はじめに
プログデンスの佐藤です。
生成AIを利用したツール作成において、よくDifyの名前が上がります。
Difyの最大の特徴は、ノーコード/ローコードでRAG(Retrieval-Augmented Generation)を組み込める点にあると考えています。
本記事では、Difyを使ってRAGを組み込んだワークフローを作成する方法を、実際の手順とともにご紹介します。
本記事はDifyのRAGシリーズの第1回目として、ファイルインポートによるナレッジベース構築に焦点を当てています。
この記事で分かること
- Difyでの基本的なチャットフローの作成方法
- ファイルからRAGナレッジベースを作成する手順
- チャンク分割の基本設定と考え方
※本記事で使用しているDifyはv1.9.2となります。
生成AIを利用した基本的なワークフローを作成する
まずは、RAGを組み込む前の基本的なワークフローを作成します。
作成する内容
- 基本的なワークフローなので、単純なチャットエージェントを作成します
- 使用するモデル:Amazon Nova(応答速度や精度を求めてるわけではないので)
作成手順
- スタジオ -> 最初から作成 を選択

- チャットフローを選択し、名前を入力、作成を選択

- 作成されたチャットフローを公開

※ただ作成するだけですので、フロー等に手は加えません。
作成されたワークフローの確認

これで基本的なチャットフローが完成しました。
次のステップでは、このワークフローにRAGを組み込んで、特定の知識に基づいた回答ができるようにカスタマイズしていきます。
RAGのナレッジベースを作成する
ここからが本記事のメインパートです。先ほど作成したチャットフローに、RAGを組み込んでいきます。
RAGとは?
RAG(Retrieval-Augmented Generation)は、外部のナレッジベースから関連情報を検索し、その情報を元に生成AIが回答を生成する技術です。
RAGのメリット
RAGを利用することのメリットとして、以下が挙げられます。
- 専門知識の活用:特定ドメインの情報を正確に回答
- ハルシネーション(幻覚)の削減:根拠のある情報源から回答
- 情報の鮮度:最新の社内情報やドキュメントを反映可能
Difyでの実装方法
DifyではRAGのナレッジベースを作成する方法がデフォルトで3通り用意されています。
- ファイルをインポートする
- Notionと連携する
- ウェブサイトと同期する
本記事では「1. ファイルをインポートする」方法を解説します。
ナレッジベースの作成手順
ナレッジベースは以下の手順で作成していきます。
- インポートするファイルの準備
- ファイルをインポート
- ファイル内容をチャンク(chunk)に分割
1. インポートするファイルの準備
今回はRFC4271(BGP-4)のテキストファイル(rfc4271.txt)を用意しました。
用意しました、と書きましたが、IETFの内容そのままです。
注意事項として、インポートできるファイルの種類及びサイズには制限があります。
TXT, MARKDOWN, MDX, PDF, HTML, XLSX, XLS, DOCX, CSV, VTT, PROPERTIES, MD, HTMをサポートしています。1 つあたりの最大サイズは15MB です。
2. ファイルをインポート
- ナレッジ -> ナレッジベースを作成

- テキストファイルからインポート -> ファイルを選択 -> 次へ
…ここでテキストという文言は必要なのか微妙なところですね。

3. ファイル内容をチャンク(chunk)に分割
インポートした内容はそのままでは、AIにとって扱いやすいものではないため、ファイルの内容を一定の固まり(chunk)に分割していきます。
チャンク分割のパラメータ解説


| パラメータ | デフォルト値 | 説明 |
|---|---|---|
| チャンク識別子 | \n\n |
どこで区切るかの基準(改行2つ) |
| 最大チャンク長 | 1,024文字 | 1つのチャンクの最大サイズ |
| チャンクオーバーラップ | 50文字 | 前後のチャンクと重複させる文字数 |
| インデックス方法 | 高品質 | 処理精度(高品質/経済的/カスタム) |
| 埋め込みモデル | amazon.titan-embed-text-v2:0 | ベクトル変換に使用するモデル |
| 検索設定 | ベクトル検索 | 検索アルゴリズム(ベクトル/全文/ハイブリッド) |
なぜオーバーラップが必要?
文脈が途切れないよう、前後のチャンクで一部重複を持たせることで、より自然な検索結果が得られます。

デフォルトのままですが、上記例では、RFC4271の内容が適切な段落単位で分割されているのが確認できます。
チャンク分割のベストプラクティス
- 技術文書の場合:セクションや段落の区切りを尊重
- 会話ログの場合:発言単位での分割を検討
- 長文の場合:最大チャンク長を調整して意味のある単位に
チャンクについては公式サイトに詳細がまとめられているので、そちらを参照するのがよいかと思います。
ナレッジベースの完成
これでナレッジベースが完成しました。

ナレッジベースをワークフローに組み込む
作成したナレッジベースを、先ほどのチャットフローに組み込みます。
組み込み手順
- 先ほど作成したチャットフローの編集画面に戻る

