【AWS】Lambdaを利用したスクレイピング【Container Support】
はじめに
re:Invent 2020において、Lambdaでコンテナイメージがサポートされました。
一番の注目ポイントは、従来のZip形式では依存パッケージ等も含め250MBまでだった容量制限が10GBまで増えた点です。
これにより、多様なモジュールを利用する機械学習系の処理が可能になったり、seleniumで利用するHeadless BrowserをLambda Layerでデプロイする必要が無くなったのではないかと思います。
(ただし、最大実行時間は変わらず15分であることに注意してください)
コンテナイメージの実現方法として以下の2つがあります。
- AWSが提供するベースイメージを利用する
- Lambda Runtime APIを実装したカスタムイメージを作成する
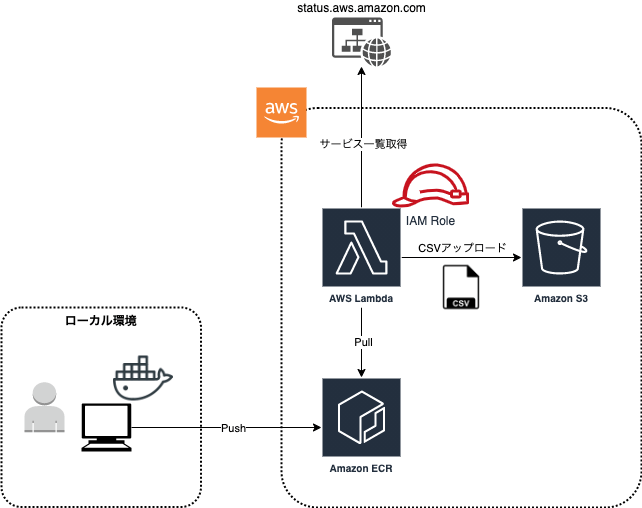
本記事では、AWS提供のベースイメージを利用して、下図のようにAWSのサービスステータス画面をスクレイピングして(※)、(AWS側に障害が発生していないときに限り)AWSサービス一覧を取得するLambdaを作成してみようと思います。
なお、LambdaのランタイムはPython3.8、IaCはterraformを利用します。
※ status.aws.amazon.comでは、以下のとおりスクレイピングが許可されています。
curl https://status.aws.amazon.com/robots.txt
User-agent: *
Allow: /
動作環境
$ aws --version
aws-cli/2.1.27 Python/3.7.4 Darwin/19.4.0 exe/x86_64 prompt/off
$ terraform -v
Terraform v0.13.6
スクレイピング処理用のコンテナ作成
まずは、スクレイピングを行い、S3にスクレイピング結果のCSVを出力する処理をPythonで記載していきます。
事前準備
Mockを用意するのが面倒なので、CSVのアップロード先S3バケットとコンテナのPush先リポジトリを作成しておきます。
resource "aws_s3_bucket" "upload_bucket" {
bucket = "test-upload-bucket-20210302"
acl = "private"
force_destroy = true
}
resource "aws_ecr_repository" "scraping" {
name = "aws_status_scraping"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
}
コーティング
以下のようなコードを記載しました。
import requests
import lxml
import re
import csv
import os
import boto3
from bs4 import BeautifulSoup
s3 = boto3.resource('s3')
output_bucket = s3.Bucket(os.environ.get("OUTPUT_BUCKET_NAME"))
URL = "https://status.aws.amazon.com/"
TMP_FILE_PATH = "/tmp/tmp.csv"
UPLOAD_FILE_NAME = os.environ.get("UPLOAD_FILE_NAME")
def handler(event, context):
try:
print({"message": f"start scraping {URL}"})
res = requests.get(URL)
soup = BeautifulSoup(res.content, "lxml", from_encoding='utf-8')
service_name_rows = soup.select('.bb.top.pad8')
service_names = {re.sub('\s\(.*\)', '', service_name.text) for service_name in service_name_rows if service_name.text != "No recent events."}
write_csv(service_names)
output_bucket.upload_file(TMP_FILE_PATH, UPLOAD_FILE_NAME)
print({"message": f"end scraping {URL}"})
return "Succeeded!!!"
except:
return "Failed..."
