/tilde -L./lib/sh -g -O2 -o bash shell.o eval.o y.tab.o general.o make_cmd.o print_cmd.o dispose_cmd.o execute_cmd.o variables.o copy_cmd.o error.o expr.o flags.o jobs.o subst.o hashcmd.o hashlib.o mailcheck.o trap.o input.o unwind_prot.o pathexp.o sig.o test.o version.o alias.o array.o arrayfunc.o assoc.o braces.o bracecomp.o bashhist.o bashline.o list.o stringlib.o locale.o findcmd.o redir.o pcomplete.o pcomplib.o syntax.o xmalloc.o -lbuiltins -lglob -lsh -lreadline -lhistory -ltermcap -ltilde lib/intl/libintl.a -liconv -Wl,-framework -Wl,CoreFoundation -liconv -ldl
# ld: warning: ignoring duplicate libraries: '-liconv'
ls -l bash
# -rwxr-xr-x 1 nukopy staff 1345288 May 29 05:37 bash
size bash
# __TEXT __DATA __OBJC others dec hex
# 901120 81920 0 4295393280 4296376320 100158000
rm -f man2html.o
gcc -c -DHAVE_CONFIG_H -DSHELL -I/Users/nukopy/Projects/OSS/bash -I.. -Wno-parentheses -Wno-format-security -DMACOSX -I/opt/homebrew/opt/openjdk@17/include -g -O2 man2html.c
gcc -g -O2 man2html.o -o man2html -ldl
ビルドした bash のバージョンを確認し、起動した。できた。
$ ./bash --version
GNU bash, version 5.2.26(1)-release (aarch64-apple-darwin23.4.0)
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
$ ./bash
bash-5.2$
echo コマンドの名前解決の仕組みをソースコードで見てみる
おそらく以下のような感じになってるはず。echo ならビルトインコマンドが実行され、ls なら外部コマンドが実行されることを確認したい。
- Bash の起動
- 対話モード(REPL)の起動 → 3 ~ 5 のループ
- 入力を受け取る
- 入力をパースする
- コマンドを実行する
- ビルトインコマンドを探す。見つかれば実行する。
- ビルトインコマンドが存在しなければ、環境変数
PATHを参照し、一番はじめに見つかった外部コマンドを実行する。
エントリーポイント:shell.c
shell.c の main 関数が Bash のエントリーポイント。
-
やってること
- コマンドライン引数の解析
- 起動ファイルの読み込み
- 対話モード初期化
- 対話モード開始
-
shell.c:main
main 関数内の reader_loop 関数を実行しているところ(L833)が対話モードを開始しているところ。
対話モードにおけるコマンドの解釈: eval.c の reader_loop() 関数
見たいのはコマンドの名前解決部分なので、reader_loop() 関数の中身を見ていく。reader_loop 関数は eval.c に定義されている。eval.c は、ソースコード 1 行目のコメントにもあるように、コマンドを読み、評価するモジュールである。
-
eval.c:reader_loop
reader_loop関数は、シェルの対話モードにおける主要な動作を制御している。この関数は、ユーザーからのコマンド入力を受け付け、それをパース(解析)し、実行し、そして再び入力を受け付ける、という一連の流れを while ループで繰り返す。
以下に、その主要なステップを抽出する:
-
コマンド入力の受け付け
- このステップは、
reader_loop関数のwhile (EOF_Reached == 0)ループが始まるところから始まる。このループは、EOF(End Of File、つまり入力の終わり)が検出されるまで繰り返される。つまり、ユーザからの新しいコマンド入力を待ち続ける。
- このステップは、
-
コマンドのパース(解析)
- このステップは、
read_command()関数の呼び出しによって行われる。この関数は、ユーザーからの入力を読み込み、それをパース(解析)してコマンドとしての形式に変換する。パースされたコマンドは、current_command = global_command行によってcurrent_command変数に格納される。
- このステップは、
-
コマンドの実行
- このステップは、
execute_command(current_command)関数の呼び出しによって行われる。この関数は、パースされたコマンド(current_command変数に格納されている)を実行する。
- このステップは、
-
コマンドの実行結果の処理 & 次の入力の準備
-
execute_command関数の実行結果(つまり、実行されたコマンドの終了ステータス)は、last_command_exit_valueというグローバル変数に格納される。 - そして再度入力受け付けモードに移る前に、
QUITマクロが呼び出される。このマクロは、シェルが終了するべきかどうかをチェックする。具体的には、last_command_exit_valueが非ゼロ(つまり、直前のコマンドがエラーで終了した)場合、シェルは終了する。 - その後、
dispose_command関数が呼び出されてcurrent_commandが解放され、再び入力を受け付ける状態に戻る。
execute_command (current_command); exec_done: QUIT; if (current_command) { dispose_command (current_command); current_command = (COMMAND *)NULL; } ...- このコードは、
execute_commandの実行結果を処理し、次のコマンド入力を待つための準備を行っている。
-
-
再び入力受付モードへ
- コマンドの実行が終わると、
reader_loop関数は再びwhile (EOF_Reached == 0)ループの先頭に戻り、新たなコマンド入力の受け付けを開始する。
- コマンドの実行が終わると、
以上が、reader_loop関数における主要なステップである。この関数は、シェルの対話モードにおける基本的な動作を制御する。
Q. あれ、でも終了ステータスがエラーでもシェルの対話モードって終わらなくない?ここでの last_command_exit_value っていうのは終了ステータス(POSIX なら 0 が成功、1 ~ 255 がエラー)とは違うの?
last_command_exit_valueは、最後に実行されたコマンドの終了ステータスを保持します。これはPOSIXの規定に従い、0が成功を示し、1から255までの値がエラーを示します。シェルの対話モードでは、コマンドがエラーで終了したとしてもシェル自体は終了しません。しかし、シェルスクリプトの中で
set -eオプションが設定されている場合(これはerrexitオプションとも呼ばれます)、エラーで終了したコマンドが実行されるとシェルスクリプト全体が終了します。したがって、
last_command_exit_valueが非ゼロ(エラー)である場合でも、シェルの対話モードは終了しません。ただし、シェルスクリプト内でエラーが発生した場合、その挙動はスクリプトがset -eを設定しているかどうかによります。
たしかに以下のシェルスクリプトを実行したらシェルが終了した。
set -e
lss # 存在しないコマンド
Q. そっか対話モードだけでなく、単純にシェルスクリプトのインタプリタとして動作するモードもあるのか。
はい、その通りです。シェルは対話モードだけでなく、シェルスクリプトのインタプリタとしても動作します。対話モードでは、ユーザーからの入力を受け付けてコマンドを実行します。一方、シェルスクリプトのインタプリタとして動作する場合、シェルスクリプトファイルを読み込み、その中に書かれたコマンドを順に実行します。
具体的には、シェルを起動する際にシェルスクリプトファイルを引数として渡すと、シェルはそのファイルを読み込み、ファイル内のコマンドを順に実行します。このとき、シェルは対話モードではなく、非対話モードで動作します。
例えば、次のようにシェルを起動すると、
script.shというシェルスクリプトを実行します。bash script.shこの
script.shファイル内には、実行したいコマンドが順番に書かれています。シェルはこれらのコマンドを上から順に実行し、スクリプトの最後まで到達したら終了します。
コードよくみると、reader_loop 内でインタラクティブシェルかどうかのフラグで処理を分岐している部分があるね。
std::process::Command
Command.new("ls") という初期かメソッドを実行したときにはコマンドは実行されず、Command.output()、Command.status()、Command.spawn() が実行されたときにコマンドが実行される。
std::process::Command.output() の中身
※UNIX 系 OS、特に macOS 前提で進める
-
std::process::Command.output()(共通の実装process.rs)-
std::process::Command.inner.output()(共通の実装process.rs)-
std::process_unix::Command.output()(ここで各 OS の実装に飛ぶ。process_unix.rs)std::process_unix::Command.spawn()
-
-
std::process_unix::Command.spawn() の中で何が行われているか?