- 「開始」と「LLM」ノードの間をクリックして、知識検索(ナレッジベース)を選択
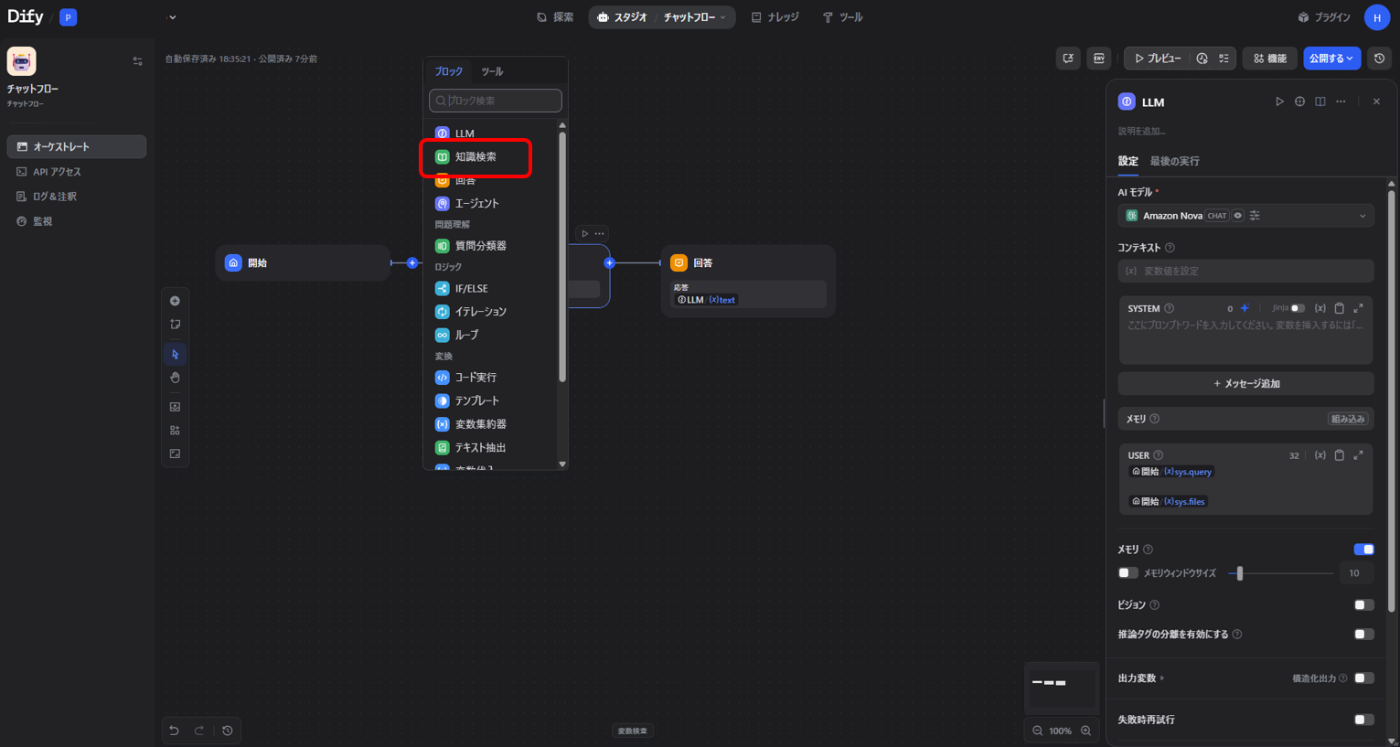
- 右側のメニューから「+」をクリックして、作成したナレッジベース「rfc4271.txt」を選択

- 知識検索の結果を利用するため、LLMの設定を編集
- コンテキスト:
{{#知識検索.result}}を追加 - システムプロンプト:検索結果に基づいた回答を促すよう調整

- コンテキスト:
- 保存して公開

ナレッジベースを組み込んだ結果
それでは、ナレッジベースをチャットフローに組み込んだ前後でのAIの回答の違いを見てみます。
今回はナレッジベースとして、公開情報であるRFCを選んでいるため、少し細かい内容での精度の比較になります。
質問:「RFC4271のセクション4.2で定義されているOPENメッセージのフォーマットを教えてください」
実際にRFC4271に記載されているフォーマット
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+
| Version |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| My Autonomous System |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Hold Time |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| BGP Identifier |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Opt Parm Len |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| Optional Parameters (variable) |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
回答結果:RAGが無い場合