def write_csv(target_set):
with open(TMP_FILE_PATH, 'w') as f:
writer = csv.writer(f)
for service in list(target_set):
writer.writerow([service])
requests
beautifulsoup4
lxml
printでログ出力を行っている理由は、後述のローカル実行時でログを出力させたい場合、dict形式で出力しないとdocker logsに表示されなかったためです。(loggingモジュールでのログ出力方法は分かりませんでした。)
(参考)
実際にLambda上で動作させる場合は、stringであってもCloudWatchLogsに出力されるのでご安心ください。
コンテナ作成
AWSの公式Dockerイメージをベースに、前手順で作成したPythonのコードと依存パッケージがインストールされた状態のイメージを作成します。
以下のDockerFileを作成し、buildを行います。
FROM public.ecr.aws/lambda/python:3.8
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY app.py ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
$ docker build -t aws_serivce_scraping . #DockerfileがあるDirで実行
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
aws_serivce_scraping latest e8d983af1fb9 5 seconds ago 619MB
ローカルでの検証
先ほどの手順で作成したDockerイメージを利用して、ローカル上で検証を行います。
docker runコマンドでコンテナを起動するとLambda Runtime Interface Emulatorが立ち上がり、curlを利用してランタイムAPIを呼び出すことでPythonのコードを実行することができます。
# Lambdaコンテナ起動
$ docker run --rm -p 9000:8080 \
-e AWS_ACCESS_KEY_ID=xxxxx \ # 自身のアクセスキーIDを指定
-e AWS_SECRET_ACCESS_KEY=xxxxx \ # 自身のアクセスキーを指定
-e AWS_DEFAULT_REGION=ap-northeast-1 \
-e OUTPUT_BUCKET_NAME=test-upload-bucket-20210302 \
-e UPLOAD_FILE_NAME=aws_services.csv \
aws_serivce_scraping
# LambdaのランタイムAPIを呼び出して実行
$ curl -d '{}' http://localhost:9000/2015-03-31/functions/function/invocations
"Succeeded!!!"
# DockerLogsには以下のようなログが出力されている
# time="2021-03-02T13:37:41.022" level=info msg="exec '/var/runtime/bootstrap' (cwd=/var/task, handler=)"
# time="2021-03-02T13:37:54.458" level=info ?msg="extensionsDisabledByLayer(/opt/disable-extensions-jwigqn8j) -> stat /opt/disable-extensions-jwigqn8j: no such file or directory"
# time="2021-03-02T13:37:54.458" level=warning msg="Cannot list external agents" error="open /opt/extensions: no such file or directory"
# START RequestId: a74e925e-6425-4a06-a517-a58ea1608e83 Version: $LATEST
# {'message': 'start scraping https://status.aws.amazon.com/'}
# {'message': 'end scraping https://status.aws.amazon.com/'}
# END RequestId: a74e925e-6425-4a06-a517-a58ea1608e83
# REPORT RequestId: a74e925e-6425-4a06-a517-a58ea1608e83 Init Duration: 1.05 ms Duration: 7667.90 ms Billed Duration: 7700 ms Memory Size: 3008 MB Max Memory Used: 3008 MB
# アップロードされたファイルを確認
$ aws s3 ls s3://test-upload-bucket-20210302
2021-03-02 22:38:02 3883 aws_services.csv
# ファイルをS3からローカルにコピー
$ aws s3 cp s3://test-upload-bucket-20210302/aws_services.csv /tmp/
download: s3://test-upload-bucket-20210302/aws_services.csv to ../../tmp/aws_services.csv
# ファイルの中身を確認
$ head -n 10 /tmp/aws_services.csv
AWS IoT Device Management
AWS Firewall Manager
AWS DeepComposer
AWS CloudTrail
Amazon Braket
Amazon WorkMail
Amazon AppStream 2.0
AWS IoT 1-Click
Amazon Neptune
Amazon Cognito
# ファイル削除
$ aws s3 rm s3://test-upload-bucket-20210302/aws_services.csv
delete: s3://test-upload-bucket-20210302/aws_services.csv
イメージのPush
ローカル環境での検証が完了したので、ECRへイメージをPushし、Lambdaが利用できる状態にします。
ecr_repo=<AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ${ecr_repo}
docker tag aws_serivce_scraping:latest ${ecr_repo}/aws_status_scraping:latest
docker push ${ecr_repo}/aws_status_scraping:latest
Lambda作成
Dockerイメージの検証・Pushが完了したので、以下のリソースを作成していきます。
- Lambda関数
- 今回作成したコンテナを稼働させる関数
- IAM Role
- LambdaへS3を操作する権限を与えるロール
terraformのコードを以下のように修正し、applyを行ってください。
locals {
function_name = "aws_status_scraping"
tag_name = "latest"
upload_file_name = "aws_services.csv"
}
resource "aws_s3_bucket" "upload_bucket" {
bucket = "test-upload-bucket-20210302"
acl = "private"
force_destroy = true
}
resource "aws_ecr_repository" "scraping" {
name = "aws_status_scraping"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
}
// Dockerイメージの変更を検出するためにイメージの情報を読み込む
data "aws_ecr_image" "scraping" {
repository_name = aws_ecr_repository.scraping.name
image_tag = local.tag_name
