この記事は「一人自作RDBMS Advent Calendar 2025」3日目の記事です。
本日の実装はGitHubにあります。昨日からの差分は以下のコマンドで確認できます。
git diff --no-index day02 day03
今日のゴール
Buffer Pool Managerを実装し、PageをメモリにキャッシュしてディスクI/Oを削減します。
なぜBuffer Poolが必要か
昨日までの実装では、Pageにアクセスするたびにディスクから読み込んでいました。
Latency Numbers Every Programmer Should Knowによれば、メモリアクセスが100nsに対してディスクシークは10ms。約10万倍遅いため、これは深刻なボトルネックになります。
Buffer Poolの仕組み
Buffer Poolは有限個のFrame(Pageを格納するメモリ領域)を事前に確保しておき、そこにPageをキャッシュします。
Pageへのアクセスは全てBuffer Pool経由で行います。要求されたPageがすでにFrameにあればそのまま返し(Cache Hit)、なければBuffer Poolがディスクから読み込んでFrameに格納します(Cache Miss)。利用側はキャッシュの有無を意識する必要がありません。
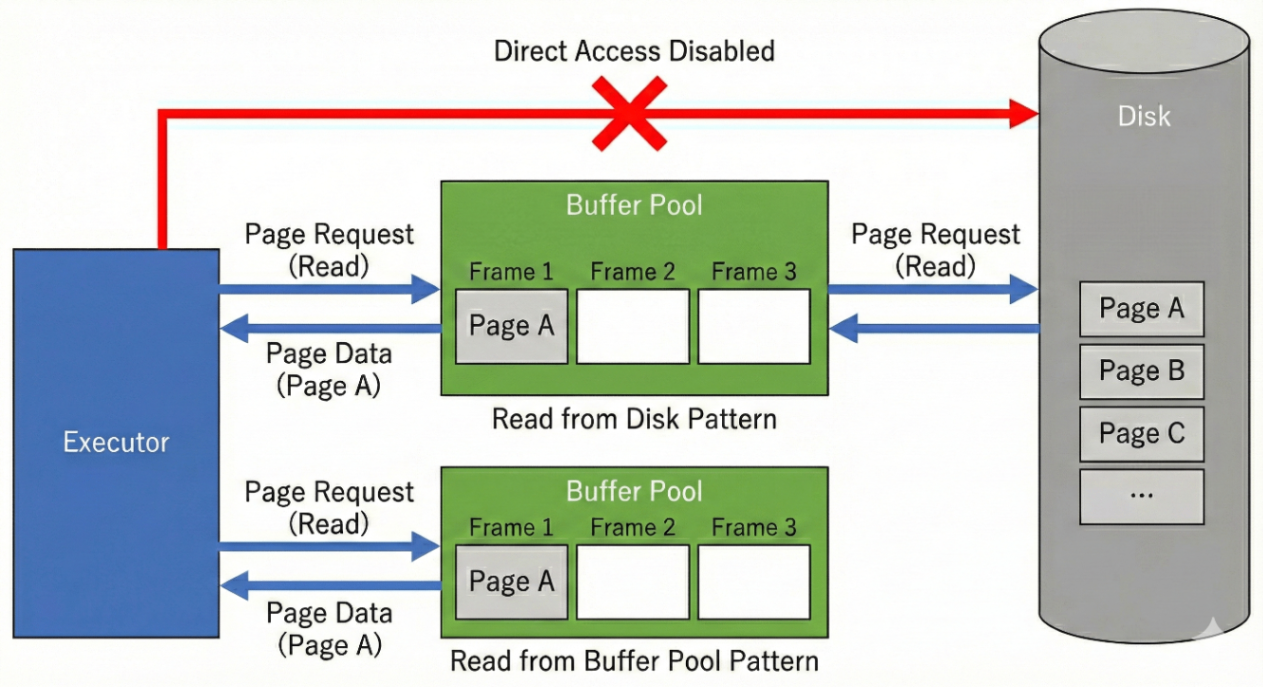
ただし、Frameは有限です。全てのPageをキャッシュすることはできないので、Frameが満杯の場合は古いPageを追い出してディスクに書き戻し、空いた場所に新しいPageを読み込む必要があります。

※ 余談ですが、以上の画像はNano Banana Proに指示をして生成しました。凄いですね。
どのPageを追い出すかを決めるのが置換アルゴリズムです。
LRU (Least Recently Used)
置換アルゴリズムにはClockやLRU-Kなど様々なものがありますが、今回はLRU(Least Recently Used)を採用します。「最も長く使われていないPageを追い出す」というシンプルなアルゴリズムです。
アクセス: A → B → C → A → D (Buffer Pool size = 3)
Step 1: [A] ←new
Step 2: [A, B] ←new
Step 3: [A, B, C] ←new (満杯)
Step 4: [B, C, A] ←move to end (Aを再使用)
Step 5: [C, A, D] ←new, evict B (Bが最も古い)
時間的局所性(最近使ったデータは近いうちにまた使う)に基づいた戦略です。
Pin Count
Buffer Poolにはもう一つ重要な概念があります。Pin Countです。
あるPageを使っている最中に、そのPageがBuffer Poolから追い出されたら困ります。例えばSELECTでスキャン中のPageが途中で消えたら、正しくデータを読めなくなります。
そこで、Pageを「使用中」としてマークする仕組みがPin Countです。
-
fetch_page: Pin Countを1増やす(このPageは使用中) -
unpin_page: Pin Countを1減らす(使い終わった) - 置換対象: Pin Count = 0 のPageのみ
Pin Count > 0 のPageは追い出し対象から除外されます。
実装
Frame構造体
Buffer PoolはFrame(Pageを格納する枠)の配列です。
const BUFFER_POOL_SIZE: usize = 3; // small for testing
struct Frame {
page: Page,
page_id: Option<u32>,
pin_count: u32,
is_dirty: bool,
}
-
page: 実際のPageデータ -
page_id: どのPageを保持しているか(None = 空きFrame) -
pin_count: 使用中カウンタ -
is_dirty: 変更されたかどうか(追い出し時にディスクに書き戻す必要があるか)
Replacer
置換アルゴリズムをtraitとして定義し、LRU以外(ClockやLRU-Kなど)にも差し替えられるようにしています。
pub trait Replacer {
fn victim(&self) -> Option<usize>; // 追い出し対象を選ぶ
fn pin(&mut self, frame_id: usize); // 使用中としてマーク
fn unpin(&mut self, frame_id: usize); // 使用終了としてマーク
