この記事は trocco Advent Calendar 2023 の6日目の記事となります。
はじめに
今回はtroccoの内部でも利用されているETLのためのOSSであるEmbulkについて、core部分のソースコードリーディングを通して、そのしくみを紐解いていきたいと思います。
おことわり
- Embulkの基本的な使い方などについては解説しません。
- 筆者はembulk-coreにコントリビュートしているわけではないので、間違いなどがあればお気軽にご指摘ください。
- 今回見ていくcoreの実装自体は、比較的変更が少ないとされる各種プラグインが従うべきインターフェース部分(embulk-spi)から隠蔽されているため、今後この記事の内容が正しくなくなる可能性は容易にあります。
- Embulkにはguessやpreviewやresumeといった機能も含まれていますが、今回は単純な
embulk runで実行される処理に絞ってお話しします。
前提
参照バージョン
embulk-coreの参照するバージョンは、2023/12/06の時点での最新であるv0.11.2とします。
後述するembulk-spiは以下のv0.11を参照します。
embulk-spi
コードを見ていく前に、いくつかの前提にも触れておきます。
各プラグインは、embulk-spiで定められたインターフェースに従ってembulk-coreと連携しています。
v0.9以前ではembulk-coreのorg/embulk/spiパッケージ以下に配置されていましたが、インターフェース以外の各種ユーティリティクラスもこの中には存在しています。
v0.11以降ではそういった依存性を減らすために、インターフェース定義を別リポジトリに切り出しています。
コードを追っていく中で、embulk-coreのorg/embulk/spiの中には見つからないインターフェースがあったらこちらのリポジトリを参照するとよいです。
また、この辺りの詳しい話はcoreのメンテナーをしているdmikurubeさんの記事に詳しくまとまっています。
プラグイン種別
こちらは、Embulkを利用していれば一般的な内容かもしれませんが、プラグインには以下のいくつかの種類が存在します。
- InputPlugin: 非ファイル系のデータ元(MySQLなど)
- FileInputPlugin: ファイル系のデータ元(S3など)
- OutputPlugin: 非ファイル系のデータ先(BigQueryなど)
- FileOutputPlugin: ファイル系のデータ先(S3など)
- FilterPlugin: データ元からデータ先への過程での変換処理。ETLのTの部分