問題点:
- ❌ フォーマット図が正確に表現できていない
- ❌ フィールド名がRFC4271の用語と微妙に異なる
- ❌ Hold Timeなど一部フィールドが欠落
- ❌ 一般的な知識に基づいた回答で、文書に忠実でない
回答結果:RAGがある場合
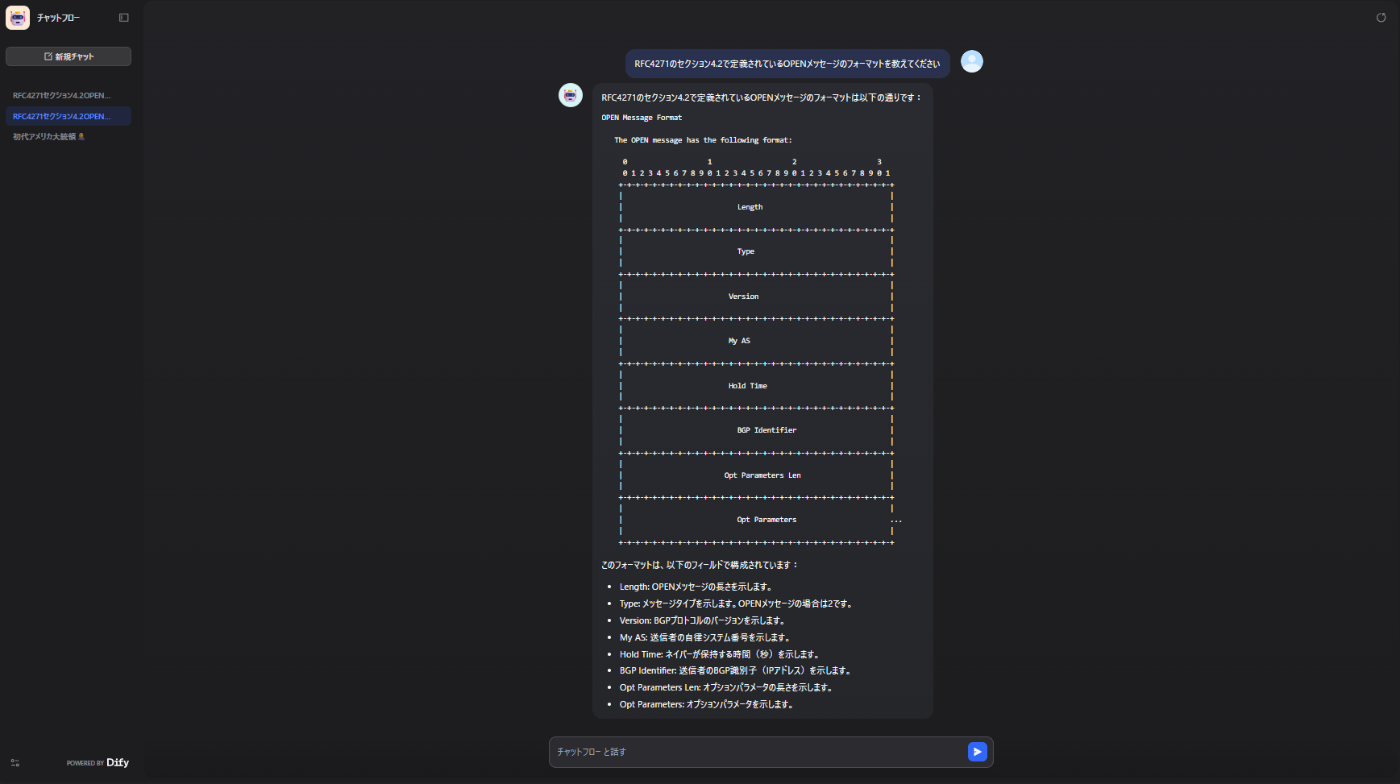
RAGが無い場合と比較して、適切になった回答になっています。
…引用セクションを返してくれないのは、AIの気まぐれなのかもしれません。
RAGの効果まとめ
インポートしたファイルが公開情報であったため、ややニッチな部分を攻めてしまった感はありますが、RAGが無い場合と比べて回答精度を向上させることはできたのではないかと思っています。
| 項目 | RAG無し | RAG有り |
|---|---|---|
| フォーマット図の正確性 | 表現が崩れる | RFC原文の通り |
| フィールド名 | 微妙に異なる | 完全一致 |
| 情報の完全性 | 一部欠落 | 全フィールド記載 |
| 文書への忠実度 | 一般知識ベース | RFC4271に忠実 |
| 特に技術文書では、用語の正確性やフォーマットの忠実な再現が重要です。 |
まとめ
本記事では、DifyのRAG(ナレッジベース)をファイルインポートで作成する方法を紹介しました。
本記事のポイント
✅ Difyはノーコードで簡単にRAGを実装できる
✅ ファイルインポートは15MBまで、多様な形式に対応
✅ チャンク分割の設定が回答精度に影響
✅ RFC4271を例に、実際のナレッジベース構築手順を体験
次回予告
次回は、Notionをデータソースとして活用する方法をご紹介します。
リアルタイム同期や編集の容易さなど、ファイルインポートとは異なる利点がありますので、ぜひご期待ください!
末筆ですが、最後までお読みいただき、ありがとうございました。
ご質問やフィードバックがあれば、コメント欄でお気軽にお寄せください。

株式会社プログデンス/BtoB向けのITソリューションを提供する企業です。 技術スタック: SASE / Prisma Access / Zscaler / Netskope / Cato Networks / Tanium / M365 / Cisco / Automation / Ansible