- 親プロセス(
std::process::Command::new("some cmd")を呼んだプロセス)、子プロセス("some cmd"を実行するために fork で生成されるプロセス)の標準入出力のオブジェクトを取得する:std::process_common::Command.setup_io()- 子プロセスのコマンドを実行するとき、コマンドの結果を取得するためにここで取得した子プロセスの標準入出力を使用する
- プロセスのフォーク:
std::process_unix::Command.do_fork()(中でlibc::fork()を呼んでいる)impl Command { unsafe fn do_fork(&mut self) -> Result<pid_t, io::Error> { cvt(libc::fork()) } - jjj
- j
std::process::ExitCode と std::process::ExitStatus の違い
どちらもプロセスの終了状態を扱うための API。以下、公式ドキュメントより引用:
Differences from
ExitStatus
ExitCodeis intended for terminating the currently running process, via theTerminationtrait, in contrast toExitStatus, which represents the termination of a child process. These APIs are separate due to platform compatibility differences and their expected usage; it is not generally possible to exactly reproduce anExitStatusfrom a child for the current process after the fact.
引用元:https://doc.rust-lang.org/std/process/struct.ExitCode.html#differences-from-exitstatus
ExitStatusとの違い
ExitCodeは、Terminationトレイトを介して現在実行中のプロセスを終了させることを目的としています。これに対して、ExitStatusは子プロセスの終了状態を表します。これらの API はプラットフォーム互換性の違いや使用目的の違いから分けられています。現在のプロセスの終了状態として子プロセスのExitStatusを正確に再現することは一般的にできません。
日本語訳 by ChatGPT 4o
現在のプロセスの終了状態として子プロセスの
ExitStatusを正確に再現することは一般的にできません。
ここがまだ理解できない。
std::process::ExitCode
ExitCode は、現在実行中のプロセスの終了コードを表す。これは、Rust プログラムが終了するときに特定の終了コードを返すために使用される。
- 目的:現在実行中のプロセスを終了させるためのコードを表す
-
使用例:
std::process::exit関数やTerminationトレイトを実装する際に使用される
例:
use std::process::ExitCode;
fn main() -> ExitCode {
// プロセスの終了コードとして 1 を返す
ExitCode::from(1)
}
std::process::ExitStatus
ExitStatus は、(現在実行中の親プロセスの)子プロセスの終了状態を表す。これは、Rust プログラムが子プロセスを生成し、そのプロセスが終了したときの状態を取得するために使用される。
- 目的:子プロセスの終了状態を表す
-
使用例:
std::process::Commandを使って子プロセスを生成し、そのプロセスが終了した後の状態を取得するために使用される
例:
use std::process::Command;
fn main() {
let status = Command::new("ls")
.status()
.expect("failed to execute process");
if status.success() {
println!("Process exited successfully");
} else {
println!("Process exited with error code: {:?}", status.code());
}
}
違いの詳細
公式ドキュメントの記述にある通り、ExitCode と ExitStatus には以下のような違いがある。
- 使用目的の違い
-
ExitCodeは、現在実行中のプロセスを終了させるために使用される。主に、Rust プログラム自体が終了コードを返す場合に使用される。 -
ExitStatusは、子プロセスの終了状態を表す。これは、親プロセスが子プロセスを生成し、その終了状態を取得して処理するために使用される。
-
- API の分離
- これらの API は、プラットフォーム互換性の違いや使用方法の違いにより分離されている。現在のプロセスの終了コードを子プロセスの終了コードとして再現することは一般的にできない。例えば、システムによっては、現在のプロセスの終了コードを直接取得する方法が異なるためである。
- 実装の違い
-
ExitCodeは、現在のプロセスの終了に特化しており、Rust のTerminationトレイトを介して使用される -
ExitStatusは、子プロセスの終了状態を詳細に扱うために設計されており、標準ライブラリのCommand構造体を使用して生成されたプロセスの終了状態を取得する
-
まとめ
-
ExitCode:現在のプロセスの終了コードを表し、プログラムの終了時に使用される -
ExitStatus:子プロセスの終了状態を表し、親プロセスが子プロセスの終了状態を取得して処理するために使用される
これらの API は異なる目的で使用され、プラットフォーム互換性や使用方法の違いから明確に分けられている。
Q
この文章もうちょっとわかりやすく解説して。
現在のプロセスの終了状態として子プロセスのExitStatusを正確に再現することは一般的にできません。
A
以下 ChatGPT の解答
子プロセスの ExitStatus を、現在のプロセスの終了状態として正確に再現することができない理由は、いくつかの技術的な制約とプラットフォーム依存の違いに起因します。以下にその主要な理由を挙げます。
プラットフォーム依存の違い
-
終了状態の情報の違い:
- 子プロセスが終了すると、その終了状態は親プロセスに通知されますが、終了状態にはプラットフォームごとに異なる情報が含まれることがあります。例えば、Unix系システムではプロセスの終了コードに加えて、シグナルによる終了情報も含まれますが、Windowsでは異なるメカニズムが使われます。
- これにより、子プロセスの
ExitStatusを現在のプロセスの終了状態として正確に再現することが難しくなります。
現在のプロセスの終了状態の制御
-
直接的な終了制御:
-
ExitCodeは現在のプロセスが終了する際に設定するものです。現在のプロセスの終了状態を設定するには、通常はstd::process::exitを使います。この関数はプロセスの終了コードを直接設定しますが、子プロセスのExitStatusに含まれる詳細な情報(例えば、シグナル情報など)をそのまま反映することはできません。
-
-
プロセス管理の違い:
- Rustでは、現在のプロセスと子プロセスの終了管理には異なるAPIが提供されています。
ExitCodeは現在のプロセス専用であり、ExitStatusは子プロセス専用です。これらのAPIは、プラットフォームの互換性や使用目的に応じて分けられており、現在のプロセスが終了する際に子プロセスの終了情報を正確に模倣することは設計上想定されていません。
- Rustでは、現在のプロセスと子プロセスの終了管理には異なるAPIが提供されています。
実装の例
現在のプロセスの終了(ExitCode)
use std::process::ExitCode;
fn main() -> ExitCode {
// 現在のプロセスを終了コード1で終了
ExitCode::from(1)
}
子プロセスの終了(ExitStatus)
use std::process::Command;
fn main() {
let status = Command::new("ls")
.status()
.expect("failed to execute process");
if status.success() {
println!("Process exited successfully");
} else {
println!("Process exited with error code: {:?}", status.code());
}
}
まとめ
-
プラットフォーム依存の違い: プロセスの終了状態にはプラットフォームごとに異なる情報が含まれるため、子プロセスの
ExitStatusを現在のプロセスの終了状態として正確に再現することは難しいです。 -
現在のプロセスと子プロセスの終了制御の違い:
ExitCodeとExitStatusはそれぞれ異なる目的と制御メカニズムを持つため、設計上これらを混同して使用することはできません。
これらの理由から、子プロセスの ExitStatus をそのまま現在のプロセスの終了状態として再現することは一般的にできないのです。
なるほど、ExitCode では ExitStatus は再現できないよってことか。
はい、その通りです。ExitCodeではExitStatusを再現できない理由は以下の通りです。
詳細な説明
-
ExitCode: 現在のプロセスを終了させるためのコードです。これは、Rustプログラムが終了するときに特定の終了コードを返すために使用されます。シンプルに終了コードを設定するためのAPIです。 -
ExitStatus: 子プロセスが終了したときの詳細な終了状態を表します。これは、終了コードに加えて、例えばシグナルによる終了などの詳細な情報も含むことができます。ExitStatusは、子プロセスの終了状態を詳細に知るためのAPIです。
再現の難しさ
-
プラットフォーム固有の情報:
ExitStatusにはプラットフォーム固有の詳細情報が含まれています。例えば、Unix系システムではシグナルによる終了情報などが含まれますが、これを現在のプロセスの終了状態として再現することは難しいです。 -
APIの目的の違い:
ExitCodeは現在のプロセスの終了を簡潔に表すためのものであり、ExitStatusのような詳細な情報を再現することを目的としていません。これらのAPIは異なる目的で設計されているため、ExitCodeでExitStatusの詳細な情報を再現することはできません。
公式ドキュメントの要約
公式ドキュメントの記述を要約すると、以下のようになります。
-
違い:
ExitCodeは現在のプロセスの終了を表すためのものであり、ExitStatusは子プロセスの終了状態を表すものです。 - 分離の理由: これらのAPIは、プラットフォームの互換性の違いや使用目的の違いにより分けられています。
-
再現の困難さ: 一般的に、子プロセスの
ExitStatusを現在のプロセスの終了状態として後から再現することはできません。
具体的な例
以下は具体的な例です。