- ParserPlugin: データ元ファイルのパース(csvなど)
- DecoderPlugin: データ元ファイルの解凍(gzipなど)
- FormatterPlugin: データ先ファイルのフォーマット(csvなど)
- EncoderPlugin: データ先ファイルの圧縮(gzipなど)
- (ExecutorPlugin): 今回は1つのインスタンス上での実行を想定したLocalExecutorを前提とする
- (GuessPlugin): guess機能で利用。今回は割愛
同名のインターフェースもembulk-spiに定義されており、プラグイン側はそれを満たすように実装する必要があります。
各プラグインの対応関係は、大まかに以下となります。
※ 厳密な実行時の流れというよりはイメージ図です。
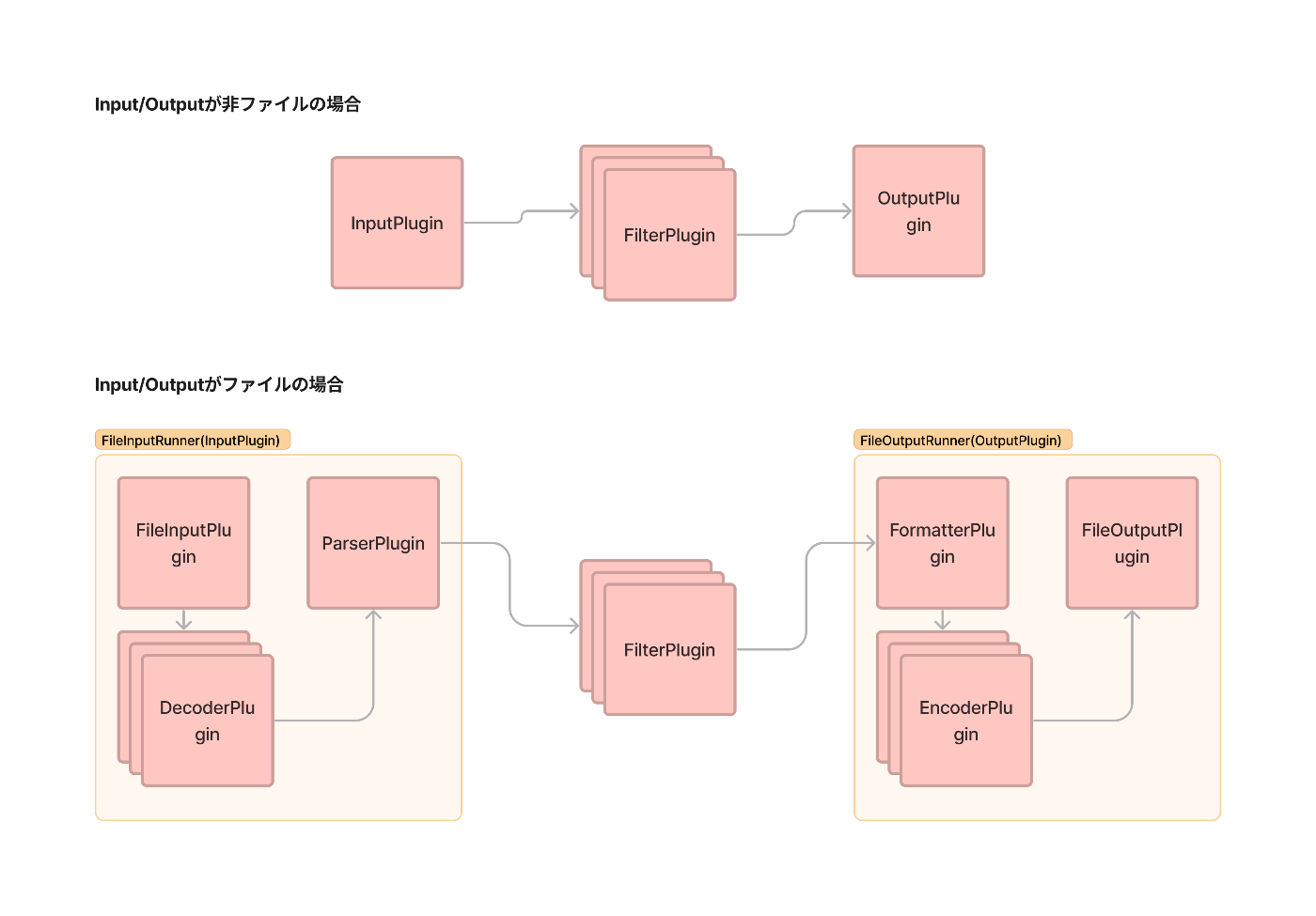
FileInputPluginはデータ元の括りですが、embulk-core側のFileInputRunnerというInputPluginを実装したクラスから利用されます。
FileInputPluginが実装を要求するメソッドはInputPluginとは異なる点も注目です。
(FileOutputPluginも同様)
また、FilterPlugin ,DecoderPlugin ,EncoderPluginは複数指定することが可能です。
コードリーディング
前置きが長くなりましたが、それではembulk-coreのソースコードを読んでいきます。
エントリーポイント
embulkコマンドを実行した際のエントリーポイントは以下のクラスのmainメソッドです。
さまざまな初期化処理が行われますが、長いのでだいぶ飛ばします。
embulk runが実行されると、最終的に以下のBulkLoaderクラスのdoRun メソッドに到達します。
ここから読み進めていきます。
transaction
まずは前述のdoRunですが、ここでは各プラグイン側で実装されたtransactionメソッドが順番に呼ばれていきます。
かなりネストしていて、core側とプラグイン側の処理がいり混じっている部分なので初見だと流れをイメージしづらいかもしれません。
整理すると、以下のシーケンス図のようになっています。細かくなってしまったので拡大して見てみてください。

core側に実装された~.Controlが各プラグインの橋渡しをしているイメージです。
一番右のExecutorPlugin.Executor.executeからは実際の転送処理の実行に移ります。
そのため、処理がreturnしてくるのは転送が終了したタイミングになります。
ファイル系のプラグインを利用しているともう少し複雑です。