}
LruReplacerではindexmapクレートのIndexSetを使い、挿入順序を維持しつつO(1)で削除できるようにしています。
pub struct LruReplacer {
order: IndexSet<usize>, // 挿入順を維持、O(1)で削除可能
pinned: Vec<bool>,
}
impl Replacer for LruReplacer {
fn victim(&self) -> Option<usize> {
// 最も古いunpinnedなframeを返す
self.order.iter().find(|&&id| !self.pinned[id]).copied()
}
fn pin(&mut self, frame_id: usize) {
self.pinned[frame_id] = true;
// 末尾に移動(最近使用された)
self.order.shift_remove(&frame_id);
self.order.insert(frame_id);
}
fn unpin(&mut self, frame_id: usize) {
self.pinned[frame_id] = false;
}
}
Buffer Pool Manager
pub struct BufferPoolManager<R: Replacer = LruReplacer> {
frames: Vec<Frame>,
page_table: HashMap<u32, usize>, // page_id -> frame_id
disk_manager: DiskManager,
replacer: R,
}
page_tableでPage IDからFrame IDへの高速な検索を実現しています。Replacerはジェネリクスで受け取るので、異なる置換アルゴリズムに差し替え可能です。
fetch_page
Pageを取得する処理です。
pub fn fetch_page(&mut self, page_id: u32) -> Result<&mut Page> {
// すでにBuffer Poolにあればそのまま返す
if let Some(&frame_id) = self.page_table.get(&page_id) {
self.frames[frame_id].pin_count += 1;
self.replacer.pin(frame_id);
return Ok(&mut self.frames[frame_id].page);
}
// 空きFrameを探すか、追い出しが必要
let frame_id = if self.page_table.len() < BUFFER_POOL_SIZE {
self.frames.iter().position(|f| f.page_id.is_none()).unwrap()
} else {
let victim = self.replacer.victim()
.ok_or_else(|| anyhow::anyhow!("no victim frame"))?;
self.evict(victim)?;
victim
};
// ディスクからPageを読み込む
let mut data = [0u8; PAGE_SIZE];
self.disk_manager.read_page(page_id, &mut data)?;
let frame = &mut self.frames[frame_id];
frame.page = Page::from_bytes(&data);
frame.page_id = Some(page_id);
frame.pin_count = 1;
frame.is_dirty = false;
self.page_table.insert(page_id, frame_id);
self.replacer.pin(frame_id);
Ok(&mut self.frames[frame_id].page)
}
- すでにBuffer Poolにあればそのまま返す(キャッシュヒット)
- なければ空きFrameを探すか、Replacerに基づいてVictimを選んで追い出す
- ディスクからPageを読み込んでFrameにセット
evict
追い出し時にdirtyならディスクに書き戻します。
fn evict(&mut self, frame_id: usize) -> Result<()> {
let frame = &mut self.frames[frame_id];
if let Some(old_page_id) = frame.page_id {