use std::process::{Command, ExitCode};
// 現在のプロセスの終了コードを設定
fn main() -> ExitCode {
// ここでは終了コード1を設定
ExitCode::from(1)
}
// 子プロセスの終了状態を取得
fn main() {
let status = Command::new("ls")
.status()
.expect("failed to execute process");
if status.success() {
println!("Process exited successfully");
} else {
println!("Process exited with error code: {:?}", status.code());
}
}
このように、ExitCodeとExitStatusは異なる目的で使用され、それぞれが異なる役割を果たしています。
chap01 done
chap2: echo
ユニット型
要素 0 のタプルを「ユニット」と呼ぶ。特に、ユニットを型として使用する場合は「タプル型」ではなく「ユニット型」と呼ぶ。
Rust では意味のある値を返す必要がないときはこのユニットを返す。例えば、スライスのインプレースソート slice::sort() では、新しいメモリ領域を確保せずに、直接元のメモリ領域が書き換えられるため、戻り値は必要ない(破壊的な操作)。
Sized トレイト
predicates というクレートを使っているときに Sized トレイトが出てきた。
predicates は組み合わせ可能な一階述語(ブール値を返す関数)を実装するライブラリ。
use predicates::prelude::*;
fn main() {
// 1. 個別の条件(述語)を作成する
let is_positive = predicate::function(|&x: &i32| x > 0);
let is_even = predicate::function(|&x: &i32| x % 2 == 0);
let less_than_100 = predicate::lt(100);
// 2. 条件を組み合わせて複雑な条件を構築する
// 条件:正かつ偶数かつ 100 未満
let complex_condition = is_positive.and(is_even).and(less_than_100);
// 3. eval メソッドで入力の評価を行う
println!(
"24 satisfies the condition: {}",
complex_condition.eval(&24)
);
println!(
"50 satisfies the condition: {}",
complex_condition.eval(&50)
);
println!(
"-6 satisfies the condition: {}",
complex_condition.eval(&-6)
);
println!(
"101 satisfies the condition: {}",
complex_condition.eval(&101)
);
// for ループで配列を使って評価する場合
let values = [24, 50, -6, 101];
for &value in &values {
println!(
"{} satisfies the condition: {}",
value,
complex_condition.eval(&value)
);
}
}
predicate::function という関数は関数やクロージャを引数に取り、独自の条件を実装することができる便利な関数。
定義
pub fn function<F, T>(function: F) -> FnPredicate<F, T>
where
F: Fn(&T) -> bool,
T: ?Sized,
{
FnPredicate {
function,
name: "fn",
_phantom: PhantomData,
}
}
例
use predicates::prelude::*;
// これは関数
fn is_greater_than_ten(x: i32) -> bool {
x > 10
}
fn main() {
// これはクロージャ
let closure = |&x: i32| x > 10;
// predicates::function でクロージャを使用
let pred_closure = predicate::function(|&x: i32| x > 10);
// predicates::function で関数を使用
let pred_function = predicate::function(is_greater_than_ten);
// クロージャは環境から値をキャプチャできる
let threshold = 15;
let dynamic_closure = |&x: i32| x > threshold;
println!("Is 12 > 10? {}", closure(&12));
println!("Predicate (closure) 12 > 10? {}", pred_closure.eval(&12));
println!("Predicate (function) 12 > 10? {}", pred_function.eval(&12));
println!("Is 12 > {}? {}", threshold, dynamic_closure(&12));
}
predicates::function の以下の部分に着目する。where 句はジェネリック型パラメータの制約を定義する部分。
pub fn function<F, T>(function: F) -> FnPredicate<F, T>
where
F: Fn(&T) -> bool,
T: ?Sized,
1 つずつジェネリック型パラメータの制約を見ていく。
F: Fn(&T) -> bool の解釈
F: Fn(&T) -> bool
- 解釈:「
Fは、&Tを引数に取りboolを返す関数トレイトを実装している」 -
Fnは関数トレイトの一つで、F がこのトレイトを実装していなければならないことを示している。 - 具体的には、
Fは&T型の引数を取り、bool型を返す呼び出し可能なもの(callable)でなければならない。
T: ?Sized の解釈
T: ?Sized
- 解釈:「
TはSizedトレイトを実装しているかもしれないし、していないかもしれない」 -
?Sizedは、通常暗黙的に要求されるSizedトレイトの制約を解除している。つまり、Tは固定サイズの型でも、動的サイズの型でも構わない。
まとめ
2 つの条件をまとめると、以下のような解釈になる。
-
predicates::function関数は、T型の参照を引数に取り、bool型を返す呼び出し可能なものFを受け取る。ただし、Tはサイズが静的に決まっている必要はない。
Sized トレイト
マーカートレイトの 1 つ。
定義
pub trait Sized {
// Empty.
}
- このトレイトは空である。メソッドや関連型を持たない。
- 「マーカートレイト」と呼ばれ、型の特性を示すためだけに使用される。
ポイント
- コンパイル時にサイズが分かる型に対して暗黙的に実装される
- 全ての型パラメータは、暗黙の
Sizedトレイト制約を持つ -
?Sizedを使用することで、このトレイト制約を解除できる(predicates::functionの型定義において、型パラメータTに対して定義されていたトレイト制約がこれ)
/// Types with a constant size known at compile time.
///
/// All type parameters have an implicit bound of `Sized`. The special syntax
/// `?Sized` can be used to remove this bound if it's not appropriate.
///
/// ```
/// # #![allow(dead_code)]
/// struct Foo<T>(T);
/// struct Bar<T: ?Sized>(T);
///
/// // struct FooUse(Foo<[i32]>); // error: Sized is not implemented for [i32]
/// struct BarUse(Bar<[i32]>); // OK
/// ```
///
/// The one exception is the implicit `Self` type of a trait. A trait does not
/// have an implicit `Sized` bound as this is incompatible with [trait object]s
/// where, by definition, the trait needs to work with all possible implementors,
/// and thus could be any size.
///
/// Although Rust will let you bind `Sized` to a trait, you won't
/// be able to use it to form a trait object later:
///
/// ```
/// # #![allow(unused_variables)]
/// trait Foo { }
/// trait Bar: Sized { }
///
/// struct Impl;
/// impl Foo for Impl { }
/// impl Bar for Impl { }
///
/// let x: &dyn Foo = &Impl; // OK
/// // let y: &dyn Bar = &Impl; // error: the trait `Bar` cannot
/// // be made into an object
/// ```
///
/// [trait object]: ../../book/ch17-02-trait-objects.html
#[doc(alias = "?", alias = "?Sized")]
#[stable(feature = "rust1", since = "1.0.0")]
#[lang = "sized"]
#[diagnostic::on_unimplemented(
message = "the size for values of type `{Self}` cannot be known at compilation time",
label = "doesn't have a size known at compile-time"
)]
#[fundamental] // for Default, for example, which requires that `[T]: !Default` be evaluatable
#[rustc_specialization_trait]
#[rustc_deny_explicit_impl(implement_via_object = false)]
#[rustc_coinductive]
pub trait Sized {
// Empty.