例えばinput部分であれば、前述のFileInputRunnerのtransactionが呼ばれ、その後その中で定義されているRunnerControl.runがDecoderPlugin,ParserPluginのtransactionが呼びだしていく構造になっていたりします。
また、FilterPluginの様に複数プラグインを設定できる場合は、core側のFilterInternal.transactionが呼ばれ、各FilterPluginのtransactionを順に呼び出す構造になっています。(DecoderPluginやEncoderPluginも同様)
では、そもそもtransactionでは何が行われているのでしょうか。
プラグイン側の実装次第ではありますが、一言で言うとメインの転送処理に対する前処理や後処理を行なっています。
特に前述のシーケンス図の右矢印の過程(前処理)においては、各プラグインで事前に算出しておくべき値などが~Controlのインターフェース定義を見ると分かります。
transactionの中では前処理を終えると~Controlのメソッドを呼び出すからです。
InputPluginでは、Schemaとint taskCountを渡して~Control.runを呼び出しています。
データ元の設定によって、最初に入ってくるデータのスキーマが決定されるので、これを事前に算出して後続へ渡しています。
また、ファイル系のプラグインでは、ファイル数に応じた並列処理がこの後に行われていくため、事前にファイル数(int taskCount)を求めておきます。
FilterPluginでもSchemaを算出しています。
これはInputPluginから渡されたスキーマがETLのTであるFilterPluginを通すことで変化していく可能性があるからです。
ExecutorPluginでは新たにint outputTaskCountという概念が出てきました。
詳しくは後述しますが、後続の並列処理ではInputPluginで求めたint taskCountに加えて、ホストマシンのCPUコア数や明示的な設定値に応じてその並列処理方法が変化します。
そのために必要なint outputTaskCountという値をExecutorPluginでは事前に算出しています。
また、transactionでは~Control.runの呼び出し後に処理を書くと全ての転送処理が終了した後の後処理を書くことができます。
例えば、embulk-output-jdbcにおいては、tempテーブルに転送したデータを最後にまとめて対象のテーブルにInsertするような処理をここで行なっています。
transactionメソッドが呼び出されていく段階では、処理はまだ直列です。