}
resource "aws_lambda_function" "aws_status_scraping" {
function_name = local.function_name
role = aws_iam_role.lambda_iam_role.arn
package_type = "Image"
image_uri = "${aws_ecr_repository.scraping.repository_url}:${local.tag_name}"
memory_size = 256
timeout = 60
source_code_hash = trimprefix(data.aws_ecr_image.scraping.id, "sha256:") //Dockerイメージに変更があった場合の更新処理
environment {
variables = {
OUTPUT_BUCKET_NAME = aws_s3_bucket.upload_bucket.id
UPLOAD_FILE_NAME = local.upload_file_name
}
}
}
// LambdaがAssumeするロールを作成
resource "aws_iam_role" "lambda_iam_role" {
name = "lambda_${local.function_name}"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
}
// LambdaにAssumeする権限を与えるポリシー
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
identifiers = ["lambda.amazonaws.com"]
type = "Service"
}
effect = "Allow"
}
}
// 「LambdaにAssumeする権限を与えるポリシー」をロールにアタッチ
resource "aws_iam_role_policy_attachment" "basic_execution" {
role = aws_iam_role.lambda_iam_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
// S3へファイルアップロードが行えるようフルアクセス権限をロールにアタッチ
// Note: プロダクション環境等では必ず対象バケットや許可するアクションを絞ってください
resource "aws_iam_role_policy_attachment" "s3_full_access" {
role = aws_iam_role.lambda_iam_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
}
Lambdaの動作確認
CLI経由もしくはAWS管理コンソールからaws_status_scraping関数を実行します。
$ aws lambda invoke --function-name aws_status_scraping \
--payload '{}' \
--cli-binary-format raw-in-base64-out \
response.json
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
$ cat response.json
"Succeeded!!!"
# アップロードされたファイルを確認(結果は割愛)
$ aws s3 ls s3://test-upload-bucket-20210302
$ aws s3 cp s3://test-upload-bucket-20210302/aws_services.csv /tmp/
$ head -n 10 /tmp/aws_services.csv
Drift検出
最後に、コンテナに変更を加えた際にDriftが検出されることを確認します。
Lambdaリソースに記載した以下により、DockerイメージのHashの違いで差分を検出することができます。
source_code_hash = trimprefix(data.aws_ecr_image.scraping.id, "sha256:") //Dockerイメージに変更があった場合の更新処理
成功時のメッセージを変更してbuild & pushします。
- return "Succeeded!!!"
+ return "Succeeded..."
terraformのplan結果として差分が出力されればOKです。
# aws_lambda_function.aws_status_scraping will be updated in-place
~ resource "aws_lambda_function" "aws_status_scraping" {
arn = "arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping"
function_name = "aws_status_scraping"
id = "aws_status_scraping"
image_uri = "321498468606.dkr.ecr.ap-northeast-1.amazonaws.com/aws_status_scraping:latest"
invoke_arn = "arn:aws:apigateway:ap-northeast-1:lambda:path/2015-03-31/functions/arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping/invocations"
~ last_modified = "2021-03-02T13:54:32.064+0000" -> (known after apply)
layers = []
memory_size = 256
package_type = "Image"
publish = false
qualified_arn = "arn:aws:lambda:ap-northeast-1:321498468606:function:aws_status_scraping:$LATEST"
reserved_concurrent_executions = -1
role = "arn:aws:iam::321498468606:role/lambda_aws_status_scraping"
~ source_code_hash = "07b6ae0e9c3f3c8cbc265dc16d012d079aedb5bbae8b35c777c502e3cb1d9d98" -> "79c095fd303af7739e343689e540763995e32cff99704e10e4c67a8d2f2113eb"
source_code_size = 0
tags = {}
timeout = 60
version = "$LATEST"
environment {
variables = {
"OUTPUT_BUCKET_NAME" = "test-upload-bucket-20210302"
"UPLOAD_FILE_NAME" = "aws_services.csv"
}
}
tracing_config {
mode = "PassThrough"
}
}
Plan: 0 to add, 1 to change, 0 to destroy.
applyをしてあげることで、変更後のDockerイメージを利用することができます。
$ aws lambda invoke --function-name aws_status_scraping \
--payload '{}' \
--cli-binary-format raw-in-base64-out \
response.json
$ cat response.json
"Succeeded..."⏎
さいごに
- 全体的に簡単に利用し易い機能であると感じました。(カスタムイメージは触ったことが無いので何とも言えないですが)
- CI/CD周り、特にECR側のDockerイメージを更新した際には、たとえタグが変わらなくてもLambda側の更新処理(update-function-cod)が必要である点は気を付ける必要がありそうです。イメージのpushをしてリリースをした気にならないようにしましょう。
- また、terraformのnull_resourceを利用してコンテナのビルド、プッシュ機構を用意することも可能ですが、planのタイミングでコンテナイメージのビルドが行われず、差分が検出できないので注意してください。
Discussion