}
T: ?Sized という型パラメータのトレイト制約はどういう目的で使える?
(Claud 3.5 Sonnet に聞いた)
?Sized の役割と predicates::function における使用について詳しく説明する。
?Sized の役割と有用性
- 動的サイズ型の取り扱い:
-
?Sizedを使用することで、コンパイル時にサイズが決まらない型(動的サイズ型)を扱えるようになります。 - 例:文字列スライス (
str)、配列スライス ([T])、トレイトオブジェクト (dyn Trait)
-
- 汎用性の向上:
- より多くの型に対応できるため、関数やデータ構造の汎用性が高まります。
- 柔軟な API 設計:
- ライブラリ作成時に、より広範な型に対応できる API を設計できます。
predicates::function における ?Sized の重要性:
pub fn function<F, T>(function: F) -> FnPredicate<F, T>
where
F: Fn(&T) -> bool,
T: ?Sized,
この定義により、predicates::function は以下のような利点を得ている:
- スライスや文字列に対する述語の作成:
-
[T]やstrのような動的サイズ型に対する述語を作成できる
-
- トレイトオブジェクトに対する述語:
-
dyn Traitのようなトレイトオブジェクトに対する述語も作成可能
-
- 将来の拡張性:
- 新しい動的サイズ型が導入された場合でも、既存のコードは変更なしで対応できる
具体例
use predicates::prelude::*;
fn main() {
// 固定サイズ型(i32)に対する述語
let is_positive = predicate::function(|&x: &i32| x > 0);
println!("Is 5 positive? {}", is_positive.eval(&5));
// 動的サイズ型(文字列スライス)に対する述語
let is_hello = predicate::function(|s: &str| s == "hello");
println!("Is 'hello' hello? {}", is_hello.eval("hello"));
// 動的サイズ型(配列スライス)に対する述語
let has_three_elements = predicate::function(|slice: &[i32]| slice.len() == 3);
println!("Does [1, 2, 3] have 3 elements? {}", has_three_elements.eval(&[1, 2, 3]));
// トレイトオブジェクトに対する述語
trait Printable {
fn to_string(&self) -> String;
}
impl Printable for i32 {
fn to_string(&self) -> String {
format!("Number: {}", self)
}
}
let is_long_string = predicate::function(|p: &dyn Printable| p.to_string().len() > 10);
println!("Is 12345 a long string? {}", is_long_string.eval(&12345 as &dyn Printable));
}
このコードでは:
-
is_positiveは固定サイズ型i32に対する述語 -
is_helloは動的サイズ型strに対する述語 -
has_three_elementsは動的サイズ型[i32](整数のスライス)に対する述語 -
is_long_stringはトレイトオブジェクトdyn Printableに対する述語
これらの例は全て、?Sized 制約があるからこそ可能になっています。もし T: Sized が要求されていたら、2, 3, 4の例は機能しない。
結論として、?Sized を使用することで、predicates::function は非常に柔軟で汎用的な API を提供できています。これにより、ユーザーは様々な型の値に対して述語を作成でき、ライブラリの適用範囲が大きく広がっています。
逆に Sized は一般にどのように役に立っているの?
(こちらも Claude 3.5 Sonnet に聞いてみた)
Sized トレイトは、Rust の型システムにおいて非常に重要な役割を果たしている。その主な利点と役割について説明する。
- コンパイル時のメモリレイアウトの決定:
-
Sizedな型は、コンパイル時に正確なサイズが分かる - これにより、コンパイラは効率的なメモリ割り当てと最適化を行える
-
- スタック割り当て:
-
Sizedな型はスタック上に直接割り当てることができる - これはヒープ割り当てよりも高速で、メモリ管理のオーバーヘッドが少なくなる
-
- 配列やベクタの要素として使用可能:
-
Sizedな型のみが、配列やベクタの要素として直接使用できる
-
- 値渡し:
-
Sizedな型は値渡しが可能。これは特に小さな型で効率的。
-
- ジェネリック型の制約:
- デフォルトで、ジェネリック型パラメータは
Sizedであることが要求される。 - これにより、多くの一般的な操作(値のコピーなど)が安全に行える。
- デフォルトで、ジェネリック型パラメータは
- コンパイラの最適化:
-
Sizedな型に対しては、より多くのコンパイラ最適化が適用できる。
-
具体例:
use std::mem;
// Sizedな型
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
// ?Sizedな型
trait Shape {
fn area(&self) -> f64;
}
fn main() {
// 1. コンパイル時のサイズ決定
println!("Size of Point: {} bytes", mem::size_of::<Point>());
// 2. スタック割り当て
let point = Point { x: 1, y: 2 };
println!("Point on stack: {:?}", point);
// 3. 配列の要素として使用
let points = [Point { x: 0, y: 0 }, Point { x: 1, y: 1 }];
println!("Array of Points: {:?}", points);
// 4. 値渡し
fn print_point(p: Point) {
println!("Received Point: {:?}", p);
}
print_point(point);
// 5. ジェネリック関数
fn generic_sized<T: Sized>(value: T) {
println!("Size of generic value: {} bytes", mem::size_of_val(&value));
}
generic_sized(point);
// 対照的に、?Sizedな型の扱い
let circle = Circle { radius: 5.0 };
let shape: &dyn Shape = &circle;
// 以下はコンパイルエラー:
// let shapes = [shape, shape]; // ?Sizedな型は配列の要素になれない
// generic_sized(shape); // ?Sizedな型はTに直接渡せない
println!("Area of shape: {}", shape.area());
}
struct Circle {
radius: f64,
}
impl Shape for Circle {
fn area(&self) -> f64 {
std::f64::consts::PI * self.radius * self.radius
}
}
この例で示されている Sized の利点:
-
Point構造体のサイズをコンパイル時に決定できる -
Pointはスタック上に直接割り当てられる -
Pointの配列を簡単に作成できる -
Pointを値渡しで関数に渡せる -
Sizedな型に対してジェネリック関数を使用できる
対照的に、?Sized な dyn Shape (トレイトオブジェクト)は:
- 配列の要素として直接使用できない
- 値渡しで関数に渡せない(参照経由でのみ可能)
-
Sizedを要求するジェネリック関数に直接渡せない
これらの特性により、Sized トレイトは Rust のパフォーマンスと型安全性に大きく貢献している。コンパイラが型のサイズを知ることで、より効率的なコードを生成し、多くの一般的なプログラミングパターンを安全に使用できるようになる。
一方で、?Sized の柔軟性も重要。これにより、動的ディスパッチやヘテロジニアスなコレクション(=異なる型の値を持つコレクション型)など、より高度で柔軟なプログラミングパターンが可能になります。Sized と ?Sized のバランスを取ることで、Rust は効率性と柔軟性の両方を提供している。
tests ディレクトリはそれぞれのファイルが独立したクレートとして扱われる
(tests ディレクトリ内の名前解決にハマったので Claude に聞いた)
Rustにおける tests ディレクトリの特殊な扱いを理解するには、Rustのクレートとモジュールシステムについて深く理解する必要があります。
// src/lib.rs
pub mod utils {
pub fn lib_function() -> &'static str {
"I'm from the main library"
}
}
// tests/utils.rs
pub fn test_function() -> &'static str {