この後は、シーケンス図の一番右のExecutorPlugin.Executor.executeの処理内容を追っていきます。
並列転送処理
前述のExecutorPlugin.Executor.execute以降の処理ですが、
Executorは、DirectExecutor,ScatterExecutorのどちらかということがtransactionの段階で決定されています。
DirectExecutor,ScatterExecutorに関しては、以下のsonotsさんの記事で詳しく解説されています。
対象バージョンはv0.8.6ですが、大まかには変わっていないと思いますので、詳細はこちらの記事を参照してください。
まずは、シンプルな方のDirectExecutorで読み進めると分かりやすいと思います。
以降は、JavaのFutureによってスレッドごとの処理に分岐してきますが、それぞれのThreadは以下の処理に到達します。
ここが転送処理の始まりの部分です。
PageOutput
最初にOutputPluginに実装されたopenというメソッドが呼ばれ、その返り値であるPageOutputというインターフェースを実装したインスタンスを取得します。
次にFilterPluginのopenが前段のPageOutputを受け取りまた新たなPageOutputを返します。
面白いことに、ここはデータの処理と流れが逆な点に注目です。
PageOutputを実装したクラスはそれぞれaddというメソッドがあり、この処理はそれぞれで異なります。
データの処理と逆の流れでリレーしていったことで、最終的にはデータの処理の順にPageOutputがネストされたオブジェクトが得られます。

そして、最終的なPageOutputは、InputPluginのrunメソッドに渡されます。
runメソッドでは各InputPluginが思いのままにデータ元からデータを取得します。
その取得したデータはPageというクラスのインスタンスに格納されます。
生成したPageは後続のプラグインへPageOutputのaddメソッドを介して受け渡されていきます。
PageOutputを先に生成していたのはここに意味があるわけです。
各PageOutputは後続のPageOutputを内包しているため、各プラグインにおける処理を終えると、Pageを生成して後続のPageOutputにaddしていきます。
最終的にはOutputPluginに到達して、そのaddメソッドはデータロードの処理を実行します。
流れは以下のシーケンス図のようになります。(FilterPluginが一つの場合)
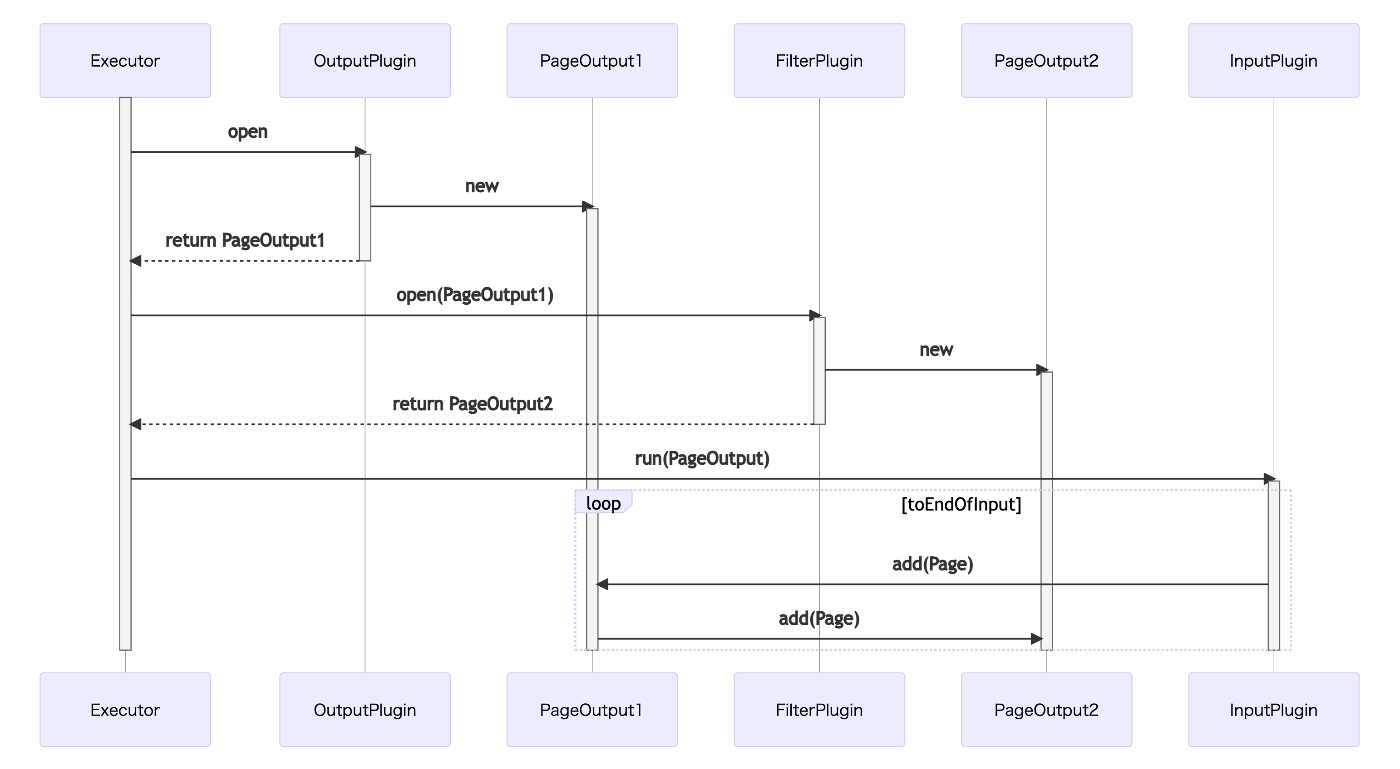