if frame.is_dirty {
self.disk_manager.write_page(old_page_id, &frame.page.data)?;
}
self.page_table.remove(&old_page_id);
}
frame.page_id = None;
frame.is_dirty = false;
frame.pin_count = 0;
Ok(())
}
Table(利用側)
Tableは昨日まではDiskManager経由でPageにアクセスしていましたが、今日からはBufferPool経由に切り替えます。
fetch_pageで取得したPageを使い終わったら、必ずunpin_pageを呼ぶ必要があるので注意が必要です。
pub fn scan(&mut self) -> Result<Vec<Vec<Value>>> {
let mut results = Vec::new();
let page_count = self.bpm.page_count();
for page_id in 0..page_count {
let page = self.bpm.fetch_page(page_id)?;
for slot_id in 0..page.tuple_count() {
if let Some(tuple_data) = page.get_tuple(slot_id) {
let values = deserialize_tuple(tuple_data, &self.schema)?;
results.push(values);
}
}
self.bpm.unpin_page(page_id, false)?; // 使い終わったらunpin
}
Ok(results)
}
動作確認
Buffer Pool size = 3 で、15件のデータを挿入して動作を確認します。
let disk_manager = DiskManager::open(DATA_FILE)?;
let bpm = BufferPoolManager::new(disk_manager);
let mut table = Table::new(bpm, schema);
for i in 1..=15 {
let name = format!("User{i}");
let loc = table.insert(&[Value::Int(i), Value::Varchar(name)])?;
println!("Inserted at: {loc:?}");
}
table.flush()?;
実行結果(stdout):
[BufferPool] Allocating new page 0
Inserted at: (0, 0)
Inserted at: (0, 1)
Inserted at: (0, 2)
[BufferPool] Allocating new page 1
Inserted at: (1, 0)
Inserted at: (1, 1)
Inserted at: (1, 2)
[BufferPool] Allocating new page 2
Inserted at: (2, 0)
Inserted at: (2, 1)
Inserted at: (2, 2)
[BufferPool] Evicting page 0 (dirty: true)
[BufferPool] Allocating new page 3
Inserted at: (3, 0)
Inserted at: (3, 1)
[BufferPool] Evicting page 1 (dirty: true)
[BufferPool] Allocating new page 4
Inserted at: (4, 0)
Inserted at: (4, 1)
[BufferPool] Evicting page 2 (dirty: true)
[BufferPool] Allocating new page 5
Inserted at: (5, 0)
Inserted at: (5, 1)
Total pages: 6
Buffer Pool size = 3 なので、4つ目のPageを割り当てる際に最も古いPage 0が追い出されています。
追い出し時にdirty: trueなのでディスクに書き戻されています。
次回予告
明日はうってかわってSQL Parserを実装します。
SELECT * FROM users WHERE id > 10のようなSQL文字列を解析し、木構造として解釈できるようにします。

Discussion