"I'm from the test utils"
}
// tests/my_test.rs
mod utils; // これは機能しない
#[test]
fn test_something() {
// このように書くと、コンパイルエラーになります
assert_eq!(utils::test_function(), "I'm from the test utils");
// しかし、これは機能します(メインライブラリの関数を呼び出しています)
assert_eq!(echo::utils::lib_function(), "I'm from the main library");
}
この例で何が起こっているのか、詳しく見ていきましょう:
-
独立したクレートとしての
testsディレクトリ:- Rustコンパイラは
testsディレクトリ内の各.rsファイルを、メインのライブラリクレートとは別の、独立した統合テストクレートとして扱います。 - これは、各テストファイルが自身のクレートルートとなることを意味します。
- Rustコンパイラは
-
モジュール解決の範囲:
- 通常のRustのモジュールシステムでは、
mod utils;という宣言は現在のファイルと同じディレクトリ内のutils.rsまたはutils/mod.rsを探します。 - しかし、
testsディレクトリ内では、この通常の解決方法が適用されません。各テストファイルは独立したクレートのルートとして扱われるため、mod utils;という宣言は意味を持ちません。
- 通常のRustのモジュールシステムでは、
-
メインライブラリへのアクセス:
- テストファイルからは、クレート名(この場合は
echo::と仮定)を使用してメインライブラリの要素にアクセスできます。 - これは、テストクレートがメインライブラリクレートに依存しているためです。
- テストファイルからは、クレート名(この場合は
-
なぜ
mod utils;が機能しないのか:- 各テストファイルは独立したクレートのルートとして扱われるため、
mod utils;という宣言は、そのファイル自体と同じディレクトリ内のutils.rsまたはutils/mod.rsを探そうとします。 - しかし、Rustのビルドシステムは
testsディレクトリ内でこの種の暗黙的なモジュール解決を行いません。
- 各テストファイルは独立したクレートのルートとして扱われるため、
-
解決方法:
-
testsディレクトリ内で共通のユーティリティを使用したい場合、明示的にモジュール構造を作成する必要があります(例:tests/common/mod.rsを作成し、そこでサブモジュールを定義する)。 - または、各テストファイルで必要な関数を直接定義するか、外部クレートとして共通のユーティリティを定義し、
Cargo.tomlの[dev-dependencies]セクションで指定します。
-
この動作の理由:
- この設計は、統合テストを本番コードから完全に分離することを目的としています。
- 各テストファイルを独立したクレートとして扱うことで、テストが本番コードと同じ環境で実行されることを保証し、潜在的な問題(例:名前の衝突)を防ぎます。
理解を深めるために、テストファイル内で println!("crate name: {}", env!("CARGO_PKG_NAME")); を使用すると、そのテストファイルが属するクレートの名前(通常は {your_project_name}-{test_file_name}のような形式)が表示されます。これは、各テストファイルが独立したクレートであることを示しています。
std::io::BufRead
From / Into トレイト
なるほど、Rust だとこういう書き方で独自エラー型を掛けるのか。あとエラー伝搬ほんと便利。
use std::fs;
use std::io;
use std::num;
enum CliError {
IoError(io::Error),
ParseError(num::ParseIntError),
}
impl From<io::Error> for CliError {
fn from(error: io::Error) -> Self {
CliError::IoError(error)
}
}
impl From<num::ParseIntError> for CliError {
fn from(error: num::ParseIntError) -> Self {
CliError::ParseError(error)
}
}
fn open_and_parse_file(file_name: &str) -> Result<i32, CliError> {
let mut contents = fs::read_to_string(&file_name)?;
let num: i32 = contents.trim().parse()?;
Ok(num)
}
エラーハンドリング
unwind: panic を Result 型でハンドリングする
基本
use std::panic;
fn main() {
let result = panic::catch_unwind(|| {
println!("パニックする前の処理");
panic!("意図的なパニック");
});
match result {
Ok(_) => println!("パニックは発生しませんでした"),
Err(e) => {
if let Some(s) = e.downcast_ref::<&str>() {
println!("文字列パニック: {}", s);
} else {
println!("不明なパニックが発生しました");
}
}
}
println!("プログラムは続行します");
}
スレッド間のパニックの伝搬の制御
use std::thread;
use std::panic;
fn main() {
let handle = thread::spawn(|| {
panic!("スレッド内でパニック");
});
let thread_result = panic::catch_unwind(|| {
handle.join().unwrap()
});
match thread_result {
Ok(_) => println!("スレッドは正常に終了しました"),
Err(_) => println!("スレッドでパニックが発生しました"),
}
}
プラグインシステムの実装
fn run_plugin(plugin: &dyn Plugin) -> Result<(), Box<dyn std::any::Any + Send>> {
panic::catch_unwind(|| {
plugin.execute();
})
}
fn main() {
let plugins = vec![Plugin1, Plugin2, Plugin3];
for plugin in plugins {
match run_plugin(&plugin) {
Ok(_) => println!("プラグインが正常に実行されました"),
Err(_) => println!("プラグインの実行中にパニックが発生しました"),
}
}
}
FFI(外部関数インタフェース)
use std::panic;
#[no_mangle]
pub extern "C" fn safe_rust_function(input: i32) -> i32 {
let result = panic::catch_unwind(|| {
if input == 0 {
panic!("ゼロ除算");
}
100 / input
});
match result {
Ok(value) => value,
Err(_) => -1, // エラー値
}
}
注意
-
catch_unwindは全てのパニックをキャッチできるわけではない。例えば、スタックオーバーフローや、abort で終了するパニックはキャッチできない。 - パニックを通常のエラー処理の一部として使用することは推奨されない。
ResultやOptionを使用した通常のエラーハンドリングを優先すべき。 -
catch_unwindの使用は、特殊なケース(FFI、スレッド間の境界など)に限定すべき。
unwind と catch_unwind の組み合わせは、Rust の柔軟なエラーハンドリング機能の一つであり、適切に使用することで、より堅牢で管理しやすいシステムを構築することができる。ただし、通常のエラー処理には Result を使用し、catch_unwind は特殊なケースに限定して使用することが推奨される。
Option 型
Rust の optional chain やっぱ便利だ
struct Person {
job: Option<Job>,
}
#[derive(Clone, Copy)]
struct Job {
phone_number: Option<PhoneNumber>,
}
#[derive(Clone, Copy)]
struct PhoneNumber {
area_code: Option<u8>,
number: u32,
}
impl Person {
// Gets the area code of the phone number of the person's job, if it exists.
// その人の市外局番が存在する場合、取得する。
fn work_phone_area_code(&self) -> Option<u8> {
// This would need many nested `match` statements without the `?` operator.
// It would take a lot more code - try writing it yourself and see which
// is easier.