つまり、まずデータ元のデータを全件取得して後続に渡して処理していくような逐次的処理ではなく、データの取得中(ETLのE)にも順次後続の処理(ETLのTL)を行っていくような準ストリーミングな方式の処理となっています。
そのため大規模なデータにおいてもメモリ消費を一定に抑えることができ、更には並列処理による速度向上も見込めるアーキテクチャとなっているわけです。
Page
それではPageとはなんでしょうか。
Pageはそのフィールドとして、bufferとstringReferences, jsonValueReferencesを持っています。
bufferは32KBのバイト列で以下のようにレイアウトとなっています。
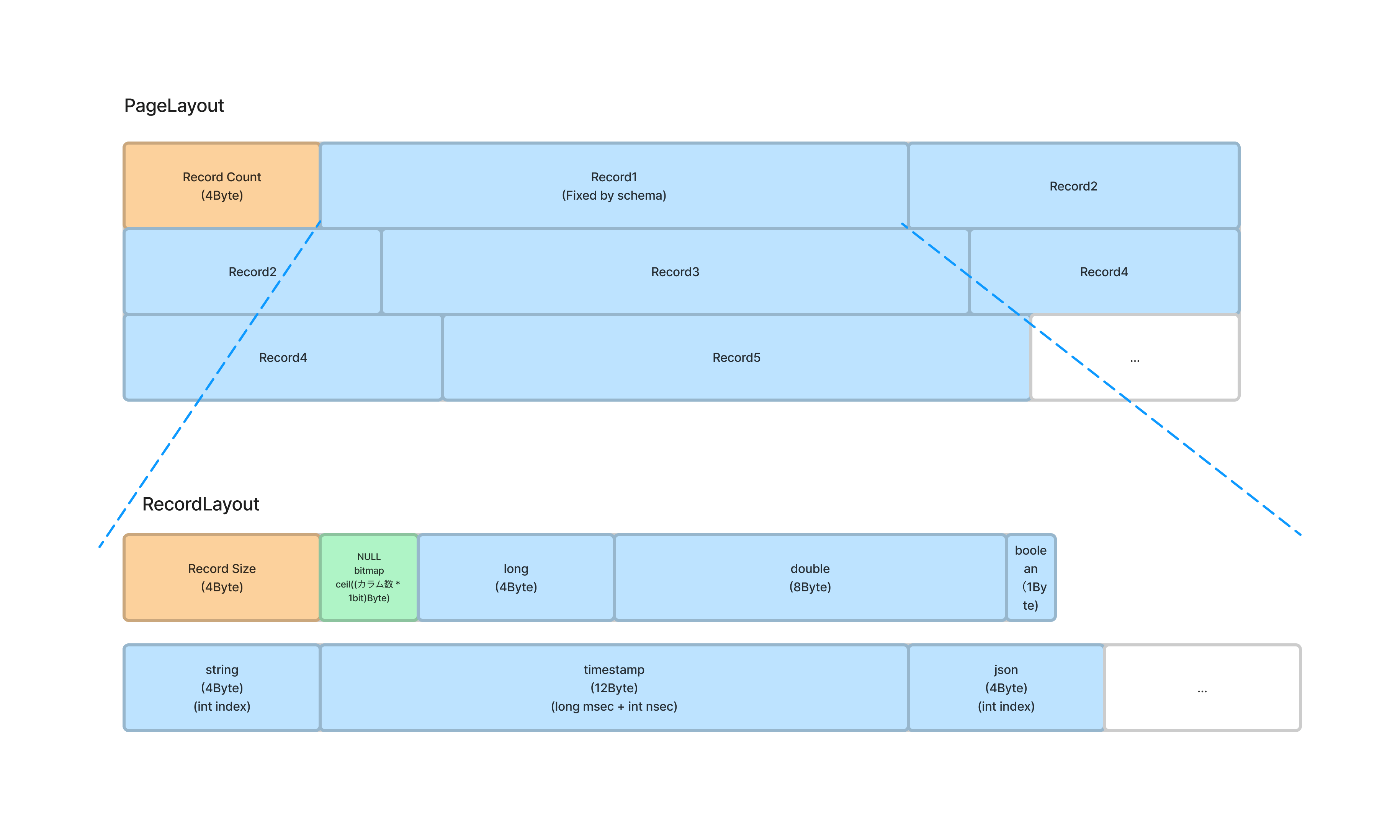
Pageという名称で行ごとのデータをシリアライズしたり、NULLのbitmapを行ヘッダーに持っているような構造は、どこかRDBMSにおけるページの概念の思い起こします。
とはいえ、string, json型のデータは可長幅のデータ型が故に、実データはstringReferences, jsonValueReferencesに保持した上でその配列のindex値がbufferに格納されているようでした。
この辺のWhy?は歴史的経緯も絡んでくると思いますが深くは調べきれていません。
そして、上記のようなPageの内部構造はプラグイン側に対しては隠蔽されているため、PageBuilder, PageReaderというクラスを利用して読み書きをしていることがほとんどです。
PageBuilder
PageBuilderを利用したPageの書き込みは、プラグイン側では例として以下のように実装できます。
特に厳密な制約はないですが、Visitorパターンを使ってEmbulkにおける各型(long, double, boolean, string, timestamp, json)に対する処理を書いているプラグインが多いと思います。
while ( /* 全体ループ */ ) {
while ( /* 行ループ */ ) {
schema.visitColumns(new ColumnVisitor() {
public void longColumn(Column column) {
boolean v = /* 値を取得 */
pageBuilder.setBoolean(column, v);
}
public void stringColumn(Column column) {
String v = /* 値を取得 */
pageBuilder.setString(column, v);
}
/* その他の型、double, boolean, timestamp, jsonについても実装 */
