はじめに
文章によるドキュメントの意味検索、類似検索を実装するうえで、Pineconeをはじめとするベクトルデータベースのセットアップが必要になります。
ベクトルデータベースを扱う場合、データの転送にEmbedding(埋め込み)の手間が増えます。
WeaviateのVectorizerのように、取り込みの際に埋め込みを行えるベクトルデータベースもありますが、そうでない場合は、ある程度の実装・メンテが必要になってきます。
本稿で扱うGitHub Issuesの場合、
- GitHub APIでのデータ取得
- Embed(埋め込み)
- ベクトルデータベース用のスキーマにデータフォーマット
- データベース登録
- 差分取り込みのためのid・更新管理
- APIの仕様変更にともなうアップデート
といった実装・メンテが必要です。
筆者は上記をGoogle Apps ScriptとCloud Funtionsで管理していましたが、チーム内でのコード引き継ぎが難しそうなため、ローコードで実現できるELTツールをいくつか試していました。
そのうち、
- ベクトルデータベース特有の埋め込みも含めて行ってくれる
- セットアップが容易
- 差分取り込みが容易
を満たしたツールとしてAirbyteを取り上げます。
環境
- MacBook Air M1
- Docker Desktop for Mac
- Docker Desktopに含まれるDocker Composeを使います。
前提
- GitHubリポジトリ
- OpenAI APIキー
- Pineconeのセットアップ
Airbyteのセットアップ
Airbyteはクラウド版もありますが、今回はセルフホスティングを試します。
ドキュメントは下記です。
git clone --depth=1 https://github.com/airbytehq/airbyte.git
cd airbyte
./run-ab-platform.sh
これでlocalhost:8000にサービスが立ち上がります。
Basic認証でユーザーネーム、パスワードが求められますので、.envに設定されている(or 設定した)BASIC_AUTH_USERNAMEとBASIC_AUTH_PASSWORDを入力すると管理画面が表示されます。
Connectionの作成
sourceにGitHub、destinationにPineconeとするConnectionを作成します。
サイドバーより"Connections"を選択します。

Source:GitHub

SourceにGitHubを設定し、下記を設定します。
- 認証キー
- OAuth / Personal Access Token
→ Personal Access Tokenを使用しました。GitHubのSetting > Developer Settingから取得できます。

- OAuth / Personal Access Token
- リポジトリ名
- org/repoの形式
- option
- Start date
- 今回はOpenAI APIを使ったEmbedding(埋め込み)を行うため、料金を抑えるために設定しました。

- 今回はOpenAI APIを使ったEmbedding(埋め込み)を行うため、料金を抑えるために設定しました。
- Start date
Destination:Pinecone
-
大きなデータを分割する際のChunk sizeやSplitterを選択できます。GitHubなので、SplitterにはBy Markdown Headerを選択しました。
-
Fields to store as metadataにpineconeのmetadataに追加したいフィールドを指定します。指定しない場合はすべてのフィールドがmetadataに追加されます。
-
Text fields to embedでは埋め込みする(検索対象にする)フィールドを指定できます。こちらも指定しない場合はすべてのフィールドが埋め込み対象になります。実際に使う場合は、指定をした方がよさそうです。