// `?`がなければ、多くのネストされた`match`文を必要とするため、より長いコードとなる。
// 実際に書いて、どちらの方が簡単か確かめてみましょう。
self.job?.phone_number?.area_code
}
}
fn main() {
let p = Person {
job: Some(Job {
phone_number: Some(PhoneNumber {
area_code: Some(61),
number: 439222222,
}),
}),
};
assert_eq!(p.work_phone_area_code(), Some(61));
}
例えば、TypeScript で optional chain で返り値に伝搬させることをやろうとすると optional chain の途中途中で明示的にリターンしなきゃだめ(実際は processStruct2 の方で問題ないけど)。
function processStruct(myStruct: any): string | undefined {
if (!myStruct.options) return undefined;
if (!myStruct.options.meal) return undefined;
if (!myStruct.options.meal.type) return undefined;
return myStruct.options.meal.type.favorite;
}
function processStruct2(myStruct: any): string | undefined {
return myStruct.options?.meal.type?.favorite;
}
const a = processStruct(myStruct);
TypeScript の optional chain では、途中のどれかが null か undefined の場合、返り値にすぐ伝搬することはない。例えば、下記の例で .options? や .type? が undefined なら変数 a に undefined が入る。後続の処理で undefined を考慮した実装を行う必要がある。
const a = myStruct.options?.meal.type?.favorite;
TypeScript で nullish 合体演算子を使うパターンは使っていきたい。
const a = myStruct.options?.meal?.type?.favorite ?? undefined;
Option 型の便利なメソッド:map、map_or、transpose
Option
pub enum Option<T> {
None,
Some(T),
}
ここから
map メソッド概要
map メソッドのシグネチャ
impl<T> Option<T>
pub fn map<U, F>(self, f: F) -> Option<U>
where F: FnOnce(T) -> U,
Option 型の map メソッドは Option<T> を Option<U> に変換する。中身の値に関数を適用する(Some の場合)か、None を返す(None の場合)。
-
my_var.map(|v| some_func(v))-
my_varがSome(T)ならsome_func(v)の戻り値(U型)をOption型に包んでSome(U)で返す -
my_varがNoneならNoneを返す - このとき
my_varは消費される- 所有権の移動:「消費される」とは、その値の所有権が移動することを意味する。
mapメソッドを呼び出した後、元の変数my_varはもはやその値を所有していないため、変数を参照することはできない。
- 所有権の移動:「消費される」とは、その値の所有権が移動することを意味する。
-
map メソッドの呼び出しにより所有権の移動が起きるのは、map メソッドが &self や &mut self といった参照ではなく、self を取るためである。このため、map を呼び出すと呼び出し元の self が消費される。
pub fn map<U, F>(self, f: F) -> Option<U>
例 1
let maybe_some_string = Some(String::from("Hello, World!"));
let maybe_some_len = maybe_some_string.map(|s| s.len());
// この時点で maybe_some_string は使用できない
// 以下の行はコンパイルエラーになる。maybe_some_string は map が呼ばれた時点で move が起きているため。
// println!("{:?}", maybe_some_string);
例 2
Option<String> の長さを Option<usize> として計算し、元の値を消費する:
let maybe_some_string = Some(String::from("Hello, World!"));
// `Option::map` takes self *by value*, consuming `maybe_some_string`
let maybe_some_len = maybe_some_string.map(|s| s.len()); // return Some(usize)
assert_eq!(maybe_some_len, Some(13));
let x: Option<&str> = None;
let maybe_x_len = x.map(|s| s.len()); // return None
assert_eq!(maybe_x_len, None);
map_or 概要
map_or メソッドのシグネチャ
impl<T> Option<T>
pub fn map_or<U, F>(self, default: U, f: F) -> U
where
F: FnOnce(T) -> U,
- 呼び出し元の
Option型の値がNoneの場合、メソッドに渡されたデフォルト結果を返す -
Some(T)の場合、含まれる値に関数を適用する -
mapと異なり、map_orの戻り値はOption<U>でなくUであることに注意。デフォルト値が設定できるため、元の値がNoneでもSome(T)の場合も必ずU型を返せることが保証されているため、Option型でラップする必要がなくなっている。
map_or に渡される引数は即時評価される。関数呼び出しの結果を渡す場合は、遅延評価される map_or_else を使用することが推奨。
Returns the provided default result (if none), or applies a function to the contained value (if any).
Arguments passed to map_or are eagerly evaluated; if you are passing the result of a function call, it is recommended to use map_or_else, which is lazily evaluated.
#[cfg(test)]
mod tests {
#[test]
fn map_or_practice() {
let x = Some("foo");
let x_len = x.map_or(42, |v| v.len());
assert_eq!(x_len, 3);
let x: Option<&str> = None;
assert_eq!(x.map_or(42, |v| v.len()), 42);
}
}
map_or_else 概要
map_or_else のシグネチャ
impl<T> Option<T>
pub fn map_or_else<U, D, F>(self, default: D, f: F) -> U
where
D: FnOnce() -> U,
F: FnOnce(T) -> U,
-
Noneの場合、デフォルトの関数結果を計算する -
Some(T)の場合、Tに対して関数を提供する - 戻り値は
Option<U>ではなくU
Computes a default function result (if none), or applies a different function to the contained value (if any).
Basic examples
let k = 21;
let x = Some("foo");
assert_eq!(x.map_or_else(|| 2 * k, |v| v.len()), 3);
let x: Option<&str> = None;
assert_eq!(x.map_or_else(|| 2 * k, |v| v.len()), 42);
Result ベースのフォールバックを扱う
Result<T, E> と組み合わせてオプショナルな値を扱う際によくある状況として、オプションが存在しない場合に "失敗する可能性のあるフォールバック" を呼び出したい場合がある。
以下の例では、コマンドライン引数(存在する場合)またはファイルの内容を整数に解析します。ただし、コマンドライン引数へのアクセスとは異なり、ファイルの読み取りは失敗する可能性があるため、Ok でラップする必要がある。
A somewhat common occurrence when dealing with optional values in combination with
Result<T, E>is the case where one wants to invoke a fallible fallback if the option is not present. This example parses a command line argument (if present), or the contents of a file to an integer. However, unlike accessing the command line argument, reading the file is fallible, so it must be wrapped with Ok.
let v: u64 = std::env::args()
.nth(1)
.map_or_else(|| std::fs::read_to_string("/etc/someconfig.conf"), Ok)?
.parse()?;
わかりやすく Ok の部分のクロージャを省略せずに書くと以下のようになる(実際は clippy::redundant_closure という warning で怒られると思う):
let v: u64 = std::env::args()
.nth(1)
.map_or_else(|| std::fs::read_to_string("/etc/someconfig.conf"), |arg| Ok(arg))?
.parse()?;
ここでは map_or_else に以下 2 つのクロージャを渡しているが、どちらも戻り値は Result<String, std::io::Error>> を返す:
-
|| std::fs::read_to_string("/etc/someconfig.conf"->Result<String, std::io::Error>> -
|arg| Ok(arg)->Result<String, std::io::Error>>
map_or_else の利点
map_or_else の利点は、特に Result<T, E> と組み合わせて使う場合に顕著になる:
let v: u64 = std::env::args()
.nth(1)
.map_or_else(|| std::fs::read_to_string("/etc/someconfig.conf"), Ok)?
.parse()?;
// 同等の処理を map_or で行おうとするとコンパイルエラーになる
// let v: u64 = std::env::args()
// .nth(1)
// .map_or(std::fs::read_to_string("/etc/someconfig.conf"), Ok)?