})
}
pageBuilder.addRecord();
}
pageBuilder.finish();
カラムごとに値をset~していき、addRecordを呼び出すと1レコードとして記録されます。
bufferに収まらなくなったタイミングで、PageBuilder.flushが呼び出され後続のPageOutputへaddされます。
PageReader
一方で、読み取り側ではPageReaderを利用します。
こちらも概ね同じようにVisitorパターンで実装しているプラグインが多いと思います。
while (pageReader.nextRecord()) {
pageReader.getSchema().visitColumns(new ColumnVisitor() {
public void booleanColumn(Column column) {
/* FilterPluginであればPageBuilderのset~を呼び出す */
/* OutputPluginであればLoadのための各種処理 */
}
/* その他の型についても実装 */
})
}
ここで一点着目したいのは、FilterPluginにおいてはPageReaderによってPageが読み出されると然るべく処理を行った後にPageBuilderを利用してPageを生成して後続に渡している点です。
(embulk-standards/embulk-filter-remove_columnsの例)
InputPlugin -> OutputPluginの流れの中で同一の一行であれば同一のPageと言うように一対一に紐づいているわけではなく、
以下のようにPageは各プラグイン間においてのデータ受け渡しのたびに生成されます。

おわりに
いかがだったでしょうか。
embulk runの処理の流れの詳細は、core側とプラグイン側の両方を参照しないとといけなかったり、PageOutputの部分などコードを上から読んでいくだけではイメージが付きづらい部分があったりするかもしれません。
今回はその辺をできるだけ図やソースコードのリンクを使って解説してみました。
普段ユーザーとして利用している分にはここまで理解する必要はないと思いますが、何かの際のトラブルシューティング時で少しでもお役に立てれば幸いです。
余談ですが、私も業務で特定の状況で発生するメモリリークの問題を調査する必要があり、その際coreのコードを読み込んだことが今回の記事を執筆した始まりでした。
(少量でもファイル数が多い場合に、プラグイン側の実装次第ではPageで割り当てたbufferが解放されないことによって発生する問題)

Discussion