-
埋め込み方法とキー指定します。OpenAI以外のキーも指定できます。

-
Pineconeの接続情報。いずれもPineconeの管理画面で確認できます。

Connectionの設定
最後にSourceとDestinationの設定を行います。
-
同期スケジュールを選択。毎時間ごとから24時間ごとまで選択できます。
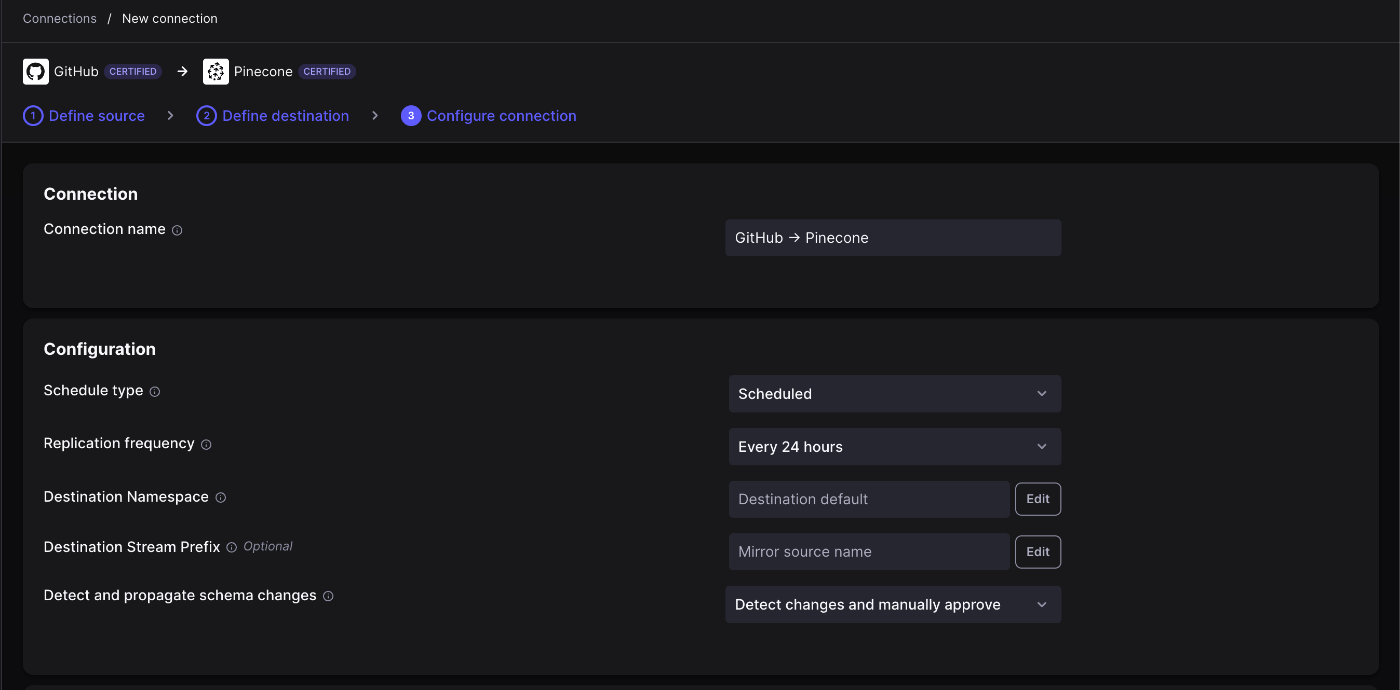
-
どのフィールドを同期させるか指定します。ここでIssues以外のToggleをoffにします。

-
Issuesの項目をクリックすると、さらにIssueの項目のうち、どれを同期させるか絞り込めます。

これで設定は完了、setup connectionで同期されます。

確認
Pinecone側
下記のように登録されていました。

Fields to store as metadataに何も指定していなかったので、syncさせた全項目がmetadataに入っていました。
OpenAI側
OpenAIのUsageを見てみると、確かにEmbeddingsの料金が発生していました。実行前に見積もりToken量の確認は出ないのでご注意ください。

検索
クライアントライブラリを使って簡単な検索をしてみます。
サンプルコード
import { Pinecone } from '@pinecone-database/pinecone';
import OpenAI from "openai"
async function main() {
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY,
environment: process.env.PINECONE_ENVIRONMENT,
});
const index = pinecone.index(process.env.PINECONE_INDEX)
const query = 'FileMaker監視'
const docs = await index.query({
"vector": await createEmbeddings(query),
topK: 1,
includeMetadata: true
})
docs.matches.forEach((doc) => {
console.log(doc.id, doc.score, doc.metadata)
})
}
async function createEmbeddings(input: string) {
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
})
const embeddings = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input
})
return embeddings.data[0].embedding
}
main().then(console.log)
結果(抜粋)
{
_ab_record_id: 'issues_1967780049',
_ab_stream: 'issues',
author_association: 'COLLABORATOR',
body: '# 概要\r\n' +
'FileMakerの監視を行い、休日中のトラブルなどの捕捉システムを作る\r\n' +
'\r\n' +
'# 課題・現状\r\n' +
'- FileMakerのインスタンス自体のモニタはGCPで可能\r\n' +
'- FIleMaker Serverのモニタが不十分...
comments: 10,
comments_url: 'https://api.github.com/repos/...',
created_at: '2023-10-30T08:23:47Z',
events_url: 'https://api.github.com/...,
html_url: 'https://github.com/...
id: 1967780049,
labels_url: 'https://api.github.com/...
}
データの同期(Sync)について
データの同期方法はSource側で指定でき、2種類あります。
- Incremental
- 新規または修正されたデータのみ
- Full Refresh
- 一括
今回のようにベクトルデータベースを用いる場合、Full Refreshだと毎回の実行でEmbeddingsの料金がかかってしまうのでご注意ください。
Incrementalの場合、cursorと呼ばれる値を元に差分検知され、cursorを持つフィールドはcursor_fieldと呼ばれます。
GitHubのIssues場合は以下の通り、updated_atがcursor_fieldとなっていました。

管理画面のSetting > Connection stateをみると、streamStateの下にupdated_atがありましたので、ここをもとに差分取り込みをしているのだと思います。
実際に少し時間をおいて実行したところ、GitHubの更新の分だけ(2レコード)取り込まれていることが確認できました。

おわりに
Airbyteを使ったGitHub IssuesのPineconeへの取り込み・同期を試しました。
AirbyteはDockerでセットアップでき、かつAPIキーを渡すだけでEmbeddingされるため、ベクトルデータベースのデータ同期をノーコードで行えます。
何か既存のデータから意味検索を実装したい場合など、有力な選択肢になると思います。

Discussion