// .parse()?;
map_or_else の主な利点:
- 遅延評価
-
map_or_elseは、Noneの場合にのみフォールバック関数を実行する -
map_orは、Someの場合でも不要なデフォルト値を計算してしまう(上の例でいうと必ずファイル読み込みが発生してしまう。Someの場合は無駄な計算となる。)
-
- 柔軟性
-
map_or_elseは、フォールバック関数として任意の処理を指定できる - この例では、ファイル読み込みという失敗する可能性のある操作をフォールバックとして使用している
-
- Result との相性
-
map_or_elseはResultを返すフォールバック関数と相性が良い - この例では、
std::fs::read_to_stringがResultを返すが、map_or_elseはこれをそのまま扱える
-
- エラーハンドリングの統一:
-
?演算子を使って、コマンドライン引数の解析とファイル読み込みのエラーを統一的に扱える
-
- コードの簡潔さ:
- 複雑な条件分岐を書かずに、オプショナルな値とフォールバックを簡潔に表現できる
map_or では実現できない点:
-
map_orは、デフォルト値としてResultを直接扱えない - フォールバック処理が失敗する可能性がある場合、
map_orでは適切に扱うのが難しくなる
この例では、コマンドライン引数がない場合にファイルから設定を読み込むという、実際のアプリケーションでよくある処理を簡潔に表現している。map_or_else を使うことで、エラーハンドリングを含む複雑な処理を読みやすく、メンテナンスしやすいコードで表現できる。
所感
たしかに〇〇したときのフォールバックで Result 型扱うときは無限にあるし、エラーハンドリングやりやすくなる。フォールバックが実際に必要になるまで無駄な処理をしない遅延評価も良い。逆にシンプルなケースでは map_or で十分なところもあるな。実際よく使う。
すでにめっちゃお世話になってるけどもっと理解を深めれば活用できる場所たくさんあるなと思った。
map は「写像 mapping」由来
mapという名前は、数学や関数型プログラミングから来ています。以下にその意味と背景を説明します:
- 数学的な意味:
数学では、「写像」(mapping)という概念があります。これは、ある集合の要素を別の集合の要素に対応させる規則のことです。- 関数型プログラミングでの意味:
データ構造の各要素に関数を適用して、新しいデータ構造を作成する操作を指します。Option::mapの場合:
Option<T>型の値をOption<U>型に変換します。- 内部の値(Tの値)に関数を適用し、結果をOption型で包んで返します。
- 略語ではない:
mapは実際には略語ではありません。"mapping"(写像)の動詞形として使われています。- 意味の解釈:
- 「変換する」
- 「適用する」
- 「対応付ける」
- 他の文脈での
map:
- コレクション型(Vec, HashMap など)でも同様の操作を提供します。
- イテレータでも
mapメソッドが存在し、各要素を変換します。- 概念の普遍性:
mapの概念は多くのプログラミング言語で採用されており、データ変換の標準的な方法となっています。例:
let numbers = vec![1, 2, 3, 4, 5];
let squares = numbers.iter().map(|&x| x * x).collect::<Vec<_>>();
// squares は [1, 4, 9, 16, 25] となります
この例では、各数値を2乗する関数を
mapで適用しています。
mapの概念を理解することは、関数型プログラミングのパラダイムを理解する上で重要です。これにより、データの変換や処理をより宣言的に記述できるようになります。
transpose 概要
transpose メソッドのシグネチャ
-
Option<Result<T, E>>に実装されているメソッド。map,map_or,map_or_elseはOption<T>に実装されているためOption型の値であれば実行できたが、transposeはOptionの中身がResult型である必要がある
impl<T, E> Option<Result<T, E>>
pub fn transpose(self) -> Result<Option<T>, E>
-
Option<Result>をResult<Option>に変換(転置 transpose)する 。 - より詳しくは、
Option<Result<T, E>>型の値をResult<Option<T>, E>型に変換する。つまり、外側のOptionと内側のResultの位置を入れ替える。 - 関連する変換
-
None→Ok(None) -
Some(Ok(_))→Ok(Some(_)) -
Some(Err(_))→Err(_)
-
※「変換」という言葉を使っているが、原文の "transpose" は数学的には「転置」とも訳せる。ここでは型の構造を入れ替える操作を指している。
Transposes an Option of a
Resultinto aResultof an Option.
Nonewill be mapped toOk(None).Some(Ok(_))andSome(Err(_))will be mapped toOk(Some(_))andErr(_).
Examples
#[derive(Debug, Eq, PartialEq)]
struct SomeErr;
let x: Result<Option<i32>, SomeErr> = Ok(Some(5));
let y: Option<Result<i32, SomeErr>> = Some(Ok(5));
assert_eq!(x, y.transpose()); // どちらも Result<Option<i32>, SomeErr> になっている
まだ transpose メソッドのエラーハンドリングのどういうところで使うかの具体的なイメージが付いていない。ただ、「この Option 型を Result 型として扱いたい」ってのは色んなところでありそうだなって思うからもうちょっと実装やってみてって感じかな。
→ 多分これは Option<Result> をあまり見たことないからかも。map の中で値に適用する関数から Result 型が返されたときに Option<Result> を受け取ってそれを transpose で Result に変換してエラーハンドリングできる形に持っていく、みたいなパターンはいろいろなところで使われていそうだなとは思うけど。
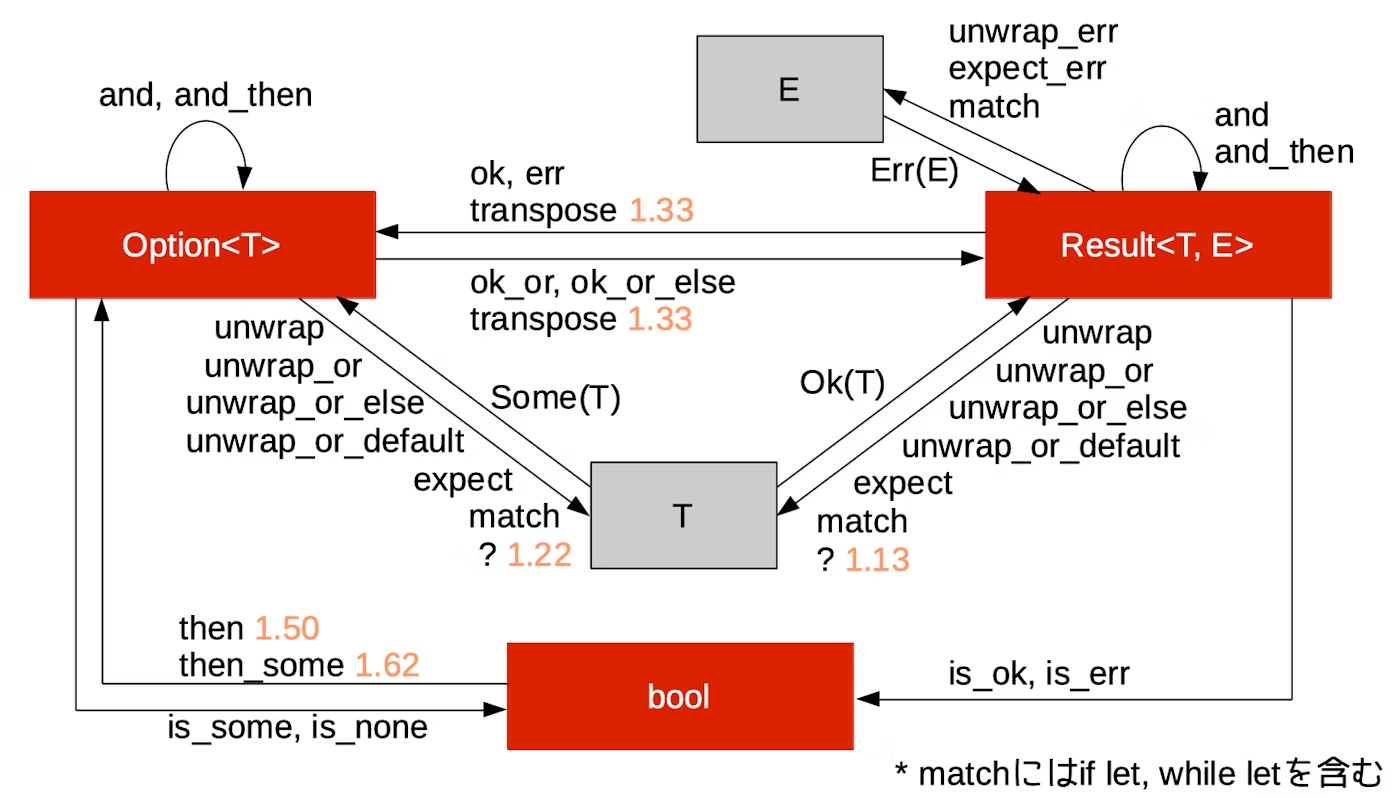
Box の挙動
↓こっちにまとめた
コンパイルエラーになる例
コード
fn get_args() -> Result<(), dyn std::error::Error> {
Ok(())
}
コンパイルエラー
error[E0277]: the size for values of type `(dyn std::error::Error + 'static)` cannot be known at compilation time
--> head/src/map_practice.rs:3:18
|
3 | fn get_args() -> Result<(), dyn std::error::Error> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
= help: the trait `Sized` is not implemented for `(dyn std::error::Error + 'static)`
note: required by an implicit `Sized` bound in `Result`
--> /Users/nukopy/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/result.rs:527:20
|
527 | pub enum Result<T, E> {
| ^ required by the implicit `Sized` requirement on this type parameter in `Result`
error[E0277]: the size for values of type `dyn std::error::Error` cannot be known at compilation time
--> head/src/map_practice.rs:4:5
|
4 | Ok(())
| ^^^^^^ doesn't have a size known at compile-time
|
= help: the trait `Sized` is not implemented for `dyn std::error::Error`
note: required by a bound in `Ok`
--> /Users/nukopy/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/result.rs:527:20
|
527 | pub enum Result<T, E> {
| ^ required by this bound in `Ok`
...
531 | Ok(#[stable(feature = "rust1", since = "1.0.0")] T),
| -- required by a bound in this tuple variant
For more information about this error, try `rustc --explain E0277`.
warning: `head` (lib) generated 1 warning
error: could not compile `head` (lib) due to 2 previous errors; 1 warning emitted
コンパイルエラーにならない例
コード
Result<T, E> の E の型を Box でくくる
-fn get_args() -> Result<(), dyn std::error::Error> {
+fn get_args() -> Result<(), Box<dyn std::error::Error>> {
Ok(())
}
Result 型
pub enum Result<T, E> {
Ok(T),
Err(E),
}
mapmap_errmap_ormap_or_else
map_or_else の使い方
シグネチャ
map_or_else のシグネチャ
pub fn map_or_else<U, D, F>(self, default: D, f: F) -> U
where
D: FnOnce(E) -> U,
F: FnOnce(T) -> U,
Result<T, E> 型の値から map_or_else メソッドを呼び出した時、値が Err(E) のときは defalut がその値に適用され、Ok(T) のときは f がその値に適用される(Option 型の map_or_else と同じ考え方)。
クロージャ default、f の戻り値は U に揃える必要がある。
例
クロージャに丁寧に型注釈してサンプルコードを書いてみた。
type MyResult = Result<i32, String>;
fn divide(a: i32, b: i32) -> MyResult {
if b == 0 {
Err(String::from("Division by zero"))
} else {
Ok(a / b)
}
}
fn main() {
// closure
let double_and_convert_str = |v: i32| (v * 2).to_string();
let fallback = |e: String| e.to_uppercase();
// test divided by not zero
let expected = 10.to_string();
let result = divide(10, 2); // Ok(5)
let result = result.map_or_else(|e: String| fallback(e), |v: i32| double_and_convert_str(v));
assert_eq!(result, expected);
// test divided by zero
let expected = String::from("Division by zero").to_uppercase();
let result = divide(10, 0); // Err(String("Division by zero"))
let result = result.map_or_else(|e: String| fallback(e), |v: i32| double_and_convert_str(v));
assert_eq!(result, expected);
}
map_err の使い方
シグネチャ
pub fn map_err<F, O>(self, op: O) -> Result<T, F>
where
O: FnOnce(E) -> F,
Result<T, E> を Result<T, F> に変換するために使用される。
Result<T, E> 型の値が Err(E) のとき、引数 op が適用される。op は F を返す。値が Ok(T) ならそのまま Ok(T) を返す。
Maps a Result<T, E> to Result<T, F> by applying a function to a contained Err value, leaving an Ok value untouched.
This function can be used to pass through a successful result while handling an error.
例
例えば、以下のように、整数型のエラーコードを含むを Err(u32) 型に対して、ログ出力のための付加情報を追加して Err(String) 型に変換するという使われ方がある。
冗長だけど、型注釈と map_err にわたす クロージャを省略せずに書いている。
冒頭で書いた通り、map_err により、以下の挙動を示している。
-
Result<T, E>(Result<u32, u32>)型の変数の値がOk(T)のときはそのままOk(T)(Result<u32, String>)が返される- 実際は使われないが、
Ok(T)のときにもResult<u32, u32>がResult<u32, String>になり、Errの中身の型が変換されていることに注意。
- 実際は使われないが、
-
Err(E)(Err(u32))型のとき、Err(F)(Err(String)) が返される。Result<u32, u32>がResult<u32, String>に変換されるというのが理解できる。
/// 3 の倍数ならエラーコード 333、それ以外ならエラーコード 0 を返す
/// 意味わからんコードでごめん
fn get_error_code(code: u32) -> Result<u32, u32> {
if code % 3 == 0 {
Ok(333)
} else {
Err(code)
}
}
/// map_err にて、値が Err(u32) のときに適用する関数
fn stringify(x: u32) -> String {
format!("error code: {x}")
}
#[allow(clippy::redundant_closure)]
fn main() {
// x は Ok(u32) なので、map_err はそのまま Ok(u32) を返す
let x: Result<u32, u32> = get_error_code(3); // Ok(333)
let expected: Result<u32, String> = Ok(333);
let result: Result<u32, String> = x.map_err(|v: u32| stringify(v));
assert_eq!(result, expected);
// x は Err(u32) なので、map_err は Ok(String) 型を返す
let x: Result<u32, u32> = get_error_code(2); // Err(2)
let expected: Result<u32, String> = Err("error code: 2".to_string());
let result: Result<u32, String> = x.map_err(|v: u32| stringify(v)); // Ok("error code: 2")
assert_eq!(result, expected);
}
examples 内のテストを実行する方法
- all
cargo test --examples
- individual file
cargo test --example <example_name>
BufRead.take(limit)
Perplexity に聞いた:
BufRead.take() メソッドは、Rustの標準ライブラリに含まれる便利なメソッドです。このメソッドは、元のリーダーから指定したバイト数だけ読み取る新しいリーダーを作成します。主な特徴は以下の通りです:
-
使用方法:
reader.take(limit) -
引数:
limit- 読み取るバイト数の上限(u64型) -
戻り値:
Take<Self>型の新しいリーダー -
動作:
- 元のリーダーから最大
limitバイトまで読み取ります。 -
limitバイト読み取った後、または元のリーダーがEOFに達した場合、新しいリーダーはEOFを返します。
- 元のリーダーから最大
-
用途:
- ファイルや入力ストリームの一部だけを読み取りたい場合に便利です。
- 大きなファイルの先頭部分だけを処理したい場合などに使用できます。
例えば:
use std::io::{self, BufRead};
fn main() -> io::Result<()> {
let input = b"Hello, world!";
let mut reader = io::Cursor::new(input).take(5);
let mut buffer = String::new();
reader.read_to_string(&mut buffer)?;
assert_eq!(buffer, "Hello");
Ok(())
}
この例では、"Hello, world!" というバイト列から最初の5バイトだけを読み取っています。
take() メソッドは、ストリームの一部だけを処理したい場合や、入力サイズを制限したい場合に非常に便利なツールです。
Citations:
[1] https://web.mit.edu/rust-lang_v1.25/arch/amd64_ubuntu1404/share/doc/rust/html/std/io/trait.BufRead.html
[2] http://doc.rust-jp.rs/the-rust-programming-language-ja/1.6/std/io/trait.BufRead.html
[3] https://doc.rust-lang.org/std/io/trait.BufRead.html
[4] https://www.brandons.me/blog/bufread-and-when-to-use-it
[5] https://www.reddit.com/r/rust/comments/pp1xep/why_does_bufread_require_read/
[6] https://doc.rust-lang.org/std/io/struct.BufReader.html
[7] https://www.reddit.com/r/rust/comments/18mdk2x/how_does_bufreadernewstdin_work/
[8] https://stackoverflow.com/questions/70572667/is-there-a-simpler-way-to-pass-a-bufreader-to-a-function
Iter.filter
tempfile クレート